
热门标签
热门文章
- 1unity入门教程(非常详细)从零基础入门到精通,看完这一篇就够了_unity完全自学教程
- 2IDEA教程_config your intellisence settings to help主要是干什么的
- 32024年最全Windows下MySQL的详细安装教程_mysql windows安装教程csdn,太厉害了_windows安装mysql
- 4Intel FPGA高速设计代码原则总结
- 5基于bert的中文语义匹配模型,判断两句话是不是同一个意思
- 6算法沉淀——BFS 解决最短路问题(leetcode真题剖析)_leetcode bfs题
- 7com.fasterxml.jackson.databind.JsonMappingException: (was java.lang.NullPointExcepti 单属性VO在序列化时空指针异常
- 8华为OD机试C卷-- 贪吃的猴子(Java & JS & Python & C)
- 9动手学深度学习 - 3.11. 模型选择、欠拟合和过拟合_动手学深度学习 3.11
- 10MySQL的视图(介绍、创建、修改、更新、重命名和删除)MySQL的存储过程(入门、变量定义、参数传递和流程控制)_mysql 修改视图
当前位置: article > 正文
【基于IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建逻辑回归鸢尾花分类预测模型】_使用spark mllib逻辑回归方法对鸢尾花分类; 2.使用spark mllib决策树方法对鸢尾
作者:酷酷是懒虫 | 2024-07-05 16:06:19
赞
踩
使用spark mllib逻辑回归方法对鸢尾花分类; 2.使用spark mllib决策树方法对鸢尾花
逻辑回归进行鸢尾花分类的案例
背景说明:
基于IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建逻辑回归鸢尾花分类预测模型,这是一个分类模型案例,通过该案例,可以快速了解Spark MLlib分类预测模型的使用方法。
依赖
ThisBuild / version := "0.1.0-SNAPSHOT"
ThisBuild / scalaVersion := "2.13.11"
lazy val root = (project in file("."))
.settings(
name := "SparkLearning",
idePackagePrefix := Some("cn.lh.spark"),
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.4.1",
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.4.1",
libraryDependencies += "org.apache.hadoop" % "hadoop-auth" % "3.3.6", libraryDependencies += "org.apache.spark" %% "spark-streaming" % "3.4.1",
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "3.4.1",
libraryDependencies += "org.apache.spark" %% "spark-mllib" % "3.4.1",
libraryDependencies += "mysql" % "mysql-connector-java" % "8.0.30"
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
代码如下:
package cn.lh.spark
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.{LogisticRegression, LogisticRegressionModel}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, StringIndexerModel, VectorIndexer, VectorIndexerModel}
import org.apache.spark.ml.linalg.{Vectors,Vector}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
case class Iris(features: org.apache.spark.ml.linalg.Vector, label: String)
/**
* 二项逻辑斯蒂回归来解决二分类问题
*/
object MLlibLogisticRegression {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[2]")
.appName("Spark MLlib Demo List").getOrCreate()
val irisRDD: RDD[Iris] = spark.sparkContext.textFile("F:\\niit\\2023\\2023_2\\Spark\\codes\\data\\iris.txt")
