
- 1Hive中的DDL操作_hive ddl
- 2Python 基本语法_class int
- 3WebSocketServer的使用(@ServerEndpoint添加过滤和token认证)_@serverendpoint websocketserver
- 4android fragment重用,如何在Fragment中重用onNewIntent()方法?
- 5为什么用Python开发桌面应用程序_用python做桌面应用
- 6全面解读视觉大模型-视觉Transformer原理、应用、优缺点以及未来发展趋势
- 78 个流行的 Python 可视化工具包,你喜欢哪个?_哪个不是python中常用的可视化工具_python 画图可视化包的对比
- 8Android主流插件化_android 插件化
- 9深入理解Java类加载器(ClassLoader)
- 10真是恍然大悟啊!腾讯、网易必问的20道题Android面试题,架构师必备技能_猎聘网android 面试题
Word2vec词向量文本分析详解
赞
踩
CSDN话题挑战赛第2期
参赛话题:学习笔记
Word2vec词向量文本分析详解
一、Word2vec简介
在NLP领域中,词向量是一项非常重要的技术,词向量表示中,最有名也是最简单的算法是one-hot,one-hot在处理文本时首先将文本中的词语形成一个不重复的词库,one-hot的维度由词库的大小决定,有多少词语,矩阵就要扩大到多少维,对于庞大的语料库来说,计算量和存储量都是很大的问题,这是 one-hot的第一个缺点—维度灾难;第二个缺点是无法度量词语之间的相似性。
由此提出采用词向量来表示文本,具体表示为一串数字(实数),这样有限的维度就可以表示无数的词语。而表示词向量的这串数字就是由Word2vec得来的。
重要假设:文本中离得越近的词语相似度越高。
在Word2vec中采用CBOW和skip-gram这两个模型来计算词向量矩阵,CBOW采用上下文词来预测中心词,而skip-gram则采用中心词预测上下文词。在实际运用中,我们通常采用skip-gram模型。
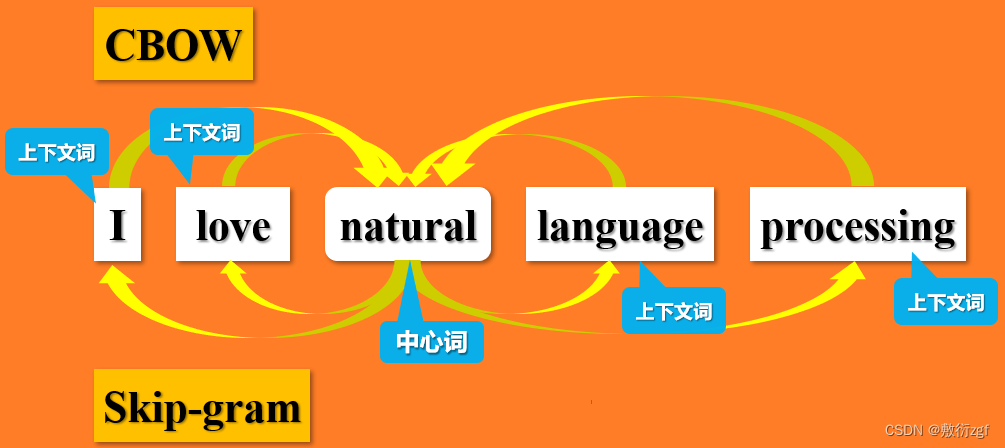
在上面的描述中,我们提到了上下文词和中心词两个概念,那么什么上下文词,什么是中心词呢?
通常我们需要定义一个窗口大小,来确定中心词周围包含哪些上下文词.例如,当窗口大小定义为 2

