
- 1hadoop学习---基于Hive的聊天数据分析报表可视化案例_基于一个社交平台app的用户数据,完成相关指标的统计分析并结合bi工具对指标进行可
- 2成功解决TypeError: 'float' object cannot be interpreted as an integer
- 3BM25:信息检索的核心算法解析
- 4Python学习第一步之Typora简单用法_typora怎么运行python
- 5Linux 服务器基线配置_csdn linux 安全基线
- 6远程控制(command&control,C2)---Fast flux_控制 (c2) 服务器
- 7机器学习基本概念01_机器学习的样本
- 8数据库课设(图书管理系统)_数据库设置管理图书馆保管和借还的数据库
- 9建筑主体结构健康监测,高层建筑如何预警结构异常
- 10头歌Python程序设计——输入输出_头歌利用python进行语音输入
【NLP】LSTM实现THUCNews中文新闻分类(Pytorch)上_thucnews 分类 torch
赞
踩
0.前言
这两天都在恶补NLP的基础知识,又看了几篇ICD编码分类的论文,好像有点头绪,又对好多Github上的代码看的云里雾里的。
RNN做手写体识别的时候非常顺利,导致我把LSTM的中文新闻分类想的太简单了,中途也碰到了很多问题,比如文件路径,版本问题等等。所以,我将整个实现分成了上下两个部分,上半部分主要是对数据的处理。
1.长短期记忆网络(LSTM)
该网络是一种特殊的RNN,主要用于解决长序列训练过程中的梯度消失和梯度爆炸问题,相较于RNN它具有更好地效果,同时,它也有更多需要学习的超参数。它包括了遗忘阶段,选择记忆阶段以及输出阶段,真的很复杂复杂,我反正不知道是怎么想到怎么会有这么个结构的,我这里我还是主打一个实现,要想真正理解LSTM,请参考其他博客。
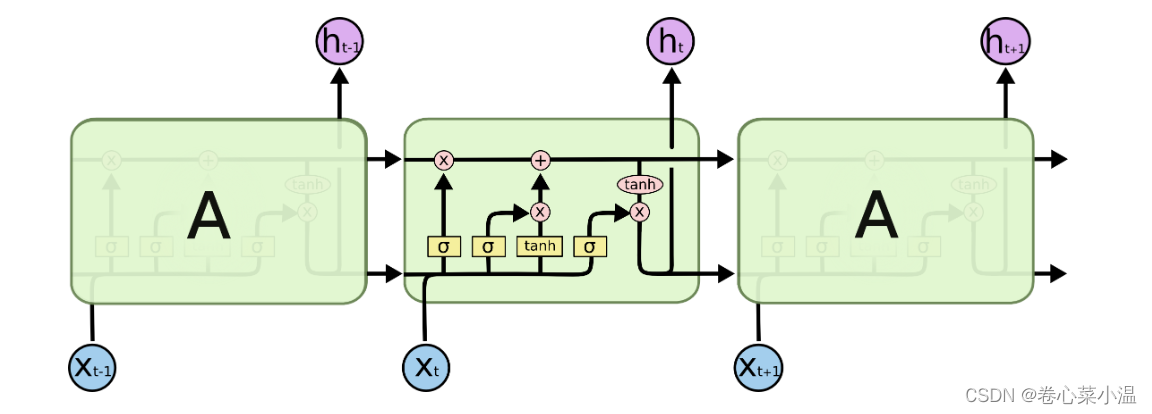
2.LSTM实现中文新闻分类
2.1导入所需要的包
这里!我要重点提三点!
1.是这个华文细黑.ttf是需要自己从网上去下载的,然后加载的时候使用自己的路径。
我这里放在百度云盘,自取。
链接:https://pan.baidu.com/s/1Z7joXRSqr4mtudG6032B3w
提取码:qsa1

2.jieba库的安装,请先安装Tensorflow,这个玩意儿的安装也很讲究,可以参考其他CSDN博客安装。就提一嘴,如果是安装gpu版本的,请先查看自己的CUDA和cudnn的版本,再下载对应得Tensorflow。本人CUDA11.6,cudnnv8.4.0(8200),安装tensorflow-gpu==2.6.0。
3.关于Field已经在torchtext高版本中被删除这一遗憾的事。绿色框框是书上代码的原版,但是!就是会报错,说没有Field这一模块了。所以咱们就改成红色部分来使用就可以了。

- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import seaborn as sns
- ##输出图显示中文
- from matplotlib.font_manager import FontProperties
- fonts = FontProperties(fname = "C:/Users/97332/Desktop/Data/华文细黑.ttf")
- import re #处理文本数据
- import string #处理文本数据
- import copy
- import time
- from sklearn.metrics import accuracy_score,confusion_matrix
- import torch
- from torch import nn
- import torch.nn.functional as F
- import torch.optim as optim
- import torch.utils.data as Data
- import jieba #中文分词操作
- #torchtext库可将数据表中的数据整理为Pytorch网络可用的数据张量
- #from torchtext import data
- from torchtext.vocab import Vectors
- import torchtext
- from torchtext.legacy.data import Field,TabularDataset,Iterator,BucketIterator

2.2数据的读取和预处理
2.2.1读取数据
好,我这里又搞了好久,因为本人没找到数据集和停用词库,找了40min,还花了3毛钱,这里无偿分享给大家。下载之后,路径部分就写自己的路径。
放百度云盘,自取。
数据集:链接:https://pan.baidu.com/s/1PmRx4XsYWe-uLlUGLgOnRA
提取码:czdv
停用词库:链接:https://pan.baidu.com/s/11h8BHudATt0vQQfhYrNJAA
提取码:wcl5
- train_df = pd.read_csv("C:/Users/97332/Desktop/Data/cnews/cnews.train.txt",sep="\t",header=None,names=["label","text"])
- val_df = pd.read_csv("C:/Users/97332/Desktop/Data/cnews/cnews.val.txt",sep="\t",header=None,names=["label","text"])
- test_df = pd.read_csv("C:/Users/97332/Desktop/Data/cnews/cnews.test.txt",sep="\t",header=None,names=["label","text"])
- stop_words = pd.read_csv(r"C:/Users/97332/Desktop/Data/cn_stopwords.txt",sep="\t",header=None,names=["text"])
2.2.2对数据进行预处理
我们设置一个函数用于对文本数据进行去除一些不需要的字符、分词、停用词等操作。
- def chinese_pre(text_data):
- ##字母转换成小写,去除数字
- text_data = text_data.lower() #将文本中所有的英文大写转换成小写
- text_data = re.sub("\d+","",text_data) #\d是数字格式,这里就是把数字都去除了
- ##分词,使用精准模式
- text_data = list(jieba.cut(text_data,cut_all=False)) #False:精确模式,比较符合我们人的理解;True:全模式,分的词很细,句子转换成词语
- ##去停用词和多余空格
- text_data = [word.strip() for word in text_data if word not in stop_words.text.values]
- ##处理后的词语使用空格连接成字符串
- text_data = " ".join(text_data)
- return text_data
函数设置好之后,利用数据表的apply方法将chinese_pre应用到三个数据表的文本信息中。
- train_df["cutword"] = train_df.text.apply(chinese_pre)
- val_df["cutword"] = val_df.text.apply(chinese_pre)
- test_df["cutword"] = test_df.text.apply(chinese_pre)
- print(train_df.cutword.head())
2.2.3类别标签编码
将10类文本数据使用0-9的数值进行表示,对文本的类别标签使用pandas库中的map方法,进行重新编码。这里要干的一件事:文本中的文本标签➡数字标签。
