
- 1React入门:基本环境搭建
- 2基于python的携程旅游数据采集作业,通过selenium爬取指定经典用户评论信息,将用户评论信息保存在本地数据库和excel文件。_python 爬取携程中某一酒店的用户评价并存储下来
- 3浅谈安数云智能安全运营管理平台:DCS-SOAR
- 4图神经网络实战(16)——经典图生成算法_图神经网络生成图
- 5自动创建XFRM虚拟接口的net2net形式的IPSEC_strongswan xfrm
- 6建筑设备【3】_用户终端是指共用天线电视的接线器,又称为?
- 7快速排序基于分治法的思想
- 8阿里云天池大赛赛题解析——机器学习篇 | 留言赠书
- 9【免费赠送源码】基于Hadoop平台的个性化图书推荐系统的研究
- 10Gitee码云 remote: Incorrect username or password ( access token )_gitee incorrect username or password (access token
Python爬取网页文本数据,从此告别复制粘贴 !_python爬取网页文字
赞
踩
如何爬一个网站的数据?大家熟知的就是python爬取网页数据,对于没有编程技术的普通人来说,怎么才能快速的爬取网站数据呢?今天给大家分享的这款免费爬取网页数据软件让您可以轻松地爬取网页指定数据,不需要你懂任何技术,只要你点点鼠标,就会采集网站任意数据!从此告别复制和粘贴的工作,爬取的数据可导出为Txt文档 、Excel表格、MySQL、SQLServer、 SQlite、Access、HTML网站等(PS:如果你爬取的是英文数据还可以使用自动翻译)
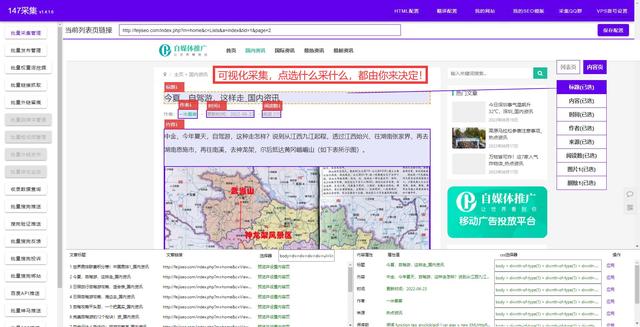
1. 网站数据爬取技巧
网站数据爬取技巧:
\1. 分析网站结构:查看网页的HTML源代码,找到数据所在的标签。
\2. 使用爬虫工具:如Scrapy、BeautifulSoup等。
\3. 设置请求头:防止被网站防爬虫机制识别。
\4. 实现分页爬取:爬取多页数据时要注意分页的参数。
\5. 遵守网站的使用条款:不要过于频繁爬取网站数据,避免影响网站正常运行。
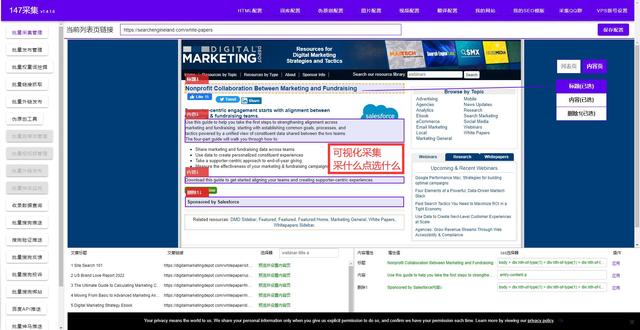
