
- 1React入门:基本环境搭建
- 2基于python的携程旅游数据采集作业,通过selenium爬取指定经典用户评论信息,将用户评论信息保存在本地数据库和excel文件。_python 爬取携程中某一酒店的用户评价并存储下来
- 3浅谈安数云智能安全运营管理平台:DCS-SOAR
- 4图神经网络实战(16)——经典图生成算法_图神经网络生成图
- 5自动创建XFRM虚拟接口的net2net形式的IPSEC_strongswan xfrm
- 6建筑设备【3】_用户终端是指共用天线电视的接线器,又称为?
- 7快速排序基于分治法的思想
- 8阿里云天池大赛赛题解析——机器学习篇 | 留言赠书
- 9【免费赠送源码】基于Hadoop平台的个性化图书推荐系统的研究
- 10Gitee码云 remote: Incorrect username or password ( access token )_gitee incorrect username or password (access token
千亿大模型来了!通义千问110B模型开源!_通义还发布开源模型qwen1.5-110b
赞
踩
近期,在开源社区中,一系列具有千亿参数规模的大模型陆续出现,这些模型在各类评测中取得了卓越的成绩。通义千问团队宣布开源了一个1100亿参数的Qwen1.5系列首个千亿参数模型——Qwen1.5-110B。该模型在基础能力评估中与Meta-Llama3-70B相媲美,并在Chat评估中表现出色,包括MT-Bench和AlpacaEval 2.0。
Qwen1.5-110B与其他Qwen1.5模型类似,采用了相同的Transformer解码器架构。它引入了分组查询注意力(GQA),使得模型在推理时更加高效。此外,该模型支持32K tokens的上下文长度,并具备多语言特性,支持英语、中文、法语、西班牙语、德语、俄语、日语、韩语、越南语、阿拉伯语等多种语言。
下面是关于基础语言模型效果的评估,并与最近的SOTA语言模型Meta-Llama3-70B以及Mixtral-8x22B进行了比较。

上述结果显示,千问110B模型在基础能力方面至少与Llama-3-70B模型相媲美。在这个模型中,没有对预训练的方法进行大幅改变,因此110B模型和72B相比的性能提升主要来自于增加模型规模。
在MT-Bench和AlpacaEval 2.0上进行了Chat评估,结果如下:
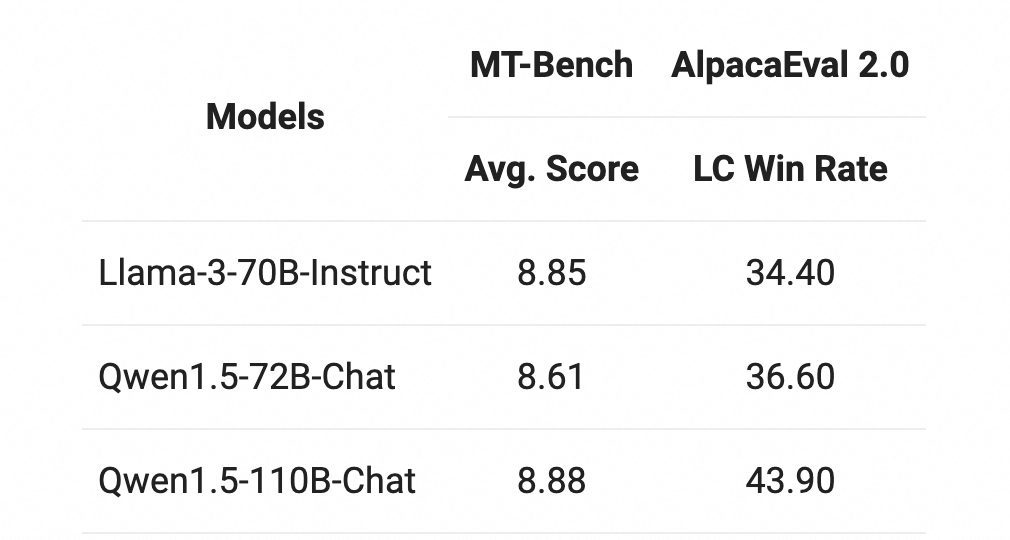
与之前发布的Qwen1.5-72B模型相比,在两个Chat模型的基准评估中,110B表现显著更好。评估结果的持续改善表明,即使在没有大幅改变后训练方法的情况下,更强大、更大规模的基础语言模型也可以带来更好的Chat模型。
Qwen1.5-110B是Qwen1.5系列中规模最大的模型,也是该系列中首个拥有超过1000亿参数的模型。它在与最近发布的SOTA模型Llama-3-70B的性能上表现出色,并且明显优于72B模型。这告诉我们,在模型大小扩展方面仍有很大的提升空间。虽然Llama-3的发布表明预训练数据规模具有重要意义,但我们相信通过在未来的发布中同时扩展数据和模型大小,我们可以同时获得两者的优势。敬请期待Qwen2!
实战:

