
- 1win10共享文件夹_win10 文件夹共享
- 2【Stable Diffusion初学者指南】模型指南_stable diffusion的剪辑跳过在哪里
- 3uniapp 自定义写底部导航栏_uniaoo app 自定义底部菜单栏
- 4一键生成透明底图像!教你用开源 SD 插件实现素材自由!_如何用sd画出透明的身体
- 5flink1.18 编译遇到的问题
- 6探索FairyGUI编辑器插件:打造高效的游戏UI开发新体验
- 7盘点:流媒体视频流协议与EasyCVR视频监控技术的深度融合
- 8AI仿站源码教程
- 9JetBrains 牛逼!支持跨 iOS、Android、桌面、Web 和服务器共享代码
- 10Elasticsearch 查询语法_elasticsearch查询语法
Linux:多线程的操作_linux在单个终端中多线程任务
赞
踩
进程与线程
- 进程是资源分配的基本单位
- 线程是调度的基本单位,共享进程的数据,拥有自己的一部分数据
线程私有的属性:线程的ID、一组寄存器(上下文数据)、栈(独立的栈结构)、调度优先级
进程的多个线程共享同一块地址空间,对堆区、栈区都是共享的
线程共享进程的资源有:文件描述符表、每种信号的处理方式(默认动作、忽略动作、自定义动作)、当前工作目录
线程的创建 create_pthread
Linux下没有真正意义的线程,而是用进程模拟的线程(LWP)。对此,Linux不会提供直接创建线程的系统调用,只会提供创建轻量级进程的接口。
在用户看来会很变扭,进程是进程,线程是线程就要区分开来。
所以出现了用户级线程库 pthread:对Linux接口进行封装,给用户提供进行线程控制的接口
(pthread 线程库在任何版本的Linux操作系统都会存在, pthread也被称为原生线程库)
可以通过 man 的3号手册来查看线程库的使用,这里不作演示
接下来介绍一些线程库的接口使用:
使用原生线程库需要包含头文件:#include <pthread>
- 创建线程
int pthread_create(pthread_t *thread, const pthread_attr_t* attr,
void* (*start_routine)(void*), void* arg);
- 1
- 2
pthread_create 函数参数介绍
thread:线程 id 地址,pthread_t 为无符号整数
attr:线程属性(线程优先级)
start_routine:函数指针,执行对应的函数功能(可以对函数进行传参),也被称为回调函数
arg:是指向任意数据的指针,将参数传递给 start_routine 函数
返回值:线程创建成功返回0,失败错误码被设置
示例:
#include <iostream> #include <pthread> #include <unistd.h> void* thread_run(void* arg) { while(true) { std::cout << "new thread running" << std::endl; sleep(1); } return nullptr; } int main() { pthread_t t; pthread_create(&t, nullptr, thread_run, nullptr);//创建线程,t是输出型参数 //主进程 while(true) { std::cout << "main thread running, new thread id:" << t << std::endl; sleep(1); } return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
上面代码直接编译的话会出现链接报错,这是因为这个多线程是一个库,直接编译 g++ 会找不到这个库,需要指定编译器去找线程库。

对此,在编译时,使用 g++ 进行编译要加上 -lpthread 选项
