
- 1CSS中的伪类,伪元素_css伪类
- 2让android支持https访问银联后台,测试成功
- 3标题:探索大数据的无尽可能 - "卜算子·大数据" 开源教程
- 4react组件的componentDidMount、componentWillUnmount与DOM节点渲染的先后顺序_componentdidunmount
- 5伪元素写竖线_CSS的伪类和伪元素
- 6NLP+VS︱深度学习数据集标注工具、图像语料数据库、实验室搜索ing..._图像处理语料库
- 7【小知识】CVPR会议_cvprworkshop和cvpr一样吗
- 8【腾讯云 HAI域探秘】基于高性能应用服务器HAI部署的 ChatGLM2-6B模型,我开发了AI办公助手,公司行政小姐姐用了都说好!_腾讯云部署chatglm大模型
- 9Flink-CDC解析(第47天)
- 10人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载_数据挖掘数据集下载
PostgreSQL教程(八):SQL语言(一)之数据定义_pg数据库 如何定义sql参数
赞
踩
一、表基础
关系型数据库中的一个表非常像纸上的一张表:它由行和列组成。列的数量和顺序是固定的,并且每一列拥有一个名字。行的数目是变化的,它反映了在一个给定时刻表中存储的数据量。SQL并不保证表中行的顺序。当一个表被读取时,表中的行将以非特定顺序出现,除非明确地指定需要排序。这些将在后续章节中介绍。此外,SQL不会为行分配唯一的标识符,因此在一个表中可能会存在一些完全相同的行。这是SQL之下的数学模型导致的结果,但并不是所期望的。稍后在本章中我们将看到如何处理这种问题。
每一列都有一个数据类型。数据类型约束着一组可以分配给列的可能值,并且它为列中存储的数据赋予了语义,这样它可以用于计算。例如,一个被声明为数字类型的列将不会接受任何文本串,而存储在这样一列中的数据可以用来进行数学计算。反过来,一个被声明为字符串类型的列将接受几乎任何一种的数据,它可以进行如字符串连接的操作但不允许进行数学计算。
PostgreSQL包括了相当多的内建数据类型,可以适用于很多应用。用户也可以定义他们自己的数据类型。大部分内建数据类型有着显而易见的名称和语义,所以我们将它们的详细解释放在第 8 章中。一些常用的数据类型是:用于整数的integer;可以用于分数的numeric;用于字符串的text,用于日期的date,用于一天内时间的time以及可以同时包含日期和时间的timestamp。
要创建一个表,我们要用到CREATE TABLE命令。在这个命令中 我们需要为新表至少指定一个名字、列的名字及数据类型。例如:
- CREATE TABLE my_first_table (
- first_column text,
- second_column integer
- );
这将创建一个名为my_first_table的表,它拥有两个列。第一个列名为first_column且数据类型为text;第二个列名为second_column且数据类型为integer。表和列的名字遵循教程(五)中解释的标识符语法。类型名称通常也是标识符,但是也有些例外。注意列的列表由逗号分隔并被圆括号包围。
当然,前面的例子是非常不自然的。通常,我们为表和列赋予的名称都会表明它们存储着什么类别的数据。因此让我们再看一个更现实的例子:
- CREATE TABLE products (
- product_no integer,
- name text,
- price numeric
- );
(numeric类型能够存储小数部分,典型的例子是金额。)
NOTES:
当我们创建很多相关的表时,最好为表和列选择一致的命名模式。例如,一种选择是用单数或复数名词作为表名,每一种都受到一些理论家支持。
一个表能够拥有的列的数据是有限的,根据列的类型,这个限制介于250和1600之间。但是,极少会定义一个接近这个限制的表,即便有也是一个值的商榷的设计。
如果我们不再需要一个表,我们可以通过使用DROP TABLE命令来移除它。例如:
- DROP TABLE my_first_table;
- DROP TABLE products;
尝试移除一个不存在的表会引起错误。然而,在SQL脚本中在创建每个表之前无条件地尝试移除它的做法是很常见的,即使发生错误也会忽略之,因此这样的脚本可以在表存在和不存在时都工作得很好(如果你喜欢,可以使用DROP TABLE IF EXISTS变体来防止出现错误消息,但这并非标准SQL)。
如果我们需要修改一个已经存在的表,请参考本章稍后的第五节。
利用到目前为止所讨论的工具,我们可以创建一个全功能的表。本章的后续部分将集中于为表定义增加特性来保证数据完整性、安全性或方便。如果你希望现在就去填充你的表,你可以跳过这些直接去后续章节。
二、默认值
一个列可以被分配一个默认值。当一个新行被创建且没有为某些列指定值时,这些列将会被它们相应的默认值填充。一个数据操纵命令也可以显式地要求一个列被置为它的默认值,而不需要知道这个值到底是什么(数据操纵命令详见后续章节)。
如果没有显式指定默认值,则默认值是空值。这是合理的,因为空值表示未知数据。
在一个表定义中,默认值被列在列的数据类型之后。例如:
- CREATE TABLE products (
- product_no integer,
- name text,
- price numeric DEFAULT 9.99
- );
默认值可以是一个表达式,它将在任何需要插入默认值的时候被实时计算(不是表创建时)。一个常见的例子是为一个timestamp列指定默认值为CURRENT_TIMESTAMP,这样它将得到行被插入时的时间。另一个常见的例子是为每一行生成一个“序列号” 。这在PostgreSQL可以按照如下方式实现:
- CREATE TABLE products (
- product_no integer DEFAULT nextval('products_product_no_seq'),
- ...
- );
这里nextval()函数从一个序列对象递增并返回新值。还有一种特别的速写:
- CREATE TABLE products (
- product_no SERIAL,
- ...
- );
SERIAL速写将在后续章节中进一步讨论。
三、约束
数据类型是一种限制能够存储在表中数据类别的方法。但是对于很多应用来说,它们提供的约束太粗糙。例如,一个包含产品价格的列应该只接受正值。但是没有任何一种标准数据类型只接受正值。另一个问题是我们可能需要根据其他列或行来约束一个列中的数据。例如,在一个包含产品信息的表中,对于每个产品编号应该只有一行。
到目前为止,SQL允许我们在列和表上定义约束。约束让我们能够根据我们的愿望来控制表中的数据。如果一个用户试图在一个列中保存违反一个约束的数据,一个错误会被抛出。即便是这个值来自于默认值定义,这个规则也同样适用。
3.1 检查约束
一个检查约束是最普通的约束类型。它允许我们指定一个特定列中的值必须要满足一个布尔表达式。例如,为了要求正值的产品价格,我们可以使用:
- CREATE TABLE products (
- product_no integer,
- name text,
- price numeric CHECK (price > 0)
- );
如你所见,约束定义就和默认值定义一样跟在数据类型之后。默认值和约束之间的顺序没有影响。一个检查约束有关键字CHECK以及其后的包围在圆括号中的表达式组成。检查约束表达式应该涉及到被约束的列,否则该约束也没什么实际意义。
我们也可以给与约束一个独立的名称。这会使得错误消息更为清晰,同时也允许我们在需要更改约束时能引用它。语法为:
- CREATE TABLE products (
- product_no integer,
- name text,
- price numeric CONSTRAINT positive_price CHECK (price > 0)
- );
要指定一个命名的约束,请在约束名称标识符前使用关键词CONSTRAINT,然后把约束定义放在标识符之后(如果没有以这种方式指定一个约束名称,系统将会为我们选择一个)。
一个检查约束也可以引用多个列。例如我们存储一个普通价格和一个打折后的价格,而我们希望保证打折后的价格低于普通价格:
- CREATE TABLE products (
- product_no integer,
- name text,
- price numeric CHECK (price > 0),
- discounted_price numeric CHECK (discounted_price > 0),
- CHECK (price > discounted_price)
- );
前两个约束看起来很相似。第三个则使用了一种新语法。它并没有依附在一个特定的列,而是作为一个独立的项出现在逗号分隔的列列表中。列定义和这种约束定义可以以混合的顺序出现在列表中。
我们将前两个约束称为列约束,而第三个约束为表约束,因为它独立于任何一个列定义。列约束也可以写成表约束,但反过来不行,因为一个列约束只能引用它所依附的那一个列(PostgreSQL并不强制要求这个规则,但是如果我们希望表定义能够在其他数据库系统中工作,那就应该遵循它)。上述例子也可以写成:
- CREATE TABLE products (
- product_no integer,
- name text,
- price numeric,
- CHECK (price > 0),
- discounted_price numeric,
- CHECK (discounted_price > 0),
- CHECK (price > discounted_price)
- );
甚至是:
- CREATE TABLE products (
- product_no integer,
- name text,
- price numeric CHECK (price > 0),
- discounted_price numeric,
- CHECK (discounted_price > 0 AND price > discounted_price)
- );
这只是口味的问题。
表约束也可以用列约束相同的方法来指定名称:
- CREATE TABLE products (
- product_no integer,
- name text,
- price numeric,
- CHECK (price > 0),
- discounted_price numeric,
- CHECK (discounted_price > 0),
- CONSTRAINT valid_discount CHECK (price > discounted_price)
- );
需要注意的是,一个检查约束在其检查表达式值为真或空值时被满足。因为当任何操作数为空时大部分表达式将计算为空值,所以它们不会阻止被约束列中的空值。为了保证一个列不包含空值,可以使用下一节中的非空约束。
3.2 非空约束
一个非空约束仅仅指定一个列中不会有空值。语法例子:
- CREATE TABLE products (
- product_no integer NOT NULL,
- name text NOT NULL,
- price numeric
- );
一个非空约束总是被写成一个列约束。一个非空约束等价于创建一个检查约束CHECK (,但在PostgreSQL中创建一个显式的非空约束更高效。这种方式创建的非空约束的缺点是我们无法为它给予一个显式的名称。column_name IS NOT NULL)
当然,一个列可以有多于一个的约束,只需要将这些约束一个接一个写出:
- CREATE TABLE products (
- product_no integer NOT NULL,
- name text NOT NULL,
- price numeric NOT NULL CHECK (price > 0)
- );
约束的顺序没有关系,因为并不需要决定约束被检查的顺序。
NOT NULL约束有一个相反的情况:NULL约束。这并不意味着该列必须为空,进而肯定是无用的。相反,它仅仅选择了列可能为空的默认行为。SQL标准中并不存在NULL约束,因此它不能被用于可移植的应用中(PostgreSQL中加入它是为了和某些其他数据库系统兼容)。但是某些用户喜欢它,因为它使得在一个脚本文件中可以很容易的进行约束切换。例如,初始时我们可以:
- CREATE TABLE products (
- product_no integer NULL,
- name text NULL,
- price numeric NULL
- );
然后可以在需要的地方插入NOT关键词。
NOTES:
在大部分数据库中多数列应该被标记为非空。
3.3 唯一约束
唯一约束保证在一列中或者一组列中保存的数据在表中所有行间是唯一的。写成一个列约束的语法是:
- CREATE TABLE products (
- product_no integer UNIQUE,
- name text,
- price numeric
- );
写成一个表约束的语法是:
- CREATE TABLE products (
- product_no integer,
- name text,
- price numeric,
- UNIQUE (product_no)
- );
要为一组列定义一个唯一约束,把它写作一个表级约束,列名用逗号分隔:
- CREATE TABLE example (
- a integer,
- b integer,
- c integer,
- UNIQUE (a, c)
- );
这指定这些列的组合值在整个表的范围内是唯一的,但其中任意一列的值并不需要是(一般也不是)唯一的。
我们可以通常的方式为一个唯一索引命名:
- CREATE TABLE products (
- product_no integer CONSTRAINT must_be_different UNIQUE,
- name text,
- price numeric
- );
增加一个唯一约束会在约束中列出的列或列组上自动创建一个唯一B-tree索引。只覆盖某些行的唯一性限制不能被写为一个唯一约束,但可以通过创建一个唯一的部分索引来强制这种限制。
通常,如果表中有超过一行在约束所包括列上的值相同,将会违反唯一约束。但是在这种比较中,两个空值被认为是不同的。这意味着即便存在一个唯一约束,也可以存储多个在至少一个被约束列中包含空值的行。这种行为符合SQL标准,但我们听说一些其他SQL数据库可能不遵循这个规则。所以在开发需要可移植的应用时应注意这一点。
3.4 主键
一个主键约束表示可以用作表中行的唯一标识符的一个列或者一组列。这要求那些值都是唯一的并且非空。因此,下面的两个表定义接受相同的数据:
- CREATE TABLE products (
- product_no integer UNIQUE NOT NULL,
- name text,
- price numeric
- );
- CREATE TABLE products (
- product_no integer PRIMARY KEY,
- name text,
- price numeric
- );
主键也可以包含多于一个列,其语法和唯一约束相似:
- CREATE TABLE example (
- a integer,
- b integer,
- c integer,
- PRIMARY KEY (a, c)
- );
增加一个主键将自动在主键中列出的列或列组上创建一个唯一B-tree索引。并且会强制这些列被标记为NOT NULL。
一个表最多只能有一个主键(可以有任意数量的唯一和非空约束,它们可以达到和主键几乎一样的功能,但只能有一个被标识为主键)。关系数据库理论要求每一个表都要有一个主键。但PostgreSQL中并未强制要求这一点,但是最好能够遵循它。
主键对于文档和客户端应用都是有用的。例如,一个允许修改行值的 GUI 应用可能需要知道一个表的主键,以便能唯一地标识行。如果定义了主键,数据库系统也有多种方法来利用主键。例如,主键定义了外键要引用的默认目标列。
3.5 外键
一个外键约束指定一列(或一组列)中的值必须匹配出现在另一个表中某些行的值。我们说这维持了两个关联表之间的引用完整性。
例如我们有一个使用过多次的产品表:
- CREATE TABLE products (
- product_no integer PRIMARY KEY,
- name text,
- price numeric
- );
让我们假设我们还有一个存储这些产品订单的表。我们希望保证订单表中只包含真正存在的产品的订单。因此我们在订单表中定义一个引用产品表的外键约束:
- CREATE TABLE orders (
- order_id integer PRIMARY KEY,
- product_no integer REFERENCES products (product_no),
- quantity integer
- );
现在就不可能创建包含不存在于产品表中的product_no值(非空)的订单。
我们说在这种情况下,订单表是引用表而产品表是被引用表。相应地,也有引用和被引用列的说法。
我们也可以把上述命令简写为:
- CREATE TABLE orders (
- order_id integer PRIMARY KEY,
- product_no integer REFERENCES products,
- quantity integer
- );
因为如果缺少列的列表,则被引用表的主键将被用作被引用列。
一个外键也可以约束和引用一组列。照例,它需要被写成表约束的形式。下面是一个例子:
- CREATE TABLE t1 (
- a integer PRIMARY KEY,
- b integer,
- c integer,
- FOREIGN KEY (b, c) REFERENCES other_table (c1, c2)
- );
当然,被约束列的数量和类型应该匹配被引用列的数量和类型。
按照前面的方式,我们可以为一个外键约束命名。
一个表可以有超过一个的外键约束。这被用于实现表之间的多对多关系。例如我们有关于产品和订单的表,但我们现在希望一个订单能包含多种产品(这在上面的结构中是不允许的)。我们可以使用这种表结构:
- CREATE TABLE products (
- product_no integer PRIMARY KEY,
- name text,
- price numeric
- );
-
- CREATE TABLE orders (
- order_id integer PRIMARY KEY,
- shipping_address text,
- ...