.map(_.split(",")).map(p =>
Iris(Vectors.dense(p(0).toDouble, p(1).toDouble, p(2).toDouble, p(3).toDouble), p(4).toString()))
import spark.implicits._
val data: DataFrame = irisRDD.toDF()
data.show()
data.createOrReplaceTempView("iris")
val df: DataFrame = spark.sql("select * from iris where label != 'Iris-setosa'")
df.map(t => t(1)+":"+t(0)).collect().foreach(println)
// 构建ML的pipeline
val labelIndex: StringIndexerModel = new StringIndexer().setInputCol("label")
.setOutputCol("indexedLabel").fit(df)
val featureIndexer: VectorIndexerModel = new VectorIndexer().setInputCol("features")
.setOutputCol("indexedFeatures").fit(df)
// 划分数据集
val Array(trainingData, testData) = df.randomSplit(Array(0.7, 0.3))
// 设置逻辑回归模型参数
val lr: LogisticRegression = new LogisticRegression().setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures").setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8)
// 设置一个labelConverter,目的是把预测的类别重新转化成字符型的
val labelConverter: IndexToString = new IndexToString().setInputCol("prediction")
.setOutputCol("predictedLabel").setLabels(labelIndex.labels)
// 构建pipeline,设置stage,然后调用fit()来训练模型
val lrPipeline: Pipeline = new Pipeline().setStages(Array(labelIndex, featureIndexer, lr, labelConverter))
val lrmodle: PipelineModel = lrPipeline.fit(trainingData)
val lrPredictions: DataFrame = lrmodle.transform(testData)
lrPredictions.select("predictedLabel", "label", "features", "probability")
.collect().foreach { case Row(predictedLabel: String, label: String, features: Vector, prob: Vector) =>
println(s"($label, $features) --> prob=$prob, predicted Label=$predictedLabel")}
// 模型评估
val evaluator: MulticlassClassificationEvaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel").setPredictionCol("prediction")
val lrAccuracy: Double = evaluator.evaluate(lrPredictions)
println("Test Error = " + (1.0 - lrAccuracy))
val lrmodel2: LogisticRegressionModel = lrmodle.stages(2).asInstanceOf[LogisticRegressionModel]
println("Coefficients: " + lrmodel2.coefficients+"Intercept: " +
lrmodel2.intercept+"numClasses: "+lrmodel2.numClasses+"numFeatures: "+lrmodel2.numFeatures)
spark.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
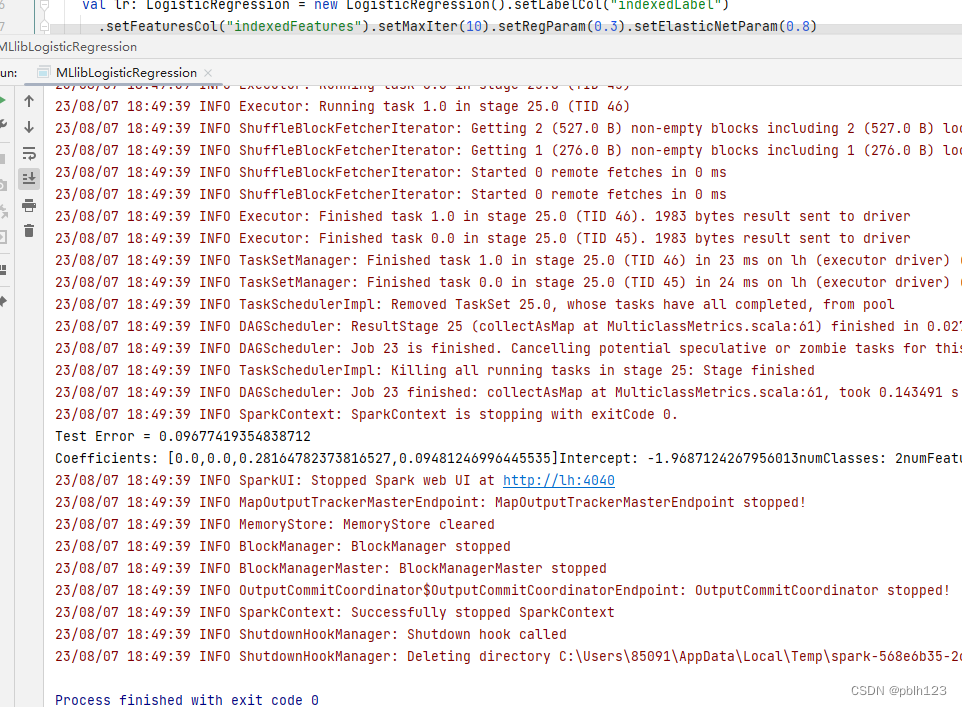
运行结果如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/790471
推荐阅读

相关标签