g++ -o threadTest threadTest .c -std=c++11 -lpthread
- 1

可以通过 ldd 对编译好的可执行文件来查看线程库的位置:
ldd threadTest
- 1
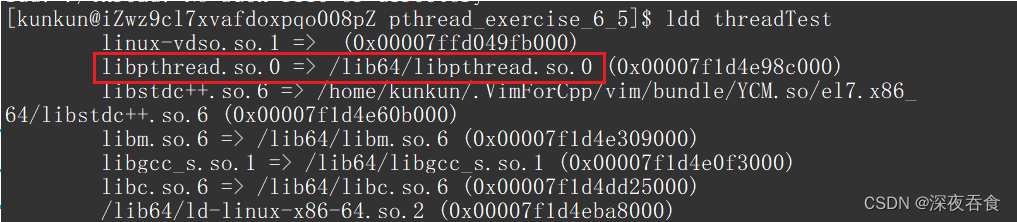
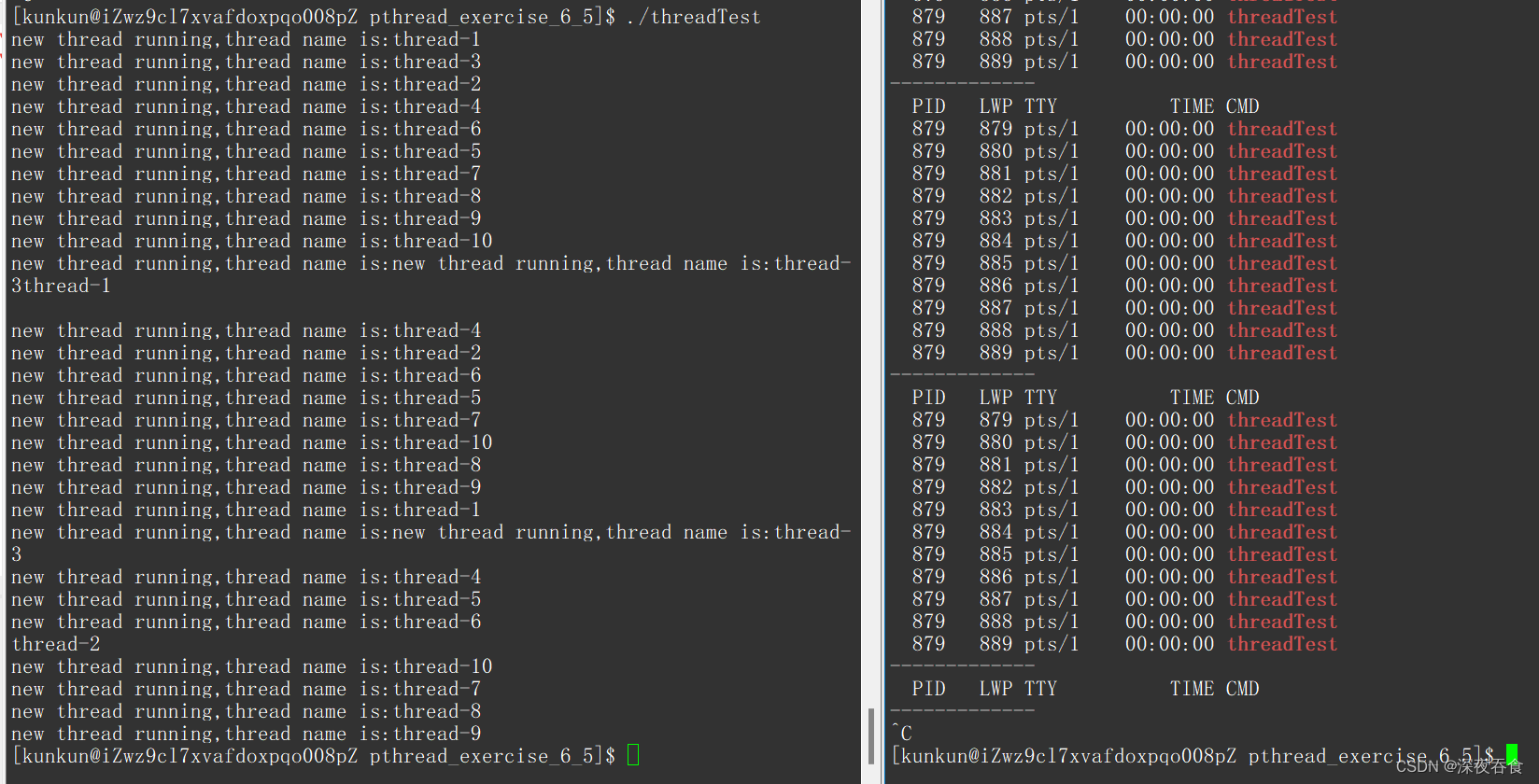
执行程序可以看到,主线程与子线程同时运行:

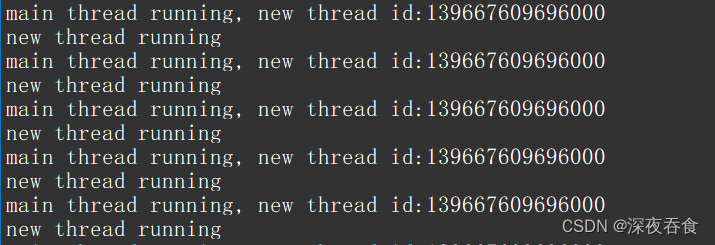
此时输出的线程id会很大,很奇怪。其实这些线程的id是地址,创建的线程会被线程库管理起来,形成数组,每个对应的线程id 其实就是数组的下标。
创建的线程是不能确定先后顺序的. Linux下的线程是轻量级的进程,进程创建执行的先后顺序是由调度器决定的,对此线程谁先谁后的问题也要看调度器来决定的
创建线程池
下面来创建一个线程池,让每一个线程都执行 thread_run 这个函数,打印对应的创建编号
#include <iostream> #include <pthread> #include <unistd.h> #define NUM 10 void* thread_run(void* arg) { char* name = (char*)arg; while(true) { std::cout << "new thread running,thread name is:" << name << std::endl; sleep(1); } return nullptr; } int main() { pthread_t tids[NUM]; for(int i = 0; i < NUM; i++) { char thname[64]; snprintf(thname, sizeof(thname), "thread-%d", i + 1); pthread_create(tids + i, nullptr, thread_run, thname);//创建线程池,将thname传参 } //主进程 while(true) { std::cout << "main thread running" << std::endl; sleep(1); } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
编译运行:
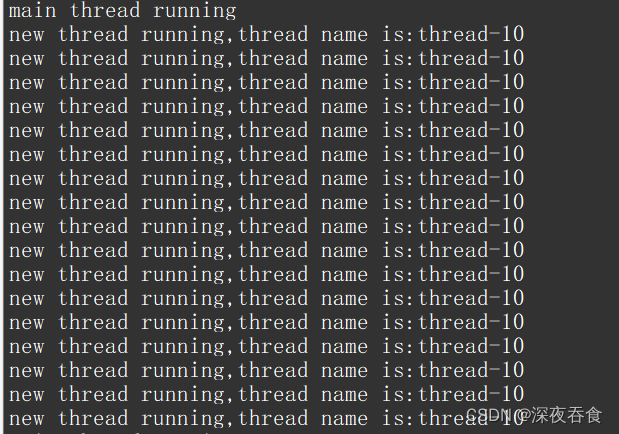
结果很不对,输出的结果都是一样的。
在给线程回调函数进行传参时,传入的是 thname 地址。thname 字符数组是属于主线程的,属于临时变量。前面提到线程会共享进程中的数据。对此,每个线程都会对这个变量进行读写,导致最终显示的结果都是一样的。
解决方式如下:
对 thname 变量在堆上申请空间,待到回调函数使用完后对这个资源进行释放:
void* thread_run(void* arg) { char* name = (char*)arg; while(true) { std::cout << "new thread running,thread name is:" << name << std::endl; sleep(1); } delete name; //释放空间 return nullptr; } int main() { pthread_t tids[NUM]; for(int i = 0; i < NUM; i++) { char* thname = new char[64]; //堆上开辟空间 snprintf(thname, 64, "thread-%d", i + 1); pthread_create(tids + i, nullptr, thread_run, thname);//创建线程池,将thname传参 } //主进程 while(true) { std::cout << "main thread running" << std::endl; sleep(1); } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
