- 1基于一体化有序信息和事件关系的脚本事件预测_事件关系脚本学习
- 2idea git 合并多个commit_idea git合并多个commit
- 3关于def __init__(self)_def --init--
- 4字节跳动的真实工作体验_字节跳动稳定吗
- 5华为HCIP-Datacom认证题库(H12-821)_mqc与pbr一样,只能在设备的三层接口下调用
- 60.1## 梯度下降的优化算法,SGD中的momentum冲量的理解_sgd momentum如何取值
- 7将本地项目上传到GitHub_添加本地git代码到sourcetree
- 8基于Python+Django+Vue+Mysql前后端分离的图书管理系统_djangovue前后端分离图书馆
- 9基于JSP的图书销售管理系统_jsp 图书信息管理 博客
- 10Linux系统Docker部署DbGate并结合内网穿透实现公网管理本地数据库_docker安装基于web的数据库管理工具_dbgate docker
【算法详解】GPT-1模型架构与训练方法详解_gpt模型的基础模型架构
赞
踩
目录
2.3 输入变换(Input transformation)
0 参考文献
原论文链接:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf
今天给大家解读一下Improving Language Understanding by Generative Pre-Training这篇文章,也就是俗称的GPT-1,是GPT语言模型公诸于世的最初版本。
谈谈我的个人理解,如有疏漏,欢迎指正!
GPT这个名字,是后人给这个模型起的,原论文中并没有将他们的模型成为GPT。对于这个名字,我看网上主要有两种说法,一说取自Generative Pre-Training,即生成式预训练的首字母缩写,代表这个模型的主要特点,一说取自Generative Pre-trained Transformer。我个人倾向于后者,因为这不但体现出了模型“生成式”和“预训练”的特点,还表明了GPT本质上基于Transformer模型结构。
1 问题背景
众所周知,GPT是一个大语言模型,无论后续的诸多变体被应用在哪个领域,GPT最初都是为了应对自然语言处理(NLP)任务而诞生的,这一点从论文标题也可以看出来。
所有语言模型,都是用来执行特定的或是多种综合的NLP任务。常见的自然语言处理任务包括很多种,比如文本蕴涵、问题回答、语义相似度评估、文本分类、机器翻译等。

1.1 语料库资源
语言模型的训练需要语料库,目前语料库的分布如同下图所示。黄色部分是未标记的数据,指的是那些没有经过手动标注、分类的文本数据集合,这些数据通常来自各种各样的地方,比如新闻报道、网络上的文章等。红色部分是针对特定任务的带标记的数据。
绝大多数数据都是没有标记的,用于学习一些特定任务的标记数据数量很少。

1.2 方法的问题
1.2.1 监督学习
GPT之前大多数的深度学习方法都采用监督学习,需要使用大量的带标签的数据。如果现有的带标签数据不够,还需要对没有标签的数据大量的手工标记,人工成本很高,所以这种方法难以适用于哪些带标记数据不足的领域。
而且文章里也提到,即使是在那些有很多带标记数据的情况下,使用无监督的方式学习对文本的表示也可以更好地捕捉数据的特征,从而显著提高性能。
1.2.2 预训练词嵌入
预训练词嵌入方法就是一种无监督学习方法,它通过大规模的文本数据来训练词向量,目的是把一个单词,映射成一个向量。单词之间联系紧密的,在向量空间中的距离就比较靠近,比如“吃”和“苹果”之间的联系比“吃”和“墙壁”之间的联系更紧密,“吃”和“苹果”这两个词在向量空间就会更近。
这种方法的问题是,使用的都是单词级的信息,只能捕捉到单词之间的语义关系,不能捕捉到更高层的语义信息,比如短语级和句子级。而且这种方式难以适应训练数据与真实数据之间单词分布的差异。
1.3 面临的挑战
GPT的目标是使用文本中单词级别以上的级别的信息,但这存在两个需要解决的挑战。
第一个是无法确定使用哪种目标函数进行优化是最有效的。因为针对不同的任务,训练效果最好的时候使用的可能是不同的目标函数,比如A任务用第一种目标函数效果最好,B任务用第二种目标函数效果最好。
第二个是预训练结束之后,模型学到了一种文本的表示,但是这种表示不一定适用于下游的所有子任务,因为不同子任务可能需要关注的特征不同,那如何把学到的文本表示有效地传递给下游的子任务,让模型在这些任务上的性能比较好,这个方法是没有达成共识的。
2 GPT模型架构(训练方法)
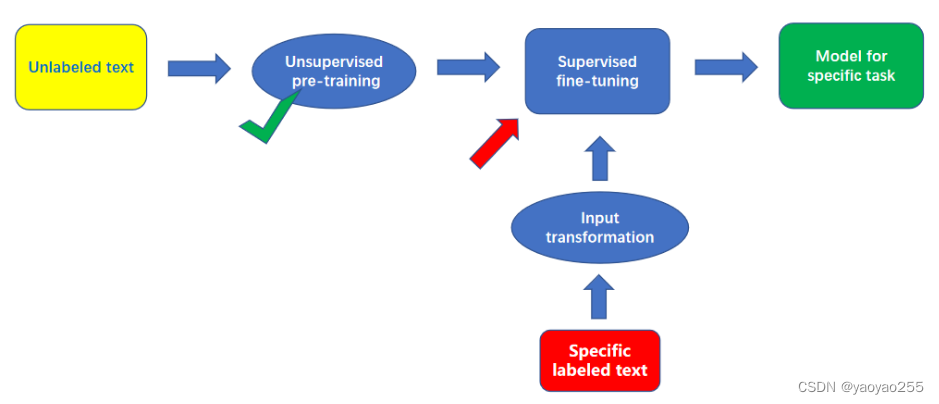
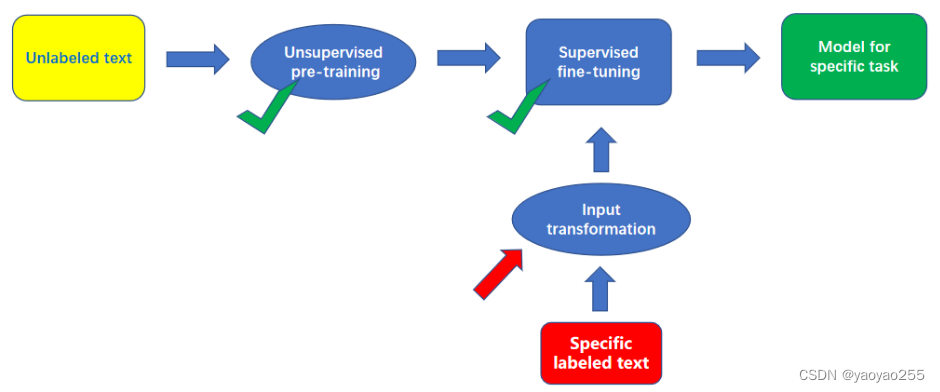
为了解决上面提到的问题,GPT使用了一种预训练+微调的架构,如下图所示,中英文对应如下:
Unlabeled text:没有标记的大量原始数据
Specific labeled text:针对不同任务的有标记的数据
Unsupervised pre-training:无监督的预训练
Supervised fine-tuning:有监督的微调
Input Transformation:输入变换
Final model:可用于解决特定NLP任务的语言模型
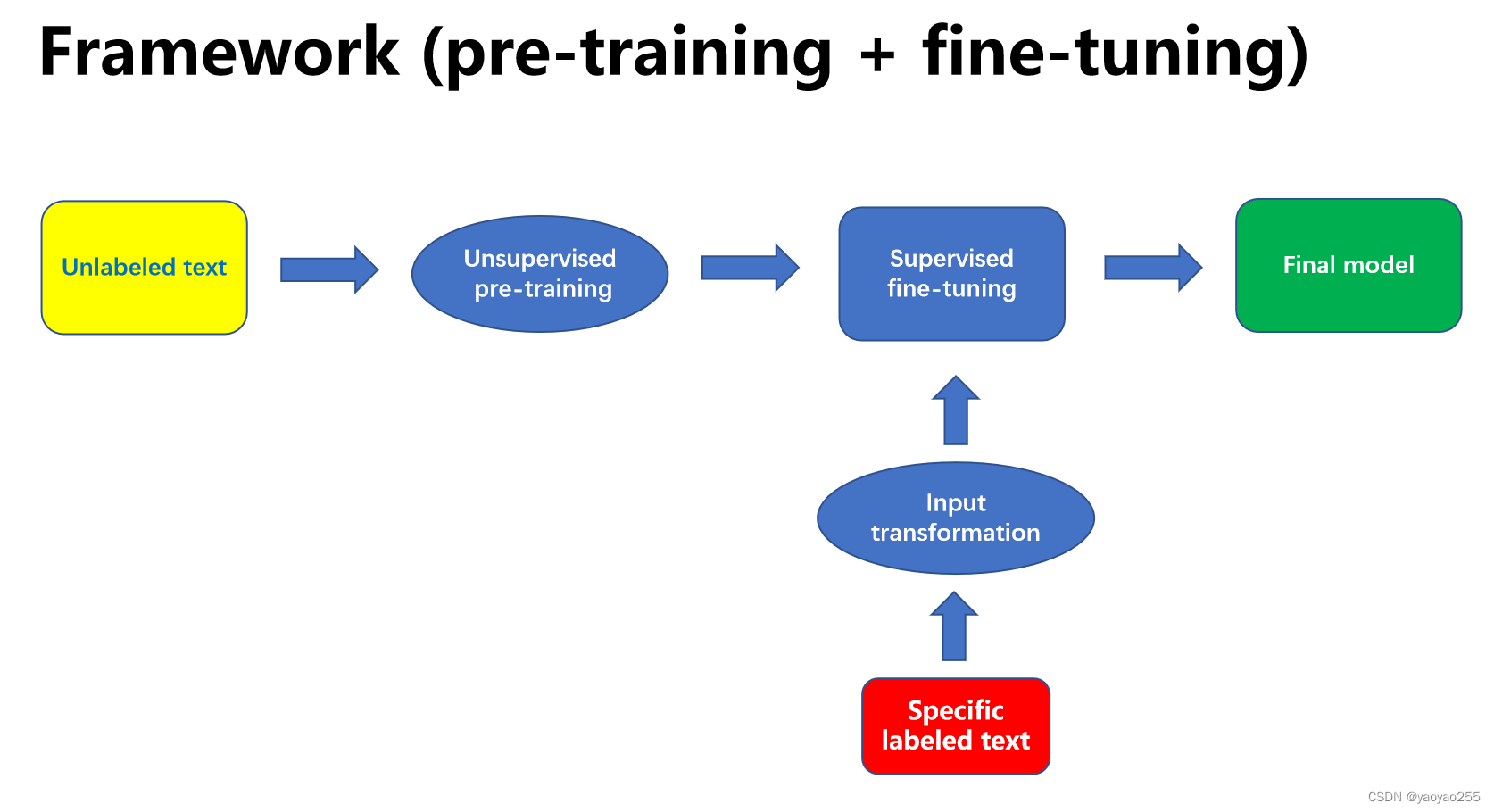
先使用大量的没有标记的数据进行无监督的预训练,获得一个预训练的模型,然后再使用有标记的数据进行微调,但是在进行微调之前,需要对不同任务的带标记的数据进行特定的输入转换。最终获得一个训练好的可以解决特定NLP任务的语言模型。
前面的预训练部分是无监督的,相当于是模型的语感训练,用于学习一种合适的文本表示,后面的微调部分是有监督的,相当于是针对解题的训练,用于适应特定任务(这是我之前可能是在某个博主的文章中看到的一个形象的比喻,感觉非常恰当,就直接写在这里了)。
这个框架需要介绍的主要就是预训练、微调、输入变换三个模块,下面我将逐一介绍。
2.1 预训练(Pre-training)
2.1.1 优化目标
预训练过程的优化目标是最大化下面这个似然函数。
这个就是一个tokens序列,其实就相当于一个文本,每个
就是一个词。
是窗口大小,也就是我们在预测某一个词的时候,关注到的它前面的序列的长度。
是这个模型的参数。
式子里的这个概率是给出
前面的
个词和模型参数
的基础上,预测
这个词出现的概率,因为用的是对数概率加和的形式,就相当于一个联合分布。这一部分的目标就是使用随机梯度下降法对模型参数进行更新,来使这个联合分布最大化。
2.1.2 模型结构
我们是时候了解一下GPT的模型结构了。为什么我不直接先把GPT的结构介绍了呢?因为后面我们会发现在预训练和微调两个阶段,GPT模型的结构并不完全相同,虽然区别不大。
在这篇博客的开头,我提到GPT模型是基于Transformer架构的。
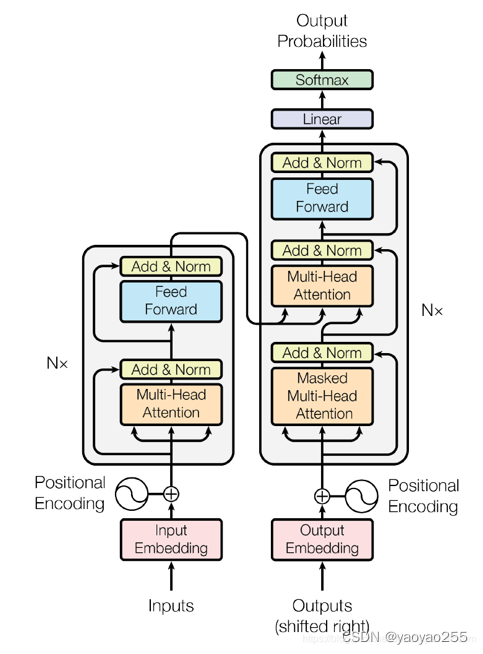
下图是Transformer模型的具体结构,左边是编码器,右边是解码器。而GPT具体的模型相当于使用的是Transformer模型的解码器,把Transformer的解码器拿出来稍微做了些改变。
那为什么要使用Transformer呢?
文章里给的解释是这样的:“与循环神经网络(RNN)等替代方案相比,Transformer具有更结构化的内存,用于处理文本中的长期依赖关系,从而在不同任务中体现出了稳健的传输性能”。
我们说的简单一点,RNN等网络存在一些问题。
首先,因为梯度消失和梯度爆炸问题的存在,RNN难以处理文本的长期依赖关系。比如在一个文本中,前面很远有一个词,会对当前这个词会产生影响,在计算梯度的时候,有可能因为隔得很远,小于1的特征值经过多次相乘之后趋近于0了,最后梯度算完了等于0(梯度消失),就没有办法有效地更新参数,或者大于1的特征值多次相乘趋近于无穷(梯度爆炸),梯度特别大,网络变得不稳定,难以收敛。LSTM(长短期记忆网络)虽然通过一些类似门的结构,选择哪些数据需要保留、丢弃和更新,但是也只是一定程度上改善了这个问题,效果还是不够理想。
其次,由于RNN是有反馈的,计算序列下一个词的时候需要用到上一个词的计算结果,所以无法并行处理文本序列。
Transformer利用一种叫多头自注意力(Multi-Head Self-Attention)的机制,本质上是依靠输入序列不同位置的元素之间的关系来设置权重,计算加权和,所以可以更好地处理长期依赖关系,而且只需要使用一次矩阵计算就可以了,所以可以并行处理整个文本序列。
那为什么使用的是解码器而不是编码器呢?
这二者的区别在于,编码器在处理文本的时候可以看到全部的文本序列,而解码器由于掩码的存在(即上图中Multi-head Attention和Masked Multi-head Attention的区别),当对第i个元素抽取特征的时候,只能看到这之前的序列。因为GPT的任务是在一个序列的基础上预测下一个词,所以和解码器更加适配。
下图是GPT预训练过程的模型结构(左),这里只展示需要更新参数的部分。可以看出来如果去掉Transformer解码器的中间部分(右),这两者就没有什么区别了。
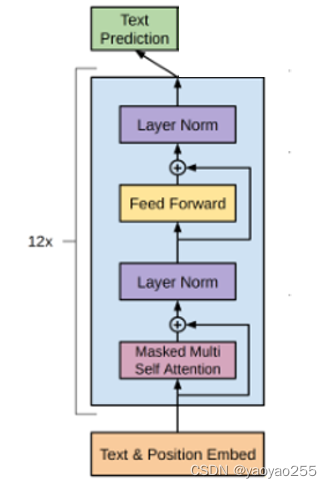
下面的式子是介绍了这个模型是如何进行计算的。
就是一个长度为
的序列,我们现在要预测这个序列的下一个词。
输入,经过在输入transformer block之前一次变换,乘上矩阵
(文本嵌入text embed),然后加上矩阵
(位置嵌入position embed)。
随后输入n个中间的transformer block,每个transformer block依次包含:带掩码的多头自注意力模块、残差层、层标准化、前馈模块(线性层+激活函数+线性层)、残差层、层标准化,最后输出一个。
随后进入线性层,然后再做softmax进行输出。左图最上面的text prediction相当于右图顶部线性层或线性层加softmax操作的部分,左图所有可更新参数在预训练中均需要进行更新。
2.2 微调(Fine-tuning)
2.2.1 优化目标
微调这个部分的优化目标如下,是两个目标函数的加和。
其中是带标记的数据集,里面每一个数据都包括一个tokens序列
到
,和对应的一个标签
。
是预训练阶段介绍过的目标函数,只不过数据集从
变成了
,但是实际上没有本质的区别,因为在这一部分是没有用到标签的。
是一个超参数,用于调整对
整体目标函数的贡献程度。
从的函数形式也可以看出这是一个联合概率分布的形式,这里的概率
表示通过给定的序列,预测对应标签的概率。
2.2.2 模型结构
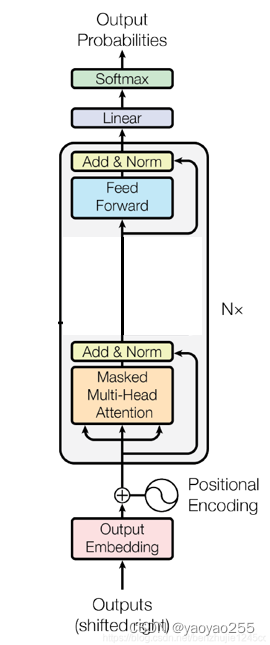
下图还是和刚才一样的GPT的结构,只是上面多了一部分,这部分task classifier是在微调过程中新加上去的,在预训练过程中没有使用到这部分结构。

简单来讲,text prediction部分是计算里面的概率需要用到的部分,task classifier是计算
里面的概率需要用到的。在预训练过程中,需要更新text prediction线性层、transformer block、tokens & position embedding的参数,而在微调过程中,需要同时更新全部参数(即上述模块参数加上task classifier的参数)。
使用作为辅助优化目标有两点好处,首先能够提高模型的泛化能力,第二是能够加速收敛。
2.3 输入变换(Input transformation)
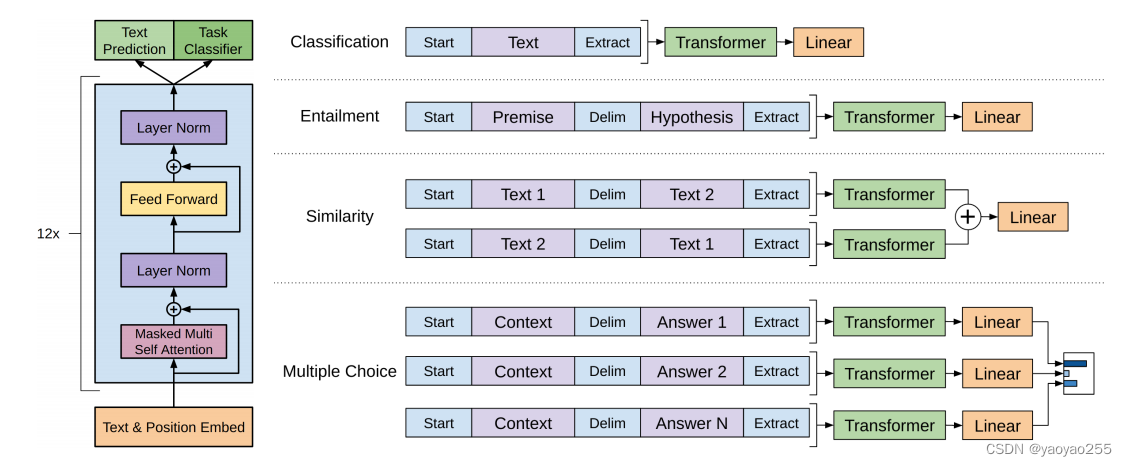
下面我们介绍一下最后的这个部分,也就是输入变换部分。下图给出了几种NLP任务输入数据的输入变换形式。
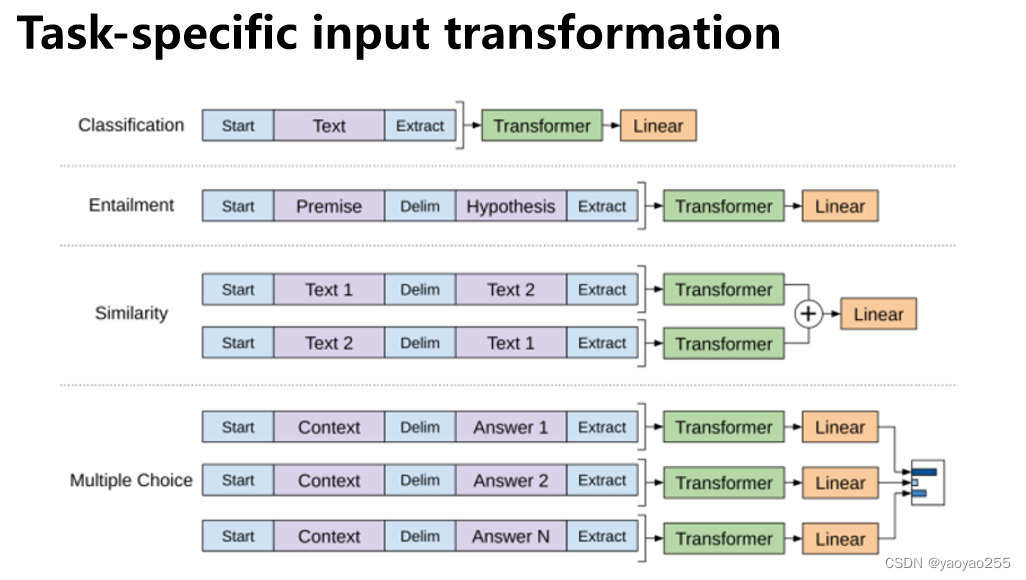
为什么要进行输入变换呢?
首先对于某些任务,比如文本分类,直接就可以用上面说的模型执行任务。但对于有些任务,是需要结构化的输入的,比如文本蕴涵问题的输入可能是句子对,问题回答是任务文本、问题、答案的三元组。
通过对输入进行变换,就避免了针对特定任务的模型结构的改变。
上面给出了自然语言处理四个常见的任务的输入变换形式。第一个文本分类任务的输入变换形式,就是在文本前后都加上一个标记。第二个文本蕴涵任务因为是给出一段文本,然后提出一个假设,看这段文本能否支持后面这个假设,所以就是前面放一个开始的标记,然后放上一段文本,中间放一个分隔符,再接上假设,最后是一个终止标记。其他的也是进行类似的变换。
3 模型实验
到这里,GPT的模型框架就已经介绍完了。文章在后面还对他们训练的模型进行了实验测试,这里就简单介绍一下结果。
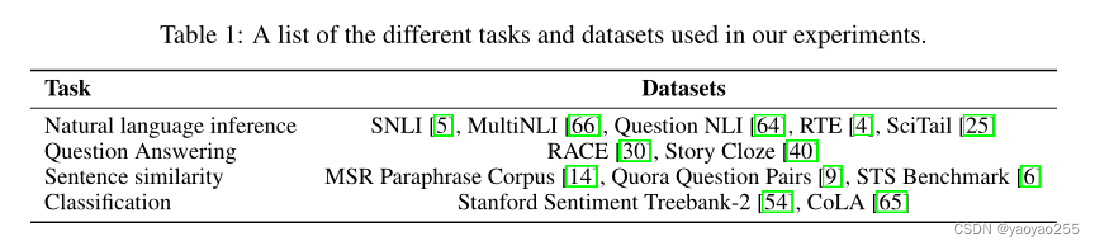
首先他们预训练使用的是BooksCorpus数据集,里面包含7000多本很多未出版的书。下面这个表格是是针对不同任务使用的数据集。
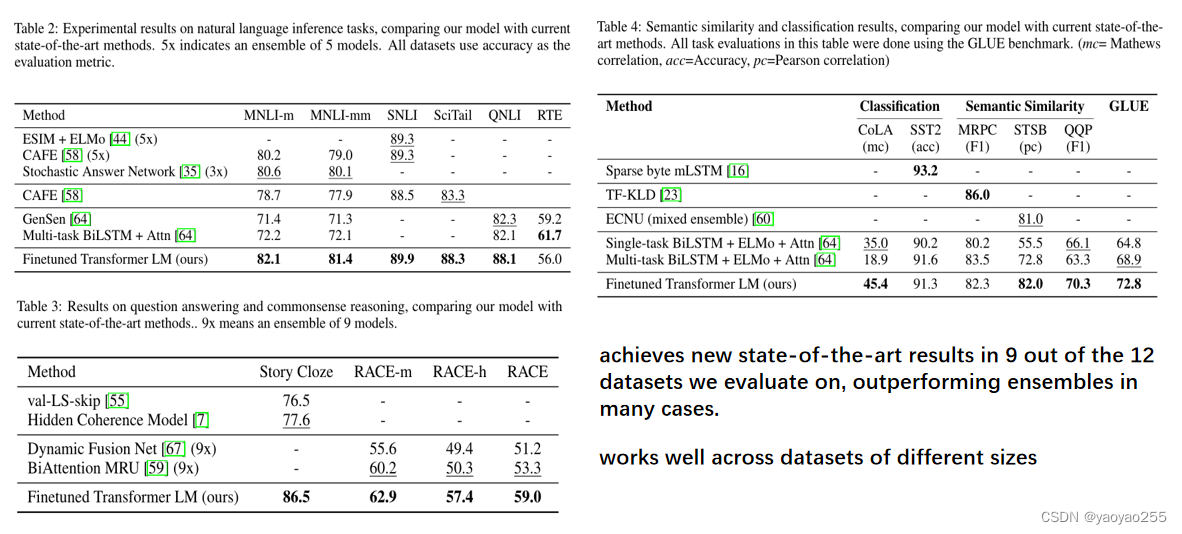
下图表格就是最后的测试结果,上面几行是之前的模型的测试效果,最下面一行是他们这个模型的测试效果。最后得出的结果就是,他们在12个测试的数据集中,在9个数据集上取得了比之前的模型更好的成绩,而且他们这个模型在不同大小的数据集上都体现出了良好的效果。
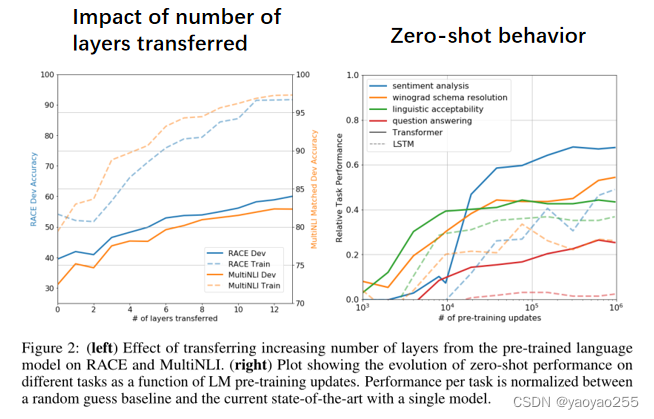
他们还进行了一些其他的实验,下图左侧这幅图是测试的模型层数对测试准确率的影响,发现随着层数增加到当前版本的层数,准确率是越来越高的,所以得出结论认为每一层都包含了解决目标任务的有用功能。
下图右侧这幅图是一个zero-shot实验,zero-shot实验就是在不进行微调过程的情况下,直接测试针对特定任务的效果,其实GPT是具有这个潜力的,因为它在预训练过程中使用了非常大量的未标记的文本,就比如你要让它执行一个问题回答的任务,他可能在那些未标记的数据中已经见过了大量的问答形式的文本,虽然没有人专门告诉他,问题回答任务是别人给一个问题,你要给出一个答案,但是它在预训练过程就培养出来了这样的语感,就是一段文本就是一个问题,后面就应该跟上它的答案。Zero-shot的效果也是他们在后续改进过程中关注的内容。从这张图同颜色的实线与虚线对比,可以看出来在zero-shot表现上,这个模型是要优于LSTM网络的。