
- 190% 项目经理的复盘方法!_项目经理成果物
- 2从源码理解 Vue-Router 实现原理_vue路由源码的实现原理
- 3随手记:HBuilder X真机调试找不到iOS设备_hbuilderx检测不到ios设备
- 4数通IP-222_假设对标记为af21的报文,设置的wred丢弃策略为:下限设为35,上限设为40,丢弃概率是
- 5使用Ollama本地部署Llama 3.1大模型_ollama llama3.1
- 6Kibana8.5破解白金版,配置webhook推送日志告警到钉钉_kibana webhook
- 7IDEA Windows下Spark连接Hive_window本地 ideal中spark连接hive
- 8基于机器学习的车牌识别系统
- 9ROS2 入门应用 发布和订阅(Python)_python ros发布
- 10项目复盘成功的12条秘诀
Hadoop介绍:什么是Hadoop?了解Hadoop的应用_hadoop应用
赞
踩
一、认识Hadoop框架

Hadoop是一个提供分布式存储和计算的开源软件框架,使用Java语言编写,具有高扩展性、高容错性、无共享和高可用(HA)等特点,非常适合处理海量数据。它基于Google发布的MapReduce论文实现,并且应用了函数式编程的思想。
Hadoop框架主要包括HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)、MapReduce、YARN(Yet Another Resource Negotiator,另一种资源协调者)等模块。其中,HDFS是Hadoop集群中最根本的文件系统,提供了高扩展、高容错、机架感知数据存储等特性,可以非常方便的部署在机器上面。MapReduce是Hadoop的分布式计算框架,它将数据处理分成两个阶段,即Map阶段和Reduce阶段。在Map阶段,数据会被分成多个小的数据块,然后由不同的Map任务并行处理;在Reduce阶段,中间结果会被分组,并且由不同的Reduce任务并行处理,生成最终的输出结果。YARN则负责为Hadoop作业分配和管理资源。
Hadoop的工作原理主要依赖HDFS和MapReduce。HDFS将大文件分割成多个块,并存储在不同的计算节点上,以提高数据的可靠性和容错性。MapReduce则将数据处理分成Map阶段和Reduce阶段,通过并行处理来加快数据处理的速度。
Hadoop的优点包括:
- 高容错性:数据自动保存多个副本,并通过增加副本的形式提高容错性,当某个副本丢失时,它可以自动恢复。
- 适合处理大数据:能够处理数据规模达到GB、TB、甚至PB级别的数据,以及百万规模以上的文件数量。
- 可构建在廉价机器上:通过多副本机制提高可靠性。
