
- 1[转载]静态成员函数能不能同时也是虚函数?
- 2Git切换账号并推送代码_gitlab切换用户然后拉代码
- 3java输入与输出_java输入和输出
- 412.6 Python read()函数:按字节(字符)读取文件_不管f是文本文件还是二进制总结,f.read()都可以读出文件所有内容
- 5技术领导力实战笔记:14
- 6火车头采集器ChatGPT伪原创接口-火车头伪原创插件的使用指南
- 7【unity】关于unity3D摄像机视角移动的几种方式详解_unity鼠标控制摄像头
- 8如何写一封稍微像样的求职邮件
- 9快速学会python基本编程学习笔记_python快速编程re大学笔记
- 10数据库第四次试验:数据库的组合查询、统计查询及视图_librarydb数据查询实训
MapReduce编程实践报告_mapreduce编程实践实验报告
赞
踩
代码来源和参考来自:MapReduce编程实践(Hadoop3.1.3)_厦大数据库实验室博客
- 实验目的
1.学习MapReduce在Hadoop中的实现。
2.实践WordCount程序:通过实现WordCount程序,具体应用MapReduce编程思想,理解如何将文本数据作为输入,通过map和reduce函数进行单词计数,并输出最终结果。
- 实验环境
操作系统:Linux
环境版本:ubuntu-18.04.6
Hadoop版本:hadoop3.1.3
Java 版本:jdk-8u162-linux
Eclipse版本:4.7.0
虚拟机:VMware
- 实验步骤及结果
1.词频统计任务要求
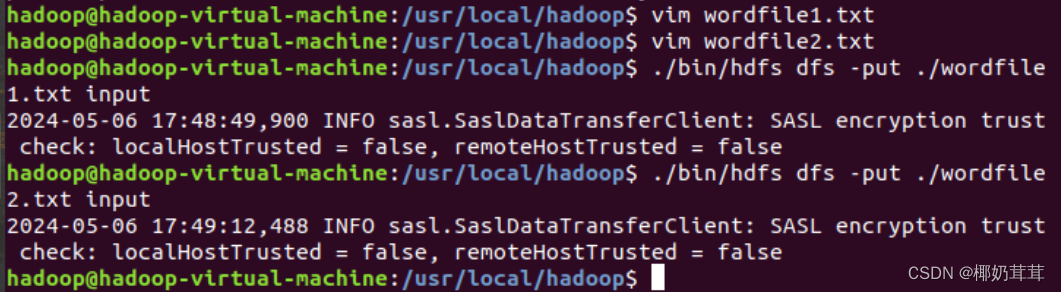
首先,在Linux系统本地创建两个文件,即文件wordfile1.txt和wordfile2.txt
![]()
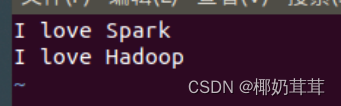
![]()
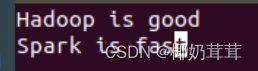
2.在Eclipse中创建项目
首先,启动Eclipse

并设置工作空间(workspace),点击“OK”按钮,打开eclipse界面,再选择“File-->New-->Java Project”菜单,开始创建一个Java工程,在“Project name”后面输入工程名称“WordCount”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/WordCount”目录下。