
- 1hbase安装踩坑_hbase 无法建表 processing servercrashprocedure
- 2渗透测试工具库总结(全网最全)_mip22 is a advanced phishing tool
- 366条AI共创文章润色秘诀,一键提升你的写作水平
- 4游戏开发面试题_游戏编程面试问题,你开发过什么项目
- 5探秘每月最佳的JavaScript开源项目:javascript-open-source
- 6Java入门,深入理解Java平台及其关键特性
- 7数据集成与大数据技术:如何处理海量数据
- 8运算放大器,放大倍数与增益的关系_运放的增益与放大倍数
- 9Mac M1 安装Oracle Java 与 IEDA_mac m1idea 安装
- 10最短路径——floyd算法_floyd最短路径算法是贪心算法吗
1.6 基础组件之Datasets_datasets.splitgenerator
赞
踩
目录
4 Datasets+DataCollator模型微调代码优化:
1 Datasets简介:

2 Datasets基本使用:
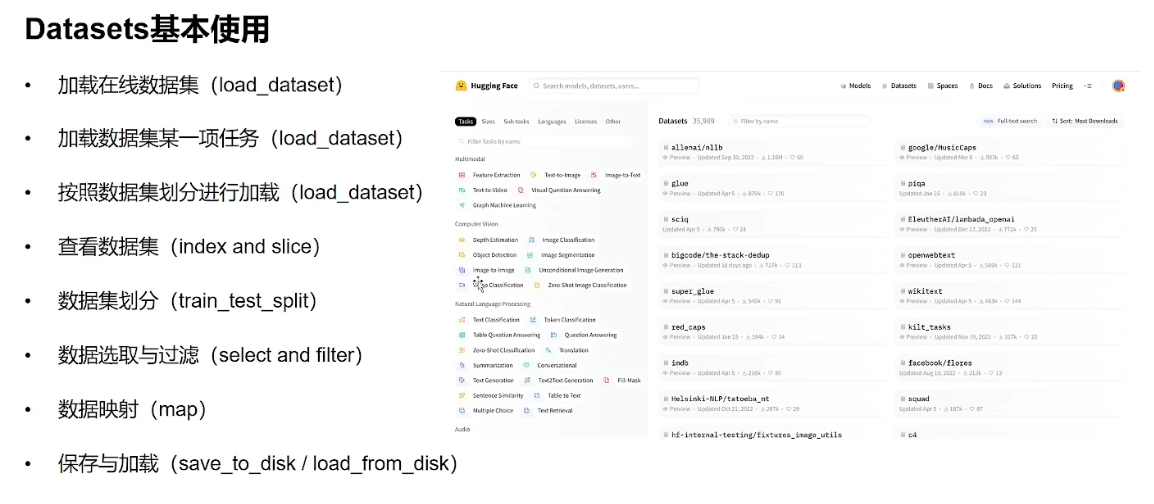
2.1 加载在线数据集:
和模型的加载方式类似,也是直接复制数据集名称就可以加载了。


2.2 加载数据集某一项任务:
对于某些数据集,其内部并非只含有一种任务,比如下图中的glue数据集,那么我们就需要针对性地加载glue中特定任务的数据集:
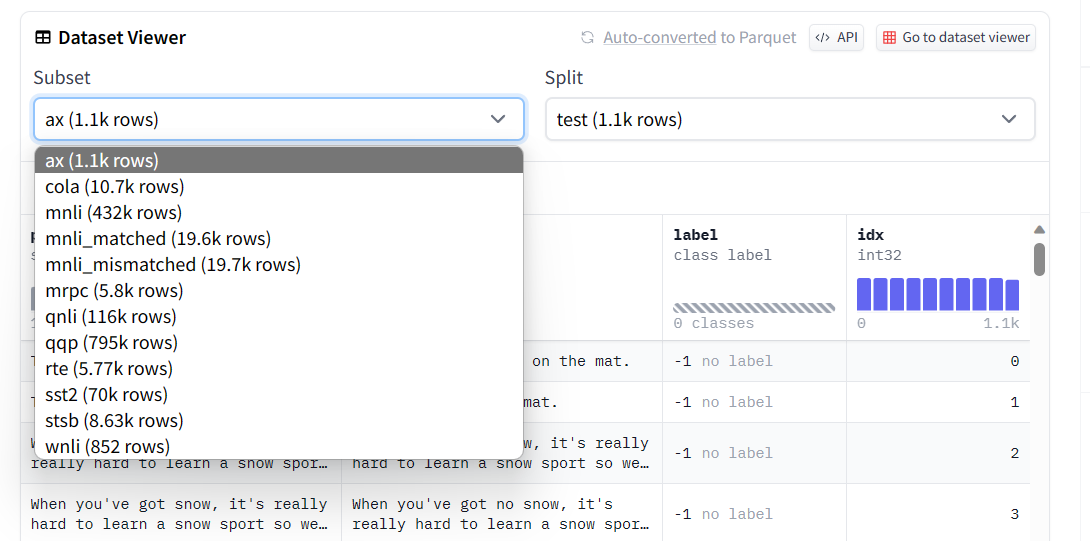
这就需要我们用参数进行指定:(boolq就是我们所需要的任务数据集)

2.3 按照数据集划分进行加载:
如果我们想要只加载数据集中的训练集、测试集、验证集等部分数据集,甚至加载这些单个数据集中的一小部分,那么我们就需要按照数据集划分进行加载:

如上图所示,我们只加载里边的训练集,此时下方的结果是Dataset,已经不再是DatasetDict
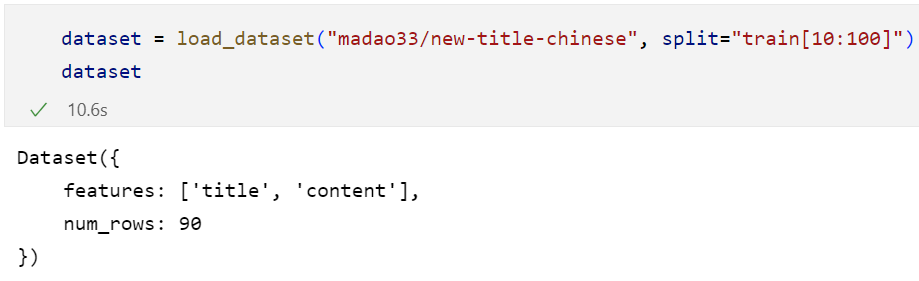
我们还可以只加载训练集中的部分:(10-100条)
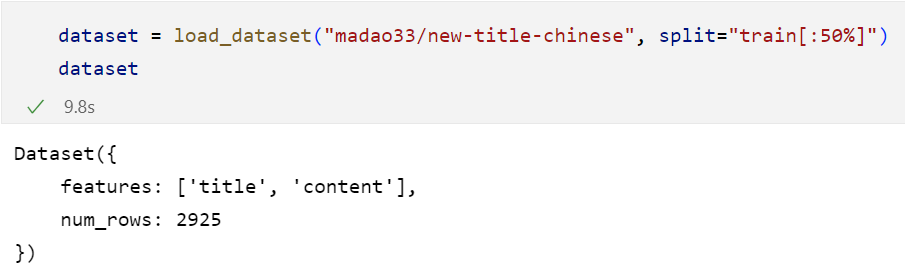
也可以按照比例加载:
我们也可以先加载后50%,再加载前50%,做一个拼接,最后是一个list的效果:(注意只能是百分数,不能是小数)
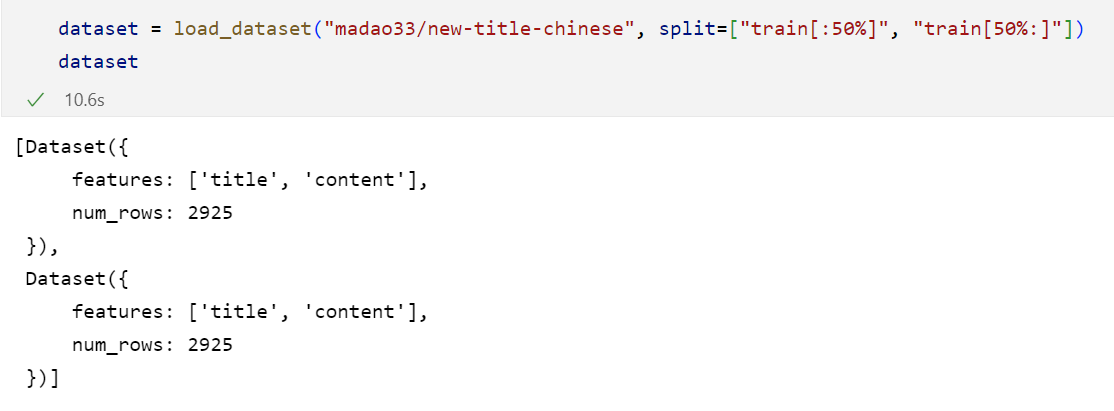
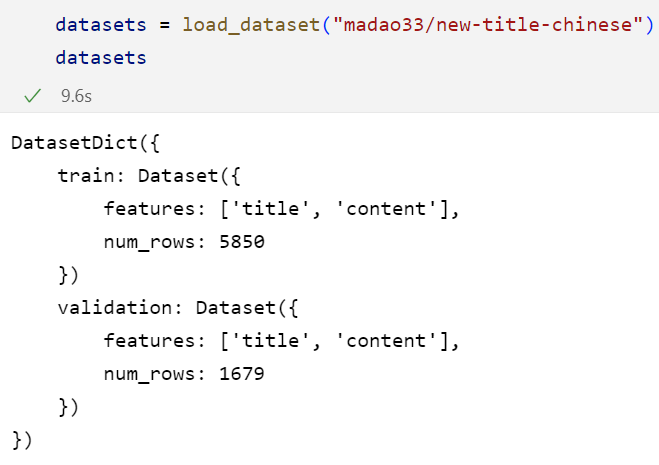
2.4 查看数据集:
如何查看数据集呢?
对于最后是DatasetDict形式的,我们就可以通过dict进行访问:


最后得到的是一个list的形式
如何查看数据集包含的字段呢?
甚至可以查看字段的具体特征:

2.5 数据集划分:
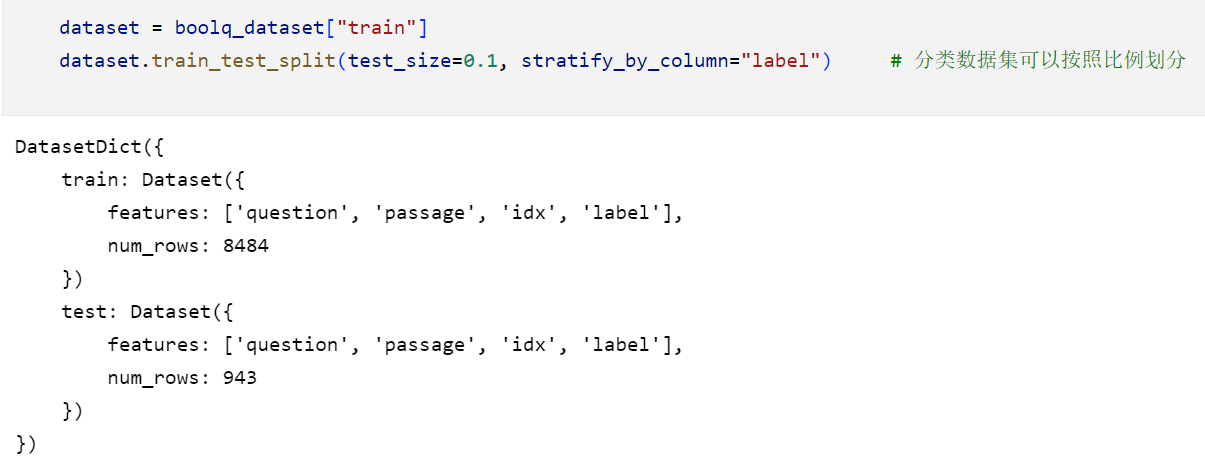
在之前的pytorch中我们使用的是random_split的方法进行的划分,那么在datasets中我们则是使用train_test_split进行划分。