然而,Hadoop也存在一些缺点,例如不适合低延时数据访问,无法高效地对大量小文件进行存储等。
总的来说,Hadoop是一个功能强大的分布式计算和存储框架,可以应用于各种大数据处理场景,如数据分析、数据挖掘、机器学习等。
二、了解Hadoop的核心组件
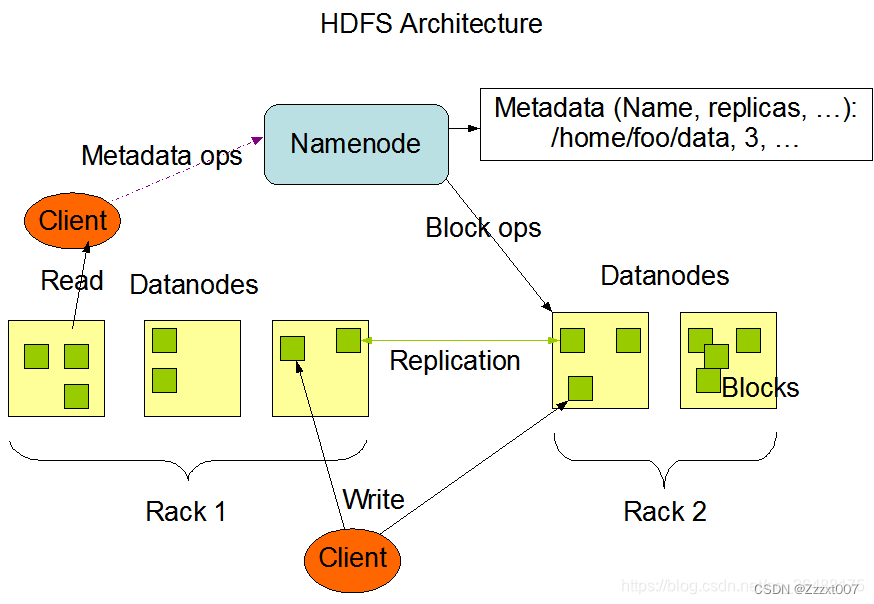
Hadoop的核心组件主要包括Hadoop Common、HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)、MapReduce以及YARN(Yet Another Resource Negotiator,另一种资源协调者)。
Hadoop的核心组件主要包括Hadoop Common、HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)、MapReduce以及YARN(Yet Another Resource Negotiator,另一种资源协调者)。
-
1.Hadoop Common:
- 这是Hadoop项目的基础,提供了许多支持其他Hadoop模块的工具和库。
- 包括文件系统(FileSystem)的抽象定义、RPC(远程过程调用)框架以及序列化机制等。
- Hadoop Common还包含Hadoop集群配置相关的API和工具,如配置文件管理、日志记录等。
-
2.HDFS(Hadoop Distributed File System):
- HDFS是Hadoop的分布式文件系统,用于存储和管理大规模数据集。
- 它设计用来在廉价硬件上运行,并提供高吞吐量的数据访问。
- HDFS将数据分成块(block)并分散存储在集群中的多个节点上,同时维护多个副本以提高容错性。
- 它提供了一个与本地文件系统类似的接口,使得用户可以像操作本地文件一样操作HDFS上的文件。
-
3.MapReduce:
- MapReduce是Hadoop的分布式计算框架,用于处理大规模数据集。
- 它将数据处理任务划分为Map阶段和Reduce阶段,并在集群中的多个节点上并行执行这些任务。
- 在Map阶段,输入数据被分割成小块并分配给集群中的节点进行并行处理,生成中间结果;在Reduce阶段,这些中间结果被汇总并生成最终输出。
- MapReduce模型简化了并行编程,使得开发者能够专注于业务逻辑而不是底层细节。
-
4.YARN(Yet Another Resource Negotiator):
- YARN是Hadoop的资源管理系统,负责为应用程序分配和管理集群资源。
- 它将资源管理和作业调度/监控功能分离,使得Hadoop集群能够同时运行多种不同的计算框架(如MapReduce、Spark等)。