2. 利用Python爬取网站数据
Python爬虫是指利用Python语言编写的程序,通过请求网站数据并解析数据,从而抓取网站上的信息。主要使用的库有BeautifulSoup、 Requests、Scrapy等。爬虫可以用于抓取大量数据,供数据分析、搜索引擎优化等用途。
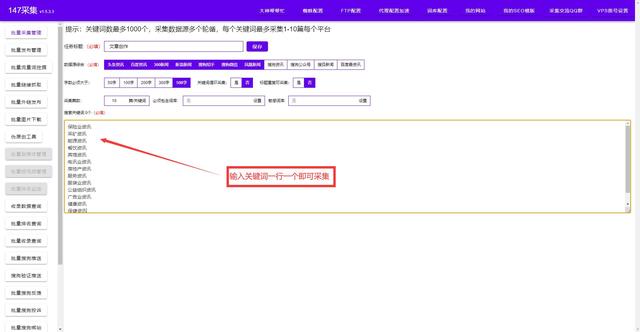
3. 使用爬虫工具爬取网站数据
爬虫(Crawler)是一种自动化的工具,用于抓取网络上的信息。爬虫通过自动地访问网页并提取数据,从而实现网络数据的采集。爬虫可以帮助收集大量的数据,便于分析和研究。爬取的数据可以是文本、图片、音频、视频等。使用爬虫前,需要对目标网站进行分析,确定需要爬取的数据,以及如何爬取数据。
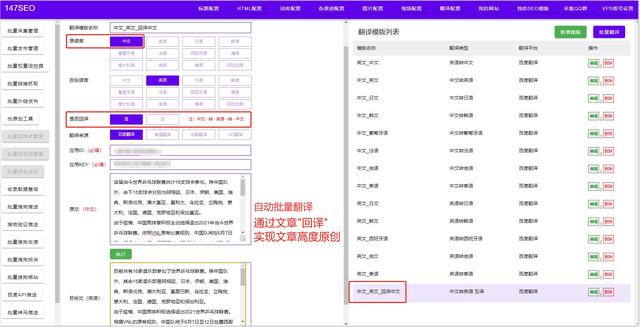
4. 数据清洗与处理的技巧
数据清洗和处理的技巧是数据分析中的一个关键步骤,它可以提高数据的质量和准确性。
常用的技巧包括:
-
缺失数据处理:如删除、插补或填充。
-
数据格式转换:如将字符串转换为数字。
-
异常值处理:如删除、替换或修正。
-
重复数据处理:如删除或合并。
-
数据归一化:如标准化或归一化处理。
-
数据规约:如汇总或聚合。

5. 爬取网站数据的法律和道德问题
爬取网站数据是指通过自动化工具或程序从网站上抓取数据的行为。爬取网站数据存在法律和道德问题,因为它可能侵犯网站所有者的隐私、版权、商业机密等权益。爬取网站数据需要遵循一些法律法规,如计算机犯罪法以及各国关于数据保护和隐私的法律。此外,爬取网站数据也需要遵循道德原则,例如不滥用从网站上获取的数据,不进行非法营利等。
以上就是今天的全部内容分享,觉得有用的话欢迎点赞收藏哦!
Python经验分享
学好 Python 不论是用于就业还是做副业赚钱都不错,而且学好Python还能契合未来发展趋势——人工智能、机器学习、深度学习等。
小编是一名Python开发工程师,自己整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
小编为对Python感兴趣的小伙伴准备了以下籽料 !
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑培训的!