如果我们希望划分出的数据是以某个特征为标准均衡的(比如标签label),那么我们就需要指定下面这个参数:
2.6 数据选取与过滤:
如果我们想要按照以索引的形式选取数据,那么就可以参照如下形式,但是我们这样子得到的形式还是一个dataset
现在我们要过滤数据集中的一些东西,比如我们只想要保留title中含有“中国”对应的数据集:
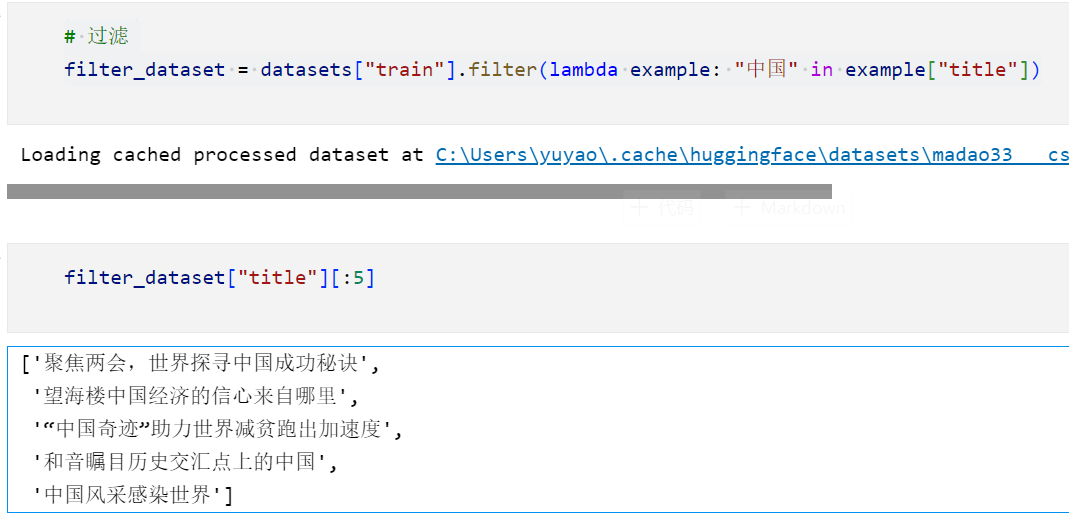
这段代码是在使用一个名为
filter()的方法来过滤名为datasets["train"]的数据集。该方法接受一个函数作为参数,用于确定哪些数据应该被保留下来。在这个例子中,使用了一个Lambda函数作为
filter()方法的参数。Lambda函数的定义是lambda example: "中国" in example["title"],它接受一个名为example的参数,并返回一个布尔值。Lambda函数的作用是检查
example字典中的"title"键对应的值是否包含字符串"中国"。如果包含,则返回True,表示该数据应该被保留下来;如果不包含,则返回False,表示该数据应该被过滤掉。
filter()方法根据Lambda函数的返回值来决定保留哪些数据。只有Lambda函数返回True的数据才会被保留下来,而返回False的数据将被过滤掉。因此,
filter_dataset将成为一个经过过滤后的数据集,其中只包含"title"中包含字符串"中国"的数据。
2.7 数据映射:
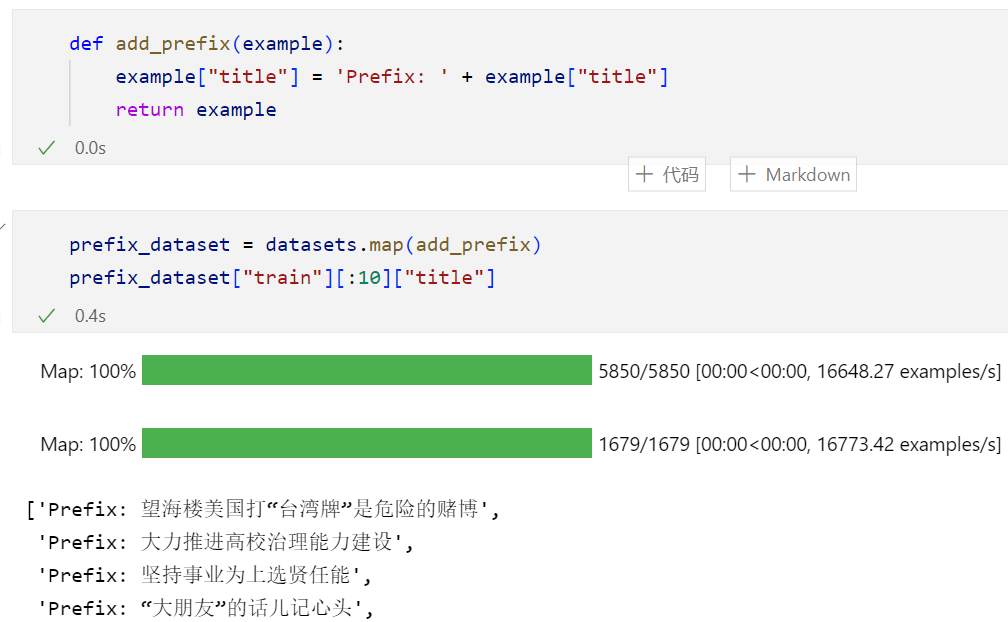
如果现在我们想要对title加上一个前缀,我们就可以用到这个map的方法,来对所哟数据实现这个样一个操作:
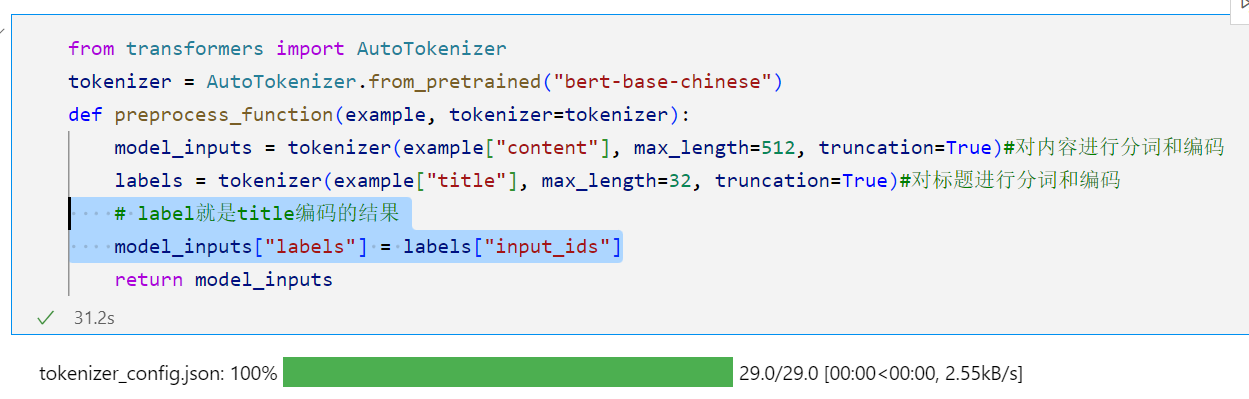
如何将这个和tokenizer结合起来使用呢?
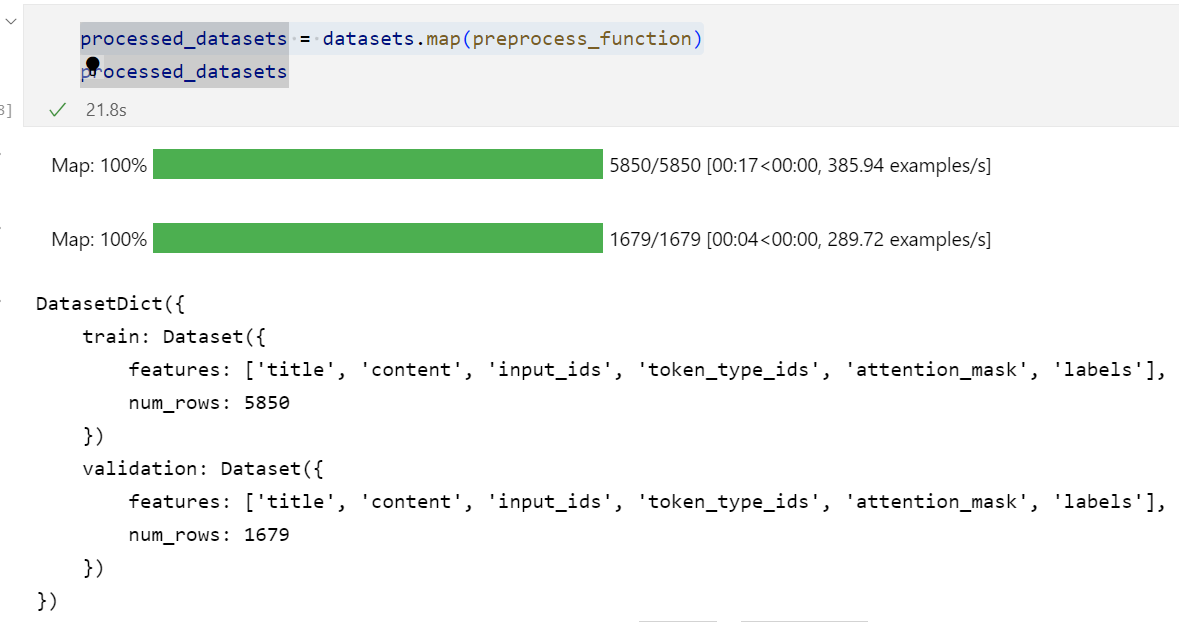
可以直观地看到:
这段代码使用了
datasets.map()方法来对数据集中的每个示例应用preprocess_function预处理函数。在
preprocess_function函数中,我们使用了BERT分词器对内容和标题进行了分词和编码操作。model_inputs字典中的键包括了原始数据中的"title"和"content",以及分词和编码后的结果,如"input_ids"、"token_type_ids"和"attention_mask"。当使用
datasets.map()方法对数据集进行映射时,会将预处理函数应用于数据集中的每个示例,并将处理后的结果作为新的数据集返回。因此,
processed_datasets是经过预处理后的新数据集,其中每个示例包含了原始数据的"title"和"content",以及分词和编码后的结果,如"input_ids"、"token_type_ids"、"attention_mask"和"labels"。
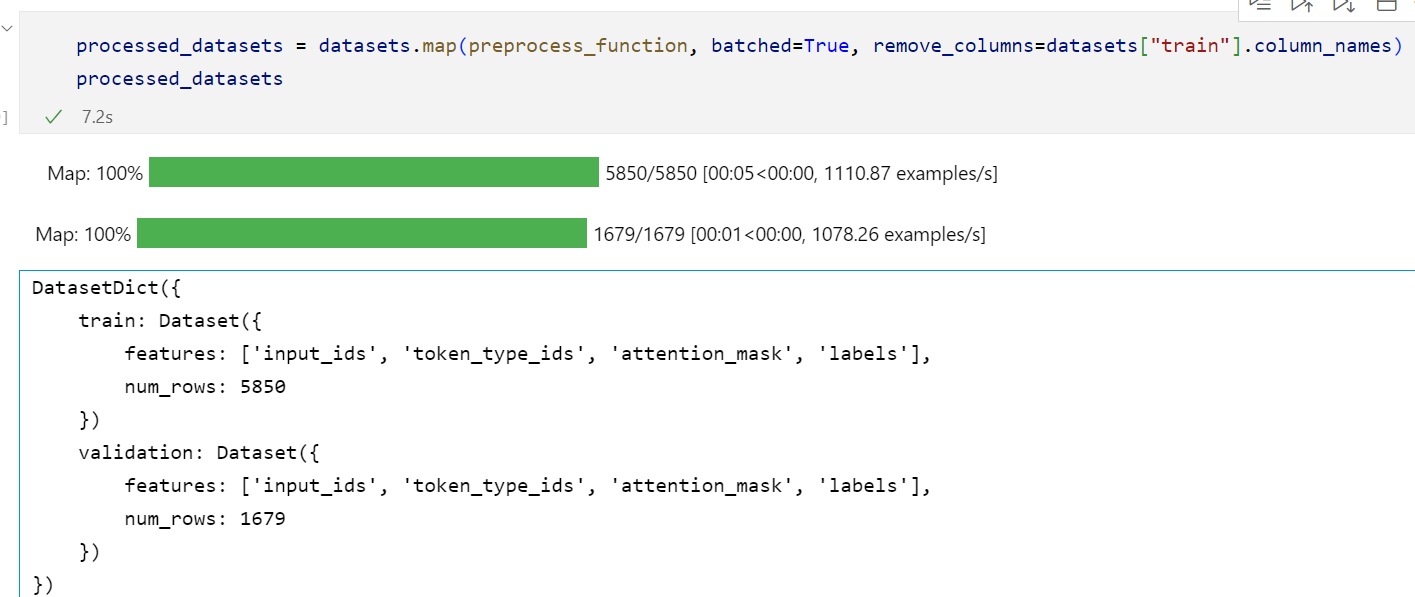
用批处理更快:

也可以多线程操作,但是这样要注意确保线程之间能够共享tokenizer。
def preprocess_function(example, tokenizer=tokenizer):

如果我们想要在输出的数据中去掉一些字段,可以使用remove_columns
2.8 保存与加载:
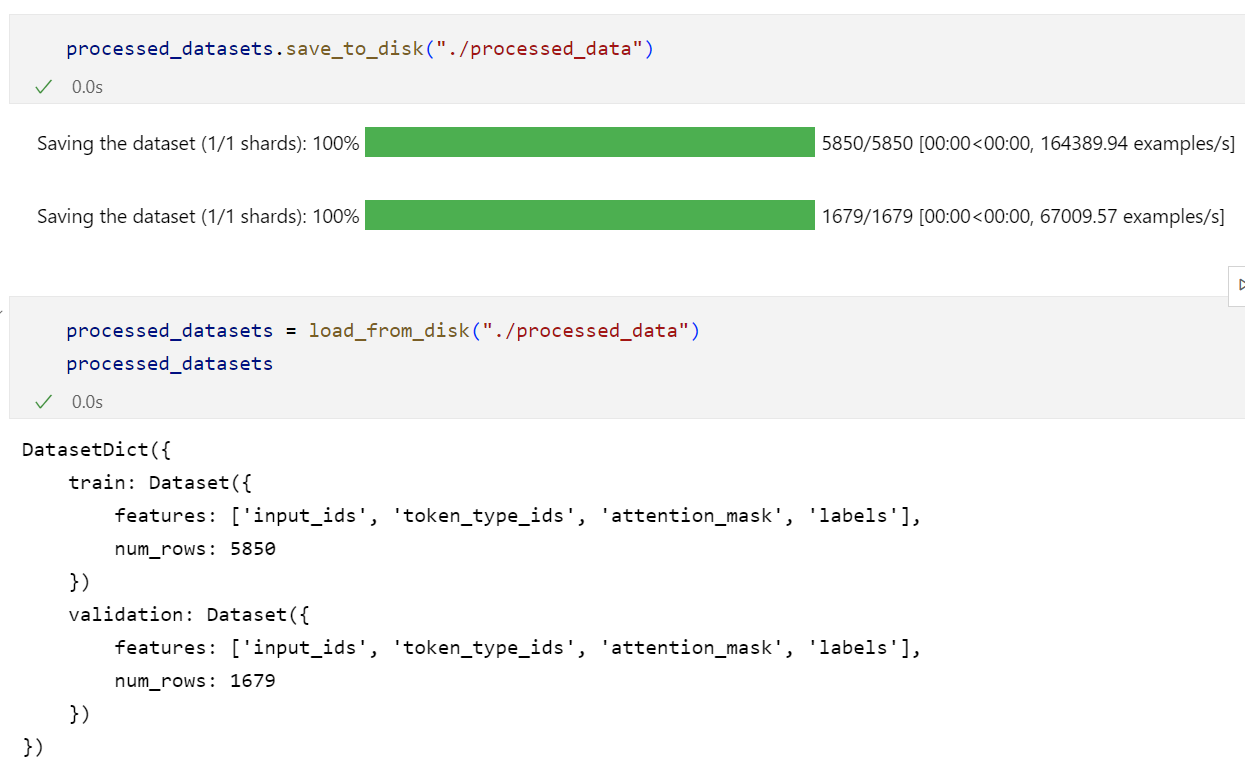
使用save_to_disk和load_from_disk即可:
3 Datasets加载本地数据集:


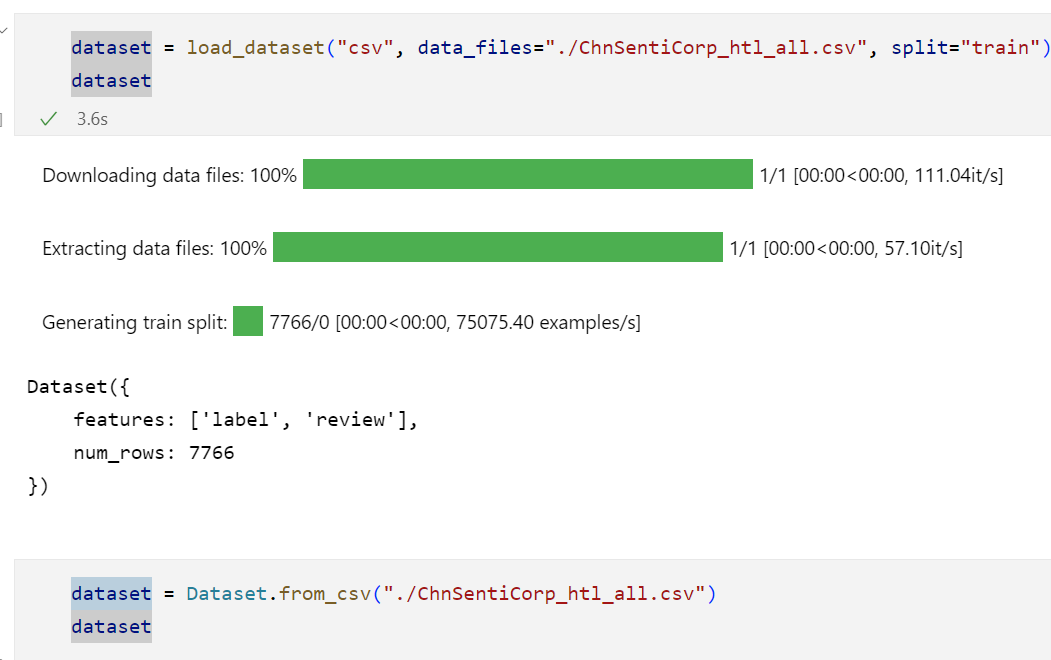
3.1 加载单个文件:
这两种加载方式都可以:
3.2 加载一个文件夹下的所有文件:
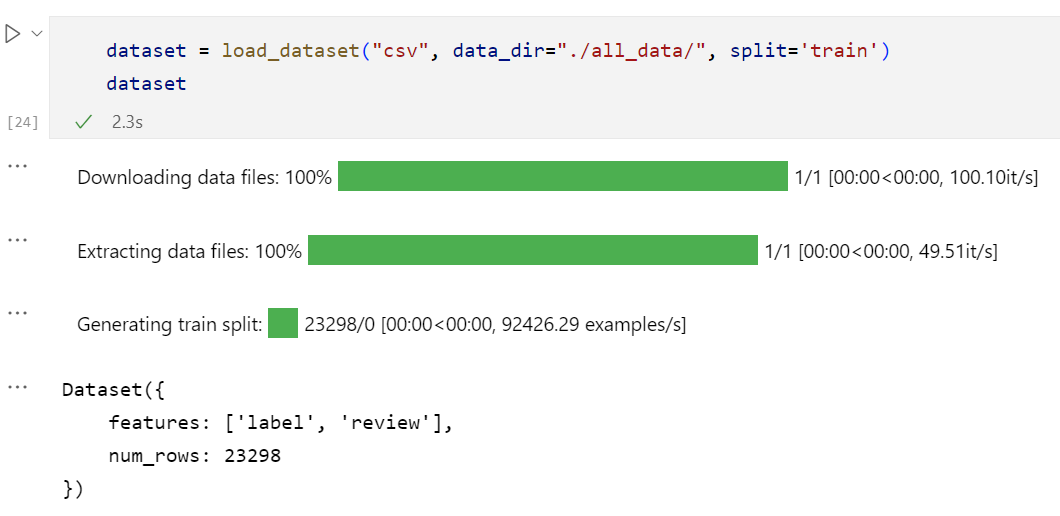
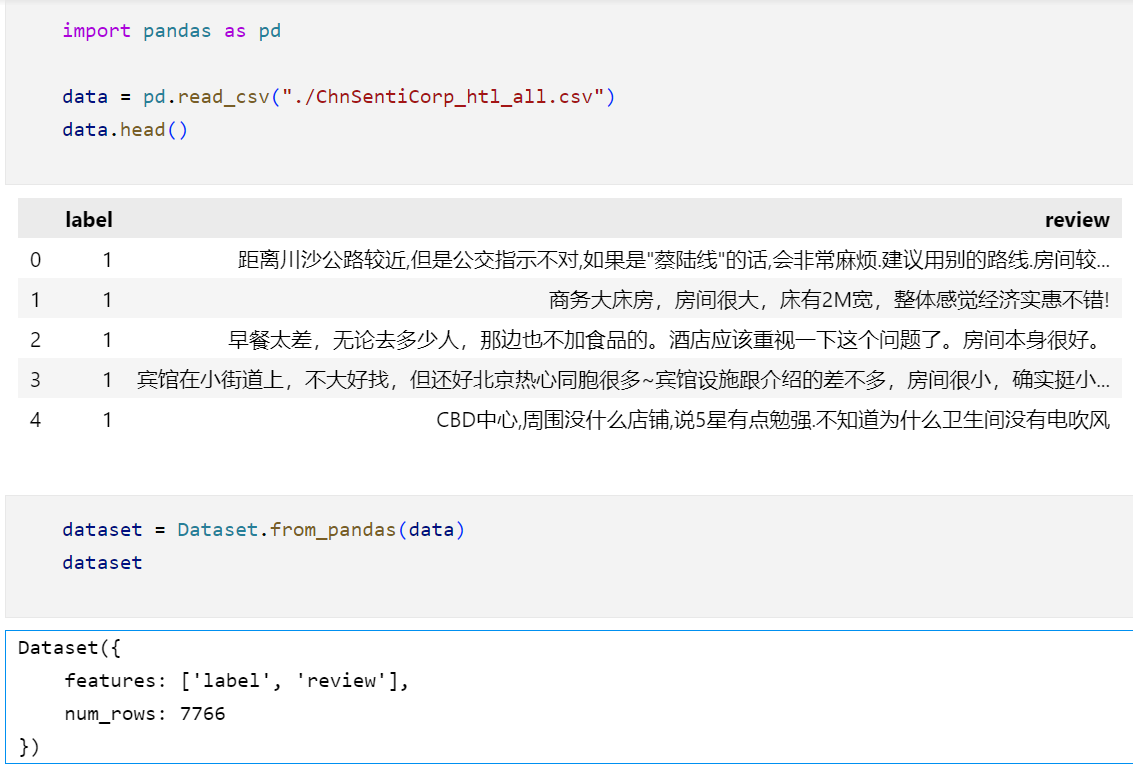
3.3 将其他格式数据转换成为dataset:
可以看到可以通过from_pandas将panda类型的数据转换为Dataset
需要注意的是,list型的数据需要指定字段,单纯的list是无法被理解的:

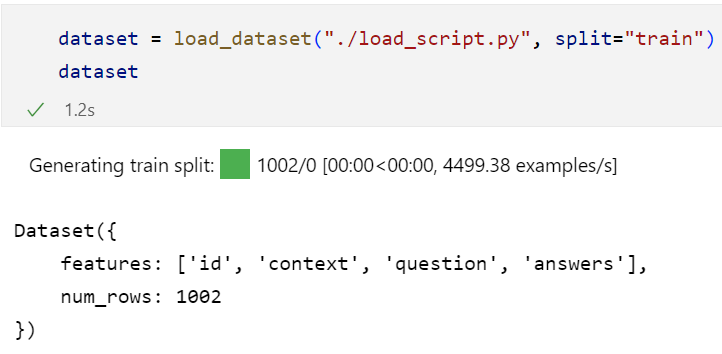
通过自定义加载脚本加载数据集:
可以通过load_dataset,但是最后得到的效果并不是很好
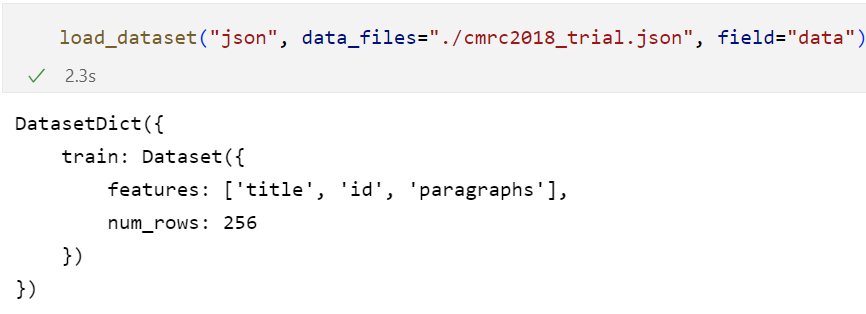
所以也可以通过自己编写的脚本实现:

定义一个名为"CMRC2018TRIAL"的自定义数据集,继承了
datasets.GeneratorBasedBuilder类。在
_info方法中,定义了数据集的信息,包括描述和特征。数据集的特征定义了数据集中每个示例的字段和类型。在这个例子中,数据集包含以下字段:
- "id":表示示例的唯一标识符,类型为字符串。
- "context":表示段落的内容,类型为字符串。
- "question":表示问题的内容,类型为字符串。
- "answers":表示答案的序列,每个答案包含两个字段:"text"表示答案的文本内容,类型为字符串;"answer_start"表示答案在段落中的起始位置,类型为整数。
在
_split_generators方法中,定义了数据集的划分生成器。这里使用了datasets.SplitGenerator来指定划分的名称为"train",并指定要读取的文件路径为"./cmrc2018_trial.json"。在
_generate_examples方法中,通过读取JSON文件并使用yield语句生成具体的样本。首先打开指定的文件,然后遍历文件中的数据。对于每个样本,遍历段落中的问题和答案。从样本中提取出上述定义的字段和特征,并使用yield语句将样本返回。通过以上定义的自定义数据集类,可以使用
datasets.load_dataset()方法加载并使用CMRC2018TRIAL数据集。
4 Datasets+DataCollator模型微调代码优化:
4.1 什么是DataCollator
DataCollator是一个用于处理数据批次的类,它用于将模型的输入数据组合成适合训练或评估的批次。在自然语言处理任务中,输入数据通常是以样本的形式存在,每个样本包含输入文本和对应的标签或目标值。
DataCollator类提供了一些常见的数据处理功能,例如将样本的输入文本进行填充(padding)以保证批次中的输入序列长度一致,以及将标签或目标值进行适当的处理。它可以根据具体任务的需求进行自定义配置,以满足特定的数据处理需求。在Hugging Face的
transformers库中,DataCollator类是用于处理模型输入数据的一个通用接口。具体的数据处理逻辑可以根据任务的不同而定制。例如,在序列分类任务中,可以使用DataCollatorForTokenClassification类来处理输入数据和标签的对应关系,将其组合成适合训练模型的批次。通过使用适当的
DataCollator类,可以有效地处理输入数据并生成模型训练所需的批次。这有助于简化数据处理过程,并提高训练和评估的效率。
4.2 如何使用Datacollator
我们将以DataCollatorWithPadding为例,仍然使用之前酒店好评、差评的数据集。
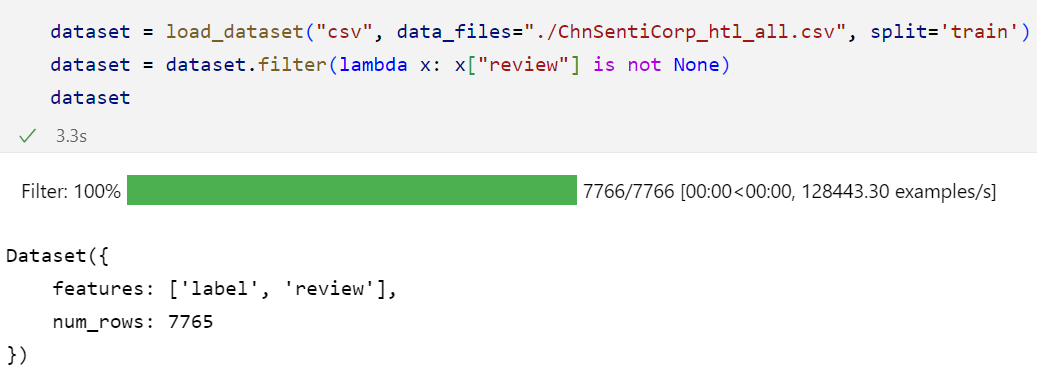
1)使用filter对空数据进行处理:
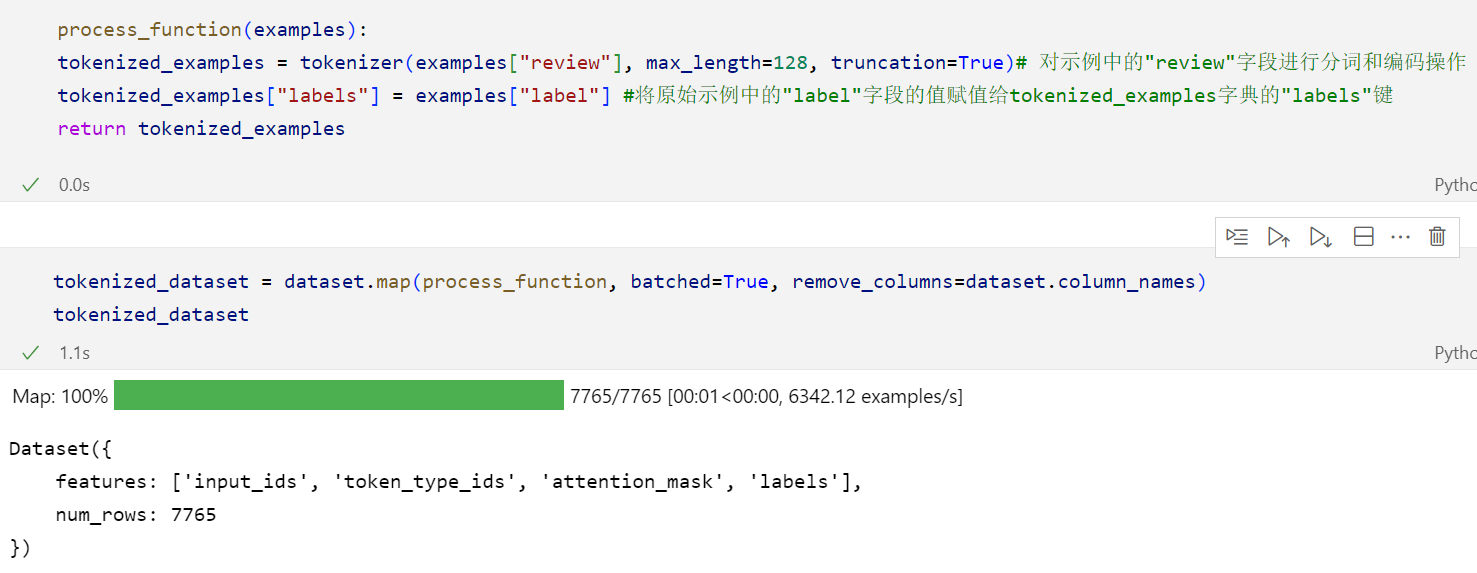
2)将输入示例中的文本字段进行分词和编码,并将标签信息与分词后的文本表示对应起来
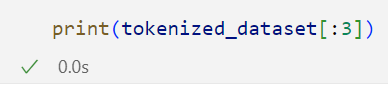
我们可以输出前几行数据看一下效果:
我们可以直观地看到,这是一个list嵌套list,那么我们希望使用这个Datacollator去转换为张量tensor。
{'input_ids': [[101, 6655, 4895, 2335, 3763, 1062, 6662, 6772, 6818, 117, 852, 3221, 1062, 769, 2900, 4850, 679, 2190, 117, 1963, 3362, 3221, 107, 5918, 7355, 5296, 107, 4638, 6413, 117, 833, 7478, 2382, 7937, 4172, 119, 2456, 6379, 4500, 1166, 4638, 6662, 5296, 119, 2791, 7313, 6772, 711, 5042, 1296, 119, 102], [101, 1555, 1218, 1920, 2414, 2791, 8024, 2791, 7313, 2523, 1920, 8024, 2414, 3300, 100, 2160, 8024, 3146, 860, 2697, 6230, 5307, 3845, 2141, 2669, 679, 7231, 106, 102], [101, 3193, 7623, 1922, 2345, 8024, 3187, 6389, 1343, 1914, 2208, 782, 8024, 6929, 6804, 738, 679, 1217, 7608, 1501, 4638, 511, 6983, 2421, 2418, 6421, 7028, 6228, 671, 678, 6821, 702, 7309, 7579, 749, 511, 2791, 7313, 3315, 6716, 2523, 1962, 511, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'labels': [1, 1, 1]}
3)使用这个Datacollator去转换为张量tensor
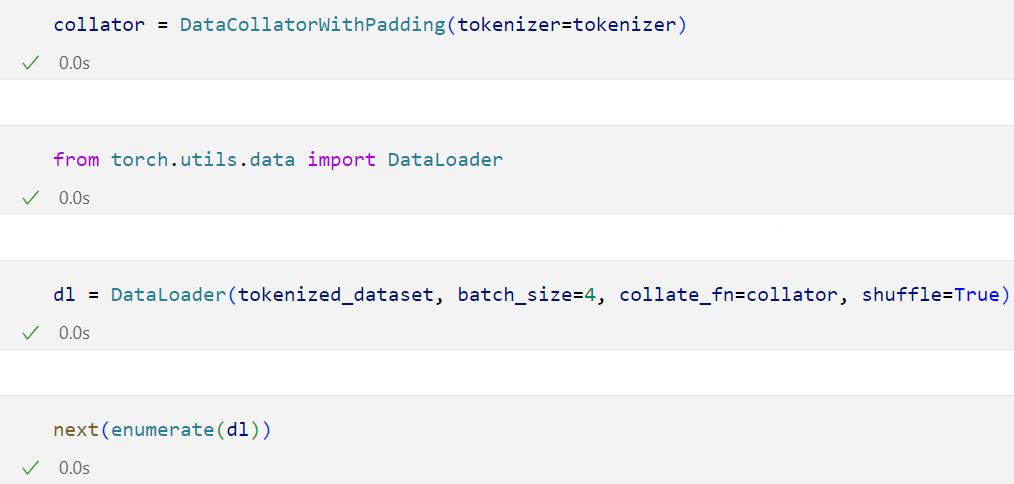

我们可以看到此时的数据已经被处理为张量形式了。
我们可以看到datacollator可以很方便地对数据进行一个规整,但是我们需要注意,如果数据集的字段中有除了以下四个字段以外的字段,那么就需要我们自定义datacollator:
![]()
5 之前酒店评价文本分类项目的改进
5.1 导包
和之前一致
5.2 加载数据集以及取消空缺数据

5.3 划分数据集:

5.4 创建Dataloader:


5.5 其他的:
剩余的步骤都和之前的一致

