
- 1STM32F103 IAP升级----Bootloader+APP(FreeRTOS)_stm32iap升级bootoader跳转到freertos列机
- 2【少儿编程Python:趣味编程,探索未来】第五章 算法与数据结构,编程的智慧结晶 / 第一节 数据结构的魔法仓库
- 3Apache HTTP server benchmarking tool(ab)-服务器基准测试工具一文上手(1)_压力测试报443
- 4Elasticsearch——Windows下ES集群部署 & Linux下ES单节点、集群部署_elasticsearch 单节点部署
- 5产品经理-一份标准需求文档的8个模块(14)
- 6pg数据库创建触发器_pg触发器
- 7bugfix与Cherry-Pick_we cherry pick relevant bug fixes from main branch
- 810 分钟了解 Kubernetes_kubernetes历史
- 9【基础算法总结】链表
- 10软件测试模型_软件测试中w模型的优点
图神经网络 PyG 入门介绍
赞
踩
原文出自这里
简介
Graph Neural Networks 简称 GNN,称为图神经网络,是深度学习中近年来一个比较受关注的领域。近年来 GNN 在学术界受到的关注越来越多,与之相关的论文数量呈上升趋势,GNN 通过对信息的传递,转换和聚合实现特征的提取,类似于传统的 CNN,只是 CNN 只能处理规则的输入,如图片等输入的高、宽和通道数都是固定的,而 GNN 可以处理不规则的输入,如点云等。 可查看【GNN】万字长文带你入门 GCN。
而 PyTorch Geometric Library (简称 PyG) 是一个基于 PyTorch 的图神经网络库,地址是:https://github.com/rusty1s/pytorch_geometric。它包含了很多 GNN 相关论文中的方法实现和常用数据集,并且提供了简单易用的接口来生成图,因此对于复现论文来说也是相当方便。用法大多数和 PyTorch 很相近,因此熟悉 PyTorch 的同学使用这个库可以很快上手。
torch_geometric.data.Data
节点和节点之间的边构成了图。所以在 PyG 中,如果你要构建图,那么需要两个要素:节点和边。PyG 提供了torch_geometric.data.Data (下面简称Data) 用于构建图,包括 5 个属性,每一个属性都不是必须的,可以为空。
-
x: 用于存储每个节点的特征,形状是
[num_nodes, num_node_features]。 -
edge_index: 用于存储节点之间的边,形状是
[2, num_edges]。 -
pos: 存储节点的坐标,形状是
[num_nodes, num_dimensions]。 -
y: 存储样本标签。如果是每个节点都有标签,那么形状是
[num_nodes, *];如果是整张图只有一个标签,那么形状是[1, *]。 -
edge_attr: 存储边的特征。形状是
[num_edges, num_edge_features]。
实际上,Data对象不仅仅限制于这些属性,我们可以通过data.face来扩展Data,以张量保存三维网格中三角形的连接性。
需要注意的的是,在Data里包含了样本的 label,这意味和 PyTorch 稍有不同。在PyTorch中,我们重写Dataset的__getitem__(),根据 index 返回对应的样本和 label。在 PyG 中,我们使用的不是这种写法,而是在get()函数中根据 index 返回torch_geometric.data.Data类型的数据,在Data里包含了数据和 label。
下面一个例子是未加权无向图 ( 未加权指边上没有权值 ),包括 3 个节点和 4 条边。
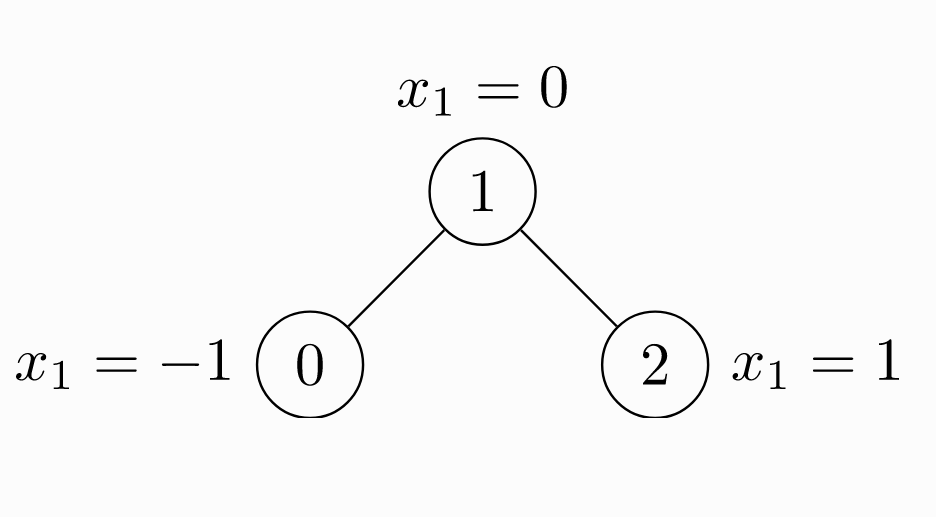
由于是无向图,因此有 4 条边:(0 -> 1), (1 -> 0), (1 -> 2), (2 -> 1)。每个节点都有自己的特征。上面这个图可以使用torch_geometric.data.Data来表示如下:
import torch from torch_geometric.data import Data # 由于是无向图,因此有 4 条边:(0 -> 1), (1 -> 0), (1 -> 2), (2 -> 1) edge_index = torch.tensor([[0, 1, 1, 2], [1, 0, 2, 1]], dtype=torch.long) # 节点的特征 x = torch.tensor([[-1], [0], [1]], dtype=torch.float) data = Data(x=x, edge_index=edge_index)
- 1
注意edge_index中边的存储方式,有两个list,第 1 个list是边的起始点,第 2 个list是边的目标节点。注意与下面的存储方式的区别。
import torch from torch_geometric.data import Data edge_index = torch.tensor([[0, 1], [1, 0], [1, 2], [2, 1]], dtype=torch.long) x = torch.tensor([[-1], [0], [1]], dtype=torch.float) data = Data(x=x, edge_index=edge_index.t().contiguous())
- 1
这种情况edge_index需要先转置然后使用contiguous()方法。关于contiguous()函数的作用,查看 PyTorch中的contiguous。
最后再复习一遍,Data中最基本的 4 个属性是x、edge_index、pos、y,我们一般都需要这 4 个参数。
有了Data,我们可以创建自己的Dataset,读取并返回Data了。
Dataset 与 DataLoader
PyG 的 Dataset继承自torch.utils.data.Dataset,自带了很多图数据集,我们以TUDataset为例,通过以下代码就可以加载数据集,root参数设置数据下载的位置。通过索引可以访问每一个数据。
from torch_geometric.datasets import TUDataset dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES') data = dataset[0]
- 1
在一个图中,由edge_index和edge_attr可以决定所有节点的邻接矩阵。PyG 通过创建稀疏的对角邻接矩阵,并在节点维度中连接特征矩阵和 label 矩阵,实现了在 mini-batch 的并行化。PyG 允许在一个 mini-batch 中的每个Data (图) 使用不同数量的节点和边。
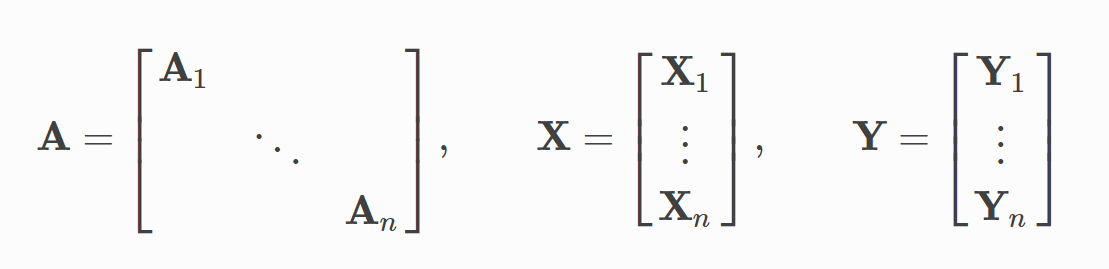
自定义 Dataset
尽管 PyG 已经包含许多有用的数据集,我们也可以通过继承torch_geometric.data.Dataset使用自己的数据集。提供 2 种不同的Dataset:
-
InMemoryDataset:使用这个
Dataset会一次性把数据全部加载到内存中。 -
Dataset: 使用这个
Dataset每次加载一个数据到内存中,比较常用。
我们需要在自定义的Dataset的初始化方法中传入数据存放的路径,然后 PyG 会在这个路径下再划分 2 个文件夹:
-
raw_dir: 存放原始数据的路径,一般是 csv、mat 等格式 -
processed_dir: 存放处理后的数据,一般是 pt 格式 ( 由我们重写process()方法实现)。
在 PyTorch 中,是没有这两个文件夹的。下面来说明一下这两个文件夹在 PyG 中的实际意义和处理逻辑。
torch_geometric.data.Dataset继承自torch.utils.data.Dataset,在初始化方法 __init__()中,会调用_download()方法和_process()方法。
def __init__(self, root=None, transform=None, pre_transform=None, pre_filter=None): super(Dataset, self).__init__() if isinstance(root, str): root = osp.expanduser(osp.normpath(root)) self.root = root self.transform = transform self.pre_transform = pre_transform self.pre_filter = pre_filter self.__indices__ = None # 执行 self._download() 方法 if 'download' in self.__class__.__dict__.keys(): self._download() # 执行 self._process() 方法 if 'process' in self.__class__.__dict__.keys(): self._process()
- 1
_download()方法如下,首先检查self.raw_paths列表中的文件是否存在;如果存在,则返回;如果不存在,则调用self.download()方法下载文件。
def _download(self): if files_exist(self.raw_paths): # pragma: no cover return makedirs(self.raw_dir) self.download()
- 1
_process()方法如下,首先在self.processed_dir中有pre_transform,那么判断这个pre_transform和传进来的pre_transform是否一致,如果不一致,那么警告提示用户先删除self.processed_dir文件夹。pre_filter同理。
然后检查self.processed_paths列表中的文件是否存在;如果存在,则返回;如果不存在,则调用self.process()生成文件。
def _process(self): f = osp.join(self.processed_dir, 'pre_transform.pt') if osp.exists(f) and torch.load(f) != __repr__(self.pre_transform): warnings.warn( 'The `pre_transform` argument differs from the one used in ' 'the pre-processed version of this dataset. If you really ' 'want to make use of another pre-processing technique, make ' 'sure to delete `{}` first.'.format(self.processed_dir)) f = osp.join(self.processed_dir, 'pre_filter.pt') if osp.exists(f) and torch.load(f) != __repr__(self.pre_filter): warnings.warn( 'The `pre_filter` argument differs from the one used in the ' 'pre-processed version of this dataset. If you really want to ' 'make use of another pre-fitering technique, make sure to ' 'delete `{}` first.'.format(self.processed_dir)) if files_exist(self.processed_paths): # pragma: no cover return print('Processing...') makedirs(self.processed_dir) self.process() path = osp.join(self.processed_dir, 'pre_transform.pt') torch.save(__repr__(self.pre_transform), path) path = osp.join(self.processed_dir, 'pre_filter.pt') torch.save(__repr__(self.pre_filter), path) print('Done!')
- 1
一般来说不用实现**downloand()**方法。
如果你直接把处理好的 pt 文件放在了self.processed_dir中,那么也不用实现process()方法。
在 Pytorch 的dataset中,我们需要实现__getitem__()方法,根据index返回样本和标签。在这里torch_geometric.data.Dataset中,重写了__getitem__()方法,其中调用了get()方法获取数据。
def __getitem__(self, idx): if isinstance(idx, int): data = self.get(self.indices()[idx]) data = data if self.transform is None else self.transform(data) return data else: return self.index_select(idx)
- 1
我们需要实现的是get()方法,根据index返回torch_geometric.data.Data类型的数据。
process()方法存在的意义是原始的格式可能是 csv 或者 mat,在process()函数里可以转化为 pt 格式的文件,这样在get()方法中就可以直接使用torch.load()函数读取 pt 格式的文件,返回的是torch_geometric.data.Data类型的数据,而不用在get()方法做数据转换操作 (把其他格式的数据转换为 torch_geometric.data.Data类型的数据)。当然我们也可以提前把数据转换为 torch_geometric.data.Data类型,使用 pt 格式保存在self.processed_dir中。
DataLoader
通过torch_geometric.data.DataLoader可以方便地使用 mini-batch。
from torch_geometric.datasets import TUDataset from torch_geometric.data import DataLoader dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True) loader = DataLoader(dataset, batch_size=32, shuffle=True) for batch in loader: # 对每一个 mini-batch 进行操作 ...
