
Python爬虫入门实战之猫眼电影数据抓取(理论篇)_猫眼 爬取
赞
踩
前言
本文可能篇幅较长,但是绝对干货满满,提供了大量的学习资源和途径。达到让读者独立自主的编写基础网络爬虫的目标,这也是本文的主旨,输出有价值能够真正帮助到读者的知识,即授人以鱼不如授人以渔,让我们直接立刻开始吧,本文包含以下内容:
-
Python环境搭建与基础知识
-
爬虫原理概述
-
爬虫技术概览
-
猫眼电影排行数据抓取
-
Ajax数据爬取猫眼电影票房
-
更多进阶,代理、模拟登陆、APP 爬取等……
Python环境搭建与基础知识
Python环境搭建
Anaconda安装
此处笔者并不会介绍Python软件的安装,有读者可能会疑问Python都不安装,我怎么学习先进的Python知识呢? 不要着急,此处笔者介绍了一种新的Python快速安装方式,即直接安装Anaconda,Anaconda是什么呢? Anaconda 是一个Python的发行版,包括了Python和很多常见的Python库, 和一个包管理器cond,Anaconda是专注于数据分析的Python发行版本,包含了conda、Python等720多个科学包及其依赖项,适用于企业级大数据分析的Python工具。在数据可视化、机器学习、深度学习等多方面都有涉及。不仅可以做数据分析,甚至可以用在大数据和人工智能领域。有读者可能会疑问这和爬虫有什么关系呢,当然有关系,在编写爬虫程序的过程中需要使用Python库,而Anaconda就已经包含这些经常使用库,这对安装Python库感到头疼的读者再好不过了。当然这一切都是免费的,接下来我们就开始安装美妙的Anaconda吧。
首先从Anaconda官网下载对应版本的Anaconda,如果下载速度过慢推荐使用国内的清华大学开源软件镜像站选择对应的Anaconda下载,Anaconda的官网下载页面如下图所示:

本文推荐下载Python3.6对应的版本,以笔者为例电脑环境为:Windows-64Bit,下载的对应版本为:Anaconda3-5.2.0-Windows-x86_64,下载完成后打开安装包如下图所示:
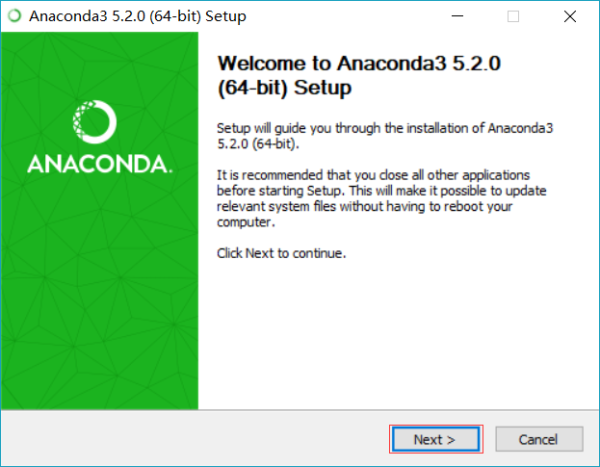
点击 next
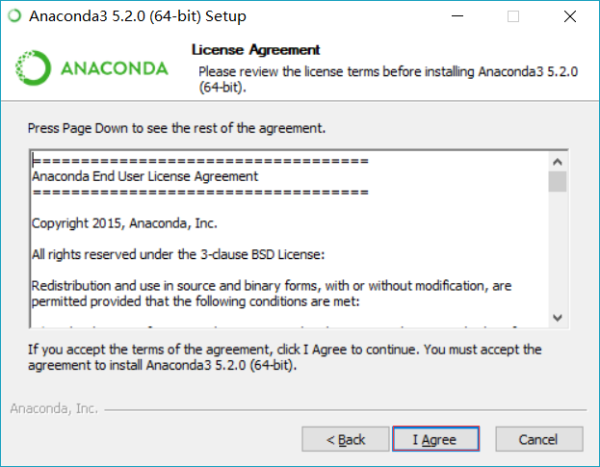
点击 I Agree
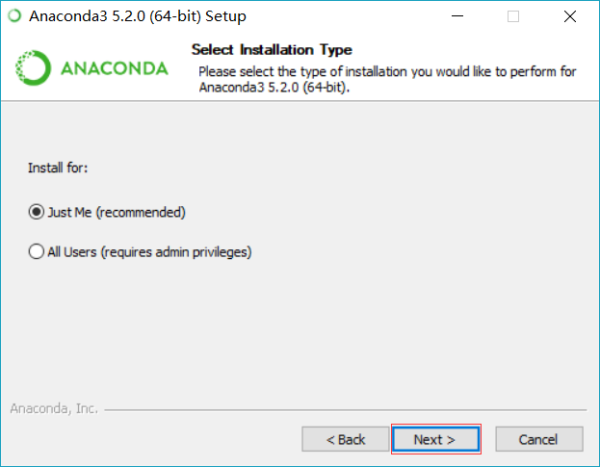
选择 Just Me ,点击 next