在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如jdk1.8.0_162。然后,点击界面底部的“Next>”按钮,进入下一步的设置。
3.为项目添加需要用到的JAR包
进入下一步的设置以后,需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了与Hadoop相关的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮。需要添加以下的包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有JAR包,但是,不包括jdiff、lib、lib-examples和sources目录;
(4)“/usr/local/hadoop/share/hadoop/mapreduce/lib”目录下的所有JAR包。
完成以后如下:
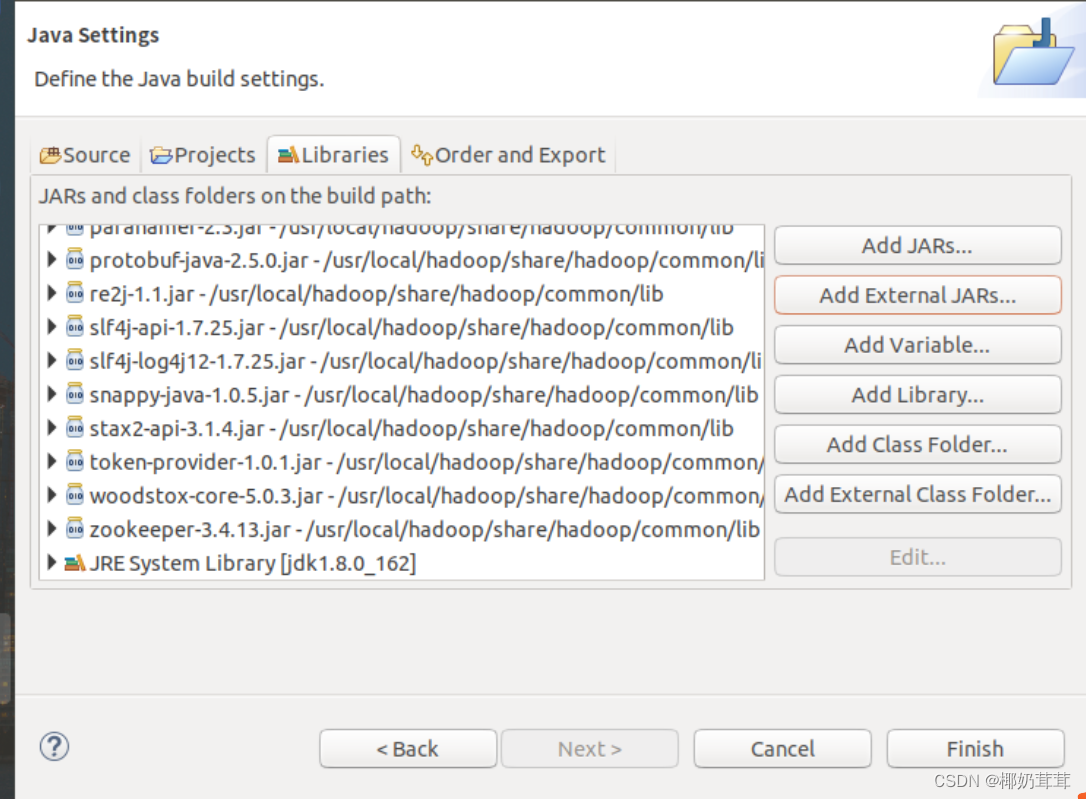
最后点击界面右下角的“Finish”按钮,完成Java工程WordCount的创建。
4.编写java应用程序