- 学习时间相对较短,学习内容更全面更集中
- 可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
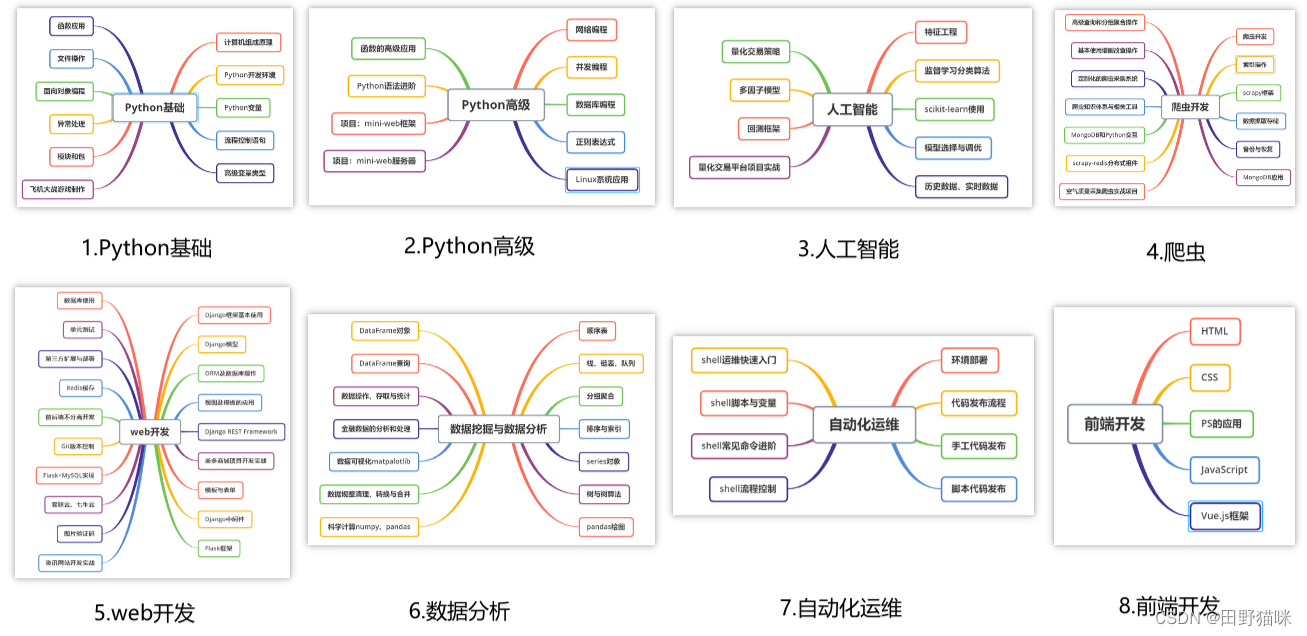
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
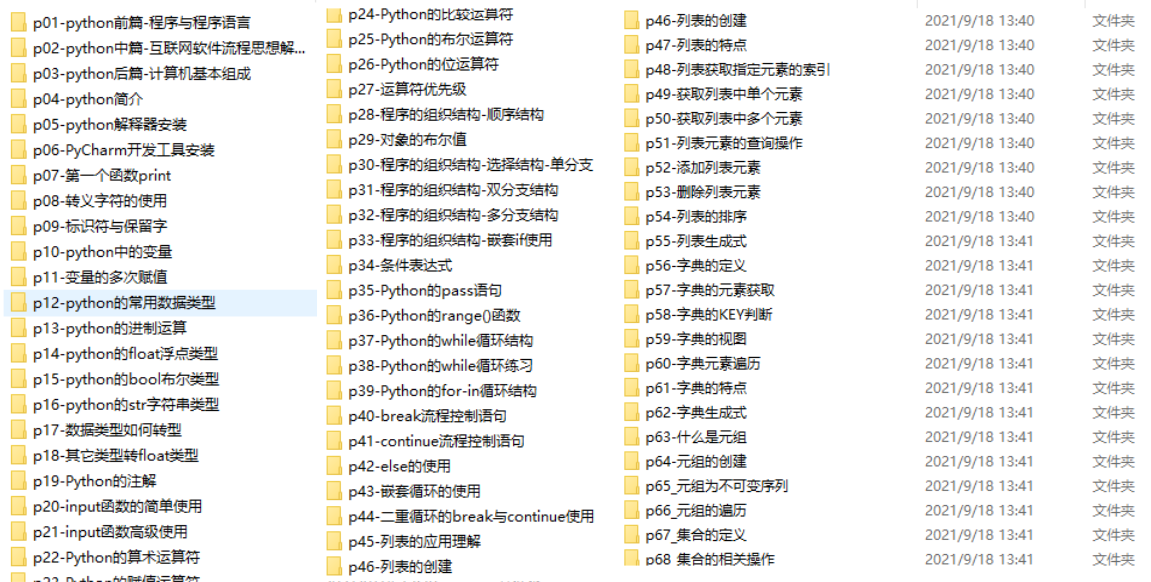
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
我已经上传至CSDN官方,如果需要可以扫描下方官方二维码免费获取【保证100%免费】

*今天的分享就到这里,喜欢且对你有所帮助的话,记得点赞关注哦~下回见 !