编译运行:
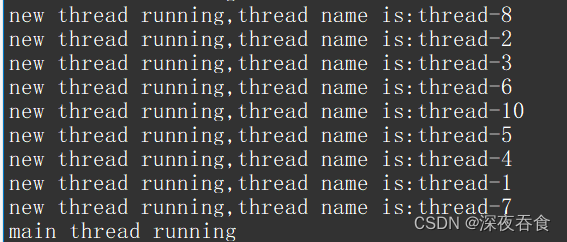
创建线程前,每次对 thname 进行资源申请,回调函数之后对资源进行释放,可以很好的避免资源共享情况发生。从结果也可以看出不同线程的执行先后顺序也是不确定的。
给线程传入对象的指针
创建线程时,不仅仅只可以传入内置类型变量的指针,还可以传入自定义类型变量的指针
示例:构建 ThreadDate 类,其内部包含线程的基本信息。在类中实现输入型参数和输出型参数,方便我们获取线程处理后的数据结果
#include <iostream> #include <unistd.h> #include <pthread.h> #include <string> #include <ctime> #define NUM 3 enum { OK=0, ERROR }; struct ThreadDate { //构造 ThreadDate(const string& name, pthread_t tid, time_t createTime, size_t top = 0) :_name(name), _tid(tid), _createTime((uint64_t)createTime), _status(OK), _top(top), _result(0) {} ~ThreadDate(){} //成员变量 //输入型变量 string _name; pthread_t _tid; uint64_t _createTime; //创建时间 //输出型变量 int _status; //线程退出状态 size_t _top;//累加到最大值 int _result; };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
下面通过实例化这个类,来演示线程中传入对象:
int main() { pthread_t tids[NUM]; // 创建线程池 for (int i = 0; i < NUM; i++) { char *thname = new char[64]; snprintf(thname, 64, "thread-%d", i + 1); //定义ThreadDate类,传入到线程中 ThreadDate* tdate = new ThreadDate(std::string(thname), i+1, time(nullptr), (100+ i * 5)); pthread_create(tids + i, nullptr, thread_run, tdate); //将tdate对象进行传参 } void *ret = nullptr; // 用于保存子线程退出的信息 for (size_t i = 0; i < NUM; i++) { int n = pthread_join(tids[i], &ret); //传入ret指针的地址 if(n != 0) std::cerr << "pthread_join error" << std::endl; ThreadDate* td = static_cast<ThreadDate*>(ret); //指针类型转换 if(td->_status == OK) //输出对象内容 std::cout << td->_name << " 计算的结果是: " << td->_result << " (它要计算的是[1, " << td->_top << "])" << std::endl; //释放资源 delete td; } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29

线程等待 pthread_join
上面实现的代码中,我们将主线程用死循环的方式,一直维持进程的运行。
如果去掉死循环,线程还能继续执行下去吗?