- );
-
- CREATE TABLE order_items (
- product_no integer REFERENCES products,
- order_id integer REFERENCES orders,
- quantity integer,
- PRIMARY KEY (product_no, order_id)
- );

注意在最后一个表中主键和外键之间有重叠。
我们知道外键不允许创建与任何产品都不相关的订单。但如果一个产品在一个引用它的订单创建之后被移除会发生什么?SQL允许我们处理这种情况。直观上,我们有几种选项:
-
不允许删除一个被引用的产品
-
同时也删除引用产品的订单
-
其他?
为了说明这些,让我们在上面的多对多关系例子中实现下面的策略:当某人希望移除一个仍然被一个订单引用(通过order_items)的产品时 ,我们组织它。如果某人移除一个订单,订单项也同时被移除:
- CREATE TABLE products (
- product_no integer PRIMARY KEY,
- name text,
- price numeric
- );
-
- CREATE TABLE orders (
- order_id integer PRIMARY KEY,
- shipping_address text,
- ...
- );
-
- CREATE TABLE order_items (
- product_no integer REFERENCES products ON DELETE RESTRICT,
- order_id integer REFERENCES orders ON DELETE CASCADE,
- quantity integer,
- PRIMARY KEY (product_no, order_id)
- );
限制删除或者级联删除是两种最常见的选项。
RESTRICT阻止删除一个被引用的行。NO ACTION表示在约束被检察时如果有任何引用行存在,则会抛出一个错误,这是我们没有指定任何东西时的默认行为(这两种选择的本质不同在于NO ACTION允许检查被推迟到事务的最后,而RESTRICT则不会)。CASCADE指定当一个被引用行被删除后,引用它的行也应该被自动删除。- 还有其他两种选项:
SET NULL和SET DEFAULT。这些将导致在被引用行被删除后,引用行中的引用列被置为空值或它们的默认值。注意这些并不会是我们免于遵守任何约束。例如,如果一个动作指定了SET DEFAULT,但是默认值不满足外键约束,操作将会失败。
与ON DELETE相似,同样有ON UPDATE可以用在一个被引用列被修改(更新)的情况,可选的动作相同。在这种情况下,CASCADE意味着被引用列的更新值应该被复制到引用行中。
正常情况下,如果一个引用行的任意一个引用列都为空,则它不需要满足外键约束。如果在外键定义中加入了MATCH FULL,一个引用行只有在它的所有引用列为空时才不需要满足外键约束(因此空和非空值的混合肯定会导致MATCH FULL约束失败)。如果不希望引用行能够避开外键约束,将引用行声明为NOT NULL。
一个外键所引用的列必须是一个主键或者被唯一约束所限制。这意味着被引用列总是拥有一个索引(位于主键或唯一约束之下的索引),因此在其上进行的一个引用行是否匹配的检查将会很高效。由于从被引用表中DELETE一行或者UPDATE一个被引用列将要求对引用表进行扫描以得到匹配旧值的行,在引用列上建立合适的索引也会大有益处。由于这种做法并不是必须的,而且创建索引也有很多种选择,所以外键约束的定义并不会自动在引用列上创建索引。
更多关于更新和删除数据的信息请见后续章节。外键约束的语法描述请参考CREATE TABLE。
3.6 排他约束
排他约束保证如果将任何两行的指定列或表达式使用指定操作符进行比较,至少其中一个操作符比较将会返回否或空值。语法是:
- CREATE TABLE circles (
- c circle,
- EXCLUDE USING gist (c WITH &&)
- );
详见CREATE TABLE ... CONSTRAINT ... EXCLUDE。
增加一个排他约束将在约束声明所指定的类型上自动创建索引。
四、系统列
每一个表都拥有一些由系统隐式定义的系统列。因此,这些列的名字不能像用户定义的列一样使用(注意这种限制与名称是否为关键词没有关系,即便用引号限定一个名称也无法绕过这种限制)。 事实上用户不需要关心这些列,只需要知道它们存在即可。
oid一行的对象标识符(对象ID)。该列只有在表使用WITH OIDS创建时或者default_with_oids配置变量被设置时才存在。该列的类型为oid(与列名一致)。tableoid包含这一行的表的OID。该列是特别为从继承层次中选择的查询而准备,因为如果没有它将很难知道一行来自于哪个表。tableoid可以与pg_class的oid列进行连接来获得表的名称。xmin插入该行版本的事务身份(事务ID)。一个行版本是一个行的一个特别版本,对一个逻辑行的每一次更新都将创建一个新的行版本。cmin插入事务中的命令标识符(从0开始)。xmax删除事务的身份(事务ID),对于未删除的行版本为0。对于一个可见的行版本,该列值也可能为非零。这通常表示删除事务还没有提交,或者一个删除尝试被回滚。cmax删除事务中的命令标识符,或者为0。ctid行版本在其表中的物理位置。注意尽管ctid可以被用来非常快速地定位行版本,但是一个行的ctid会在被更新或者被VACUUM FULL移动时改变。因此,ctid不能作为一个长期行标识符。OID或者最好是一个用户定义的序列号才应该被用来标识逻辑行。
OID是32位量,它从一个服务于整个集簇的计数器分配而来。在一个大型的或者历时长久的数据库中,该计数器有可能会出现绕回。因此,不要总是假设OID是唯一的,除非你采取了措施来保证。如果需要在一个表中标识行,推荐使用一个序列生成器。然而,OID也可以被使用,但是是要采取一些额外的预防措施:
-
如果要将OID用来标识行,应该在OID列上创建一个唯一约束。当这样一个唯一约束(或唯一索引)存在时,系统会注意不生成匹配现有行的OID(当然,这只有在表的航数目少于232(40亿)时才成立。并且在实践中表的尺寸最好远比这个值小,否则将会牺牲性能)。
-
绝不要认为OID在表之间也是唯一的,使用
tableoid和行OID的组合来作为数据库范围内的标识符。 -
当然,问题中的表都必须是用
WITH OIDS创建。在PostgreSQL 8.1中,WITHOUT OIDS是默认形式。
事务标识符也是32位量。在一个历时长久的数据库中事务ID同样会绕回。但如果采取适当的维护过程,这不会是一个致命的问题。但是,长期(超过10亿个事务)依赖事务ID的唯一性是不明智的。
命令标识符也是32位量。这对一个事务中包含的SQL命令设置了一个硬极限: 232(40亿)。在实践中,该限制并不是问题 — 注意该限制只是针对SQL命令的数目而不是被处理的行数。同样,只有真正 修改了数据库内容的命令才会消耗一个命令标识符。
五、修改表
当我们已经创建了一个表并意识到犯了一个错误或者应用需求发生改变时,我们可以移除表并重新创建它。但如果表中已经被填充数据或者被其他数据库对象引用(例如有一个外键约束),这种做法就显得很不方便。因此,PostgreSQL提供了一组命令来对已有的表进行修改。注意这和修改表中所包含的数据是不同的,这里要做的是对表的定义或者说结构进行修改。
利用这些命令,我们可以:
-
增加列
-
移除列
-
增加约束
-
移除约束
-
修改默认值
-
修改列数据类型
-
重命名列
-
重命名表
所有这些动作都由ALTER TABLE命令执行,其参考页面中包含更详细的信息。
5.1 增加列
要增加一个列,可以使用这样的命令:
ALTER TABLE products ADD COLUMN description text;新列将被默认值所填充(如果没有指定DEFAULT子句,则会填充空值)。
也可以同时为列定义约束,语法:
ALTER TABLE products ADD COLUMN description text CHECK (description <> '');事实上CREATE TABLE中关于一列的描述都可以应用在这里。记住不管怎样,默认值必须满足给定的约束,否则ADD将会失败。也可以先将新列正确地填充好,然后再增加约束(见后文)。
TIPS:
增加一个带默认值的列需要更新表中的每一行(来存储新列值)。然而,如果不指定默认值,PostgreSQL可以避免物理更新。因此如果我们准备向列中填充的值大多是非默认值,最好是增加列的时候不指定默认值,增加列后用UPDATE填充正确的数据并且增加所需要的默认值约束。
5.2 移除列
为了移除一个列,使用如下的命令:
ALTER TABLE products DROP COLUMN description;列中的数据将会消失。涉及到该列的表约束也会被移除。
然而,如果该列被另一个表的外键所引用,PostgreSQL不会安静地移除该约束。我们可以通过增加CASCADE来授权移除任何依赖于被删除列的所有东西:
ALTER TABLE products DROP COLUMN description CASCADE;
5.3 增加约束
为了增加一个约束,可以使用表约束的语法,例如:
- ALTER TABLE products ADD CHECK (name <> '');
- ALTER TABLE products ADD CONSTRAINT some_name UNIQUE (product_no);
- ALTER TABLE products ADD FOREIGN KEY (product_group_id) REFERENCES product_groups;
要增加一个不能写成表约束的非空约束,可使用语法:
ALTER TABLE products ALTER COLUMN product_no SET NOT NULL;该约束会立即被检查,所以表中的数据必须在约束被增加之前就已经符合约束。
5.4 移除约束
为了移除一个约束首先需要知道它的名称。如果在创建时已经给它指定了名称,那么事情就变得很容易。否则约束的名称是由系统生成的,我们必须先找出这个名称。psql的命令 "\d 将会对此有所帮助,其他接口也会提供方法来查看表的细节。因此命令是:表名"
ALTER TABLE products DROP CONSTRAINT some_name;(如果处理的是自动生成的约束名称,如$2,别忘了用双引号使它变成一个合法的标识符。)
和移除一个列相似,如果需要移除一个被某些别的东西依赖的约束,也需要加上CASCADE。一个例子是一个外键约束依赖于被引用列上的一个唯一或者主键约束。
这对除了非空约束之外的所有约束类型都一样有效。为了移除一个非空约束可以用:
ALTER TABLE products ALTER COLUMN product_no DROP NOT NULL;(回忆一下,非空约束是没有名称的,所以不能用第一种方式。)
5.5 更改列的默认值
要为一个列设置一个新默认值,使用命令:
ALTER TABLE products ALTER COLUMN price SET DEFAULT 7.77;注意这不会影响任何表中已经存在的行,它只是为未来的INSERT命令改变了默认值。
要移除任何默认值,使用:
ALTER TABLE products ALTER COLUMN price DROP DEFAULT;这等同于将默认值设置为空值。相应的,试图删除一个未被定义的默认值并不会引发错误,因为默认值已经被隐式地设置为空值。
5.6 修改列的数据类型
为了将一个列转换为一种不同的数据类型,使用如下命令:
ALTER TABLE products ALTER COLUMN price TYPE numeric(10,2);只有当列中的每一个项都能通过一个隐式造型转换为新的类型时该操作才能成功。如果需要一种更复杂的转换,应该加上一个USING子句来指定应该如何把旧值转换为新值。
PostgreSQL将尝试把列的默认值转换为新类型,其他涉及到该列的任何约束也是一样。但是这些转换可能失败或者产生奇特的结果。因此最好在修改类型之前先删除该列上所有的约束,然后在修改完类型后重新加上相应修改过的约束。
5.7 重命令列
要重命名一个列:
ALTER TABLE products RENAME COLUMN product_no TO product_number;5.8 重命名表
