
- 14.k8s:cronJob计划任务,初始化容器,污点、容忍,亲和力,身份认证和权限
- 2C语言----二维数组
- 3创建Oracle本地数据库详细步骤,Oracle-创建本地数据库
- 4Ubuntu下的STM32开发环境搭建(VScode+CubeMX+arm-none-eabi-gcc交叉编译工具链),使用JLink进行烧录(非OpenOCD),使用Ozone进行调试_ozone调试
- 5【java基础-实战3】list遍历时删除元素的方法_list 遍历删除
- 6【云计算学习教程】探讨私有云计算平台的搭建(附带3套解决方案)_私有云云平台解决方案学习路径(3)_如何学习私有云
- 7LiveGBS流媒体平台GB/T28181功能-获取GB28181接入的海康大华宇视华为摄像头硬件NVR设备通道视频直播流地址HLS/HTTP-FLV/WS-FLV/WebRTC/RTMP/RTSP_gb28181平台
- 8【附源码】流浪动物救助及领养管理系统(源码+毕业论文齐全)java开发ssm框架javaweb javaee项目,可做计算机毕业设计或课程设计_流浪动物救助系统
- 9网易 Duilib:功能全面的开源桌面 UI 开发框架_duilib 跨平台
- 10cookie,session和token的区别_chrome查看token
浅谈Hive(分布式SQL计算工具)_hive计算
赞
踩
目录
前言
在Hive诞生之前,大数据分析通常需要编写复杂的MapReduce代码,这对非专业技术人员来说很困难。Hive的出现使得数据分析变得更加容易,开发人员可以使用类似于SQL的语言(HiveQL)进行查询和分析,而无需编写复杂的MapReduce代码。同时,Hive还提供了用于将查询转换为MapReduce任务的引擎,使得数据分析人员可以轻松地利用Hadoop集群的计算能力。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。Hive还支持分区表、分桶表、自定义函数等高级功能,为用户提供了灵活的数据处理和分析能力。
分区表:
Hive中的分区表是一种将数据按照某个或多个列的值进行划分和存储的方式。通过分区,可以将数据按照特定的维度进行组织,从而提高查询效率和数据管理的灵活性。

分区表基本语法:
- create table tablename(...) partitioned by (分区列 列类型, ......)
- row format delimited fields terminated by '';
分桶表:
分桶表是将Hive表中的数据进一步划分成固定数目的桶(bucket),每个桶中包含相同数量的数据,并且每个桶都按照指定的列进行排序。分桶也是一种表优化方式,但它与分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储。

分桶表基本语法:
- #开启分桶的自动优化(自动匹配reduce task数量和桶数量一致)
- set hive.enforce.bucketing=true;
- #创建分桶表
- create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
Hive启动:
hive依赖于Hadoop,所以运行hive之前要先运行HDFS跟YARN以确保Hadoop在运行当中,使用jps可以查看以下的服务是否启动完成。

Metastore:
Metastore在Hive中扮演着至关重要的角色,主要用于存储Hive表的元数据信息。这些元数据信息包括表的结构、数据类型、存储格式、位置等。通过Metastore,Hive允许用户轻松创建、管理和查询表,从而实现对数据的统一管理和查询。
启动Metastore服务:
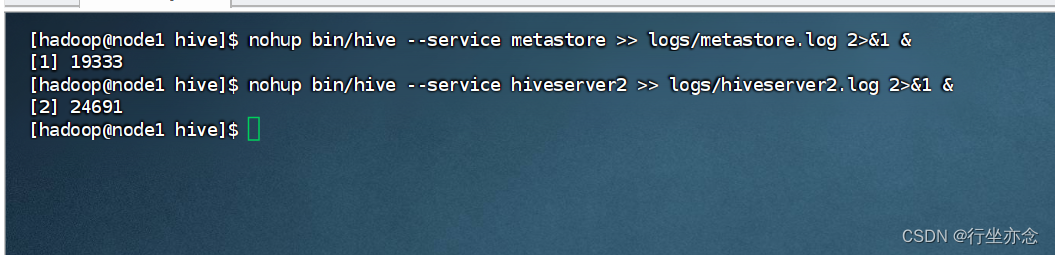
我们先来到hive的文件目录之下
- cd /export/server/hive/
- nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &

HiveServer2:
HiveServer2 是 Hive 架构中的一个关键组件,它使得 Hive 能够支持多种客户端的连接和数据访问
1.HiveServer2 是 Hive 提供的服务组件之一,它负责接受客户端的连接请求,并管理客户端与 Hive 之间的会话。
2.通过 HiveServer2,用户可以使用多种客户端工具(如 JDBC、ODBC、Beeline 等)来连接到 Hive,并执行 SQL 查询。
3.HiveServer2 还提供了多用户并发访问的能力,使得多个用户可以同时连接到 Hive,并执行查询操作。
启动HiveServer2服务:
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
hive:
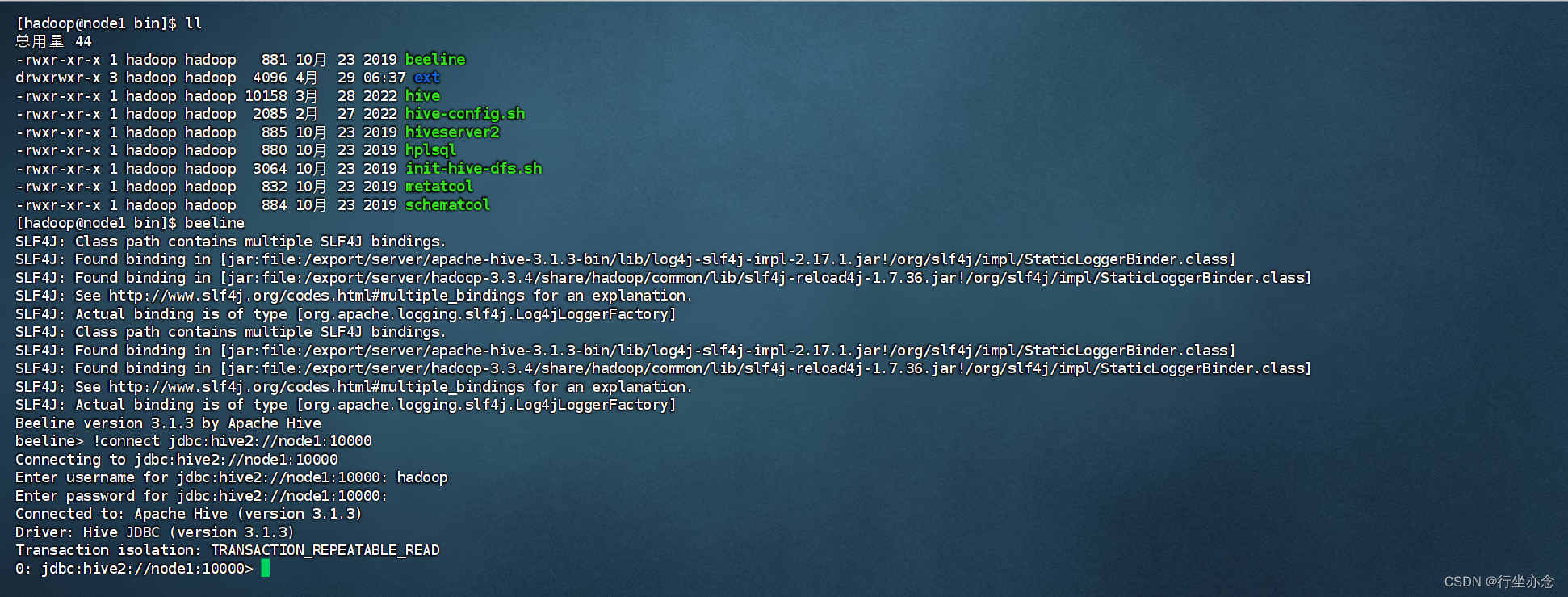
cd进入hive的bin目录在bin目录下使用ll命令可以看到文件中有hive跟beeline:
hive有两大客户端一个是hive一个是beeline,接下来一个个演示如何打开

- cd bin
- ll
- hive
在bin文件目录执行hive命令像下面这样即为成功。

beeline:
还是在bin目录下输入命令:
- beeline
- !connect jdbc:hive2://node1:10000
如下表明成功(Enter username for jdbc:hive2://node1:10000:这里输入的是你的系统用户的名字,密码没有设置可以直接回车):
idea使用JDBC连接hive:
先保证自己的hive的lib文件目录下有hive-jdbc的jar包 以及mysql-connector-java的jar包:
没有的话可以自取(这里是3.1.2版本hive-jdbc的jar包)
链接:https://pan.baidu.com/s/19HHQHICcINV6WLSpbPzpDw?pwd=vwu2
提取码:vwu2
将其放在lib目录下(推荐使用FinalShell上传文件到Linux)
新建maven项目在pom.xml里面添加仓库跟依赖:
- <repositories>
- <!-- 添加Cloudera仓库 -->
- <repository>
- <id>cloudera-repos</id>
- <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
- <releases>
- <enabled>true</enabled>
- </releases>
- <snapshots>
- <enabled>false</enabled>
- </snapshots>
- </repository>
- <!-- 其他的仓库配置 -->
- </repositories>
- <dependencies>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-data-jdbc</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-web</artifactId>
- </dependency>
-
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-test</artifactId>
- <scope>test</scope>
- </dependency>
-
- <dependency>
- <groupId>org.apache.hive</groupId>
- <artifactId>hive-jdbc</artifactId>
- <version>3.1.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.commons</groupId>
- <artifactId>commons-dbcp2</artifactId>
- <version>2.8.0</version>
- </dependency>
- <dependency>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok</artifactId>
- <version>1.18.30</version>
- </dependency>
-
-
-
- </dependencies>

新建HiveJdbcClient类(在第11行jdbcUrl这里如果自己的主机映射不一样就改这里的名字映射文件在hosts里面):
- ublic class HiveJdbcClient {
- private static String driverName = "org.apache.hive.jdbc.HiveDriver";
- public static void main(String[] args) throws SQLException {
- try {
- Class.forName(driverName);
- } catch (ClassNotFoundException e) {
- // Handle exceptions for JDBC driver
- e.printStackTrace();
- System.exit(1);
- }
- String jdbcUrl = "jdbc:hive2://node1:10000";
- Connection con = DriverManager.getConnection(jdbcUrl, "hadoop", "");
-
- // Create a Statement
- Statement stmt = con.createStatement();
- System.out.println("----------------连接成功----------------");
-
- // Execute a query
- String tableName = "temp";
- String sql = "SELECT * FROM " + tableName + " LIMIT 10";
- System.out.println("Running: " + sql);
- ResultSet res = stmt.executeQuery(sql);
-
- // Retrieve and print the results
- while (res.next()) {
- System.out.println(String.valueOf(res.getString(1)+ "\t" +res.getInt(2)) + "\t" +res.getInt(3));
- }
-
- // Clean up resources
- res.close();
- stmt.close();
- con.close();
- }
- }
没有报错证明已经连接成功(那个select只是我写的一个查询语句看看能不能用,连接上没问题是能用的,只是可能你们的hive里面没有表所以查不出数据很正常):

以上是一些学习心得,有不正确的地方请多多指教。

