
热门标签
热门文章
- 1python re模块compile_python正则表达式re模块理解(RE.COMPILE、RE.MATCH、RE.SEARCH)(六)...
- 2关于git配置代理的方法和一些需要注意的细节_git config --global proxy
- 3多模态大模型代表了人工智能领域的新一代技术范式
- 4计算机毕业设计hadoop+pyspark图书推荐系统 豆瓣图书数据分析可视化大屏 豆瓣图书爬虫 知识图谱 图书大数据 大数据毕业设计 机器学习_基于pyspark的推荐系统
- 5Caused by: kotlin.UninitializedPropertyAccessException: lateinit property rv has not been initialize
- 6弹出框 custombox.min.js 使用时候由于滚动条隐藏造成网页抖动变形的解决办法
- 7面相_面相 马鞍鼻
- 8数据安全与隐私保护在返利App中的实施策略
- 9Unity编程笔录--Unity Android 加密 so_unity text encry release
- 10STM32智能小车学习笔记(避障、循迹、跟随)_stm32f103rct6小车结合串口的避障循迹代码
当前位置: article > 正文
python的pandas重复值处理(duplicated()和drop_duplicates())_pandas duplicate
作者:黑客灵魂 | 2024-06-26 16:37:32
赞
踩
pandas duplicate
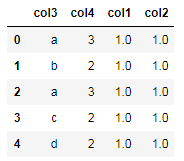
一、生成重复记录数据
- import numpy as np
- import pandas as pd
-
- #生成重复数据
- df=pd.DataFrame(np.ones([5,2]),columns=['col1','col2'])
- df['col3']=['a','b','a','c','d']
- df['col4']=[3,2,3,2,2]
- df=df.reindex(columns=['col3','col4','col1','col2']) #将新增的一列排在第一列
- df
输出:
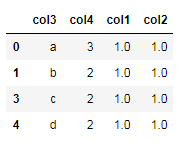
二、判断重复记录(行)
- #判断重复数据
- isDplicated=df.duplicated() #判断重复数据记录
- isDplicated
输出:

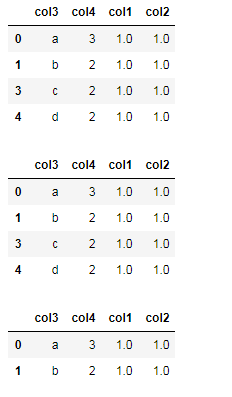
三、删除重复值
- #删除重复值
- new_df1=df.drop_duplicates() #删除数据记录中所有列值相同的记录
- new_df2=df.drop_duplicates(['col3']) #删除数据记录中col3列值相同的记录
- new_df3=df.drop_duplicates(['col4']) #删除数据记录中col4列值相同的记录
- new_df4=df.drop_duplicates(['col3','col4']) #删除数据记录中(col3和col4)列值相同的记录
- new_df1
- new_df2
- new_df3
- new_df4
输出:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/黑客灵魂/article/detail/759910
推荐阅读

相关标签