要重命名一个表:
ALTER TABLE products RENAME TO items;六、权限
一旦一个对象被创建,它会被分配一个所有者。所有者通常是执行创建语句的角色。对于大部分类型的对象,初始状态下只有所有者(或者超级用户)能够对该对象做任何事情。为了允许其他角色使用它,必须分配权限。
有多种不同的权限:SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE以及USAGE。可以应用于一个特定对象的权限随着对象的类型(表、函数等)而不同。PostgreSQL所支持的不同类型的完整权限信息请参考GRANT。下面的章节将简单介绍如何使用这些权限。
修改或销毁一个对象的权力通常是只有所有者才有的权限。
一个对象可以通过该对象类型相应的ALTER命令来重新分配所有者,例如ALTER TABLE。超级用户总是可以做到这点,普通角色只有同时是对象的当前所有者(或者是拥有角色的一个成员)以及新拥有角色的一个成员时才能做同样的事。
要分配权限,可以使用GRANT命令。例如,如果joe是一个已有角色,而accounts是一个已有表,更新该表的权限可以按如下方式授权:
GRANT UPDATE ON accounts TO joe;
用ALL取代特定权限会把与对象类型相关的所有权限全部授权。
一个特殊的名为PUBLIC的“角色”可以用来向系统中的每一个角色授予一个权限。同时,在数据库中有很多用户时可以设置“组”角色来帮助管理权限。
为了撤销一个权限,使用REVOKE命令:
REVOKE ALL ON accounts FROM PUBLIC;对象拥有者的特殊权限(即执行DROP、GRANT、REVOKE等的权力)总是隐式地属于拥有者,并且不能被授予或撤销。但是对象拥有者可以选择撤销他们自己的普通权限,例如把一个表变得对他们自己和其他人只读。
一般情况下,只有对象拥有者(或者超级用户)可以授予或撤销一个对象上的权限。但是可以在授予权限时使用“with grant option”来允许接收人将权限转授给其他人。如果后来授予选项被撤销,则所有从接收人那里获得的权限(直接或者通过授权链获得)都将被撤销。更多详情请见GRANT和REVOKE参考页。
七、行安全性策略
除可以通过GRANT使用 SQL 标准的 特权系统之外,表还可以具有 行安全性策略,它针对每一个用户限制哪些行可以 被普通的查询返回或者可以被数据修改命令插入、更新或删除。这种 特性也被称为行级安全性。默认情况下,表不具有 任何策略,这样用户根据 SQL 特权系统具有对表的访问特权,对于 查询或更新来说其中所有的行都是平等的。
当在一个表上启用行安全性时(使用 ALTER TABLE ... ENABLE ROW LEVEL SECURITY),所有对该表选择行或者修改行的普通访问都必须被一条 行安全性策略所允许(不过,表的拥有者通常不服从行安全性策略)。如果 表上不存在策略,将使用一条默认的否定策略,即所有的行都不可见或者不能 被修改。应用在整个表上的操作不服从行安全性,例如TRUNCATE和 REFERENCES。
行安全性策略可以针对特定的命令、角色或者两者。一条策略可以被指定为 适用于ALL命令,或者SELECT、 INSERT、UPDATE或者DELETE。 可以为一条给定策略分配多个角色,并且通常的角色成员关系和继承规则也 适用。
要指定哪些行根据一条策略是可见的或者是可修改的,需要一个返回布尔结果 的表达式。对于每一行,在计算任何来自用户查询的条件或函数之前,先会计 算这个表达式(这条规则的唯一例外是leakproof函数, 它们被保证不会泄露信息,优化器可能会选择在行安全性检查之前应用这类 函数)。使该表达式不返回true的行将不会被处理。可以指定 独立的表达式来单独控制哪些行可见以及哪些行被允许修改。策略表达式会作 为查询的一部分运行并且带有运行该查询的用户的特权,但是安全性定义者函数 可以被用来访问对调用用户不可用的数据。
具有BYPASSRLS属性的超级用户和角色在访问一个表时总是 可以绕过行安全性系统。表拥有者通常也能绕过行安全性,不过表拥有者 可以选择用ALTER TABLE ... FORCE ROW LEVEL SECURITY来服从行安全性。
启用和禁用行安全性以及向表增加策略是只有表拥有者具有的特权。
策略的创建可以使用CREATE POLICY命令,策略的修改 可以使用ALTER POLICY命令,而策略的删除可以使用 DROP POLICY命令。要为一个给定表启用或者禁用行 安全性,可以使用ALTER TABLE命令。
每一条策略都有名称并且可以为一个表定义多条策略。由于策略是表相 关的,一个表的每一条策略都必须有一个唯一的名称。不同的表可以拥有 相同名称的策略。
当多条策略适用于一个给定的查询时,会把它们用OR(对宽容性策略,默认的策略类型)或者AND(对限制性策略)组合在一起。这和给定角色拥有它作为成员的所有角色的特权的规则类似。宽容性策略和限制性策略在下文将会进一步讨论。
作为一个简单的例子,这里是如何在account关系上 创建一条策略以允许只有managers角色的成员能访问行, 并且只能访问它们账户的行:
- CREATE TABLE accounts (manager text, company text, contact_email text);
-
- ALTER TABLE accounts ENABLE ROW LEVEL SECURITY;
-
- CREATE POLICY account_managers ON accounts TO managers
- USING (manager = current_user);
上面的策略隐含地提供了一个与其该约束适用于被一个命令选择的行(这样一个经理不能SELECT、UPDATE或者DELETE属于其他经理的已有行)以及被一个命令修改的行(这样属于其他经理的行不能通过INSERT或者UPDATE创建)。
如果没有指定角色或者使用了特殊的用户名PUBLIC, 则该策略适用于系统上所有的用户。要允许所有用户访问users 表中属于他们自己的行,可以使用一条简单的策略:
- CREATE POLICY user_policy ON users
- USING (user_name = current_user);
这个例子的效果和前一个类似。
为了对增加到表中的行使用与可见行不同的策略,可以组合多条策略。这一对策略将允许所有用户查看users表中的所有行,但只能修改他们自己的行:
- CREATE POLICY user_sel_policy ON users
- FOR SELECT
- USING (true);
- CREATE POLICY user_mod_policy ON users
- USING (user_name = current_user);
在一个SELECT命令中,这两条规则被用OR组合在一起,最终的效应就是所有的行都能被选择。在其他命令类型中,只有第二条策略适用,这样其效果就和以前相同。
也可以用ALTER TABLE命令禁用行安全性。禁用行安全性 不会移除定义在表上的任何策略,它们只是被简单地忽略。然后该表中的所有 行都是可见的并且可修改,服从于标准的 SQL 特权系统。
下面是一个较大的例子,它展示了这种特性如何被用于生产环境。表 passwd模拟了一个 Unix 口令文件:
- -- 简单的口令文件例子
- CREATE TABLE passwd (
- user_name text UNIQUE NOT NULL,
- pwhash text,
- uid int PRIMARY KEY,
- gid int NOT NULL,
- real_name text NOT NULL,
- home_phone text,
- extra_info text,
- home_dir text NOT NULL,
- shell text NOT NULL
- );
-
- CREATE ROLE admin; -- 管理员
- CREATE ROLE bob; -- 普通用户
- CREATE ROLE alice; -- 普通用户
-
- -- 填充表
- INSERT INTO passwd VALUES
- ('admin','xxx',0,0,'Admin','111-222-3333',null,'/root','/bin/dash');
- INSERT INTO passwd VALUES
- ('bob','xxx',1,1,'Bob','123-456-7890',null,'/home/bob','/bin/zsh');
- INSERT INTO passwd VALUES
- ('alice','xxx',2,1,'Alice','098-765-4321',null,'/home/alice','/bin/zsh');
-
- -- 确保在表上启用行级安全性
- ALTER TABLE passwd ENABLE ROW LEVEL SECURITY;
-
- -- 创建策略
- -- 管理员能看见所有行并且增加任意行
- CREATE POLICY admin_all ON passwd TO admin USING (true) WITH CHECK (true);
- -- 普通用户可以看见所有行
- CREATE POLICY all_view ON passwd FOR SELECT USING (true);
- -- 普通用户可以更新它们自己的记录,但是限制普通用户可用的 shell
- CREATE POLICY user_mod ON passwd FOR UPDATE
- USING (current_user = user_name)
- WITH CHECK (
- current_user = user_name AND
- shell IN ('/bin/bash','/bin/sh','/bin/dash','/bin/zsh','/bin/tcsh')
- );
-
- -- 允许管理员有所有普通权限
- GRANT SELECT, INSERT, UPDATE, DELETE ON passwd TO admin;
- -- 用户只在公共列上得到选择访问
- GRANT SELECT
- (user_name, uid, gid, real_name, home_phone, extra_info, home_dir, shell)
- ON passwd TO public;
- -- 允许用户更新特定行
- GRANT UPDATE
- (pwhash, real_name, home_phone, extra_info, shell)
- ON passwd TO public;
对于任意安全性设置来说,重要的是测试并确保系统的行为符合预期。 使用上述的例子,下面展示了权限系统工作正确:
- -- admin 可以看到所有的行和域
- postgres=> set role admin;
- SET
- postgres=> table passwd;
- user_name | pwhash | uid | gid | real_name | home_phone | extra_info | home_dir | shell
- -----------+--------+-----+-----+-----------+--------------+------------+-------------+-----------
- admin | xxx | 0 | 0 | Admin | 111-222-3333 | | /root | /bin/dash
- bob | xxx | 1 | 1 | Bob | 123-456-7890 | | /home/bob | /bin/zsh
- alice | xxx | 2 | 1 | Alice | 098-765-4321 | | /home/alice | /bin/zsh
- (3 rows)
-
- -- 测试 Alice 能做什么
- postgres=> set role alice;
- SET
- postgres=> table passwd;
- ERROR: permission denied for relation passwd
- postgres=> select user_name,real_name,home_phone,extra_info,home_dir,shell from passwd;