- 1
torch_geometric.data.Batch继承自torch_geometric.data.Data,并且多了一个属性:batch。batch是一个列向量,它将每个元素映射到每个 mini-batch 中的相应图:
batch KaTeX parse error: Undefined control sequence: \[ at position 7: =\left\̲[̲\begin{array}{c…
我们可以使用它分别为每个图的节点维度计算平均的节点特征:
from torch_scatter import scatter_mean from torch_geometric.datasets import TUDataset from torch_geometric.data import DataLoader dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True) loader = DataLoader(dataset, batch_size=32, shuffle=True) for data in loader: data #data: Batch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32]) x = scatter_mean(data.x, data.batch, dim=0) # x.size(): torch.Size([32, 21])
- 1
关于 batching 的流程细节,你可以点击Pytorch Geometric Documentation查看。关于scatter方法的说明,你可以查看torch-scatter说明文档。
Transforms
transforms在计算机视觉领域是一种很常见的数据增强。PyG 有自己的transforms,输出是Data类型,输出也是Data类型。可以使用torch_geometric.transforms.Compose封装一系列的transforms。我们以 ShapeNet 数据集 (包含 17000 个 point clouds,每个 point 分类为 16 个类别的其中一个) 为例,我们可以使用transforms从 point clouds 生成最近邻图:
import torch_geometric.transforms as T from torch_geometric.datasets import ShapeNet dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'], pre_transform=T.KNNGraph(k=6)) # dataset[0]: Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
- 1
还可以通过transform在一定范围内随机平移每个点,增加坐标上的扰动,做数据增强:
import torch_geometric.transforms as T from torch_geometric.datasets import ShapeNet dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'], pre_transform=T.KNNGraph(k=6), transform=T.RandomTranslate(0.01)) # dataset[0]: Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
- 1
模型训练
这里只是展示一个简单的 GCN 模型构造和训练过程,没有用到Dataset和DataLoader。
我们将使用一个简单的 GCN 层,并在 Cora 数据集上实验。有关 GCN 的更多内容,请查看 关于 GCN 的理解。
我们首先加载数据集:
from torch_geometric.datasets import Planetoid dataset = Planetoid(root='/tmp/Cora', name='Cora')
- 1
然后定义 2 层的 GCN:
import torch import torch.nn.functional as F from torch_geometric.nn import GCNConv class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = GCNConv(dataset.num_node_features, 16) self.conv2 = GCNConv(16, dataset.num_classes) def forward(self, data): x, edge_index = data.x, data.edge_index x = self.conv1(x, edge_index) x = F.relu(x) x = F.dropout(x, training=self.training) x = self.conv2(x, edge_index) return F.log_softmax(x, dim=1)
- 1
然后训练 200 个 epochs:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = Net().to(device) data = dataset[0].to(device) optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4) model.train() for epoch in range(200): optimizer.zero_grad() out = model(data) loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask]) loss.backward() optimizer.step()
- 1
最后在测试集上验证了模型的准确率:
model.eval() _, pred = model(data).max(dim=1) correct = float (pred[data.test_mask].eq(data.y[data.test_mask]).sum().item()) acc = correct / data.test_mask.sum().item() print('Accuracy: {:.4f}'.format(acc))
- 1
至此,关于Pytorch Geometric的简单使用教程就讲完了。
回顾一下,在这篇文章中,在讲述使用Pytorch Geometric的过程中,花了较多篇幅分析了图数据是如何表示的,分析了Dataset的工作流程,让你明白图数据在Dataset里都经过了哪些步骤,才得以输入到模型,最终可以利用Dataset来构建自己的数据集。
如果你觉得这篇文章对你有帮助,不妨点个赞,让我有更多动力写出好文章。
我的文章会首发在公众号上,欢迎扫码关注我的公众号张贤同学。