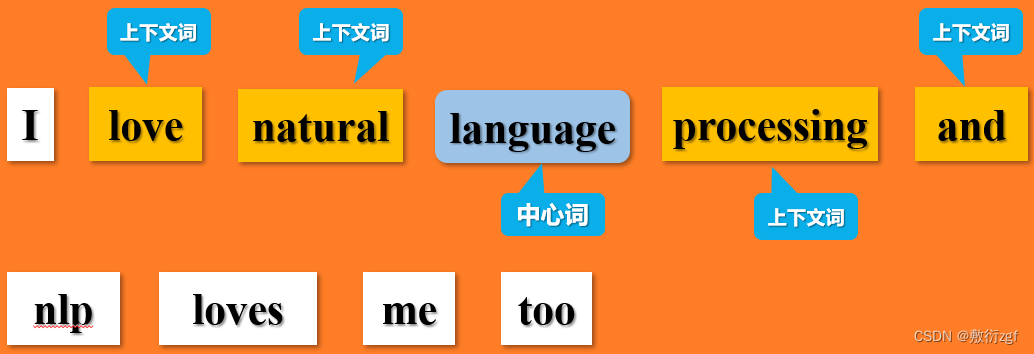
依次类推!
词向量将词语具体表示为一串数字,那么这串数字的具体意思以及它的具体效果我们很难通过直接观察得出结论,但我们可以通过一些具体的实验对词向量进行评估。
二、word2vec的缺点
1.没有考虑多义词,没有办法根据语境动态调整词向量;
2.窗口长度有限,只能考虑周围的几个词语;
3.没有考虑全局的文本信息;
4.并不是严格意义上的语序。
三、评估词向量
方法一: 对于文本来说,我们可以通过输出与特定词语相关度较高的词语来观察效果;
1.导入第三方库
import jieba
import re
import numpy as np
from sklearn.decomposition import PCA
import gensim # 主要是gensim做词向量训练
from gensim.models import Word2Vec
import matplotlib.pyplot as plt
import matplotlib
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.进行分词
f = open("Harry Potter.txt", 'r',encoding='utf-8') #读入文本
lines = []
dic_file = "E:/jupyterCode/word2vec/stop_dic/dict.txt" # 存放用户自定义词汇,例如网络热词,在分词时不能拆开
jieba.load_userdict(dic_file)
for line in f: #分别对每段分词
temp = jieba.lcut(line) #结巴分词 精确模式 cut()表示全模式
words = []
for i in temp:
#过滤掉所有的标点符号
i = re.sub("[\s+\.\!\/_,$%^*(+\"\'””《》]+|[+——!,。?、~@#¥%……&*():;‘-]+|[他,她]", "", i)
if len(i) > 0:
words.append(i)
if len(words) > 0:
lines.append(words)
print(lines[0:5])#预览前5行分词结果
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

3.模型训练
# 调用Word2Vec训练
# 参数:lines :分好词的文本 vector_size: 词向量维度;window: 上下文的宽度,min_count为考虑计算的单词的最低词频阈值,将词频小于5的词语去掉
model = Word2Vec(lines,vector_size = 20, window = 2 , min_count = 3, epochs=7, negative=10,sg=0)
# epochs模型迭代次数 negative每次采集的负样本数 sg定义训练算法,默认情况下 ('sg=0'),使用 CBOW 否则 ('sg=1'),则采用skip-gram
print("哈利的词向量:\n",model.wv.get_vector('哈利')) # 共计20个数值,表示哈利的词向量
print("\n和哈利相关性最高的前20个词语:")
model.wv.most_similar('哈利', topn = 20)# 与哈利最相关的前20个词语
- 1
- 2
- 3
- 4
- 5
- 6
- 7

方法二: 通过python可视化,观察相似度较高的词语是否聚集在一起。
可视化
# 将词向量投影到二维空间 原先定义的vector_size: 词向量维度 为20
rawWordVec = []
word2ind = {}
for i, w in enumerate(model.wv.index_to_key): #index_to_key 序号,词语
rawWordVec.append(model.wv[w]) #词向量
word2ind[w] = i #{词语:序号}
rawWordVec = np.array(rawWordVec)
# 经过 PCA 处理的数据中的各个样本之间的关系往往更直观,它是一种非常常用的数据分析和预处理工具。PCA 处理之后的数据各个维度之间是线性无关的,通过剔除方差较小的那些维度上的数据我们可以达到数据降维的目的
X_reduced = PCA(n_components=2).fit_transform(rawWordVec) # 采用PCA主成分分析对词向量降维 20维降到2维 ,这样我们就可以将一列作为x轴,一列作为y周,将数据映射到图表中
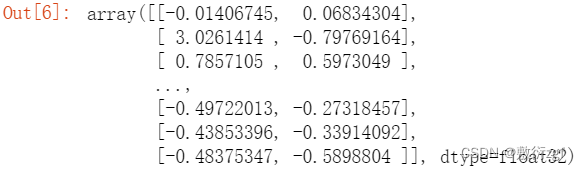
rawWordVec #降维之前20维
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