选择安装目录,点击next
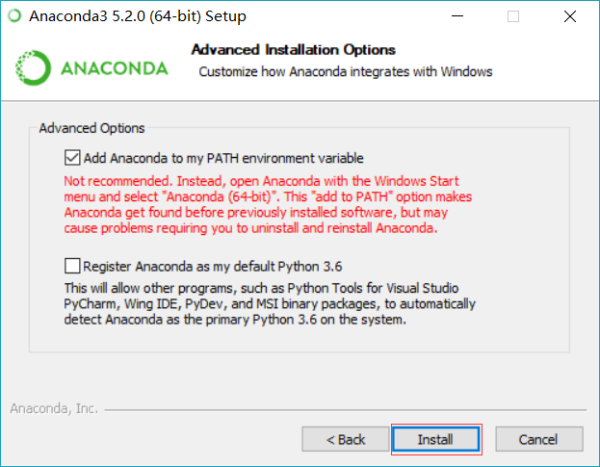
勾选 Add Anaconda to my PATH environment variable ,然后点击 install 安装即可
IDE环境搭建
IDE笔者推荐使用Pycharm,有朋友需要安装包和永久激活码可以找我领取~

1.1Python 基础技术
我不会介绍过于基础内容,因为这些内容互联网上已经大量免费的基础入门教程了,但是笔者会给大家提供一些互联网的免费学习资源和方法,让大家快速学会编写爬虫程序所需要的Python基础知识和进阶知识,而对于基础的爬虫我们需要掌握的Python知识有以下:
-
数据类型
-
列表
-
循环语句
-
判断语句
-
函数
Python基础
对于完全没有Python基础的读者,可以找我领取一份免费入门学习资料,扫码添加即可!
爬虫是什么
爬虫原理
爬虫是什么?爬虫从本质上说就是在模拟HTTP请求,记住这句话,这就是我们后面经常需要做的事情。一般用户获取网络数据的方式有两种:
a. 浏览器提交HTTP请求—>下载网页代码—>解析成页面。
b. 模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中。
爬虫就是在做第二种事情,大致过程如下:
i. 通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器的响应
ii. 如果服务器正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML、JSON、二进制文件(如图片、视频等类型)。 iii. 得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是JSON,可以直接转成JOSN对象进行解析,可能是二进制数据,可以保存或者进一步处理
iv. 保存形式多样,可以保存成文本,也可以保存至数据库,或者保存成特定格式的文件。
许多读者可能不知道上面具体在做什么,那么接下来我们通过浏览器抓包分析上面的过程,笔者推荐使用Chrome,对开发者很友好,后续我们会经常使用到,Chrome下载,如果下载速度较慢,建议使用国内Chrome镜像下载安装。
首先打开浏览器在地址栏输入 https://www.baidu.com/ (读者也可以使用其他网页测试比如咱们的https://gitbook.cn/),回车,百度页面映面而来,然后按下F12,浏览器开发者选项的快捷键,选择Network栏目,打开界面下图所示:

按下F5刷新页面:

栏目里面更新了大量的数据包,这些包就是浏览器请求的数据,我们想要的数据就在这些请求里面
-
第一列Name:请求的名称,一般会将URL的最后一 部分内容当作名称。
-
第二列Status: 响应的状态码,这里显示为200,代表响应是正常的。通过状态码,我们可 以判断发送了请求之后是否得到了正常的响应。
-
第三列Type: 请求的文档类型。这里为document, 代表我们这次请求的是一个HTML文档,内容就是一些HTML代码。
-
第四列initiator: 请求源。用来标记请求是由哪个对象或进程发起的。
-
第五列Size: 从服务器下载的文件和请求的资源大小。如果是从缓存中取得的资源,则该列会显示from cache。
-
第六列Time:发起请求到获取响应所用的总时间。
-
第七列Waterfall:网络请求的可视化瀑布流。 接下来我们分析请求的详细组成,比如点第一个请求即Name为www.baidu.com的请求,如下图所示:

我们看到响应中分General部分,请求头、响应头
General一般包含以下部分:
-
Request URL为请求的URL
-
Request Method为请求的方法
-
Status Code为响应状态码,
-
Remote Address为远程服务器的地址和端口
Response Headers一般包含以下部分(响应(服务端->客户端[response])):
-
HTTP/1.1为响应采用的协议和版本号 200 (状态码) OK(描述信息)
-
Location为服务端需要客户端访问的页面路径
-
Server为服务端的Web服务端名
-
Content-Encoding为服务端能够发送压缩编码类型
-
Content-Length为服务端发送的压缩数据的长度
-
Content-Language为服务端发送的语言类型
-
Content-Type为服务端发送的类型及采用的编码方式
-
Last-Modified为服务端对该资源最后修改的时间
-
Refresh为服务端要求客户端1秒钟后,刷新,然后访问指定的页面路径
-
Content-Disposition为服务端要求客户端以下载文件的方式打开该文件
-
Transfer-Encoding为分块传递数据到客户端
-
Set-Cookie为服务端发送到客户端的暂存数据
-
Connection为维护客户端和服务端的连接关系
Request Headers 一般包含以下部分(请求(客户端->服务端[request])):
-
GET(请求的方式) /newcoder/hello.html(请求的目标资源) HTTP/1.1(请求采用的协议和版本号)
-
Accept为客户端能接收的资源类型
-
Accept-Language为客户端接收的语言类型
-
Connection为维护客户端和服务端的连接关系
-
Host: localhost为连接的目标主机和端口号
-
Referer告诉服务器我来自于哪里
-
User-Agent为客户端版本号的名字
-
Accept-Encoding为客户端能接收的压缩数据的类型
-
If-Modified-Since为缓存时间
-
Cookie为客户端暂存服务端的信息
-
Date为客户端请求服务端的时间 而我们需要做的就是模拟浏览器提交Requests Headers获取服务器的响应信息,从而得到我们想要的数据,想要深入了解的读者请访问HTTP | MDN文档了解更多信息。
爬虫能抓什么样的数据
在网页中我们能看到各种各样的信息,最常见的就是用户能够看到的网页页面,而通过浏览器的开发者工具对网页请求进行抓包时我们可以看见大量的请求,即有些网页返回的不是HTML代码,可能是json字符串,各种二级制数据,比如图片、音频、视频等,当然还有些是CSS、JavaScript等文件。那么即浏览器能够获取的数据,爬虫程序都能获取到,而浏览器的数据是翻译给用户看到的信息,即只要能够在浏览器访问到的信息,爬虫程序就都能够抓取下来。
爬虫技术概览
_:本节介绍爬虫经常使用到的技术,比如请求:requests,信息提取:Xpath,Re正则,json,存储:CSV,MySQL, MongoDB,模拟浏览器Selenium,保证在项目实战中涉及的技术读者都会,也就是这里需要讲清楚这些技术的使用方法,
第一个请求
Requests库
Requests库,官方文档是这样描述:Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。 Requests 是以 PEP 20 (即著名的Python之禅)的箴言为中心开发的,下面就是Requests的开发哲学,望读者能够细细品读,写出更加Pythonic的代码。
Beautiful is better than ugly.(美丽优于丑陋) Explicit is better than implicit.(直白优于含蓄) Simple is better than complex.(简单优于复杂) Complex is better than complicated.(复杂优于繁琐) Readability counts.(可读性很重要)
在2.1中我们谈到爬虫的原理就是进行HTTP请求然后得到响应,在响应中提取我们想要的信息并保存。而Requests库就是利用Python模拟HTTP请求的利器。如果读者已经安装了Anaconda,那么Requests库就已经可用了,如果没有Requests库,读者可以在命令行中(win+R 输入 cmd)pip install requests 安装requests库,接下来就开始我们的第一个请求吧! 使用Requests发送HTTP请求非常简单,接下来我们就以GitChat为例:
# 导入requests 模块
import requests
# 发起Get请求并返回Response对象,包含服务器对HTTP请求的响应
response = requests.get('https://gitbook.cn/')
# 打印 响应状态码
print(response.status_code)
# 打印 str类型的响应体,比如一个普通的 HTML 页面,需要对文本进一步分析时,使用 text
print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
部分运行的结果如下图所示:

Requests不仅支持Get方式请求,比如Post请求:
# 导入 requests 模块
import requests
# 需要提交的表单数据
data = {
'name': 'ruo', 'age': 22
}
# 发起Post请求
response = requests.post("http://httpbin.org/post", data=data)
# 响应体内容
print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
部分运行的结果如下图所示:

当然Requests还支持更多的请求方式,比如以下请求,笔者就不一一演示了,最常用的请求就是以上Get和Post两种请求方式。
# PUT请求
requests.put(“http://httpbin.org/put”)
# DELETE请求
requests.delete(“http://httpbin.org/delete”)
# HEAD请求
requests.head(“http://httpbin.org/get”)
# OPTIONS请求
requests.options(“http://httpbin.org/get”)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
由于大多数服务器都会通过请求头中的User-Agent识别客户端使用的操作系统及版本、浏览器及版本等信息,所以爬虫程序也需要加上此信息,以此伪装浏览器;如果不加上很可能别识别出为爬虫,比如当我们不加Headers对知乎进行get请求时:
# 导入 requests 模块
import requests
# 发起Get请求
response = requests.get("https://www.zhihu.com")
# 状态码
print(response.status_code)
# 响应体内容
print(r.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
返回的内容如下图所示:

我们可以看见返回的400的状态码,及请求无效,接着我们在请求里添加Headers,然后添加User-Agent信息,再次尝试请求:
# 导入 requests 模块
import requests
# 在Headers中添加User-Agent字段信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
# 发起Get请求
response = requests.get("https://www.zhihu.com", headers=headers)
# 状态码
print(response.status_code)
# 响应体内容
print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
返回的内容如下图所示:

可以看见请求成功,并返回了正确的响应状态码和响应体。 想要更深入的学习Requests的读者可以访问Requests官方原文文档或者中文文档。
提取信息
当我们通过HTTP请求获取到响应后,加下来就需要提取响应体中的内容,此处笔者介绍两种常用的提取方法,一个是正则表达式,另一个是Xpath。
正则表达式
正则表达式是一个很强大的字符串处理工具,几乎任何关于字符串的操作都可以使用正则表达式来完成,作为一个爬虫工作者,每天和字符串打交道,正则表达式更是不可或缺的技能。有了它,从HTML里提取想要的信息就非常方便了。
读者可以通过正则表达式 | 廖雪峰的官方网站快速入门,也可以通过Python正则表达式 | 菜鸟教程 学习Python中操作正则和使用正则,Python的官方文档中Python标准库的6.2节也对Re有详细的介绍和使用教程。
初次接触正则表达式的读者可能会觉得有些抽象,有点难入门,因为毕竟正则表达式本身就是一种小型的、高度专业化的编程语言,以上的入门教程了解后,这里给读者介绍一个提取信息通用的正则字符串 .*?,该规则能够以非贪婪的方式匹配任意字符,后面我们会经常使用到。比如我们需要匹配
Chapter 1 - 介绍正则表达式
标签中的内容,我们可以:# 导入 re 模块
import re
# 待匹配文本
h1 = '<H1>Chapter 3.2.1 - 介绍正则表达式</H1>'
# 将正则字符串编译成正则表达式对象,方便在后面的匹配中复用
pat = re.compile('<H1>(.*?)</H1>', re.S)
# re.search 扫描整个字符串并返回第一个成功的匹配
result = re.search(pat, h1)
# 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
print(result.group(0))
# 匹配的第一个括号内的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
print(result.group(1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
以下是匹配结果:

Xpath
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。 XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言,在爬虫中提取信息也是不错的好帮手。
读者可以通过 Xpath 教程 | 菜鸟教程 学习Xpath的原理及编写方法,也可以访问CSDN博客中搜索Python Xpath学习更多Python中Xpath的基本操作,接下来介绍编写“编写”的技巧和在Python中使用的方法,之所以加上“编写”,读者看下面便知。 还记得在2.1爬虫原理中使用的浏览器的开发者工具吗,我们可以通过这个工具直接获取对应节点的Xpath规则,从而达到快速利用Xpath提取网页信息的目的,例如提取猫眼电影TOP100榜中的电影信息,首先打开浏览器输入http://maoyan.com/board/4,将鼠标移动到需要提取的信息(电影名称)上,右键选择检查,如下图所示:
接着我们选择下面的元素,右键选择Copy–>xpath, 如下图所示:

获取了该节点的xpath规则了,接下来我们编写Python程序验证该规则是否能够真正提取电影名:
import requests # 导入lxml库的etree模块 from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } url = 'http://maoyan.com/board/4' response = requests.get(url, headers=headers) html = response.text # 调用HTML类进行初始化 html = etree.HTML(html) # 粘贴我们copy的xpath,提取电影名 “霸王别姬” result_bawangbieji = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[1]/a') # 打印节点标签包含的文本内容 print(result_bawangbieji[0].text) # 提取该页面所有电影名,即选择所有'dd'标签的电影名 result_all = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a') # 打印所有提取出的电影名 print('该页面全部电影名:') for one in result_all: print(one.text)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
结果如下图所示,我们成功提取了HTML中电影名的信息:

存储信息
TEXT 文本存储
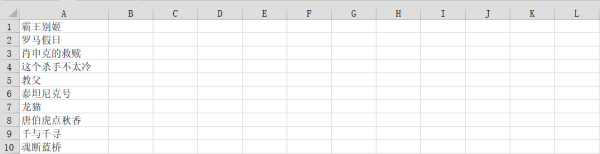
如果读者学习了Python的基础知识,那么应该比较熟悉这种基本信息存储方式,即直接将我们需要存储的信息写入文件中,比如常见的TEXT文件,如果不熟悉的读者可以通过Python文件读写 - Python教程™快速概览,下面我们就对3.2.2中Xpath提取的电影名进行文件存储操作:
import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } url = 'http://maoyan.com/board/4' response = requests.get(url, headers=headers) html = response.text # 调用HTML类进行初始化 html = etree.HTML(html) # 粘贴我们copy的xpath,提取电影名 “霸王别姬” result_bawangbieji = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[1]/a') # 打印节点标签包含的文本内容 print(result_bawangbieji[0].text) # 提取该页面所有电影名 result_all = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a') # 打印所有提取出的电影名 print('该页面全部电影名:') for one in result_all: print(one.text) # 将这一页电影名存储至TEXT文件中,'a' 指打开一个文件进行追加。 如果文件存在,则文件指针位于文件末尾。也就是说,文件处于追加模式。如果文件不存在,它将创建一个新文件进行写入。 with open('film_name.text', 'a') as f: for one in result_all: f.write(one + '\n')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
存储结果如下图所示:

CSV存储
CSV文件即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,以纯文本形式存储表格数据,包括数字或者字符。Python中已经内置CSV文件操作的模块,只需要导入就可以进行CSV存储操作,下面我们就将3.2.2中Xpath提取的电影名进行CSV文件存储操作:
import requests from lxml import etree # 导入CSV模块 import csv headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } url = 'http://maoyan.com/board/4' response = requests.get(url, headers=headers) html = response.text html = etree.HTML(html) result_bawangbieji = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[1]/a') print(result_bawangbieji[0].text) result_all = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a') print('该页面全部电影名:') for one in result_all: print(one.text) # 将这一页电影名存储至CSV文件中: with open('film_name.csv', 'a', newline='') as f: csv_file = csv.writer(f) for one in result_all: csv_file.writerow([one.text])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
CSV文件存储结果如下图所示:
MySQL 存储
MySQL 是最流行的关系型数据库管理系统,如果读者没有安装MySQL可以通过phpstudy 2018 下载下载phpstudy快速安装MySQL
在Python2中,连接MySQL的库大多是使用MySQLdb,但是此库的官方并不支持Python3,所以这里推荐使用的库是PyMySQL,读者可以通过Python+MySQL数据库操作(PyMySQL)| Python教程™学习PyMYSQL操作MySQL的相关方法和实例,接下来我们就尝试将3.2.2中Xpath提取的电影名存储到MySQL中,没有该模块的读者可以通过(win+R 输入 cmd)pip install pymysql 安装pymysql库。
import requests from lxml import etree # 导入pymysql模块 import pymysql # 打开一个数据库连接 db = pymysql.connect(host='localhost', user='root', password='root', port=3306, db='spider', use_unicode=True, charset="utf8") # 获取MySQL的操作游标,利用游标来执行SQL语句 cursor = db.cursor() headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } url = 'http://maoyan.com/board/4' response = requests.get(url, headers=headers) html = response.text html = etree.HTML(html) result_bawangbieji = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[1]/a') print(result_bawangbieji[0].text) result_all = html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a') print('该页面全部电影名:') for one in result_all: print(one.text) try: # 插入数据语句 sql = 'INSERT INTO film_infor(film_name) values (%s)' cursor.execute(sql, (one.text)) db.commit() except: db.rollback()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
MySQL存储结果如下图所示:

如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

