- 1docker学习和进阶2023_2023 docker
- 2Spark 部署与应用程序交互简单使用说明_m&m巧克力豆数据集
- 3(附源码)anjule客户信息管理系统 毕业设计181936_用户管理系统毕业设计
- 4[程序员:产品思维速通宝典⓪⑥] - 职场人所面临困惑与迷茫应该如何破局?_困惑 破局
- 5卷积神经网络(基础篇)_卷积神经网络入门项目
- 6php种调用jodConverter+ openoffic实现word转pdf_php openoffice
- 7CompletableFuture并发工具类_completablefuture工具类
- 8代码质量与安全 | 如何将清洁代码标准扩展到整个企业,促进业务上的成功?
- 9开源软件和开源协定_开源软件的历史渊源 发展和主要开源协议
- 10Android Gantt View 安卓实现项目甘特图
昇思25天学习打卡营第10天|基于 MindSpore 实现 BERT 对话情绪识别
赞
踩
今天是参加昇思25天学习打卡营的第10天,今天打卡的课程是“基于 MindSpore 实现 BERT 对话情绪识别”,这里做一个简单的分享。
1.简介
从今天开始以后就是实践类的课程了,我选择从NLP方向开始学习,今天学习的目标是如何实现基于BERT的对话情绪识别?
1.了解的BERT模型的原理
2.实战基于BERT模型的情绪识别代码
2.BERT模型的基本原理
BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模型例如问答、命名实体识别、自然语言推理、文本分类等在许多自然语言处理任务中发挥着重要作用。模型是基于Transformer中的Encoder并加上双向的结构,因此一定要熟练掌握Transformer的Encoder的结构。
BERT模型的主要创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。在用Masked Language Model方法训练BERT的时候,随机把语料库中15%的单词做Mask操作。对于这15%的单词做Mask操作分为三种情况:80%的单词直接用[Mask]替换、10%的单词直接替换成另一个新的单词、10%的单词保持不变。
BERT预训练之后,会保存它的Embedding table和12层Transformer权重(BERT-BASE)或24层Transformer权重(BERT-LARGE)。使用预训练好的BERT模型可以对下游任务进行Fine-tuning,比如:文本分类、相似度判断、阅读理解等。
对话情绪识别(Emotion Detection,简称EmoTect),专注于识别智能对话场景中用户的情绪,针对智能对话场景中的用户文本,自动判断该文本的情绪类别并给出相应的置信度,情绪类型分为积极、消极、中性。 对话情绪识别适用于聊天、客服等多个场景,能够帮助企业更好地把握对话质量、改善产品的用户交互体验,也能分析客服服务质量、降低人工质检成本。
3.基于BERT模型的情绪识别实战
整个训练过程总共分为四个步骤
- 数据集的准备
import numpy as np # 定义数据集 def process_dataset(source, tokenizer, max_seq_len=64, batch_size=32, shuffle=True): is_ascend = mindspore.get_context('device_target') == 'Ascend' column_names = ["label", "text_a"] dataset = GeneratorDataset(source, column_names=column_names, shuffle=shuffle) # transforms type_cast_op = transforms.TypeCast(mindspore.int32) def tokenize_and_pad(text): if is_ascend: tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len) else: tokenized = tokenizer(text) return tokenized['input_ids'], tokenized['attention_mask'] # map dataset dataset = dataset.map(operations=tokenize_and_pad, input_columns="text_a", output_columns=['input_ids', 'attention_mask']) dataset = dataset.map(operations=[type_cast_op], input_columns="label", output_columns='labels') # batch dataset if is_ascend: dataset = dataset.batch(batch_size) else: dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id), 'attention_mask': (None, 0)}) return dataset

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 模型构建
通过 BertForSequenceClassification 构建用于情感分类的 BERT 模型,加载预训练权重,设置情感三分类的超参数自动构建模型。
from mindnlp.transformers import BertForSequenceClassification, BertModel from mindnlp._legacy.amp import auto_mixed_precision # set bert config and define parameters for training model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3) model = auto_mixed_precision(model, 'O1') optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5) metric = Accuracy() # define callbacks to save checkpoints ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='bert_emotect', epochs=1, keep_checkpoint_max=2) best_model_cb = BestModelCallback(save_path='checkpoint', ckpt_name='bert_emotect_best', auto_load=True) trainer = Trainer(network=model, train_dataset=dataset_train, eval_dataset=dataset_val, metrics=metric, epochs=5, optimizer=optimizer, callbacks=[ckpoint_cb, best_model_cb]) trainer.run(tgt_columns="labels")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 模型验证
将验证数据集加再进训练好的模型,对数据集进行验证,查看模型在验证数据上面的效果,此处的评价指标为准确率。
evaluator = Evaluator(network=model, eval_dataset=dataset_test, metrics=metric)
evaluator.run(tgt_columns="labels")
- 1
- 2
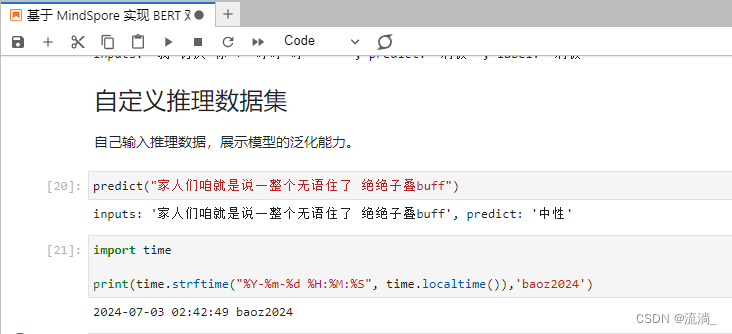
- 模型推理
遍历推理数据集,将结果与标签进行统一展示。
def predict(text, label=None):
label_map = {0: "消极", 1: "中性", 2: "积极"}
text_tokenized = Tensor([tokenizer(text).input_ids])
logits = model(text_tokenized)
predict_label = logits[0].asnumpy().argmax()
info = f"inputs: '{text}', predict: '{label_map[predict_label]}'"
if label is not None:
info += f" , label: '{label_map[label]}'"
print(info)
from mindspore import Tensor
for label, text in dataset_infer:
predict(text, label)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4.小结
到了应用实践阶段学习的目标就是解决实际的问题了。本章节学习的内容是BERT模型的学习和使用。实际上与BERT模型相关的理论知识是比较多的,比如Transformer架构、词嵌入、位置嵌入、分割嵌入、注意力模型等。本章的代码只是为了学习如何利用mindspore来实现基于BERT的训练和分析预测,更多的是偏重于编码层面的学习。对于理论基础则需要查看相关书籍、文章来学习。
以上是第10天的学习内容,附上今日打卡记录: