
- 1查找两个字符串a,b中的最长公共子串。_查找两个字符串a,b中最长的公共子串
- 2【Git学习笔记】提交PR_提交pr +csdn
- 3python图表绘制及可视化_python绘制图表+前端展示框架
- 4eclipse 启动不了
- 5msyql truncate 恢复数据_mysql truncate 恢复
- 6仿站_dedecms仿站csdn
- 7【AI 大模型】RAG 检索增强生成 ② ( 关键字检索 | 向量检索 | 向量简介 | 二维空间向量计算示例 | 文本向量 - 重点 ★★ | 文本向量示例 )
- 8论文阅读:CSPNET: A NEW BACKBONE THAT CAN ENHANCE LEARNING CAPABILITY OF CNN_cspnet论文
- 9Unity无法连接git下载package_unity github无法连接到服务器
- 10安装配置Ubuntu20.04以及jdk、hadhoop的过程记录_ubuntu20 安装jdk
In Context Learning(ICL)个人记录_in-context learning
赞
踩
In Context Learning(ICL)简介
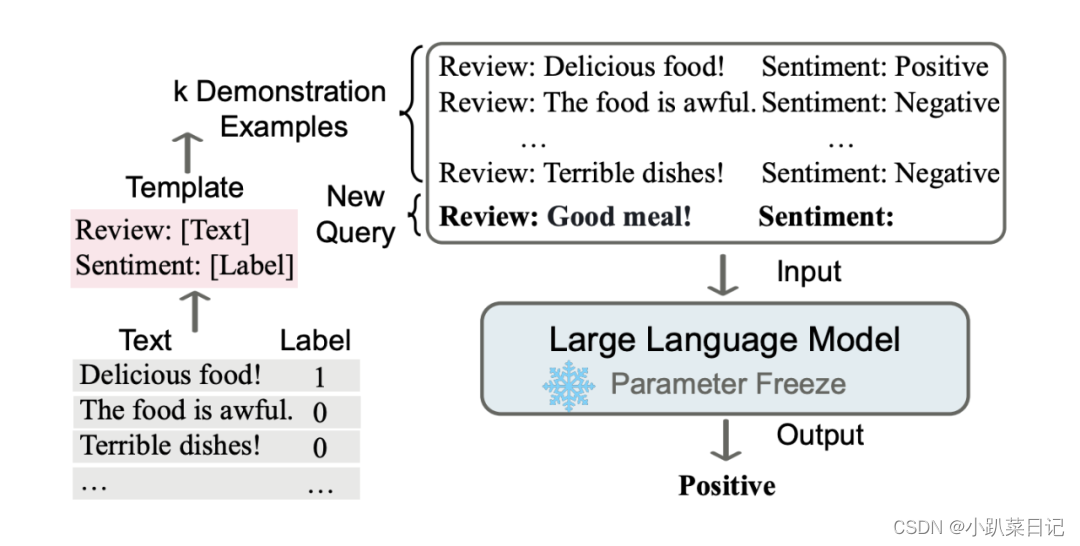
In Context Learning(ICL)的关键思想是从类比中学习。上图给出了一个描述语言模型如何使用 ICL 进行决策的例子。首先,ICL 需要一些示例来形成一个演示上下文。这些示例通常是用自然语言模板编写的。然后 ICL 将查询的问题(即你需要预测标签的 input)和一个上下文演示(一些相关的 cases)连接在一起,形成带有提示的输入prompt,并将其输入到语言模型中进行预测。
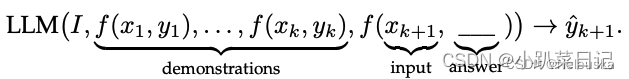
其中I表示任务 。值得注意的是,与需要使用反向梯度更新模型参数的训练阶段的监督学习不同,ICL 不需要参数更新,并直接对预先训练好的语言模型进行预测。我们希望该模型学习隐藏在演示中的模式,并据此做出正确的预测。
OpenAI 的一篇长达 70 多页的论文《Language Models are Few-Shot Learners》中提到,ICL 包含三种分类:
- Few-shot learning,允许输入数条示例和一则任务说明;
- One-shot learning,只允许输入一条示例和一则任务说明;
- Zero-shot learning,不允许输入任何示例,只允许输入一则任务说明。

论文:Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
提出:In-Context Learning模型是如何学习的,以及演示的哪些方面有助于最终任务的性能
探索了cases的四个方面是否是是最终任务性能的关键驱动因素
(1)标签yi是否正确
(2)输入文本的分布。x1 x2...xk是否来自同一个分布
(3)标签空间。y1 y2...y3是否来自同一个标签空间
(4)序列的整体格式。
文章挑选了6个模型26个数据集,
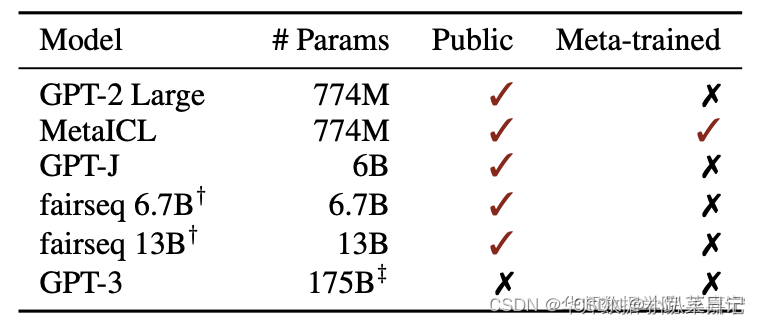
其中Public表示模型参数是否开源,Meta-trained表示模型是否进行多任务训练。

标签
分成了三种不同的标签数据:
(1) 无标签:没有任何的标签,直接输入输出即可。
(2) 正确标签。
(4)随机标签:把标签和数据打乱。
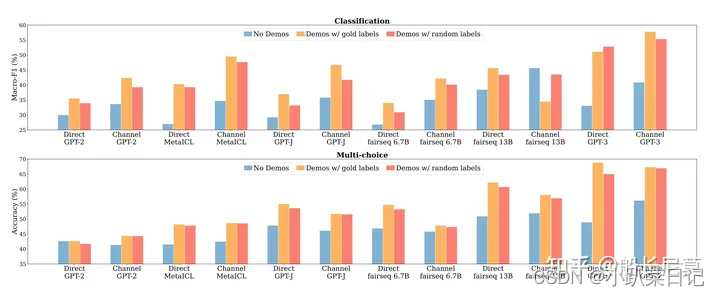
其中蓝色列是无标签,正确标签是橘红色,随机标签是红色。看结果会分析出红色的部分比橘红色的,没有低多少,也就意味着即使label是随机打乱的,对于结果的影响也很小
其中蓝色列是无标签,正确标签是橘红色,随机标签是红色。看结果会分析出一个很有意思的观点,那就是红色的部分比橘红色的,没有低多少,也就意味着即使label是随机打乱的,对于结果的影响也很小,这点是为什么呢?
下面进一步探索错误标签所占的比重对预测影响的情况

- 正确样本数量对模型性能几乎没有什么影响;
- 宁愿使用错误的标签样本,也比完全不使用demonstration要好;
验证不同样本数量 k 的选择对上述两个结论的影响情况

- 使用demonstration example依然比不使用的效果好;
- 使用random label在不同k的条件下效果下降很小;
- 有趣的发现,随着K增大,并非效果也是持续增大的,这与标准fine-tune事实不同。
输入x分布
给定 k个demonstration sentence,这 k个句子是从别的task的语料(不同于当前task) 随机采样得到的,而标签空间和demonstration的format保持不变。此时,输入句子的分布是与当前task不同的。
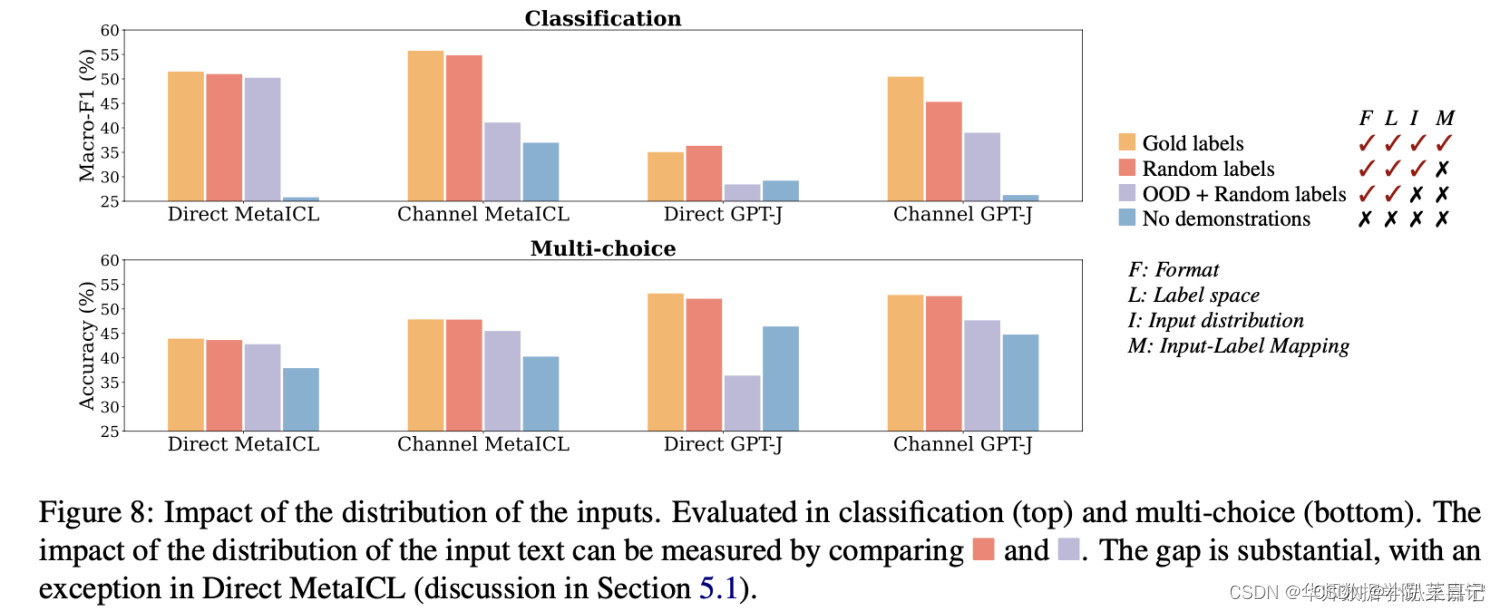
- 观察红色(Input都是同一个数据集分布的)和紫色(Input来自不同于当前任务的数据集分布)两个图,可以发现大多数任务上差异很大。说明选择不同分布的Input对ICL的性能影响很大。