对上面的代码进行修改:在线程被创建后,维持 3 秒后主进程退出
int main() { pthread_t tids[NUM]; for(int i = 0; i < NUM; i++) { char* thname = new char[64]; //堆上开辟空间 snprintf(thname, 64, "thread-%d", i + 1); pthread_create(tids + i, nullptr, thread_run, thname);//创建线程池,将thname传参 } //主进程 sleep(3); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
进程是资源的申请的主体,进程退出了,不管子进程还在进行什么操作都会终止运行。
这样会造成什么后果?
会造成资源泄漏,如果此时的线程在堆区申请了资源还没来得及释放,会导致内存泄漏。
线程与子进程一样,线程退出后需要被回收处理。就拿子进程来说,当子进程退出后会处于僵尸状态,父进程如果没有等待子进程,对子进程的僵尸状态进行回收的话会造成资源的泄漏。
有僵尸进程,但是有没有僵尸线程一说。与进程相似,线程退出后也会处于一种被回收的状态,没有及时回收线程的话,也会造成内存泄漏!
对此,线程退出是需要进行等待的
下面来介绍一个函数接口:pthread_join 等待线程
int pthread_join(pthread_t thread, void **retval);
- 1
参数介绍:
thread:等待的线程 id 号
retval:是一个指向指针的指针,用于存储被等待线程的返回值
返回值:等待成功返回0,失败错误码被返回
对上面的代码进行修改,写一个等待进程的版本:
void* thread_run(void* arg) { char* name = (char*)arg; while(true) { std::cout << "new thread running,thread name is:" << name << std::endl; sleep(1); } delete name; //释放空间 return nullptr; } int main() { pthread_t tids[NUM]; for(int i = 0; i < NUM; i++) { // char thname[64]; char* thname = new char[64]; // snprintf(thname, sizeof(thname), "thread-%d", i + 1); snprintf(thname, 64, "thread-%d", i + 1); pthread_create(tids + i, nullptr, thread_run, thname);//创建线程池,将thname传参 } for(size_t i = 0; i < NUM; i++) { pthread_join(tids[i], nullptr);//等待线程 } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
