
热门标签
热门文章
- 1java版家政预约上门系统全套源码,App端采用uniapp开发编写,可打包H5 、微信小程序、微信公众号、Android、IOS等。_家政上门软件源代码
- 2四非、双非计算机保研夏令营入营情况_北航计算机学院双非保研
- 3聊聊那些Git的基本概念_那聊聊git是干嘛的,常用命令有哪些,什么是分支?
- 4Apache相关配置----日志管理_apache日志配置
- 5【Git】为什么需要版本控制?版本控制工具有那些?_对项目为什么要进行版本控制
- 6Uni-app 跨平台应用开发指南_uni-app跨平台开发与应用
- 7掌握 Spring Boot 运行内存及内存参数设置:助力高效应用部署与优化_springboot设置内存大小
- 8Github 2024-06-23php开源项目日报Top10_php项目
- 9※【python自学】7个Python生态系统核心库,你值得拥有_python 生态位模型包
- 10高可用的分布式Hadoop大数据平台搭建,超详细,附代码。_hadoop高可用搭建步骤
当前位置: article > 正文
hadoop-mapreduce-yarn-配置-yarn高可用配置(HA)(学习)_hadoop yarn配置
作者:酷酷是懒虫 | 2024-07-19 15:52:50
赞
踩
hadoop yarn配置
1、hadoop三大组件
hdfs(分布式存储)
mapreduce(分布式计算)
yarn(分布式调度)
2. 配置mapreduce
2.1 配置mapred-env.sh文件
# 在hadoop配置文件中
vim mapred-env.sh
# 新增内容
export JAVA_HOME=jdk所在目录
# 设置JobHistorySer\ver进程内存为1G :
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
# 设置日志级别为INF0 :
export HADOOP_MAPRED_ROOT_LOGGER=INF0,RFA
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2 配置mapred-site.xml文件
vim mapred-site.xml
- 1
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>MapReduce的运行框架设置为YARN</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> <description>历史服务器通讯端口为node1:10020</description> </property> <property> <name>mapreduce.webapp.address</name> <value>node1:19888</value> <description>历史服务器的web端口为node1的19888</description> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/home/kk/data/mr-history/tmp</value> <description>历史信息在hdfs的记录临时路径</description> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/home/kk/export/soft/hadoop336</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/home/kk/export/soft/hadoop336</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/home/kk/export/soft/hadoop336</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
3、配置yarn
3.1 配置yarn-env.sh文件
#配置jdk路径
export JAVA_HOME=jdk目录
#配置配置文件的路径
export HADOOP_CONF_DIR=hadoop配置文件hadoop安装文件号下/etc/hadoop目录路劲
#配置日志文件路径
export HADOOP_LOG_DIR=目录路劲
- 1
- 2
- 3
- 4
- 5
- 6
3.2 配置yarn-size.xml文件
vim yarn-size.xml
- 1
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>node11</value> <description>ResourceManager设置在node1节点上</description> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/home/kk/data/nodemanager-local</value> <description>nodeManager中间数据本地存储位置</description> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/home/kk/data/nodemanager-log</value> <description>nodemanager数据日志本地存储位置</description> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>为mapreduce程序开放shuffle服务</description> </property> <property> <name>yarn.log.server.url</name> <value>http://node11:19888/jobhistory/logs</value> <description>历史服务器url</description> </property> <property> <name>yarn.web-proxy.address</name> <value>node11:8089</value> <description>代理服务器主机和端口</description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description>开启日志聚合</description> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/home/kk/export/soft/hadoop336/logs</value> <description>程序日志HDFS的存储路径</description> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> <description>选择公平调度器</description> </property> <!-- Site specific YARN configuration properties --> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
4 服务启动
start-yarn.sh # 启动yarn
mapred --daemon start | stop historyserver # 历史服务器的启停
start-all.sh #启动全部
jps # 查看进程号
- 1
- 2
- 3
- 4
5 web页面访问
浏览器打开: http://resourceManager所在节点ip:8088