- user_name | real_name | home_phone | extra_info | home_dir | shell
- -----------+-----------+--------------+------------+-------------+-----------
- admin | Admin | 111-222-3333 | | /root | /bin/dash
- bob | Bob | 123-456-7890 | | /home/bob | /bin/zsh
- alice | Alice | 098-765-4321 | | /home/alice | /bin/zsh
- (3 rows)
-
- postgres=> update passwd set user_name = 'joe';
- ERROR: permission denied for relation passwd
- -- Alice 被允许更改她自己的 real_name,但不能改其他的
- postgres=> update passwd set real_name = 'Alice Doe';
- UPDATE 1
- postgres=> update passwd set real_name = 'John Doe' where user_name = 'admin';
- UPDATE 0
- postgres=> update passwd set shell = '/bin/xx';
- ERROR: new row violates WITH CHECK OPTION for "passwd"
- postgres=> delete from passwd;
- ERROR: permission denied for relation passwd
- postgres=> insert into passwd (user_name) values ('xxx');
- ERROR: permission denied for relation passwd
- -- Alice 可以更改她自己的口令;行级安全性会悄悄地阻止更新其他行
- postgres=> update passwd set pwhash = 'abc';
- UPDATE 1
目前为止所有构建的策略都是宽容性策略,也就是当多条策略都适用时会被适用“OR”布尔操作符组合在一起。而宽容性策略可以被用来仅允许在预计情况中对行的访问,这比将宽容性策略与限制性策略(记录必须通过这类策略并且它们会被“AND”布尔操作符组合起来)组合在一起更简单。在上面的例子之上,我们增加一条限制性策略要求通过一个本地Unix套接字连接过来的管理员访问passwd表的记录:
- CREATE POLICY admin_local_only ON passwd AS RESTRICTIVE TO admin
- USING (pg_catalog.inet_client_addr() IS NULL);
然后,由于这条限制性规则的存在,我们可以看到从网络连接进来的管理员将无法看到任何记录:
- => SELECT current_user;
- current_user
- --------------
- admin
- (1 row)
-
- => select inet_client_addr();
- inet_client_addr
- ------------------
- 127.0.0.1
- (1 row)
-
- => SELECT current_user;
- current_user
- --------------
- admin
- (1 row)
-
- => TABLE passwd;
- user_name | pwhash | uid | gid | real_name | home_phone | extra_info | home_dir | shell
- -----------+--------+-----+-----+-----------+------------+------------+----------+-------
- (0 rows)
-
- => UPDATE passwd set pwhash = NULL;
- UPDATE 0
参照完整性检查(例如唯一或逐渐约束和外键引用)总是会绕过行级安全性以 保证数据完整性得到维护。在开发模式和行级安全性时必须小心避免 “隐通道”通过这类参照完整性检查泄露信息。
在某些环境中确保行安全性没有被应用很重要。例如,在做备份时,如果 行安全性悄悄地导致某些行被从备份中忽略掉,这会是灾难性的。在这类 情况下,你可以设置row_security配置参数为 off。这本身不会绕过行安全性,它所做的是如果任何结果会 被一条策略过滤掉,就会抛出一个错误。然后错误的原因就可以被找到并且 修复。
在上面的例子中,策略表达式只考虑了要被访问的行中的当前值。这是最简 单并且表现最好的情况。如果可能,最好设计行安全性应用以这种方式工作。 如果需要参考其他行或者其他表来做出策略的决定,可以在策略表达式中通过 使用子-SELECT或者包含SELECT的函数 来实现。不过要注意这类访问可能会导致竞争条件,在不小心的情况下这可能 会导致信息泄露。作为一个例子,考虑下面的表设计:
- -- 特权组的定义
- CREATE TABLE groups (group_id int PRIMARY KEY,
- group_name text NOT NULL);
-
- INSERT INTO groups VALUES
- (1, 'low'),
- (2, 'medium'),
- (5, 'high');
-
- GRANT ALL ON groups TO alice; -- alice 是管理员
- GRANT SELECT ON groups TO public;
-
- -- 用户的特权级别的定义
- CREATE TABLE users (user_name text PRIMARY KEY,
- group_id int NOT NULL REFERENCES groups);
-
- INSERT INTO users VALUES
- ('alice', 5),
- ('bob', 2),
- ('mallory', 2);
-
- GRANT ALL ON users TO alice;
- GRANT SELECT ON users TO public;
-
- -- 保存要被保护的信息的表
- CREATE TABLE information (info text,
- group_id int NOT NULL REFERENCES groups);
-
- INSERT INTO information VALUES
- ('barely secret', 1),
- ('slightly secret', 2),
- ('very secret', 5);
-
- ALTER TABLE information ENABLE ROW LEVEL SECURITY;
-
- -- 对于安全性 group_id 大于等于一行的 group_id 的用户,
- -- 这一行应该是可见的/可更新的
- CREATE POLICY fp_s ON information FOR SELECT
- USING (group_id <= (SELECT group_id FROM users WHERE user_name = current_user));
- CREATE POLICY fp_u ON information FOR UPDATE
- USING (group_id <= (SELECT group_id FROM users WHERE user_name = current_user));
-
- -- 我们只依赖于行级安全性来保护信息表
- GRANT ALL ON information TO public;
现在假设alice希望更改“有一点点秘密” 的信息,但是觉得mallory不应该看到该行中的新 内容,因此她这样做:
- BEGIN;
- UPDATE users SET group_id = 1 WHERE user_name = 'mallory';
- UPDATE information SET info = 'secret from mallory' WHERE group_id = 2;
- COMMIT;
这看起来是安全的,没有窗口可供mallory看到 “对 mallory 保密”的字符串。不过,这里有一种 竞争条件。如果mallory正在并行地做:
SELECT * FROM information WHERE group_id = 2 FOR UPDATE;
并且她的事务处于READ COMMITTED模式,她就可能看到 “s对 mallory 保密”的东西。如果她的事务在alice 做完之后就到达信息行,这就会发生。它会阻塞等待 alice的事务提交,然后拜FOR UPDATE子句所赐 取得更新后的行内容。不过,对于来自users的隐式 SELECT,它不会取得一个已更新的行, 因为子-SELECT没有FOR UPDATE,相反 会使用查询开始时取得的快照读取users行。因此, 策略表达式会测试mallory的特权级别的旧值并且允许她看到 被更新的行。
有多种方法能解决这个问题。一种简单的答案是在行安全性策略中的 子-SELECT里使用SELECT ... FOR SHARE。 不过,这要求在被引用表(这里是users)上授予 UPDATE特权给受影响的用户,这可能不是我们想要的( 但是另一条行安全性策略可能被应用来阻止它们实际使用这个特权,或者 子-SELECT可能被嵌入到一个安全性定义者函数中)。 还有,在被引用的表上过多并发地使用行共享锁可能会导致性能问题, 特别是表更新比较频繁时。另一种解决方案(如果被引用表上的更新 不频繁就可行)是在更新被引用表时对它取一个排他锁,这样就没有 并发事务能够检查旧的行值了。或者我们可以在提交对被引用表的更新 之后、在做依赖于新安全性情况的更改之前等待所有并发事务结束。
更多细节请见CREATE POLICY 和ALTER TABLE。
八、模式(schema)
一个PostgreSQL数据库集簇中包含一个或更多命名的数据库。用户和用户组被整个集簇共享,但没有其他数据在数据库之间共享。任何给定客户端连接只能访问在连接中指定的数据库中的数据。
NOTES:
一个集簇的用户并不必拥有访问集簇中每一个数据库的权限。用户名的共享意味着不可能在同一个集簇中出现重名的不同用户,例如两个数据库中都有叫joe的用户。但系统可以被配置为只允许joe访问某些数据库。
一个数据库包含一个或多个命名模式,模式中包含着表。模式还包含其他类型的命名对象,包括数据类型、函数和操作符。相同的对象名称可以被用于不同的模式中二不会出现冲突,例如schema1和myschema都可以包含名为mytable的表。和数据库不同,模式并不是被严格地隔离:一个用户可以访问他们所连接的数据库中的所有模式内的对象,只要他们有足够的权限。
下面是一些使用方案的原因:
-
允许多个用户使用一个数据库并且不会互相干扰。
-
将数据库对象组织成逻辑组以便更容易管理。
-
第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。
模式类似于操作系统层的目录,但是模式不能嵌套。
8.1 创建 模式/schema
要创建一个模式,可使用CREATE SCHEMA命令,并且给出选择的模式名称。例如:
CREATE SCHEMA myschema;
在一个模式中创建或访问对象,需要使用由模式名和表名构成的限定名,模式名和表名之间以点号分隔:
schema.table
在任何需要一个表名的地方都可以这样用,包括表修改命令和后续章节要讨论的数据访问命令(为了简洁我们在这里只谈到表,但是这种方式对其他类型的命名对象同样有效,例如类型和函数)。
事实上,还有更加通用的语法:
database.schema.table
也可以使用,但是目前它只是在形式上与SQL标准兼容。如果我们写一个数据库名称,它必须是我们正在连接的数据库。
因此,如果要在一个新模式中创建一个表,可用:
- CREATE TABLE myschema.mytable (
- ...