有了线程等待,可以很好的避免内存泄漏。主进程会等待所有的子线程,只有当所有的线程都退出后才会结束整个程序的运行。
退出线程 pthread_exit
如何控制线程的退出呢?
这里还是拿进程来说,也比较好举例(前面也说过线程是轻量级的进程)。进程退出的方式可以在main函数中使用 return 语句、在任意行代码处调用 exit 函数。
那么线程可以使用类似的方法吗?
先来看看 return 语句的作用,还是拿刚刚编写的代码来举例。这里我们直接往死循环内部编写 3 秒的停顿,之后直接执行break 语句,后续执行 return 语句。为了方便展示,下面只展示修改的代码:
void* thread_run(void* arg)
{
char* name = (char*)arg;
while(true)
{
std::cout << "new thread running,thread name is:" << name << std::endl;
sleep(3);
break; //跳出循环
}
delete name;
return nullptr;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
编译运行,来看看执行结果:
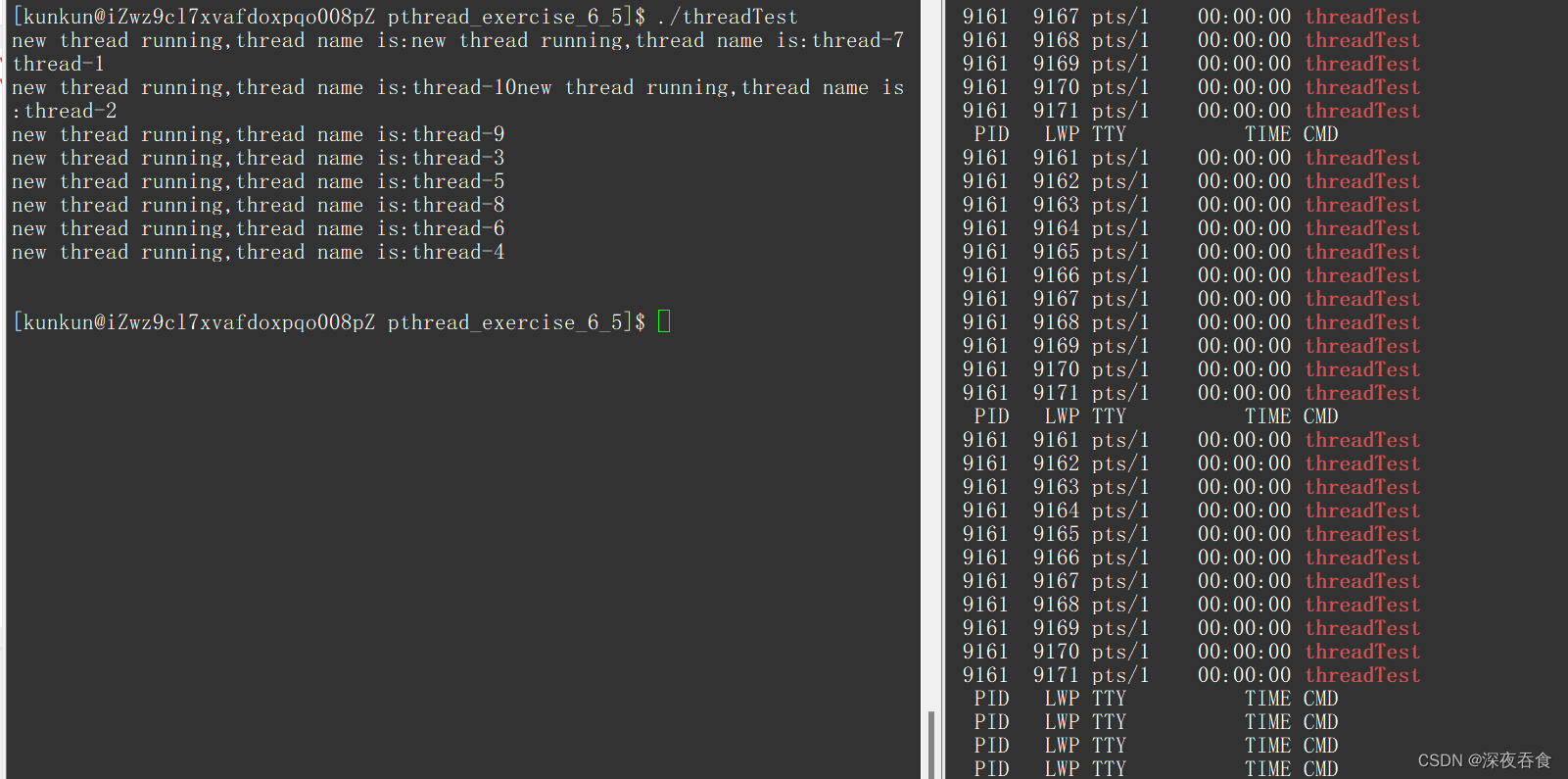
所有的线程都会打印一次,然后停顿卡住,到执行 return 语句后所有的线程都会退出。执行的效果也是符合我们的预期的。
下面来使用 exit 函数来测试线程退出情况,还是上面的代码,将 break 语句换成 exit 函数
void* thread_run(void* arg)
{
char* name = (char*)arg;
while(true)
{
std::cout << "new thread running,thread name is:" << name << std::endl;
exit(10); //调用exit函数
}
delete name; //释放空间
return nullptr;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
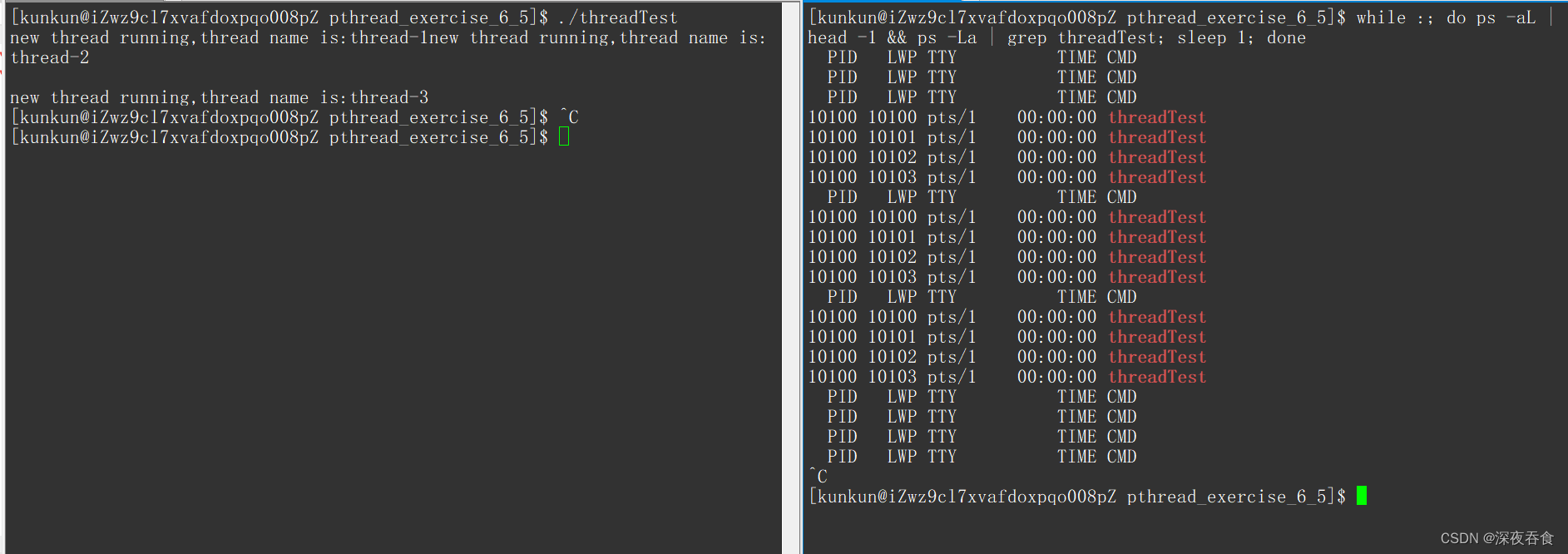
下面来看看现象:

线程池只创建了一部分,然后直接终止了运行。在右边监视 threadTest 进程也没有任何显示。
exit 函数退出作用是整个 threadTest 进程,当某一子线程调用了 exit 函数的时候,就会导致整个进程都退出。这也是为什么会只创建了一些子线程,然后导致整个进程都结束运行了。
对此,在线程执行流中,非必要情况下,不要轻易的调用 exit 函数。
不能使用 exit 函数,但是线程库中提供了一个API,用于退出某一线程:pthread_exit
void pthread_exit(void *retval);
- 1
参数介绍:
retval:指向线程退出状态的指针
当线程调用 pthread_exit 时,它会立即停止执行,并释放其栈空间。但是,线程的资源(如线程ID和线程属性)直到其他线程调用 pthread_join 来回收它时才会被完全释放。