下面编写一个Java应用程序,即WordCount.java。请在Eclipse工作界面左侧的“Package Explorer”面板中,找到刚才创建好的工程名称“WordCount”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New-->Class”菜单。

选择“New-->Class”菜单以后会出现如下图所示界面。
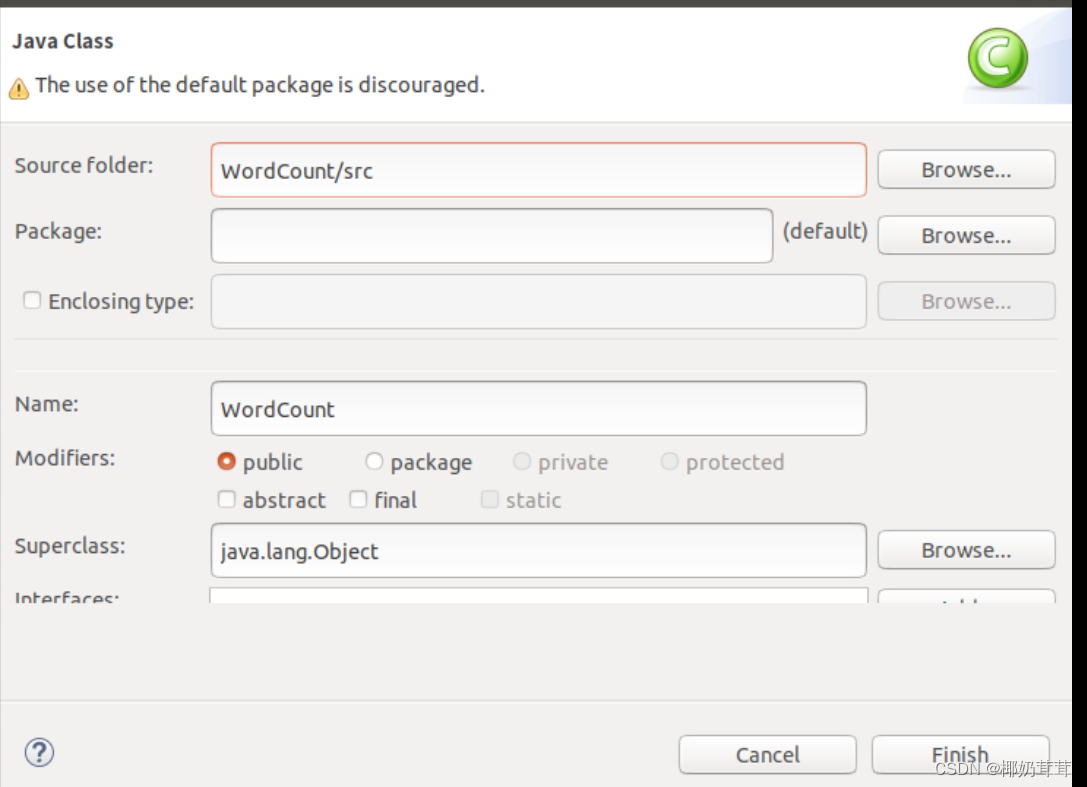
在该界面中,只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“WordCount”,其他都可以采用默认设置,然后,点击界面右下角“Finish”按钮,出现如下图所示界面。
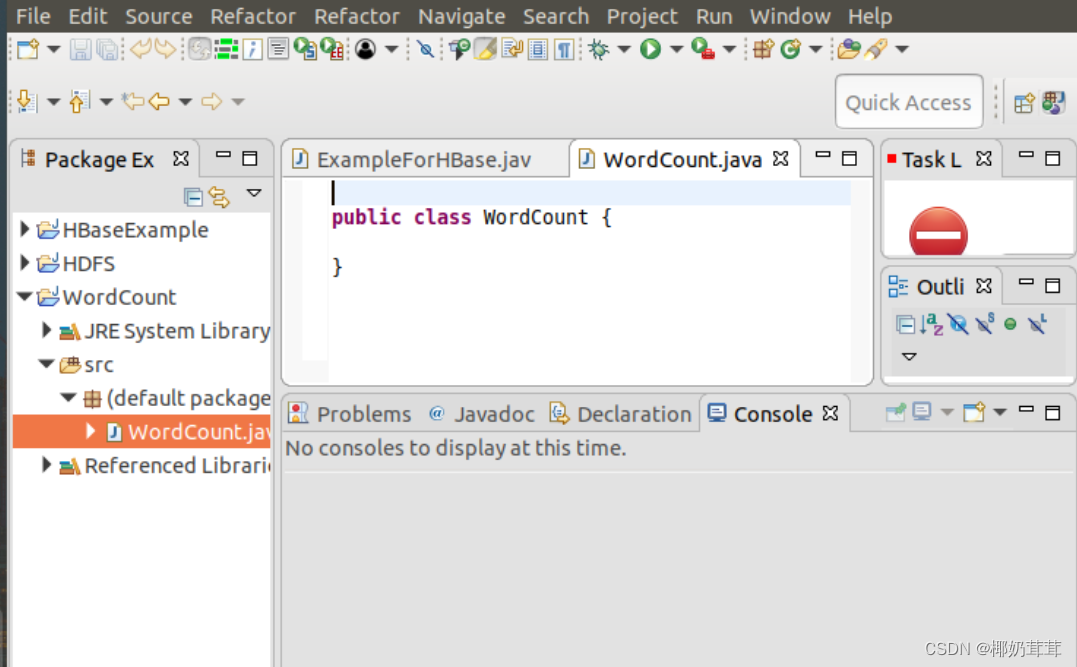
可以看出,Eclipse自动创建了一个名为“WordCount.java”的源代码文件,并且包含了代码“public class WordCount{}”,请清空该文件里面的代码,然后在该文件中输入完整的词频统计程序代码。
5.编译打包程序