输出y的分布
本部分探索标签 yi的分布是否有影响。例如测试样本为SST-2情感分析,但是挑选的In-Context Example的标签来自是其他类型的任务,例如主题分类、QA等。为了方便实验,我们使用Random Labels来表示。
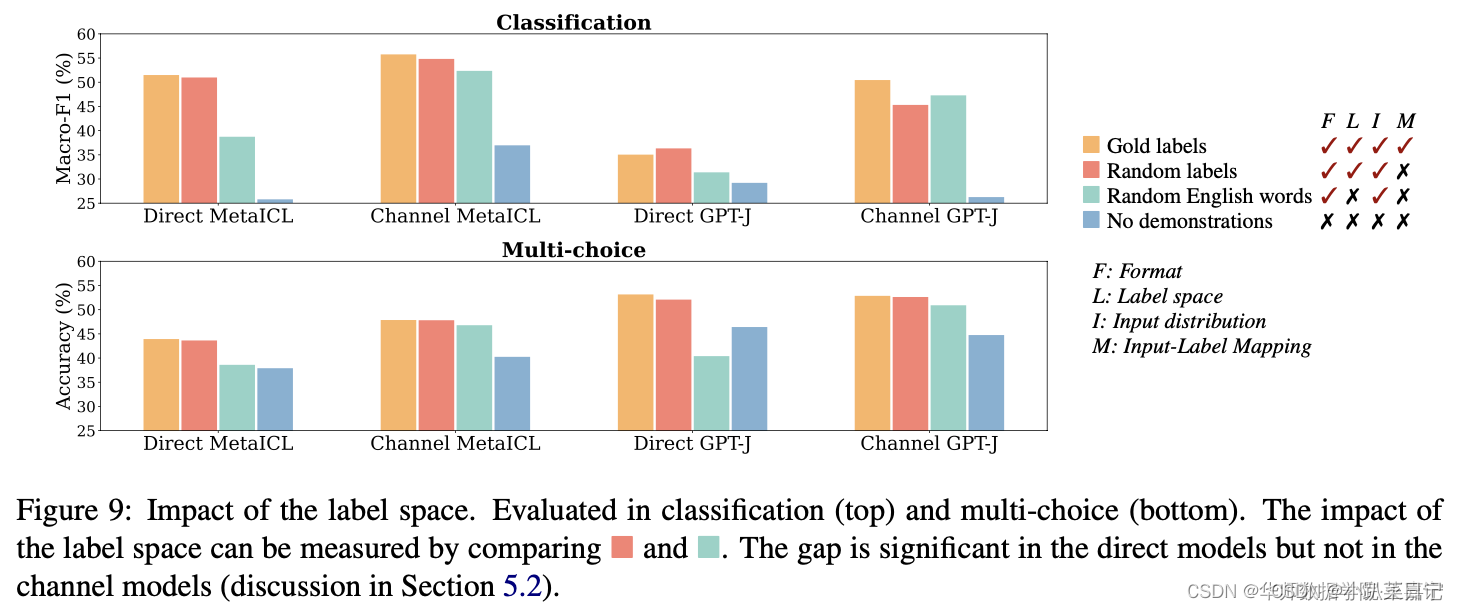
- Glod labels比Random Labels高,但是差异非常小,说明标签是否来自于同一个分布并不重要;
format
修改demonstration的模式(format)
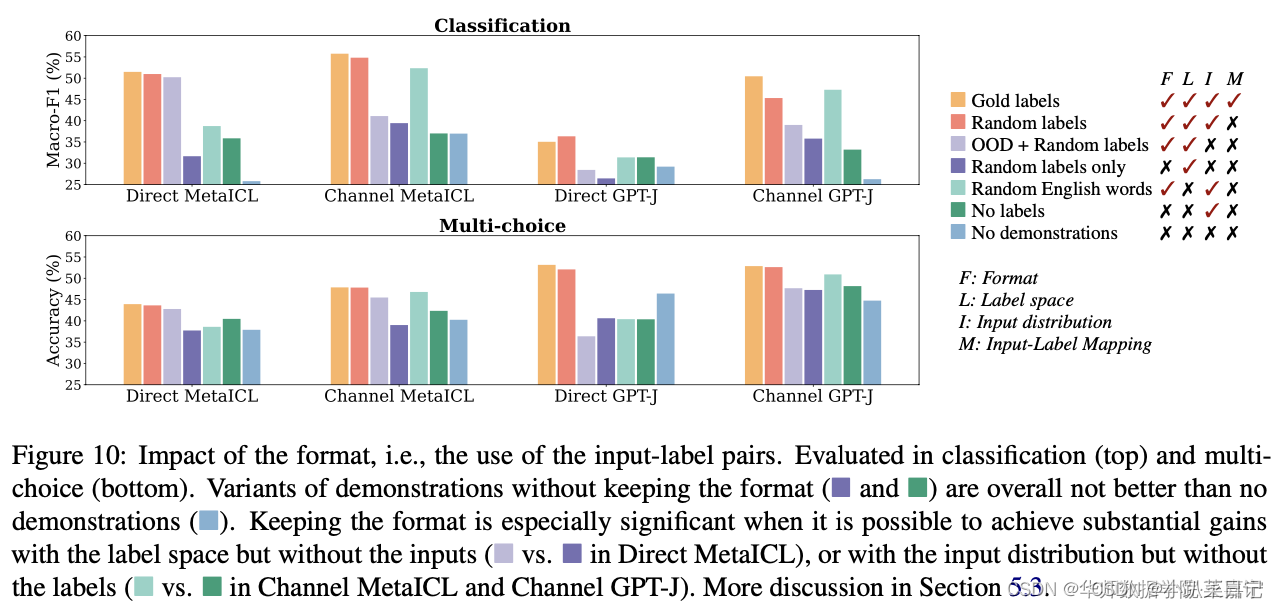
- 去掉format后,发现与no demonstrate相比没有明显的提升,说明format是很重要的(即label和input text 缺一不可)
补充
LM在测试时不会学习新任务,这点在随机的label种有所体现。我们的分析表明,模型可能会忽略演示定义的任务,而是使用来自预训练的先验知识。然而,学习新任务可以更广泛地解释:它可能包括适应特定的输入和标签分布以及演示所建议的格式,并最终更准确地进行预测。
一个关键发现是,在不使用任何标记数据的情况下,通过将每个未标记的输入与随机标签配对并将其用作演示,几乎可以达到k-shot性能。这意味着零样本基准水平比以前预想的要高得多。未来的工作可以通过放宽对未标记训练数据的假设来进一步提高零样本性能。
待更:
【论文笔记】A Survey on In-context Learning_supervised in-context training-CSDN博客

