
热门标签
当前位置: article > 正文
用百度进行爬虫练习和常见的问题_百度的反扒
作者:酷酷是懒虫 | 2024-07-18 12:27:54
赞
踩
百度的反扒
用百度进行爬虫练习和常见的问题
目标
- 确认url
- 向百度发送请求
- 获取响应
- 获取到百度首页的数据保存
工具
谷歌浏览器
pycharm
执行
首先这里使用的谷歌浏览器(默认打开百度)
#导入requrests 模块
import requests
# 1.确认url
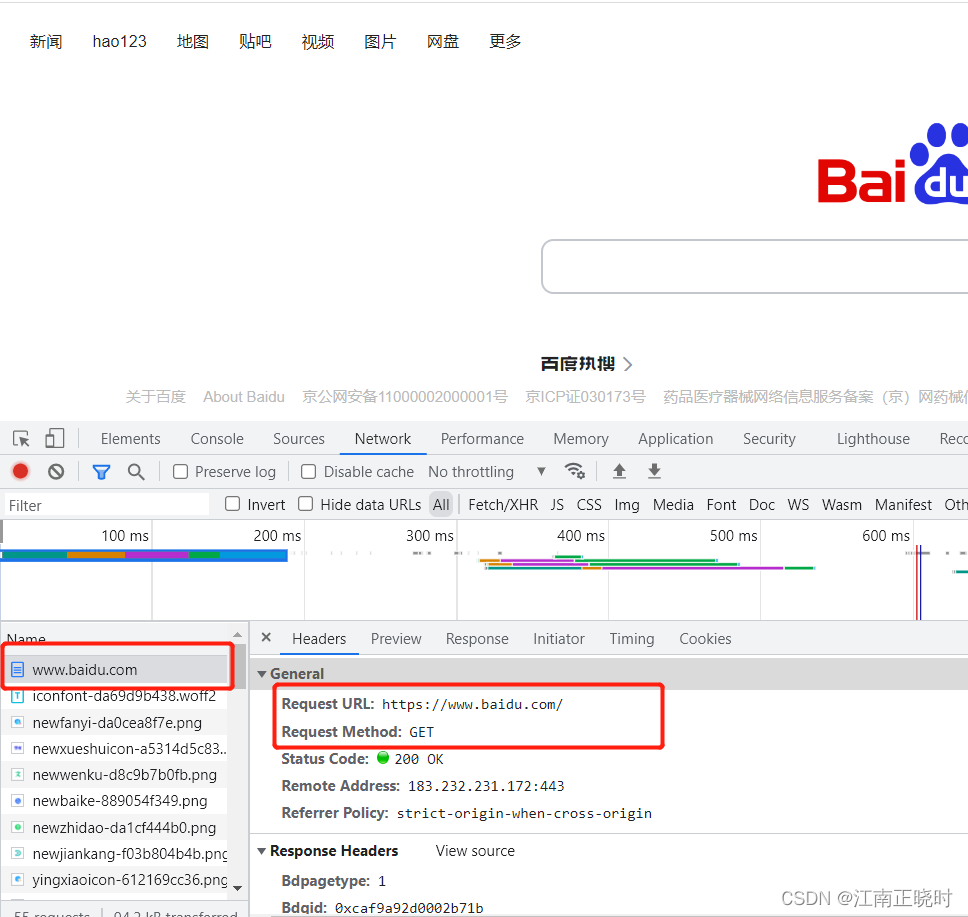
#查看百度界面
#按f12——>network——>刷新一下界面——>百度搜索——>Header(确认url和请求方法)
url="https://www.baidu.com/"
# 2.发送请求获得响应
# 确认请求方法 Method:GET
response=requests.get(url=url)
# 查看响应内容 文本内容 <Response[200]> 响应成功
print(response)
# 3.确认编码格式
response.encoding="utf-8"
# 4 保存到 html 文件
with open("百度一下.html","w",encoding="utf-8") as file1:
# 文件对象 的write方法只能写入字符串类型数据 重点
file1.write(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
可能出现的问题
1.反扒,安全认证不通过
遇到错误
raise SSLError(e, request=request)
requests.exceptions.SSLError: 。。。
原因:被反扒了 绕过ssl验证
解决方法:response=requests.get(url=url,verify=False)
来跳过安全验证
- 1
- 2
- 3
2.返回值是200,输出的响应结果里出现乱码
原因没有指定编解码格式
可以查看返回值的编解码
code=response.encoding
print(code)
设置urf-8
response.encoding="utf-8"
- 1
- 2
- 3
- 4
- 5
- 6
3.输出结果无法用浏览器打开
原因:浏览器设置环境变量,设置一下即可
- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/845655
推荐阅读
相关标签