- );
要删除一个为空的模式(其中的所有对象已经被删除),可用:
DROP SCHEMA myschema;
要删除一个模式以及其中包含的所有对象,可用:
DROP SCHEMA myschema CASCADE;有关于此的更一般的机制请参见 十三节。
我们常常希望创建一个由其他人所拥有的模式(因为这是将用户动作限制在良定义的名字空间中的方法之一)。其语法是:
CREATE SCHEMA schema_name AUTHORIZATION user_name;我们甚至可以省略模式名称,在此种情况下模式名称将会使用用户名,参见8.6。
以pg_开头的模式名被保留用于系统目的,所以不能被用户所创建。
8.2 公共模式
在前面的小节中,我们创建的表都没有指定任何模式名称。默认情况下这些表(以及其他对象)会自动的被放入一个名为“public”的模式中。任何新数据库都包含这样一个模式。因此,下面的命令是等效的:
- CREATE TABLE products ( ... );
-
- CREATE TABLE public.products ( ... );
8.3 模式搜索路径
限定名写起来很冗长,通常最好不要把一个特定模式名拉到应用中。因此,表名通常被使用非限定名来引用,它只由表名构成。系统将沿着一条搜索路径来决定该名称指的是哪个表,搜索路径是一个进行查看的模式列表。 搜索路径中第一个匹配的表将被认为是所需要的。如果在搜索路径中没有任何匹配,即使在数据库的其他模式中存在匹配的表名也将会报告一个错误。
在不同方案中创建命名相同的对象的能力使得编写每次都准确引用相同对象的查询变得复杂。这也使得用户有可能更改其他用户查询的行为,不管是出于恶意还是无意。由于未经限定的名称在查询中以及在PostgreSQL内部的广泛使用,在search_path中增加一个方案实际上是信任所有在该方案中具有CREATE特权的用户。在你运行一个普通查询时,恶意用户可以在你的搜索路径中的以方案中创建能够夺取控制权并且执行任意SQL函数的对象,而这些事情就像是你在执行一样。
搜索路径中的第一个模式被称为当前模式。除了是第一个被搜索的模式外,如果CREATE TABLE命令没有指定模式名,它将是新创建表所在的模式。
SHOW search_path;
在默认设置下这将返回:

第一个元素说明一个和当前用户同名的模式会被搜索。如果不存在这个模式,该项将被忽略。第二个元素指向我们已经见过的公共模式。
搜索路径中的第一个模式是创建新对象的默认存储位置。这就是默认情况下对象会被创建在公共模式中的原因。当对象在任何其他没有模式限定的环境中被引用(表修改、数据修改或查询命令)时,搜索路径将被遍历直到一个匹配对象被找到。因此,在默认配置中,任何非限定访问将只能指向公共模式。
要把新模式放在搜索路径中,我们可以使用:
SET search_path TO myschema,public;(我们在这里省略了$user,因为我们并不立即需要它)。然后我们可以删除该表而无需使用方案进行限定:
DROP TABLE mytable;
同样,由于myschema是路径中的第一个元素,新对象会被默认创建在其中。
我们也可以这样写:
SET search_path TO myschema;
这样我们在没有显式限定时再也不必去访问公共模式了。公共模式没有什么特别之处,它只是默认存在而已,它也可以被删除。
搜索路径对于数据类型名称、函数名称和操作符名称的作用与表名一样。数据类型和函数名称可以使用和表名完全相同的限定方式。如果我们需要在一个表达式中写一个限定的操作符名称,我们必须写成一种特殊的形式:
OPERATOR(schema.operator)
这是为了避免句法歧义。例如:
SELECT 3 OPERATOR(pg_catalog.+) 4;
实际上我们通常都会依赖于搜索路径来查找操作符,因此没有必要去写如此“丑陋”的东西。
8.4 模式和权限
默认情况下,用户不能访问不属于他们的方案中的任何对象。要允许这种行为,模式的拥有者必须在该模式上授予USAGE权限。为了允许用户使用方案中的对象,可能还需要根据对象授予额外的权限。
一个用户也可以被允许在其他某人的模式中创建对象。要允许这种行为,模式上的CREATE权限必须被授予。注意在默认情况下,所有人都拥有在public模式上的CREATE和USAGE权限。这使得用户能够连接到一个给定数据库并在它的public模式中创建对象。回收这一特权的使用模式调用:
REVOKE CREATE ON SCHEMA public FROM PUBLIC;(第一个“public”是方案,第二个“public”指的是“每一个用户”。第一种是一个标识符,第二种是一个关键词,所以两者的大小写不同。)
8.5 系统目录模式
除public和用户创建的模式之外,每一个数据库还包括一个pg_catalog模式,它包含了系统表和所有内建的数据类型、函数以及操作符。pg_catalog总是搜索路径的一个有效部分。如果没有在路径中显式地包括该模式,它将在路径中的模式之前被搜索。这保证了内建的名称总是能被找到。然而,如果我们希望用用户定义的名称重载内建的名称,可以显式的将pg_catalog放在搜索路径的末尾。
由于系统表名称以pg_开头,最好还是避免使用这样的名称,以避免和未来新版本中 可能出现的系统表名发生冲突。系统表将继续采用以pg_开头的方式,这样它们不会 与非限制的用户表名称冲突。
8.6 使用模式
有一些默认配置可以轻易支持的使用模式,当数据库用户不信任其他数据库用户时,使用其中之一就足够了:
-
将普通用户约束在其私有的方案中。要实现这一点,发出
REVOKE CREATE ON SCHEMA public FROM PUBLIC,并且为每一个用户创建一个用其用户名命名的方案。如果受影响的用户在做这些之前就已经登入,应该对与方案pg_catalog中对象命名相似的对象审计public方案。回忆一下,默认的搜索路径开始于$user,它会被解析为用户名。因此,如果每个用户都有一个单独的方案,默认他们访问他们自己的方案。 -
使用
ALTER ROLE从每个用户的默认搜索路径中去掉public方案。每个人都保留着在public方案中创建对象的能力,但是只有限定的名称才能选择那些对象。虽然限定的表引用是好的,但对public方案中函数的调用将是不安全或不可靠的。此外,持有userSET search_path = "$user"CREATEROLE特权的用户可以撤销这种设置并且以依赖于这种设置的用户的身份发出任意查询。如果你在public方案中创建方案或扩展或者把CREATEROLE授予给不能正当使用这种几乎是超级用户能力的用户,应该使用第一种模式。 -
从postgresql.conf中的
search_path去掉public方案。接下来的用户体验符合前一种模式。除了上一中模式对函数和CREATEROLE的暗示之外,这种模式像CREATEROLE那样信任数据库拥有者。如果你在public方案中创建函数或扩展,或者向不能正当使用几乎是超级用户访问的用户授予CREATEROLE特权、CREATEDB特权或数据库的拥有关系,请使用第一种模式。 -
保持默认。所有用户都隐式地访问public模式。这模拟了方案根本不可用的情况,可以用于从没有方案的世界平滑过渡。不过,任何用户都能以任何无法自我保护的用户的身份发出任意查询。只有当数据库仅有单个用户或者少数相互信任的用户时,这种模式才可接受。
对于任何一种模式,为了安装共享的应用(所有人都要用其中的表,第三方提供的额外函数,等等),可把它们放在单独的方案中。记住授予适当的特权以允许其他用户访问它们。然后用户可以通过以方案名限定名称的方式来引用这些额外的对象,或者他们可以把额外的方案放在自己的搜索路径中。
8.7 可移植性
在SQL标准中,在由不同用户拥有的同一个模式中的对象是不存在的。此外,某些实现不允许创建与拥有者名称不同名的模式。事实上,在那些仅实现了标准中基本模式支持的数据库中,模式和用户的概念是等同的。因此,很多用户认为限定名称实际上是由user_name.table_name
同样,在SQL标准中也没有public模式的概念。为了最大限度的与标准一致,我们不应使用(甚至是删除)public模式。
当然,某些SQL数据库系统可能根本没有实现方案,或者提供允许跨数据库访问的名字空间。如果需要使用这样一些系统,最好不要使用方案。
九、继承
PostgreSQL实现了表继承,这对数据库设计者来说是一种有用的工具(SQL:1999及其后的版本定义了一种类型继承特性,但和这里介绍的继承有很大的不同)。
让我们从一个例子开始:假设我们要为城市建立一个数据模型。每一个州有很多城市,但是只有一个首府。我们希望能够快速地检索任何特定州的首府城市。这可以通过创建两个表来实现:一个用于州首府,另一个用于不是首府的城市。然而,当我们想要查看一个城市的数据(不管它是不是一个首府)时会发生什么?继承特性将有助于解决这个问题。我们可以将capitals表定义为继承自cities表:
INHERITS
- CREATE TABLE cities (
- name text,
- population float,
- altitude int -- in feet
- );
-
- CREATE TABLE capitals (
- state char(2)
- ) INHERITS (cities);
在这种情况下,capitals表继承了它的父表cities的所有列。州首府还有一个额外的列state用来表示它所属的州。
在PostgreSQL中,一个表可以从0个或者多个其他表继承,而对一个表的查询则可以引用一个表的所有行或者该表的所有行加上它所有的后代表。默认情况是后一种行为。例如,下面的查询将查找所有海拔高于500尺的城市的名称,包括州首府:
- SELECT name, altitude
- FROM cities
- WHERE altitude > 500;
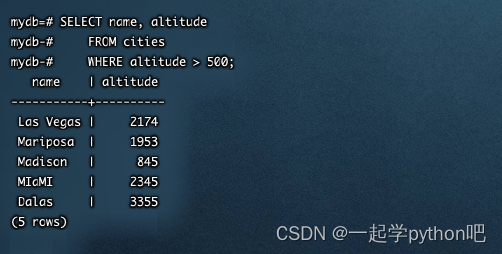
在另一方面,下面的查询将找到海拔超过500尺且不是州首府的所有城市:
- SELECT name, altitude
- FROM ONLY cities
- WHERE altitude > 500;

这里的ONLY关键词指示查询只被应用于cities上,而其他在继承层次中位于cities之下的其他表都不会被该查询涉及。很多我们已经讨论过的命令(如SELECT、UPDATE和DELETE)都支持ONLY关键词。
我们也可以在表名后写上一个*来显式地将后代表包括在查询范围内:
- SELECT name, altitude
- FROM cities*
- WHERE altitude > 500;
写*不是必需的,因为这种行为总是默认的。不过,为了兼容可以修改默认值的较老版本,现在仍然支持这种语法。
在某些情况下,我们可能希望知道一个特定行来自于哪个表。每个表中的系统列tableoid可以告诉我们行来自于哪个表:
- SELECT c.tableoid, c.name, c.altitude
- FROM cities c
- WHERE c.altitude > 500;
将会返回:

(如果重新生成这个结果,可能会得到不同的OID数字。)通过与pg_class进行连接可以看到实际的表名:
- SELECT c.tableoid::regclass, c.name, c.altitude
- FROM cities c
- WHERE c.altitude > 500;

继承不会自动地将来自INSERT或COPY命令的数据传播到继承层次中的其他表中。在我们的例子中,下面的INSERT语句将会失败:
- INSERT INTO cities (name, population, altitude, state)
- VALUES ('Albany', NULL, NULL, 'NY');
我们也许希望数据能被以某种方式被引入到capitals表中,但是这不会发生:INSERT总是向指定的表中插入。在某些情况下,可以通过使用一个规则(见后续章节)来将插入动作重定向。但是这对上面的情况并没有帮助,因为cities表根本就不包含state列,因而这个命令将在触发规则之前就被拒绝。
父表上的所有检查约束和非空约束都将自动被它的后代所继承,除非显式地指定了NO INHERIT子句。其他类型的约束(唯一、主键和外键约束)则不会被继承。
一个表可以从超过一个的父表继承,在这种情况下它拥有父表们所定义的列的并集。任何定义在子表上的列也会被加入到其中。如果在这个集合中出现重名列,那么这些列将被“合并”,这样在子表中只会有一个这样的列。重名列能被合并的前提是这些列必须具有相同的数据类型,否则会导致错误。可继承的检查约束和非空约束会以类似的方式被合并。例如,如果合并成一个合并列的任一列定义被标记为非空,则该合并列会被标记为非空。如果检查约束的名称相同,则他们会被合并,但如果它们的条件不同则合并会失败。
表继承通常是在子表被创建时建立,使用CREATE TABLE语句的INHERITS子句。一个已经被创建的表也可以另外一种方式增加一个新的父亲关系,使用ALTER TABLE的INHERIT变体。要这样做,新的子表必须已经包括和父表相同名称和数据类型的列。子表还必须包括和父表相同的检查约束和检查表达式。相似地,一个继承链接也可以使用ALTER TABLE的 NO INHERIT变体从一个子表中移除。动态增加和移除继承链接可以用于实现表划分(见第十节)。
一种创建一个未来将被用做子女的新表的方法是在CREATE TABLE中使用LIKE子句。这将创建一个和源表具有相同列的新表。如果源表上定义有任何CHECK约束,LIKE的INCLUDING CONSTRAINTS选项可以用来让新的子表也包含和父表相同的约束。
当有任何一个子表存在时,父表不能被删除。当子表的列或者检查约束继承于父表时,它们也不能被删除或修改。如果希望移除一个表和它的所有后代,一种简单的方法是使用CASCADE选项删除父表(见第十三节)。
ALTER TABLE将会把列的数据定义或检查约束上的任何变化沿着继承层次向下传播。同样,删除被其他表依赖的列只能使用CASCADE选项。ALTER TABLE对于重名列的合并和拒绝遵循与CREATE TABLE同样的规则。
继承的查询仅在附表上执行访问权限检查。例如,在cities表上授予UPDATE权限也隐含着通过cities访问时在capitals表中更新行的权限。这保留了数据(也)在父表中的样子。但是如果没有额外的授权,则不能直接更新capitals表。以类似的方式,父表的行安全性策略(见第七节)适用于继承查询期间来自于子表的行。只有当子表在查询中被明确提到时,其策略(如果有)才会被应用,在那种情况下,附着在其父表上的任何策略都会被忽略。
外部表(见第十一节)也可以是继承层次 中的一部分,即可以作为父表也可以作为子表,就像常规表一样。如果 一个外部表是继承层次的一部分,那么任何不被该外部表支持的操作也 不被整个层次所支持。
WARNNING:
注意并非所有的SQL命令都能工作在继承层次上。用于数据查询、数据修改或模式修改(例如SELECT、UPDATE、DELETE、大部分ALTER TABLE的变体,但INSERT或ALTER TABLE ... RENAME不在此列)的命令会默认将子表包含在内并且支持ONLY记号来排除子表。负责数据库维护和调整的命令(如REINDEX、VACUUM)只工作在独立的、物理的表上并且不支持在继承层次上的递归。每个命令相应的行为请参见它们的参考页(SQL 命令)。
继承特性的一个严肃的限制是索引(包括唯一约束)和外键约束值应用在单个表上而非它们的继承子女。在外键约束的引用端和被引用端都是这样。因此,按照上面的例子:
-
如果我们声明
cities.name为UNIQUE或者PRIMARY KEY,这将不会阻止capitals表中拥有和cities中城市同名的行。而且这些重复的行将会默认显示在cities的查询中。事实上,capitals在默认情况下是根本不能拥有唯一约束的,并且因此能够包含多个同名的行。我们可以为capitals增加一个唯一约束,但这无法阻止相对于cities的重复。 -
相似地,如果我们指定
cities.nameREFERENCES某个其他表,该约束不会自动地传播到capitals。在此种情况下,我们可以变通地在capitals上手工创建一个相同的REFERENCES约束。 -
指定另一个表的列
REFERENCES cities(name)将允许其他表包含城市名称,但不会包含首府名称。这对于这个例子不是一个好的变通方案。
这些不足可能还将存在于某些未来的发布中,但是同时在决定继承是否对我们的应用有用时需要相当小心。
十、表分区
10.1 概述
划分指的是将逻辑上的一个大表分成一些小的物理上的片。划分有很多益处:
-
在某些情况下查询性能能够显著提升,特别是当那些访问压力大的行在一个分区或者少数几个分区时。划分可以取代索引的主导列、减小索引尺寸以及使索引中访问压力大的部分更有可能被放在内存中。
-
当查询或更新访问一个分区的大部分行时,可以通过该分区上的一个顺序扫描来取代分散到整个表上的索引和随机访问,这样可以改善性能。
-
如果批量操作的需求是在分区设计时就规划好的,则批量装载和删除可以通过增加或者去除分区来完成。执行
ALTER TABLE DETACH PARTITION或者使用DROP TABLE删除一个分区远快于批量操作。这些命令也完全避免了批量DELETE导致的VACUUM开销。 -
很少使用的数据可以被迁移到便宜且较慢的存储介质上。
当一个表非常大时,划分所带来的好处是非常值得的。一个表何种情况下会从划分获益取决于应用,一个经验法则是当表的尺寸超过了数据库服务器物理内存时,划分会为表带来好处。
PostgreSQL对下列分区形式提供了内建支持:
- 范围划分 - 表被根据一个关键列或一组列划分为“范围”,不同的分区的范围之间没有重叠。例如,我们可以根据日期范围划分,或者根据特定业务对象的标识符划分。
- 列表划分 - 通过显式地列出每一个分区中出现的键值来划分表。
- 哈希分区 - 通过为每个分区指定模数和余数来对表进行分区。每个分区所持有的行都满足:分区键的值除以为其指定的模数将产生为其指定的余数。
如果你的应用需要使用上面所列之外的分区形式,可以使用诸如继承和UNION ALL视图之类的替代方法。这些方法很灵活,但是却缺少内建声明式分区的一些性能优势。
10.2 声明式划分
PostgreSQL提供了一种方法指定如何把一个表划分成称为分区的片段。被划分的表被称作分区表。这种说明由分区方法以及要被用作分区键的列或者表达式列表组成。
所有被插入到分区表的行将被基于分区键的值路由到分区中。每个分区都有一个由其分区边界定义的数据子集。当前支持的分区方法是范围、列表以及哈希。
分区本身也可能被定义为分区表,这种用法被称为子分区。分区可以有自己的与其他分区不同的索引、约束以及默认值。创建分区表及分区的更多细节请见CREATE TABLE。
无法把一个常规表转换成分区表,反之亦然。不过,可以把一个包含数据的常规表或者分区表作为分区加入到另一个分区表,或者从分区表中移走一个分区并且把它变成一个独立的表。有关ATTACH PARTITION和DETACH PARTITION子命令的内容请见ALTER TABLE。
个体分区在内部以继承的方式链接到分区表,不过无法对声明式分区表或其分区使用继承的某些一般特性(下文讨论)。例如,分区不能有除其所属分区表之外的父表,一个常规表也不能从分区表继承使得后者成为其父表。这意味着分区表及其分区不会参与到与常规表的继承关系中。由于分区表及其分区组成的分区层次仍然是一种继承层次,所有 第九节 中所述的继承的普通规则也适用,不过有一些例外,尤其是:
-
分区表的
CHECK约束和NOT NULL约束总是会被其所有的分区所继承。不允许在分区表上创建标记为NO INHERIT的CHECK约束。 -
只要分区表中不存在分区,则支持使用
ONLY仅在分区表上增加或者删除约束。一旦分区存在,那样做就会导致错误,因为当分区存在时是不支持仅在分区表上增加或删除约束的。不过,分区表本身上的约束可以被增加(如果它们不出现在父表中)和删除。 -
由于分区表并不直接拥有任何数据,尝试在分区表上使用
TRUNCATEONLY将总是返回错误。 -
分区不能有在父表中不存在的列。在使用
CREATE TABLE创建分区时不能指定列,在事后使用ALTER TABLE时也不能为分区增加列。只有当表的列正好匹配父表时(包括任何oid列),才能使用ALTER TABLE ... ATTACH PARTITION将它作为分区加入。 -
如果
NOT NULL约束在父表中存在,那么就不能删除分区的列上的对应的NOT NULL约束。
分区也可以是外部表,不过它们有一些普通表没有的限制,详情请见CREATE FOREIGN TABLE。
更新行的分区键可能导致它满足另一个不同的分区的分区边界,进而被移动到那个分区中。
10.2.1 例子
假定我们正在为一个大型的冰激凌公司构建数据库。该公司每天测量最高温度以及每个区域的冰激凌销售情况。概念上,我们想要一个这样的表:
- CREATE TABLE measurement (
- city_id int not null,
- logdate date not null,
- peaktemp int,
- unitsales int
- );
我们知道大部分查询只会访问上周的、上月的或者上季度的数据,因为这个表的主要用途是为管理层准备在线报告。为了减少需要被存放的旧数据量,我们决定只保留最近3年的数据。在每个月的开始我们将去除掉最早的那个月的数据。在这种情况下我们可以使用分区技术来帮助我们满足对measurement表的所有不同需求。
要在这种情况下使用声明式分区,可采用下面的步骤:
①. 通过指定PARTITION BY子句把measurement表创建为分区表,该子句包括分区方法(这个例子中是RANGE)以及用作分区键的列列表。
- CREATE TABLE measurement (
- city_id int not null,
- logdate date not null,
- peaktemp int,
- unitsales int
- ) PARTITION BY RANGE (logdate);
你可能需要决定在分区键中使用多列进行范围分区。当然,这通常会导致较大数量的分区,其中每一个个体都比较小。另一方面,使用较少的列可能会导致粗粒度的分区策略得到较少数量的分区。如果条件涉及这些列中的一部分或者全部,访问分区表的查询将不得不扫描较少的分区。例如,考虑一个使用列lastname和firstname(按照这样的顺序)作为分区键进行范围分区的表。
②.创建分区。每个分区的定义必须指定对应于父表的分区方法和分区键的边界。注意,如果指定的边界使得新分区的值会与已有分区中的值重叠,则会导致错误。向父表中插入无法映射到任何现有分区的数据将会导致错误,这种情况下应该手工增加一个合适的分区。
分区以普通PostgreSQL表(或者可能是外部表)的方式创建。可以为每个分区单独指定表空间和存储参数。
没有必要创建表约束来描述分区的分区边界条件。相反,只要需要引用分区约束时,分区约束会自动地隐式地从分区边界说明中生成。
- CREATE TABLE measurement_y2006m02 PARTITION OF measurement
- FOR VALUES FROM ('2006-02-01') TO ('2006-03-01');
-
- CREATE TABLE measurement_y2006m03 PARTITION OF measurement
- FOR VALUES FROM ('2006-03-01') TO ('2006-04-01');
-
- ...
