
- 1docker安装,yum安装失败解决方案,阿里云镜像安装
- 2Mask RCNN保存分割后的图片_maskrcnn将分割的图片保存
- 3Win10中pyTorch1.4.0+tensorboard配置后graph显示空白_torch 1.4 对应tensorboard什么版本
- 4车辆信息检测数据集收集汇总_ngvsim数据集车辆id识别
- 5鸿蒙系统国内厂商,谷歌自食其果,华为鸿蒙系统已经被启用,国内厂商或将弃用安卓...
- 6GitHub Desktop安装与使用教程
- 7代码随想录算法训练营第三十三天 | 动态规划理论基础、509. 斐波那契数、70. 爬楼梯、746. 使用最小花费爬楼梯
- 8HTML5果蔬电商购物网站css3+html5模板_h5农产品购物网站开源
- 9fragment 实现按键监听_fragment监听物理按键
- 10分布式时序数据库TimeLyre 9.2发布:原生多模态、高性能计算、极速时序回放分析
plsa(Probabilistic Latent Semantic Analysis) 概率隐语义分析_概率隐标签
赞
踩
Probabilistic Latent Semantic Analysis
主题模型简介
plsa,也就是概率隐语义分析,是主题模型的一种。主题模型是什么呢?先从文档说起,每篇文档用bag-of-words模型表示,也就是每篇文档只与所包含的词有关,而不考虑这些词的先后顺序。假设文档集
所以,如果我们有文档集
主题模型的用处还是很多的,在推荐系统,舆情监控等等,都有广泛的用途。
plsa原理
介绍完主题模型的基本概念,就要回到本文的重点,给定一个文档集
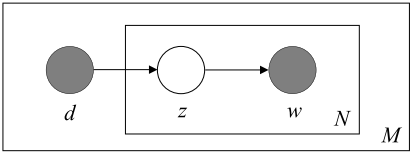
首先介绍一下图中参数:
plsa是一个生成模型,它假设了
1. 以概率
2. 以概率
3. 以概率
我们需要估计的参数就是
再写出log似然函数