- YARN包括ResourceManager、NodeManager、ApplicationMaster等组件,它们共同协作以有效地利用集群资源并执行用户提交的作业。
这些核心组件共同构成了Hadoop的基础架构,使得Hadoop能够处理大规模数据集并提供高效、可靠的分布式计算和存储服务。同时,Hadoop还提供了丰富的API和工具,使得开发者能够轻松地构建和部署基于Hadoop的应用程序。
三、了解Hadoop生态系统
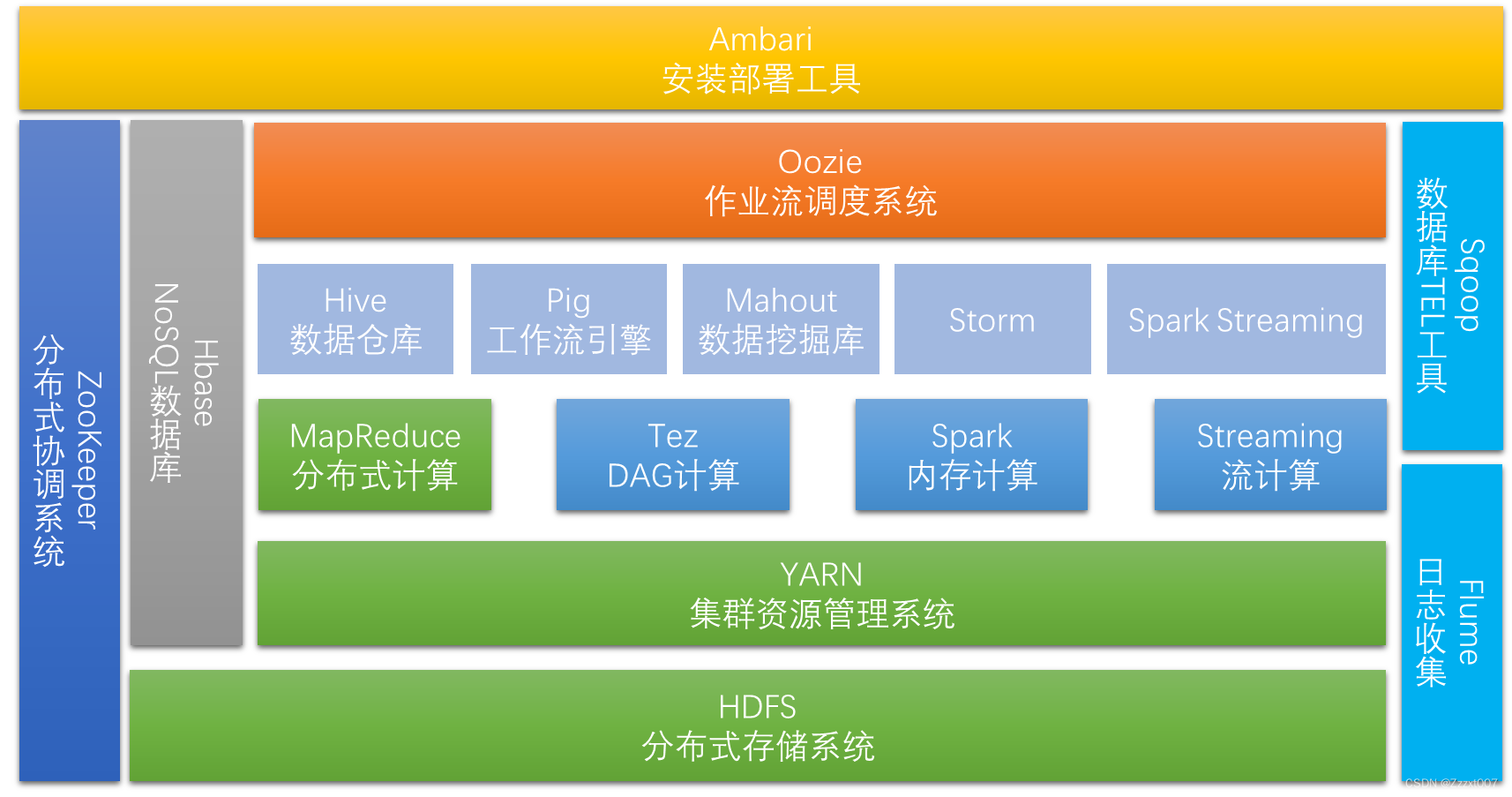
Hadoop生态系统是一个庞大且复杂的集合,它包含了多个组件,每个组件都有其独特的功能和角色,共同构成了大数据处理和分析的完整框架。
首先,Hadoop分布式文件系统(HDFS)是整个Hadoop体系的基础,负责数据的存储与管理。HDFS将数据分散存储在多个节点上,提供高可靠性和可扩展性,确保数据的持久性和安全性。
其次,MapReduce是一种分布式计算模型,用于处理大规模数据集。它将任务划分为多个小任务,并在集群中的节点上并行执行,最后合并结果。这种并行计算的方式能够显著提高数据处理的速度和效率。
YARN(Yet Another Resource Negotiator)是Hadoop生态系统中的资源管理器,负责管理和调度集群中的资源。它允许多个应用程序同时运行在集群上,并根据需要动态分配资源,提高了资源的利用率和系统的灵活性。
此外,Hadoop生态系统还包括其他重要组件,如Hive、Pig、ZooKeeper、Flume等。Hive是一个数据仓库工具,提供了类似于SQL的查询语言,方便用户进行数据分析。Pig是一个数据流语言和运行环境,用于处理和分析大规模数据集。ZooKeeper是一个分布式协调服务,用于实现分布式应用程序的协调和管理。Flume则是一个分布式、可靠和高可扩展性的日志收集和聚合系统。
这些组件在Hadoop生态系统中相互协作,形成了一个完整的大数据处理和分析平台。用户可以根据具体需求选择适合的组件和工具,构建自己的大数据应用程序。
总的来说,Hadoop生态系统是一个功能强大、灵活多变的大数据处理框架,它能够帮助企业和组织有效地管理和分析大规模数据集,从而发现其中的价值和洞察。随着技术的不断发展,Hadoop生态系统也在不断演进和完善,为用户提供更加高效、可靠和便捷的大数据解决方案。
四、了解Hadoop应用场景
Hadoop是一个开源的分布式计算框架,具有处理海量数据的能力,因此在许多领域都有广泛的应用。以下是一些Hadoop的主要应用场景:
- 日志分析:Hadoop可以处理和分析大量的日志数据,通过对日志数据进行聚合、过滤和统计,帮助企业了解用户行为、系统性能等信息,从而优化业务和决策。