- CREATE TABLE measurement_y2007m11 PARTITION OF measurement
- FOR VALUES FROM ('2007-11-01') TO ('2007-12-01');
-
- CREATE TABLE measurement_y2007m12 PARTITION OF measurement
- FOR VALUES FROM ('2007-12-01') TO ('2008-01-01')
- TABLESPACE fasttablespace;
-
- CREATE TABLE measurement_y2008m01 PARTITION OF measurement
- FOR VALUES FROM ('2008-01-01') TO ('2008-02-01')
- WITH (parallel_workers = 4)
- TABLESPACE fasttablespace;
为了实现子分区,在创建分区的命令中指定PARTITION BY子句,例如:
- CREATE TABLE measurement_y2006m02 PARTITION OF measurement
- FOR VALUES FROM ('2006-02-01') TO ('2006-03-01')
- PARTITION BY RANGE (peaktemp);
在创建了measurement_y2006m02的分区之后,任何被插入到measurement中且被映射到measurement_y2006m02的数据(或者直接被插入到measurement_y2006m02的数据,假定它满足这个分区的分区约束)将被基于peaktemp列进一步重定向到measurement_y2006m02的一个分区。指定的分区键可以与父亲的分区键重叠,不过在指定子分区的边界时要注意它接受的数据集合是分区自身边界允许的数据集合的一个子集,系统不会尝试检查事情情况是否如此。
③.在分区表的键列上创建一个索引,还有其他需要的索引(键索引并不是必需的,但是大部分场景中它都能很有帮助)。这会自动在每个分区上创建一个索引,并且后来创建或者附着的任何分区也将会包含索引。
CREATE INDEX ON measurement (logdate);
④.确保enable_partition_pruning配置参数在postgresql.conf中没有被禁用。如果被禁用,查询将不会按照想要的方式被优化。
在上面的例子中,我们会每个月创建一个新分区,因此写一个脚本来自动生成所需的DDL会更好。
10.2.2 分区维护
通常在初始定义分区表时建立的分区并非保持静态不变。移除旧分区的数据并且为新数据周期性地增加新分区的需求比比皆是。分区的最大好处之一就是可以通过操纵分区结构来近乎瞬时地执行这类让人头痛的任务,而不是物理地去除大量数据。
移除旧数据最简单的选择是删除掉不再需要的分区:
DROP TABLE measurement_y2006m02;
这可以非常快地删除数百万行记录,因为它不需要逐个删除每个记录。不过要注意上面的命令需要在父表上拿到ACCESS EXCLUSIVE锁。
另一种通常更好的选项是把分区从分区表中移除,但是保留它作为一个独立的表:
ALTER TABLE measurement DETACH PARTITION measurement_y2006m02;这允许在它被删除之前在其数据上执行进一步的操作。例如,这通常是一种使用COPY、pg_dump或类似工具备份数据的好时候。这也是把数据聚集成较小的格式、执行其他数据操作或者运行报表的好时机。
类似地,我们可以增加一个新分区来处理新数据。我们可以在分区表中创建一个空分区,就像上面创建的初始分区那样:
- CREATE TABLE measurement_y2008m02 PARTITION OF measurement
- FOR VALUES FROM ('2008-02-01') TO ('2008-03-01')
- TABLESPACE fasttablespace;
另外一种选择是,有时候在分区结构之外创建新表更加方便,然后将它作为一个合适的分区。这允许先对数据进行装载、检查和转换,然后再让它们出现在分区表中:
- CREATE TABLE measurement_y2008m02
- (LIKE measurement INCLUDING DEFAULTS INCLUDING CONSTRAINTS)
- TABLESPACE fasttablespace;
-
- ALTER TABLE measurement_y2008m02 ADD CONSTRAINT y2008m02
- CHECK ( logdate >= DATE '2008-02-01' AND logdate < DATE '2008-03-01' );
-
- \copy measurement_y2008m02 from 'measurement_y2008m02'
- -- possibly some other data preparation work
-
- ALTER TABLE measurement ATTACH PARTITION measurement_y2008m02
- FOR VALUES FROM ('2008-02-01') TO ('2008-03-01' );
在运行ATTACH PARTITION命令之前,推荐在要被挂接的表上创建一个CHECK约束来描述想要的分区约束。采用这种方法,系统将能够跳过验证隐式分区约束的扫描。如果没有这样一个约束,则将会扫描表来验证分区约束,其间会持有一个父表上的ACCESS EXCLUSIVE锁。人们可能在ATTACH PARTITION完成之后删除该约束,因为之后就不再需要它了。
10.2.3 限制
分区表有下列限制:
-
没有办法创建跨越所有分区的排除约束,只可能单个约束每个叶子分区。
-
虽然在分区表上支持主键,但引用分区表的外键不受支持(但支持从分区表到某个其他表的外键引用)。
-
当一个
UPDATE导致一行从一个分区移动到另一个分区时,另一个并发的UPDATE或DELETE可能会产生一个串行化错误。假设会话1正在执行一个分区键上的UPDATE,同时一个并发的能看见这个行的会话2执行了对该行的UPDATE或者DELETE操作。在这种情况下,会话2的UPDATE或者DELETE会检测到行的移动,并抛出一个串行化的错误(将总是会返回一个SQLSTATE '40001')。 如果发生这种情况,应用程序可能希望重试该事务。 在没有分区表或没有行移动的通常情况下, 会话2将识别新更新的行并在新行上执行UPDATE/DELETE。 -
如果必要,必须在个体分区上定义
BEFORE ROW触发器,分区表上不需要。 -
不允许在同一个分区树中混杂临时关系和持久关系。因此,如果分区表是持久的,则其分区也必须是持久的,反之亦然。在使用临时关系时,分区数的所有成员都必须来自于同一个会话。
10.3 使用继承实现
虽然内建的声明式分区适合于大部分常见的用例,但还是有一些场景需要更加灵活的方法。分区可以使用表继承来实现,这能够带来一些声明式分区不支持的特性,例如:
-
对声明式分区来说,分区必须具有和分区表正好相同的列集合,而在表继承中,子表可以有父表中没有出现过的额外列。
-
表继承允许多继承。
-
声明式分区仅支持范围、列表以及哈希分区,而表继承允许数据按照用户的选择来划分(不过注意,如果约束排除不能有效地剪枝子表,查询性能可能会很差)。
-
在使用声明式分区时,一些操作比使用表继承时要求更长的持锁时间。例如,向分区表中增加分区或者从分区表移除分区要求在父表上取得一个
ACCESS EXCLUSIVE锁,而在常规继承的情况下一个SHARE UPDATE EXCLUSIVE锁就足够了。
10.3.1 例子
我们使用上面用过的同一个measurement表。为了使用继承实现分区,可使用下面的步骤:
①.创建“主”表,所有的“子”表都将从它继承。这个表将不包含数据。不要在这个表上定义任何检查约束,除非想让它们应用到所有的子表上。同样,在这个表上定义索引或者唯一约束也没有意义。对于我们的例子来说,主表是最初定义的measurement表。
②.创建数个“子”表,每一个都从主表继承。通常,这些表将不会在从主表继承的列集合之外增加任何列。正如声明性分区那样,这些表就是普通的PostgreSQL表(或者外部表)。
- CREATE TABLE measurement_y2006m02 () INHERITS (measurement);
- CREATE TABLE measurement_y2006m03 () INHERITS (measurement);
- ...
- CREATE TABLE measurement_y2007m11 () INHERITS (measurement);
- CREATE TABLE measurement_y2007m12 () INHERITS (measurement);
- CREATE TABLE measurement_y2008m01 () INHERITS (measurement);
③.为子表增加不重叠的表约束来定义每个分区允许的键值。
典型的例子是:
- CHECK ( x = 1 )
- CHECK ( county IN ( 'Oxfordshire', 'Buckinghamshire', 'Warwickshire' ))
- CHECK ( outletID >= 100 AND outletID < 200 )
确保约束能保证不同子表允许的键值之间没有重叠。设置范围约束的常见错误:
- CHECK ( outletID BETWEEN 100 AND 200 )
- CHECK ( outletID BETWEEN 200 AND 300 )
这是错误的,因为不清楚键值200属于哪一个子表。
像下面这样创建子表会更好:
- CREATE TABLE measurement_y2006m02 (
- CHECK ( logdate >= DATE '2006-02-01' AND logdate < DATE '2006-03-01' )
- ) INHERITS (measurement);
-
- CREATE TABLE measurement_y2006m03 (
- CHECK ( logdate >= DATE '2006-03-01' AND logdate < DATE '2006-04-01' )
- ) INHERITS (measurement);
-
- ...
- CREATE TABLE measurement_y2007m11 (
- CHECK ( logdate >= DATE '2007-11-01' AND logdate < DATE '2007-12-01' )
- ) INHERITS (measurement);
-
- CREATE TABLE measurement_y2007m12 (
- CHECK ( logdate >= DATE '2007-12-01' AND logdate < DATE '2008-01-01' )
- ) INHERITS (measurement);
-
- CREATE TABLE measurement_y2008m01 (
- CHECK ( logdate >= DATE '2008-01-01' AND logdate < DATE '2008-02-01' )
- ) INHERITS (measurement);
④.对于每个子表,在键列上创建一个索引,以及任何想要的其他索引。
- CREATE INDEX measurement_y2006m02_logdate ON measurement_y2006m02 (logdate);
- CREATE INDEX measurement_y2006m03_logdate ON measurement_y2006m03 (logdate);
- CREATE INDEX measurement_y2007m11_logdate ON measurement_y2007m11 (logdate);
- CREATE INDEX measurement_y2007m12_logdate ON measurement_y2007m12 (logdate);
- CREATE INDEX measurement_y2008m01_logdate ON measurement_y2008m01 (logdate);
⑤.我们希望我们的应用能够使用INSERT INTO measurement ...并且数据将被重定向到合适的分区表。我们可以通过为主表附加一个合适的触发器函数来实现这一点。如果数据将只被增加到最后一个分区,我们可以使用一个非常简单的触发器函数:
- CREATE OR REPLACE FUNCTION measurement_insert_trigger()
- RETURNS TRIGGER AS $$
- BEGIN
- INSERT INTO measurement_y2008m01 VALUES (NEW.*);
- RETURN NULL;
- END;
- $$
- LANGUAGE plpgsql;
完成函数创建后,我们创建一个调用该触发器函数的触发器:
- CREATE TRIGGER insert_measurement_trigger
- BEFORE INSERT ON measurement
- FOR EACH ROW EXECUTE FUNCTION measurement_insert_trigger();
我们必须在每个月重新定义触发器函数,这样它才会总是指向当前的子表。而触发器的定义则不需要被更新。
我们也可能希望插入数据时服务器会自动地定位应该加入数据的子表。我们可以通过一个更复杂的触发器函数来实现之,例如:
- CREATE OR REPLACE FUNCTION measurement_insert_trigger()
- RETURNS TRIGGER AS $$
- BEGIN
- IF ( NEW.logdate >= DATE '2006-02-01' AND
- NEW.logdate < DATE '2006-03-01' ) THEN
- INSERT INTO measurement_y2006m02 VALUES (NEW.*);
- ELSIF ( NEW.logdate >= DATE '2006-03-01' AND
- NEW.logdate < DATE '2006-04-01' ) THEN
- INSERT INTO measurement_y2006m03 VALUES (NEW.*);
- ...
- ELSIF ( NEW.logdate >= DATE '2008-01-01' AND
- NEW.logdate < DATE '2008-02-01' ) THEN
- INSERT INTO measurement_y2008m01 VALUES (NEW.*);
- ELSE
- RAISE EXCEPTION 'Date out of range. Fix the measurement_insert_trigger() function!';
- END IF;
- RETURN NULL;
- END;
- $$
- LANGUAGE plpgsql;
触发器的定义和以前一样。注意每一个IF测试必须准确地匹配它的子表的CHECK约束。
当该函数比单月形式更加复杂时,并不需要频繁地更新它,因为可以在需要的时候提前加入分支。
NOTES:
在实践中,如果大部分插入都会进入最新的子表,最好先检查它。为了简洁,我们为触发器的检查采用了和本例中其他部分一致的顺序。
把插入重定向到一个合适的子表中的另一种不同方法是在主表上设置规则而不是触发器。例如:
- CREATE RULE measurement_insert_y2006m02 AS
- ON INSERT TO measurement WHERE
- ( logdate >= DATE '2006-02-01' AND logdate < DATE '2006-03-01' )
- DO INSTEAD
- INSERT INTO measurement_y2006m02 VALUES (NEW.*);
- ...
- CREATE RULE measurement_insert_y2008m01 AS
- ON INSERT TO measurement WHERE
- ( logdate >= DATE '2008-01-01' AND logdate < DATE '2008-02-01' )
- DO INSTEAD
- INSERT INTO measurement_y2008m01 VALUES (NEW.*);
规则的开销比触发器大很多,但是这种开销是每个查询只有一次,而不是每行一次,因此这种方法可能对批量插入的情况有优势。不过,在大部分情况下,触发器方法将提供更好的性能。
注意COPY会忽略规则。如果想要使用COPY插入数据,则需要拷贝到正确的子表而不是直接放在主表中。COPY会引发触发器,因此在使用触发器方法时可以正常使用它。
规则方法的另一个缺点是,如果规则集合无法覆盖插入日期,则没有简单的方法能够强制产生错误,数据将会无声无息地进入到主表中。
⑥.确认constraint_exclusion配置参数在postgresql.conf中没有被禁用,否则将会不必要地访问子表。
如我们所见,一个复杂的表层次可能需要大量的DDL。在上面的例子中,我们可能为每个月创建一个新的子表,因此编写一个脚本来自动生成所需要的DDL可能会更好。
10.3.2 继承分区的维护
要快速移除旧数据,只需要简单地去掉不再需要的子表:
DROP TABLE measurement_y2006m02;要从继承层次表中去掉子表,但还是把它当做一个表保留:
ALTER TABLE measurement_y2006m02 NO INHERIT measurement;要增加一个新子表来处理新数据,可以像上面创建的原始子表那样创建一个空的子表:
- CREATE TABLE measurement_y2008m02 (
- CHECK ( logdate >= DATE '2008-02-01' AND logdate < DATE '2008-03-01' )
- ) INHERITS (measurement);
或者,用户可能想要创建新子表并且在将它加入到表层次之前填充它。这可以允许数据在被父表上的查询可见之前对数据进行装载、检查以及转换。
- CREATE TABLE measurement_y2008m02
- (LIKE measurement INCLUDING DEFAULTS INCLUDING CONSTRAINTS);
- ALTER TABLE measurement_y2008m02 ADD CONSTRAINT y2008m02
- CHECK ( logdate >= DATE '2008-02-01' AND logdate < DATE '2008-03-01' );
- \copy measurement_y2008m02 from 'measurement_y2008m02'
- -- possibly some other data preparation work
- ALTER TABLE measurement_y2008m02 INHERIT measurement;
10.3.3 提醒
下面的提醒适用于用继承实现的分区:
-
没有自动的方法啊验证所有的
CHECK约束之间是否互斥。编写代码来产生子表以及创建和修改相关对象比手写命令要更加安全。 -
这里展示的模式假定行的键列值从不改变,或者说改变不足以让行移动到另一个分区。由于
CHECK约束的存在,尝试那样做的UPDATE将会失败。如果需要处理那种情况,可以在子表上放置适当的更新触发器,但是那会使对结构的管理更加复杂。 -
如果使用手工的
VACUUM或者ANALYZE命令,不要忘记需要在每个子表上单独运行它们。这样的命令:
ANALYZE measurement;
将只会处理主表。
-
带有
ON CONFLICT子句的INSERT语句不太可能按照预期工作,因为只有在指定的目标关系而不是其子关系上发生唯一违背时才会采取ON CONFLICT行动。 -
将会需要触发器或者规则将行路由到想要的子表中,除非应用明确地知道分区的模式。编写触发器可能会很复杂,并且会比声明式分区在内部执行的元组路由慢很多。
10.4 分区剪枝
分区剪枝是一种提升声明式分区表性能的查询优化技术。例如:
- SET enable_partition_pruning = on; -- the default
- SELECT count(*) FROM measurement WHERE logdate >= DATE '2008-01-01';
如果没有分区剪枝,上面的查询将会扫描measurement表的每一个分区。如果启用了分区剪枝,规划器将会检查每个分区的定义并且检验该分区是否因为不包含符合查询WHERE子句的行而无需扫描。当规划器可以证实这一点时,它会把分区从查询计划中排除(剪枝)。
通过使用EXPLAIN命令和enable_partition_pruning配置参数,可以展示剪枝掉分区的计划与没有剪枝的计划之间的差别。对这种类型的表设置,一种典型的未优化计划是:
- SET enable_partition_pruning = off;
- EXPLAIN SELECT count(*) FROM measurement WHERE logdate >= DATE '2008-01-01';
- QUERY PLAN
- -----------------------------------------------------------------------------------
- Aggregate (cost=188.76..188.77 rows=1 width=8)
- -> Append (cost=0.00..181.05 rows=3085 width=0)
- -> Seq Scan on measurement_y2006m02 (cost=0.00..33.12 rows=617 width=0)
- Filter: (logdate >= '2008-01-01'::date)
- -> Seq Scan on measurement_y2006m03 (cost=0.00..33.12 rows=617 width=0)
- Filter: (logdate >= '2008-01-01'::date)
- ...