X_reduced #降维之后2维
- 1
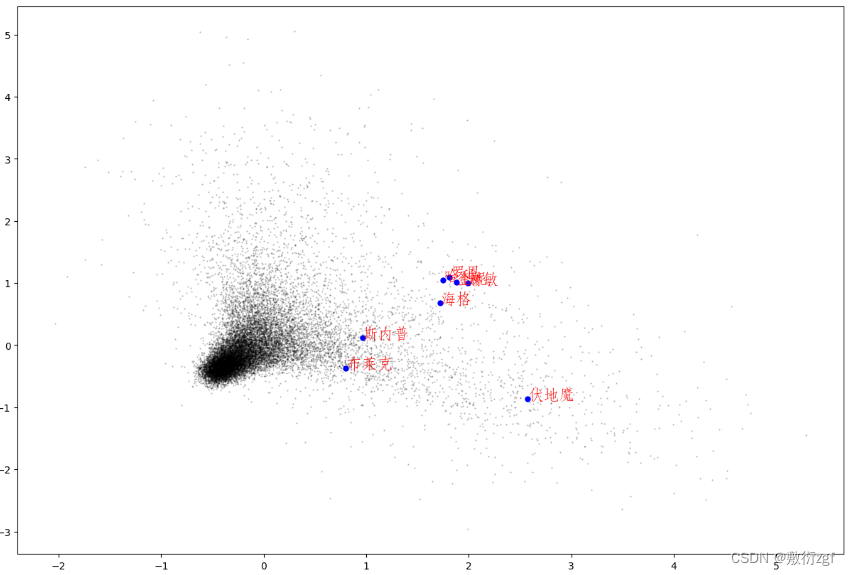
# 绘制星空图 # 绘制所有单词向量的二维空间投影 fig = plt.figure(figsize = (15, 10)) # 指定figure的宽和高,单位为英寸 ax = fig.gca() # ax.set_facecolor('white') # 设置轴背景颜色 # 绘制二维线图 X_reduced[:,n]表示在全部数组(维)中取第n个数据 markersize:标记尺寸的大小 # 加权系数alpha是提高预测精度。根据实践经验,alpha的值一般以0.1~0.3为宜。 # 选择alpha的一些基本准则,如果序列的基本趋势比较稳,预测偏差由随机因素造成,则alpha值应取小一些。如果预测目标的基本趋势已发生系统地变化,则apha应取值大一些 ax.plot(X_reduced[:, 0], X_reduced[:, 1], '.', markersize = 1, alpha = 0.3, color = 'black') # 绘制几个特殊单词的向量 words = ['哈利','罗恩', '金妮', '赫敏', '海格', '斯内普','伏地魔','布莱克'] # 注意特殊单词不能再分词时被拆开 # 设置中文字体 否则乱码 zhfont1 = matplotlib.font_manager.FontProperties(fname='./华文仿宋.ttf', size=16) # FontProperties类用于存储和操作字体的属性 for w in words: if w in word2ind: ind = word2ind[w] xy = X_reduced[ind] plt.plot(xy[0], xy[1], '.', alpha =1, color = 'blue',markersize=10) plt.text(xy[0], xy[1], w, fontproperties = zhfont1, alpha = 1, color = 'red')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
方法三: 类比实验
# 哈利-金妮=?-罗恩 # 采用向量的减法做关系类比
words = model.wv.most_similar(positive=['哈利', '罗恩'], negative=['金妮'])
words
- 1
- 2
- 3

可以在具体操作过程中,调节不同的参数,观察其产生的不同效果。