- 数据仓库和数据湖:Hadoop可以用作数据仓库和数据湖,帮助企业存储和处理包括交易数据、客户数据、市场数据等在内的大规模数据,同时支持数据分析和查询。
- 风险管理:金融机构需要对风险进行实时监控和管理,Hadoop可以帮助金融机构管理和分析大规模的数据,以满足监管要求。
- 社交网络分析:Hadoop可以分析和挖掘社交网络中的关系和模式,帮助企业了解用户的社交行为和兴趣。
- 物联网数据处理:Hadoop可以用于处理和分析物联网设备生成的大量数据,帮助企业监控和管理物联网系统。
- 病人监测与医疗数据处理:Hadoop的分布式计算和存储能力可以轻松应对大规模的病人监测数据,帮助医生及时了解病人的健康状况。同时,Hadoop还可以用于病历数据的归类和关联,为医生提供更全面的患者信息,从而辅助医生做出更准确的诊断和治疗决策。
- 电商领域的数据驱动的营销和销售:Hadoop可以帮助电商平台更好地挖掘数据价值,提高营销和销售效果。
此外,Hadoop还在农业、智慧城市、版权保护等多个领域有着广泛的应用。总的来说,Hadoop适用于需要处理大规模数据、需要高性能计算和需要分布式处理的场景。
需要注意的是,虽然Hadoop具有强大的数据处理能力,但在实际应用中也需要根据具体的业务需求和场景来选择合适的工具和配置,以达到最佳的处理效果。同时,对于大数据的处理和分析,也需要结合其他技术和方法,如机器学习、数据挖掘等,以提供更全面和深入的分析结果。
小结:
Hadoop是一个开源的分布式计算框架,专为处理和分析大规模数据集而设计。其核心组件包括Hadoop Common、HDFS(分布式文件系统)、MapReduce(分布式计算模型)以及YARN(资源管理器)。这些组件共同协作,使得Hadoop能够高效、可靠地处理海量数据。
Hadoop的应用场景非常广泛,包括日志分析、数据仓库与数据湖、风险管理、社交网络分析、物联网数据处理以及医疗和电商等多个领域。其强大的分布式计算和存储能力使得企业能够更好地挖掘数据价值,优化业务决策,提高运营效率。
此外,Hadoop生态系统还包含了许多其他工具和组件,如Hive、Pig、ZooKeeper、Flume等,它们提供了更丰富的数据处理和分析功能,进一步增强了Hadoop的灵活性和可扩展性。
然而,值得注意的是,Hadoop并不是适用于所有场景的万金油。在选择是否使用Hadoop时,需要根据具体的业务需求、数据量大小以及技术栈等因素进行综合考虑。同时,Hadoop的使用也需要一定的技术储备和经验积累,以确保其能够发挥最大的价值。
总的来说,Hadoop是一个功能强大、灵活多变的大数据处理框架,它在许多领域都有着广泛的应用前景。随着技术的不断发展和完善,Hadoop将继续为企业和组织提供高效、可靠的大数据解决方案。