示例:
#define NUM 3 void* thread_run(void* arg) { char* name = (char*)arg; while(true) { std::cout << "new thread running,thread name is:" << name << std::endl; sleep(4); break; } delete name; //释放空间 pthread_exit(nullptr); //退出调用的线程 } int main() { pthread_t tids[NUM]; for(int i = 0; i < NUM; i++) { // char thname[64]; char* thname = new char[64]; // snprintf(thname, sizeof(thname), "thread-%d", i + 1); snprintf(thname, 64, "thread-%d", i + 1); pthread_create(tids + i, nullptr, thread_run, thname);//创建线程池,将thname传参 } //等待线程 for(size_t i = 0; i < NUM; i++){ pthread_join(tids[i], nullptr); } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
这里只创建了三个子线程的线程池,来看看运行的效果:
线程等待参数 retval 与 线程退出参数 retval
先来看看这两个API的接口声明:
int pthread_join(pthread_t thread, void **retval); //线程等待接口
void pthread_exit(void *retval); //线程退出接口
- 1
- 2
两个函数之间的 retval 参数有关联吗?答案是有的。
一般创建进程都是为了帮助我们去完成某些任务,线程也是如此,创建线程也是为了帮助进程完成一部分任务。进程在完成任务后正常退出,返回对应的退出码。当然,进程完成到一定的任务时也会直接退出。
下面是进程退出的几个情况:
- 在 main 函数中调用 return 语句,返回对应的退出码;
- 在进程中任意代码处调用 exit 函数。当然调用 exit 函数需要传参,进程退出的退出码也就是传入exit 函数参数的值;
- 收到OS的终止信号
进程的退出码、退出信号的返回,是方便我们去查看当前进程是不是完成了指定的任务。线程也是如此,线程退出是否正常我们也要知道。对此,上面提到的 两个 API 接口的参数作用就是用于获取线程退出的退出信息!
线程退出接口 pthread_exit 一般是用在回调函数内部,也就是子线程中。我们可以先将 pthread_exit 功能想象成 exit 函数那般,在子线程退出后我们将子线程退出码带出来。
但是问题来了,为什么 pthread_exit 传入的参数是 void* retval 一级指针?