- labelMap = {"体育":0,"娱乐":1,"家居":2,"房产":3,"教育":4,"时尚":5,"时政":6,"游戏":7,"科技":8,"财经":9}
- ##使用Pandas库里的map方法,将数据集中label变量分别对应到0-9,生成新的变量labelcode
- train_df["labelcode"] = train_df["label"].map(labelMap)
- val_df["labelcode"] = val_df["label"].map(labelMap)
- test_df["labelcode"] = test_df["label"].map(labelMap)
2.2.4数据保存
将预处理后的文本cutword与重新编码的类别标签labelcode数据进行保存。使用数据框to_csv方法,将三个数据集的指定变量保存为csv文件。将数据保存为csv格式是为了方便利用torchtext库对文本数据进行预处理,以及方便使用Pytorch建立LSTM网络对数据集的调用。
- train_df[["labelcode","cutword"]].to_csv("C:/Users/97332/Desktop/Data/cnews/cnews_train2.csv",index=False)
- val_df[["labelcode","cutword"]].to_csv("C:/Users/97332/Desktop/Data/cnews/cnews_val2.csv",index=False)
- test_df[["labelcode","cutword"]].to_csv("C:/Users/97332/Desktop/Data/cnews/cnews_test2.csv",index=False)
2.3数据的再处理和单词表的建立
2.3.1数据再处理
数据预处理只是做了一些简单的去除,加标签等,要想最终的分类效果好,还得进一步对数据进行相应的处理,这里我们使用torchtext库对数据再进行处理,再传进LSTM网络。
我们可以从2.2.2的结果可知,每一行的词与词之间都是由空格隔开的,所以我们这里要取每一个词就用空格隔开来取。之后使用Field函数实例化文本内容和类别标签(TEXT和LABEL),然后将实例和数据中的变量名称相对应,组成列表text_data_fields。
- mytokenize = lambda x : x.split() ##定义文本切分发,使用空格切分
- TEXT = Field(sequential=True,tokenize=mytokenize,
- include_lengths=True,use_vocab=True,
- batch_first=True,fix_length=400) #文本保持长度为400
- LABEL = Field(sequential=False,use_vocab=True,
- pad_token=None,unk_token=None)
- ##对所要读取的数据集的列进行处理
- text_data_fields = [
- ("labelcode",LABEL),
- ("cutword",TEXT)]
再将之前保存好的处理好的数据读取出来。
- #使用参数fields=text_data_fields来确定重新读取数据的处理过程
- traindata,valdata,testdata = TabularDataset.splits(
- path="C:/Users/97332/Desktop/Data/cnews",format="csv",
- train="cnews_train2.csv",fields=text_data_fields,
- validation="cnews_val2.csv",
- test="cnews_test2.csv",skip_header=True
- )
2.3.1单词表的建立
1.使用build_vocab()函数训练数据集建立单词表。
- TEXT.build_vocab(traindata,max_size=20000,vectors=None) #max_size=20000表示词表中只使用出现频率较高的前20000个单词,vectors=None表示不适用预训练好的词向量
- LABEL.build_vocab(traindata)
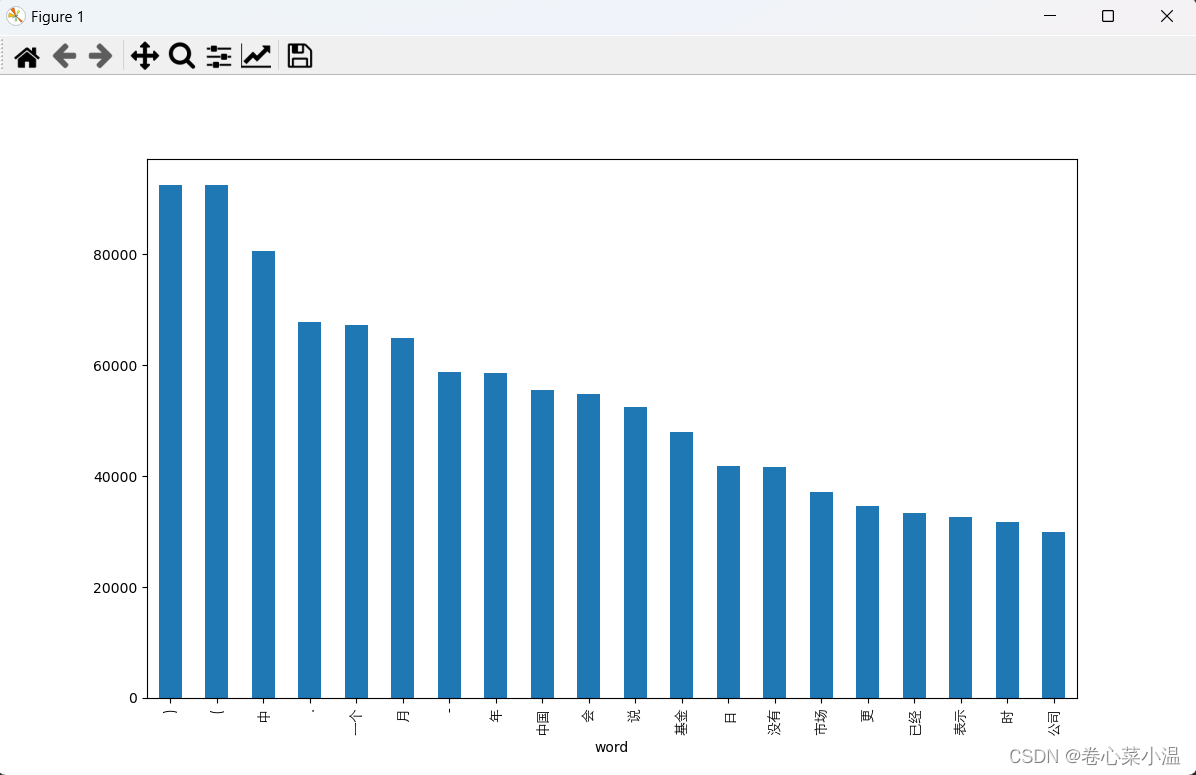
2.可视化训练集中的前20个高频词,使用vocab.freqs.most_common(n=20)方法获取词表中出现频率最高的20个词语,然后进行可视化。
- word_fre = TEXT.vocab.freqs.most_common(n=20)
- word_fre = pd.DataFrame(data=word_fre,columns=["word","fre"])
- word_fre.plot(x="word",y="fre",kind="bar",legend=False,figsize=(12,7))
- plt.xticks(rotation = 90,fontproperties = fonts,size=10)
- plt.show()
可视化结果。
2.4设置数据加载器
数据处理好了,单词表也建立好了,要想LSTM网络可以使用这些处理好的数据,就必须再设置一个数据加载器,用于数据的读取。
- ##定义一个加载器。将类似长度的示例一批处理
- BATCH_SIZE = 64
- train_iter = BucketIterator(traindata,batch_size=BATCH_SIZE)
- val_iter = BucketIterator(valdata,batch_size=BATCH_SIZE)
- test_iter = BucketIterator(testdata,batch_size=BATCH_SIZE)
3.总结
ok,上半部分的实现就到这里了,后续模型的实现,分类预测都放在了下半部分。