- -> Seq Scan on measurement_y2007m11 (cost=0.00..33.12 rows=617 width=0)
- Filter: (logdate >= '2008-01-01'::date)
- -> Seq Scan on measurement_y2007m12 (cost=0.00..33.12 rows=617 width=0)
- Filter: (logdate >= '2008-01-01'::date)
- -> Seq Scan on measurement_y2008m01 (cost=0.00..33.12 rows=617 width=0)
- Filter: (logdate >= '2008-01-01'::date)
某些或者全部的分区可能会使用索引扫描取代全表顺序扫描,但是这里的重点是根本不需要扫描较老的分区来回答这个查询。当我们启用分区剪枝时,我们会得到一个便宜很多的计划,而它能给出相同的答案:
- SET enable_partition_pruning = on;
- EXPLAIN SELECT count(*) FROM measurement WHERE logdate >= DATE '2008-01-01';
- QUERY PLAN
- -----------------------------------------------------------------------------------
- Aggregate (cost=37.75..37.76 rows=1 width=8)
- -> Append (cost=0.00..36.21 rows=617 width=0)
- -> Seq Scan on measurement_y2008m01 (cost=0.00..33.12 rows=617 width=0)
- Filter: (logdate >= '2008-01-01'::date)
注意,分区剪枝仅由分区键隐式定义的约束所驱动,而不是由索引的存在驱动。因此,没有必要在键列上定义索引。是否需要为一个给定分区创建索引取决于预期的查询扫描该分区时会扫描大部分还是小部分。后一种情况下索引的帮助会比前者大。
不仅在给定查询的规划期间可以执行分区剪枝,在其执行期间也能执行分区剪枝。这非常有用,因为如果子句中包含查询规划时值未知的表达式时,这可以剪枝掉更多的分区,例如在PREPARE语句中定义的参数会使用从子查询拿到的值或者嵌套循环连接内侧关系上的参数化值。执行期间的分区剪枝可能在下列任何时刻执行:
-
在查询计划的初始化期间。对于执行的初始化阶段就已知值的参数,可以在这里执行分区剪枝。这个阶段中被剪枝掉的分区将不会显示在查询的
EXPLAIN或EXPLAIN ANALYZE结果中。通过观察EXPLAIN输出的“Subplans Removed”属性,可以确定被剪枝掉的分区数。 -
在查询计划的实际执行期间。这里可以使用只有在实际查询执行时才能知道的值执行分区剪枝。这包括来自子查询的值以及来自执行时参数的值(例如来自于参数化嵌套循环连接的参数)。由于在查询执行期间这些参数的值可能会改变多次,所以只要分区剪枝使用到的执行参数发生改变,就会执行一次分区剪枝。要判断分区是否在这个阶段被剪枝,需要仔细地观察
EXPLAIN ANALYZE输出中的loops属性。 对应于不同分区的子计划可以具有不同的值,这取决于在执行期间每个分区被修剪的次数。 如果每次都被剪枝,有些分区可能会显示为(never executed)。
可以使用enable_partition_pruning设置禁用分区剪枝。
NOTES:
当前,UPDATE or DELETE命令规划时的分区剪枝采用约束排除方法实现(但是,它是由enable_partition_pruning而不是constraint_exclusion控制 — 其细节及相应的提醒请参考接下来的小节。
此外,执行时的分区剪枝当前仅发生在Append节点类型上,对MergeAppend则不会。
这些行为都很可能在未来的PostgreSQL发行中被改变。
10.5 分区和约束排除
约束排除是一种与分区剪枝类似的查询优化技术。虽然它主要被用于使用传统继承方法实现的分区上,但它也可以被用于其他目的,包括用于声明式分区。
约束排除以非常类似于分区剪枝的方式工作,不过它使用每个表的CHECK约束 — 这也是它得名的原因 — 而分区剪枝使用表的分区边界,分区边界仅存在于声明式分区的情况中。另一点不同之处是约束排除仅在规划时应用,在执行时不会尝试移除分区。
由于约束排除使用CHECK约束,这导致它比分区剪枝要慢,但有时候可以被当作一种优点加以利用:因为甚至可以在声明式分区的表上(在分区边界之外)定义约束,约束排除可能可以从查询计划中消去额外的分区。
constraint_exclusion的默认(也是推荐的)设置不是on也不是off,而是一种被称为partition的中间设置,这会导致该技术仅被应用于可能工作在继承分区表上的查询。on设置导致规划器检查所有查询中的CHECK约束,甚至是那些不太可能受益的简单查询。
下列提醒适用于约束排除:
-
约束排除仅适用于查询规划期间,和分区剪枝不同,它不适用于查询执行期间。
-
只有查询的
WHERE子句包含常量(或者外部提供的参数)时,约束排除才能有效果。例如,针对一个非不变函数(如CURRENT_TIMESTAMP)的比较不能被优化,因为规划器不知道该函数的值在运行时会落到哪个子表中。 -
保持分区约束简单化,否则规划器可能无法验证哪些子表可能不需要被访问。如前面的例子所示,对列表分区使用简单的等值条件,对范围分区使用简单的范围测试。一种好的经验规则是分区约束应该仅包含分区列与常量使用B-树的可索引操作符的比较,因为只有B-树的可索引列才允许出现在分区键中。
-
约束排除期间会检查父表的所有子表上的所有约束,因此大量的子表很可能明显地增加查询规划时间。因此,传统的基于继承的分区可以很好地处理上百个子表,不要尝试使用上千个子表。
十一、外部数据
PostgreSQL实现了部分的SQL/MED规定,允许我们使用普通SQL查询来访问位于PostgreSQL之外的数据。这种数据被称为外部数据(注意这种用法不要和外键混淆,后者是数据库中的一种约束)。
外部数据可以在一个外部数据包装器的帮助下被访问。一个外部数据包装器是一个库,它可以与一个外部数据源通讯,并隐藏连接到数据源和从它获取数据的细节。在contrib模块中有一些外部数据包装器,参见附录 F。其他类型的外部数据包装器可以在第三方产品中找到。如果这些现有的外部数据包装器都不能满足你的需要,可以自己编写一个,参见后续章节。
要访问外部数据,我们需要建立一个外部服务器对象,它根据它所支持的外部数据包装器所使用的一组选项定义了如何连接到一个特定的外部数据源。接着我们需要创建一个或多个外部表,它们定义了外部数据的结构。一个外部表可以在查询中像一个普通表一样地使用,但是在PostgreSQL服务器中外部表没有存储数据。不管使用什么外部数据包装器,PostgreSQL会要求外部数据包装器从外部数据源获取数据,或者在更新命令的情况下传送数据到外部数据源。
访问远程数据可能需要在外部数据源的授权。这些信息通过一个用户映射提供,它基于当前的PostgreSQL角色提供了附加的数据例如用户名和密码。
十二、其他数据库对象
表是一个关系型数据库结构中的核心对象,因为它们承载了我们的数据。但是它们并不是数据库中的唯一一种对象。有很多其他种类的对象可以被创建来使得数据的使用和刮泥更加方便或高效。在本章中不会讨论它们,但是我们在会给出一个列表:
-
视图
-
函数、过程和操作符
-
数据类型和域
-
触发器和重写规则
十三、依赖跟踪
当我们创建一个涉及到很多具有外键约束、视图、触发器、函数等的表的复杂数据库结构时,我们隐式地创建了一张对象之间的依赖关系网。例如,具有一个外键约束的表依赖于它所引用的表。
为了保证整个数据库结构的完整性,PostgreSQL确保我们无法删除仍然被其他对象依赖的对象。例如,尝试删除上面第三节中的产品表会导致一个如下的错误消息,因为有订单表依赖于产品表:
- DROP TABLE products;
-
- ERROR: cannot drop table products because other objects depend on it
- DETAIL: constraint orders_product_no_fkey on table orders depends on table products
- HINT: Use DROP ... CASCADE to drop the dependent objects too.
该错误消息包含了一个有用的提示:如果我们不想一个一个去删除所有的依赖对象,我们可以执行:
DROP TABLE products CASCADE;这样所有的依赖对象将被移除,同样依赖于它们的任何对象也会被递归删除。在这种情况下,订单表不会被移除,但是它的外键约束会被移除。之所以在这里会停下,是因为没有什么依赖着外键约束(如果希望检查DROP ... CASCADE会干什么,运行不带CASCADE的DROP并阅读DETAIL输出)。
PostgreSQL中的几乎所有DROP命令都支持CASCADE。当然,其本质的区别随着对象的类型而不同。我们也可以用RESTRICT代替CASCADE来获得默认行为,它将阻止删除任何被其他对象依赖的对象。
NOTES:
根据SQL标准,在DROP命令中指定RESTRICT或CASCADE是被要求的。但没有哪个数据库系统真正强制了这个规则,但是不同的系统中两种默认行为都是可能的。
如果一个DROP命令列出了多个对象,只有在存在指定对象构成的组之外的依赖关系时才需要CASCADE。例如,如果发出命令DROP TABLE tab1, tab2且存在从tab2到tab1的外键引用,那么就不需要CASCADE即可成功执行。
对于用户定义的函数,PostgreSQL会追踪与函数外部可见性质相关的依赖性,例如它的参数和结果类型,但不追踪检查函数体才能知道的依赖性。例如,考虑这种情况:
- CREATE TYPE rainbow AS ENUM ('red', 'orange', 'yellow',
- 'green', 'blue', 'purple');
-
- CREATE TABLE my_colors (color rainbow, note text);
-
- CREATE FUNCTION get_color_note (rainbow) RETURNS text AS
- 'SELECT note FROM my_colors WHERE color = $1'
- LANGUAGE SQL;
(SQL 元函数的解释见后续章节)。PostgreSQL将会注意到get_color_note函数依赖于rainbow类型:删掉该类型会强制删除该函数,因为该函数的参数类型就无法定义了。但是PostgreSQL不会认为get_color_note依赖于my_colors表,因此即使该表被删除也不会删除这个函数。虽然这种方法有缺点,但是也有好处。如果该表丢失,这个函数在某种程度上仍然是有效的,但是执行它会导致错误。创建一个同名的新表将允许该函数重新有效。