这个要结合 pthread_join 来看:
int pthread_join(pthread_t thread, void **retval);
- 1
pthread_join 是等待线程的一个接口,会回收退出的子线程(线程的ID、线程的属性等)。pthread_join 的 retval 是一个输出型参数。
这里的 retval 如同在进程中调用的 wait 函数时,传入 status 参数,这个 status 也是输出型参数,会将 子进程的退出码、退出信号带出来。
retval 参数的作用就是将子线程的退出数据带出来,不同的是这里是二级指针。在使用前需要定义一个指针,然后将这个指针的地址传入 pthread_join 的 retval 参数中。在子线程调用 pthread_exit 函数时,传出对应的数据即可。
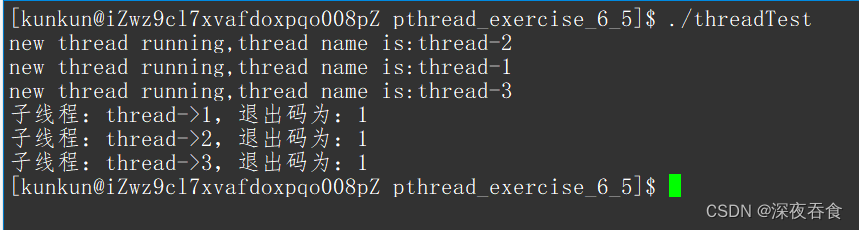
光说不做,假把戏。下面来看看测试案例:
void *thread_run(void *arg) { char *name = (char *)arg; while (true) { std::cout << "new thread running,thread name is:" << name << std::endl; sleep(3); break; } delete name; // 释放空间 pthread_exit((void*)1); //子线程退出,退出信息设置为1 } int main() { pthread_t tids[NUM]; for (int i = 0; i < NUM; i++) { char *thname = new char[64]; snprintf(thname, 64, "thread-%d", i + 1); pthread_create(tids + i, nullptr, thread_run, thname); // 创建线程池,将thname传参 } void *ret = nullptr; // 用于保存子线程退出的信息 for (size_t i = 0; i < NUM; i++) { int n = pthread_join(tids[i], &ret); //传入ret指针的地址 if(n != 0) std::cerr << "pthread_join error" << std::endl; std::cout << "子线程:thread->" << i+1 << ",退出码为:" << (uint64_t)ret << std::endl; } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
这里需要注意就是传指针的问题:
定义 ret 一级指针,传参到 pthread_join 内部时,传入的是 ret 指针的地址。pthread_exit 传参需要传入指针类型,对此上面代码需要对 1 进行 void* 类型的强转。在输出子线程退出信息时,ret 是指针,经过子线程的等待,ret内部值已经被设置为了除了低位的第一位为1其他全为 0 的二进制序列,在通过 uint64_t 类型强转即可将数据打印输出!
还要提一点就是:在获取线程的退出码时,是不需要考虑异常的。如果一个线程中出现了异常,那么就会带动的整个主进程退出。主进程都退出了还需要考虑等待进程的异常吗?是不需要的。对此,在多线程中是不需要考虑异常的!异常问题通常是由进程来考虑。
线程中断 pthread_cancel
在实际开发需求中,如果想要将创建的线程中断运行需要用到 API:pthread_cancel
int pthread_cancel(pthread_t thread);
- 1
参数介绍:
thread:传入的线程编号
示例:我们先来创建一个正常线程,再执行一段任务后线程会自动退出:
void* thread_run(void* args) { //静态类型转换 const char* str = static_cast<const char*>(args); int cnt = 5; while(cnt) { cout << str << "is runing :" << cnt-- << endl; sleep(1); } //退出线程 pthread_exit((void*)1); } int main() { //创建线程 pthread_t tid; pthread_create(&tid, nullptr, thread_run, (void*)"thread 1"); //等待线程 void* ret = nullptr; pthread_join(tid, &ret); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29

修改上述代码,在线程执行两秒任务后,直接调用 pthread_cancel 接口,查看现象:
void* thread_run(void* args) { //静态类型转换 const char* str = static_cast<const char*>(args); int cnt = 5; while(cnt) { cout << str << "is runing :" << cnt-- << endl; sleep(1); } //退出线程 pthread_exit((void*)1); } int main() { //创建线程 pthread_t tid; pthread_create(&tid, nullptr, thread_run, (void*)"thread 1"); //2秒后,中断线程 sleep(2); pthread_cancel(tid); //等待线程 void* ret = nullptr; pthread_join(tid, &ret); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32

可以看到当线程执行两秒后直接中断
获取线程编号 pthread_self
pthread_t pthread_self(void);
- 1
谁调用这个接口就获取谁的线程 id 编号,示例:
void* thread_run(void* args) { //静态类型转换 const char* str = static_cast<const char*>(args); int cnt = 5; while(cnt) { cout << str << "is runing :" << cnt-- << "obtain self id ->" << pthread_self() << endl; //获取线程id sleep(1); } //退出线程 pthread_exit((void*)1); } int main() { //创建线程 pthread_t tid; pthread_create(&tid, nullptr, thread_run, (void*)"thread 1"); //等待线程 void* ret = nullptr; pthread_join(tid, &ret); cout << " new thread exit : " << (int64_t)ret << "quit thread: " << tid << endl; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

线程分离 pthread_detach
新线程被创建,默认情况下是 joinable 的,线程退出,主进程需要对这个线程进行 pthread_join 操作。不对线程进行等待的操作就会造成内存泄漏,无法释放资源。
如果不关心线程的返回值,那么等待就会变成一种负担。
就是主线程自己为了等待子线程,难道不用去做自己的事情了吗?这个时候,我们可以告诉OS,当线程退出的时候,自己去释放资源。如何操作呢?需要用到下面这个 API :
int pthread_detach(pthread_t thread);
- 1
pthread_detach 功能是将一个线程分离出来,但是要记住一个点:被分离的线程在后续操作是不能被等待的!!如果对被分离的线程进行 pthread_join 操作,主进程是会报错的。报错出现后,就不会再对子线程进行等待操作,直接向后运行属于主进程的代码。
线程分离好比现实生活中的:已婚与未婚,是属于一种属性。
线程分离,并不是字面上的意思将线程与进程分离开那种。分离是一种属性,没有被分离的线程,是 joinable 的。该线程需要被等待回收资源;已经被分离的线程,其内部属性会发生变化,表示这个线程不需要再被等待回收资源。
示例:创建一个子线程,在等待子线程之前对该子线程进行分离操作
#include <pthread.h> #include <iostream> #include <cstdio> #include <cstring> #include <unistd.h> #include <string> using namespace std; void* threadRoution(void* arg) { const char* tname = static_cast<const char*>(arg); int cnt = 5; while(cnt) { cout << tname << ":" << cnt-- << endl; sleep(1); } return nullptr; } int main() { //创建线程 pthread_t tid; pthread_create(&tid, nullptr, threadRoution, (void*)"thread 1"); //对子线程进行分离操作 pthread_detach(tid); //等待线程 void* ret = nullptr; int n = pthread_join(tid, &ret); if(n != 0) cerr << "error:" << errno << strerror(n) << endl; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
编译查看效果:

主进程在等待子线程时,发现该线程已经被分离。对此,不会再阻塞等待子线程,程序直接向后运行走,子线程也没有机会继续执行对应的功能,整个进程就退出了。
因此,线程分离的主要功能就是将子线程分离出来,让主进程有更多的时间去处理属于自己事情,也不需要对子线程的资源释放与否而担心。
不过在使用线程分离的时候,要注意执行流先后问题,不然会出现奇奇怪怪的现象。
下面来举个例子:在子线程内部去调用本线程的分离
void* threadRoution(void* arg) { //将调用的线程分离开来 pthread_detach(pthread_self()); const char* tname = static_cast<const char*>(arg); int cnt = 5; while(cnt) { cout << tname << ":" << cnt-- << endl; sleep(1); } return nullptr; } int main() { //创建线程 pthread_t tid; pthread_create(&tid, nullptr, threadRoution, (void*)"thread 1"); int n = pthread_join(tid, nullptr); if(n != 0) cerr << "error:" << errno << strerror(n) << endl; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
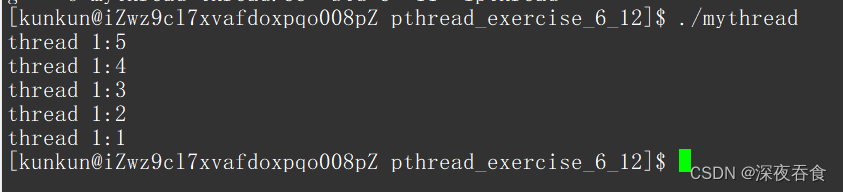
此时会发现,线程正常的跑,主进程也等待成功。
子线程调用分离没有用吗?其实不然,这是由于执行流先后问题:
子线程被创建出来之前,主进程就执行到了 pthread_join 代码处,子线程还没有来得及分离,分离属性没有被修改,造成主进程阻塞等待子线程。对此,就算子线程将自己分离开来,主进程早就处于进行了等待状态,也就造成了子线程继续往后执行的现象。
提示:使用线程分离的接口,尽量在创建线程之后进行调用,防止奇奇怪怪的执行流的问题产生
线程操作就讲到这里,感谢大家的支持!!