6、运行内置的mapreduce程序
对应的jar包在/soft/hadoop336/share/hadoop/mapreduce
文件夹下面
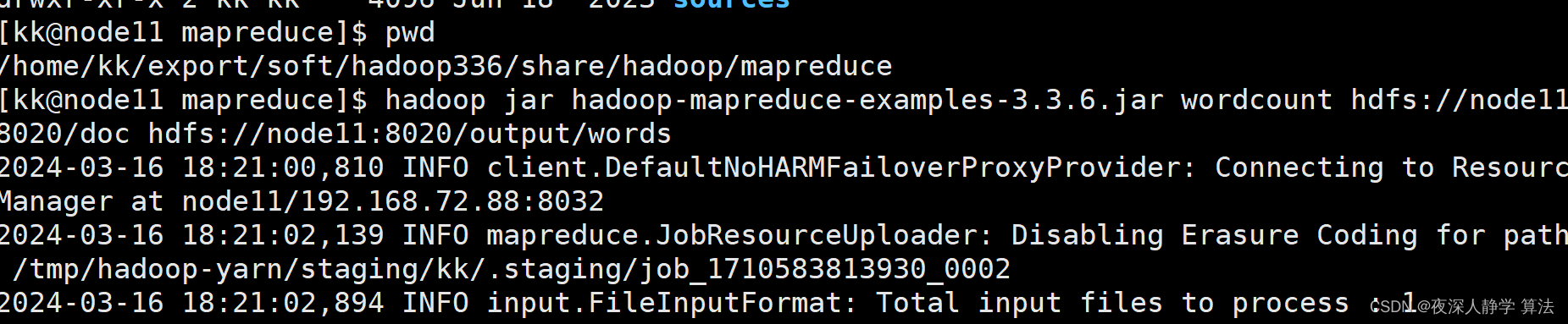
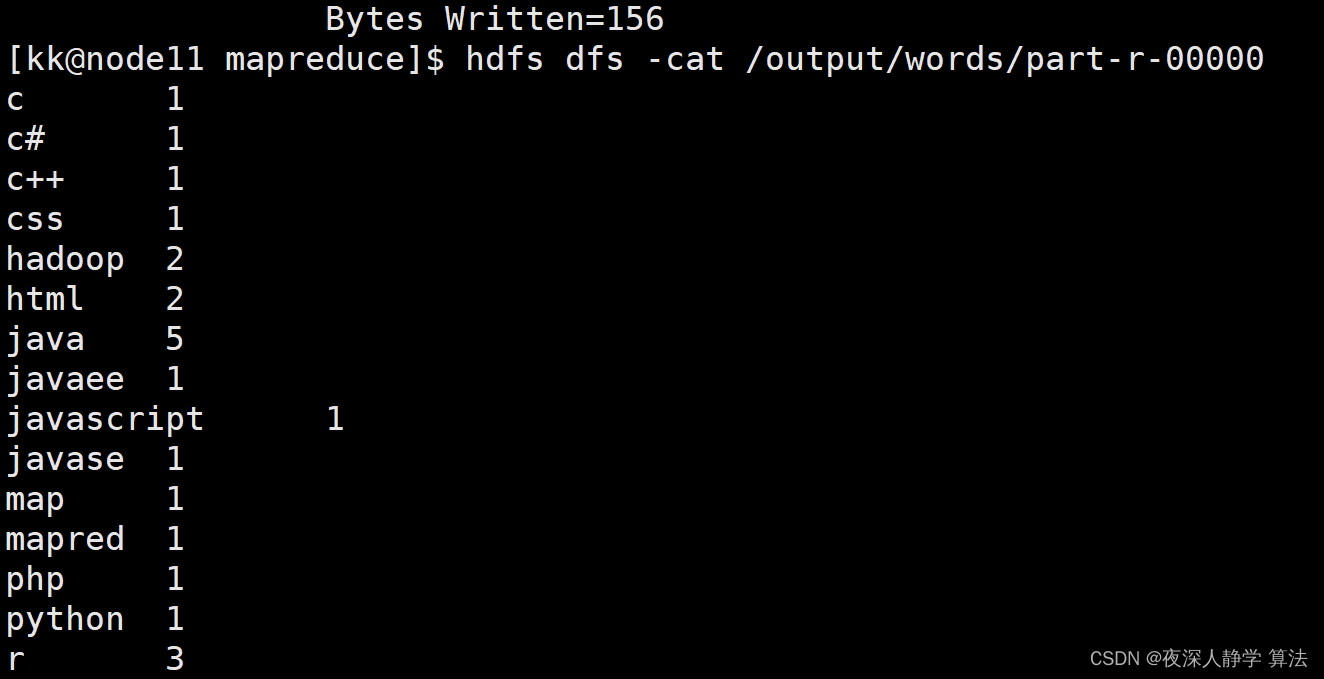
6.1 wordcount(单词计数程序)
hadoop jar hadoop-mapreduce-examples-3.3.6.jar wordcount hdfs://node11:8020/doc hdfs://node11:8020/output/words
- 1

6.2 pi(求圆周率)
# 三台机器1000个样本求π
hadoop jar hadoop-mapreduce-examples-3.3.6.jar pi 3 1000
- 1
- 2

7. yarn高可用(HA)配置
编写yarn-site.xml:
vim yarn-site.xml
# 添加如下内容
- 1
- 2
<property> <!--开启resourcemanager ha--> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <!--s--> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!--指定逻辑名称对应的主机名--> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node11</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node22</value> </property> <!--配置web端王文地址--> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>node11:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node22:8088</value> </property> <!--指定zookeeper节点--> <property> <name>hadoop.zk.address</name> <value>node11:2181,node22:2181,node33:2181</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
复制到其他节点中:
scp yarn-site.xml node22:`pwd`
scp yarn-site.xml node33:`pwd`
- 1
- 2
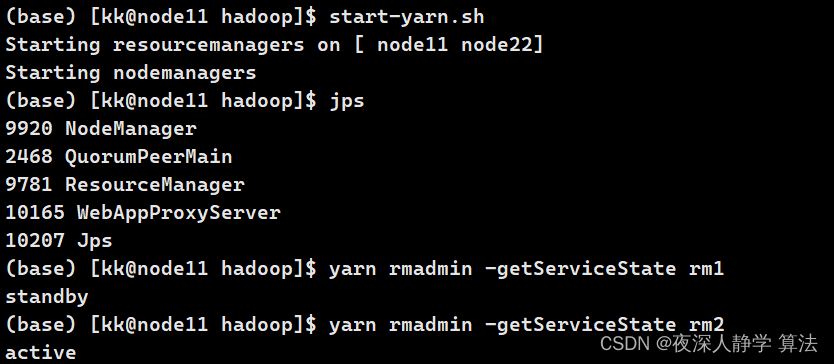
启动yarn进程:
start-yarn.sh
# 查看状态
yarn rmadmin -getAllServiceState # 查看全部
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
- 1
- 2
- 3
- 4
- 5
- 6
杀掉node2中的resourceManager进程:
skill 进程号
- 1
可见rm1已经变为了active状态:

声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