编译上面编写的代码,可以直接点击Eclipse工作界面上部的运行程序的快捷按钮(倒三角),当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run as”,继续在弹出来的菜单中选择“Java Application”,然后会弹出一个界面,点OK就可以运行程序了,运行出来如下图:
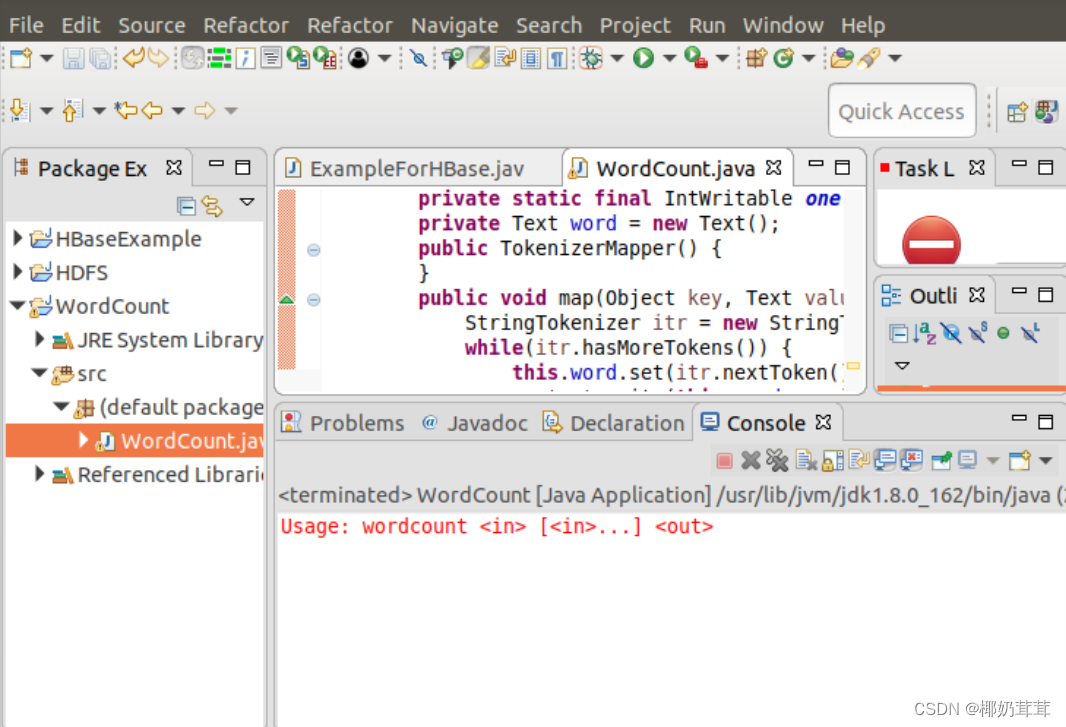

下面就可以把Java应用程序打包生成JAR包,部署到Hadoop平台上运行。现在可以把词频统计程序放在“/usr/local/hadoop/myapp”目录下。因为我的没有这个目录,所以我创了一个。

然后在Eclipse工作界面左侧的“Package Explorer”面板中,在工程名称“WordCount”上点击鼠标右键,在弹出的菜单中选择“Export”,如下图所示。
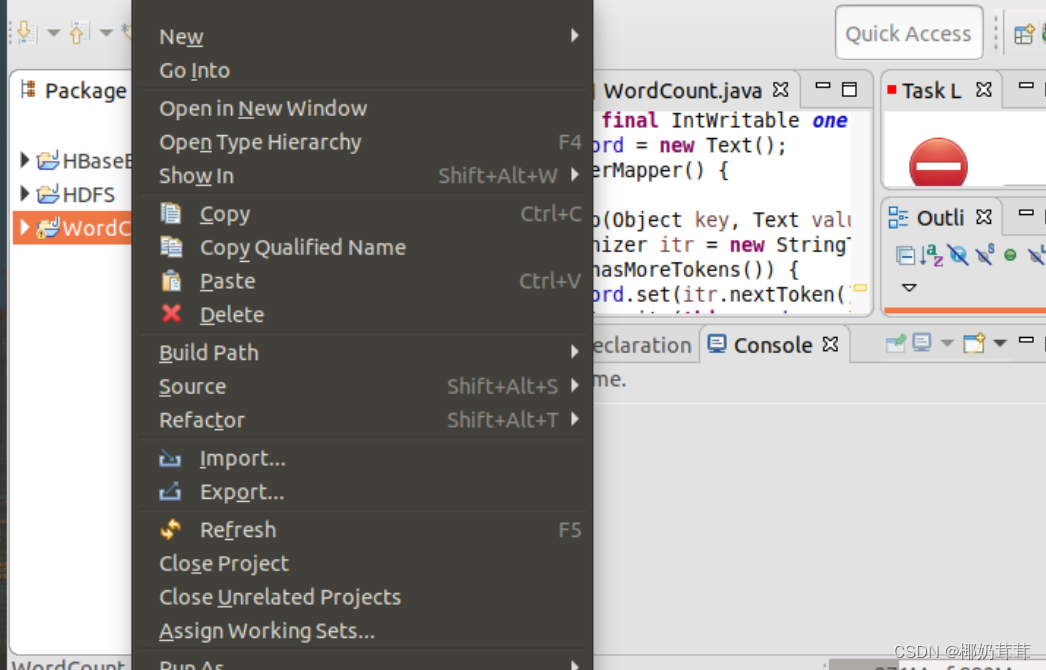
然后,会弹出如下图所示界面。
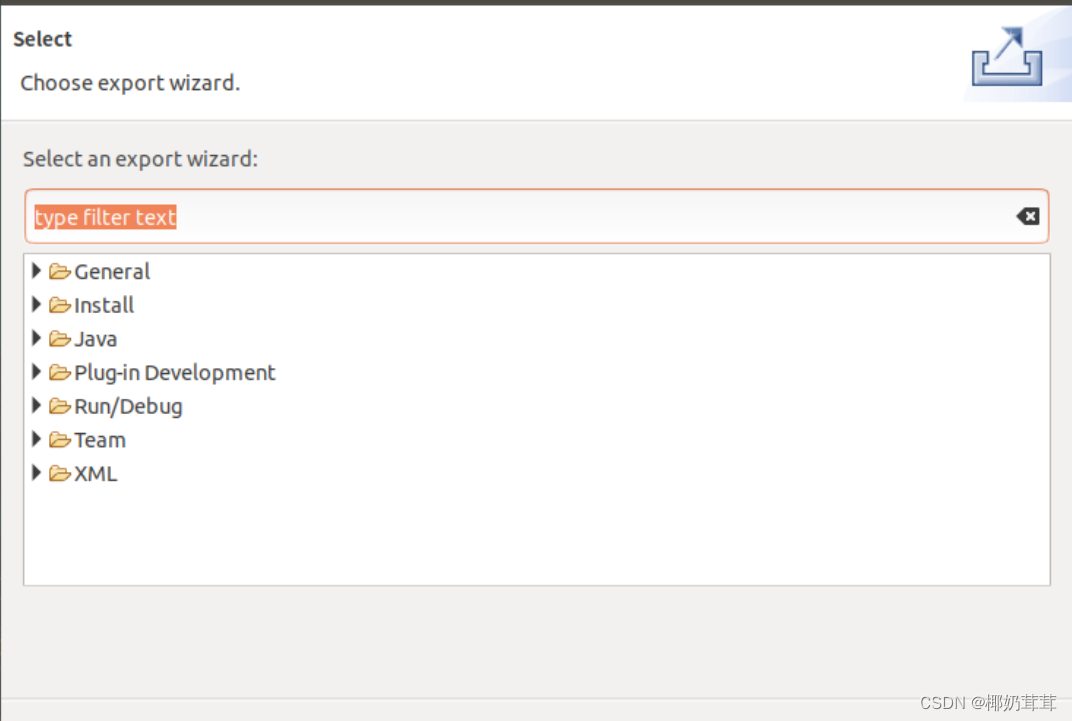
在该界面中,选择“Runnable JAR file”。
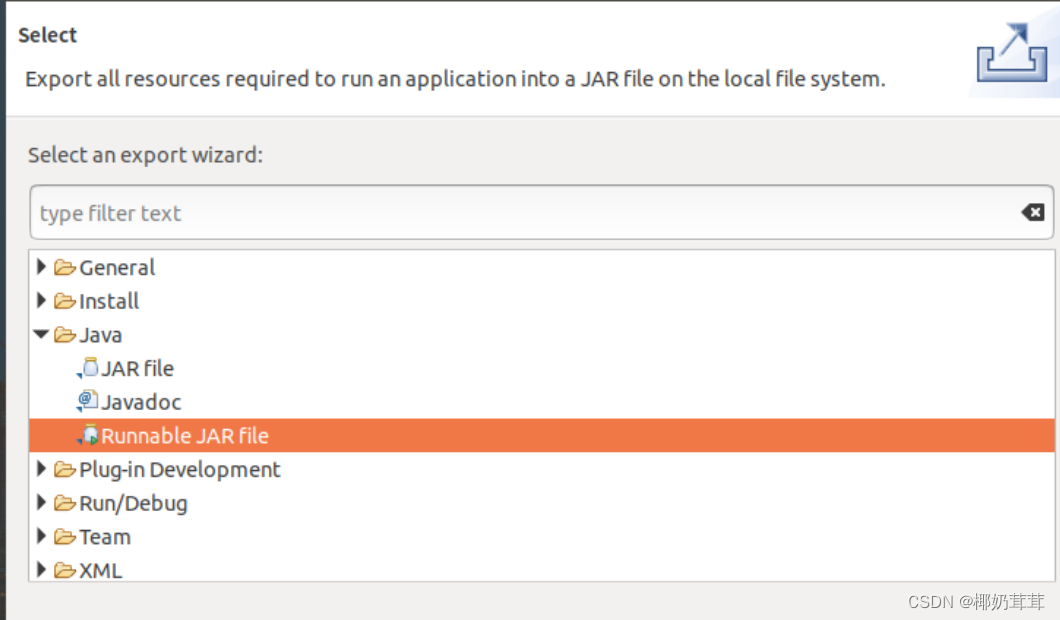
然后,点击“Next>”按钮,弹出如下图所示界面。
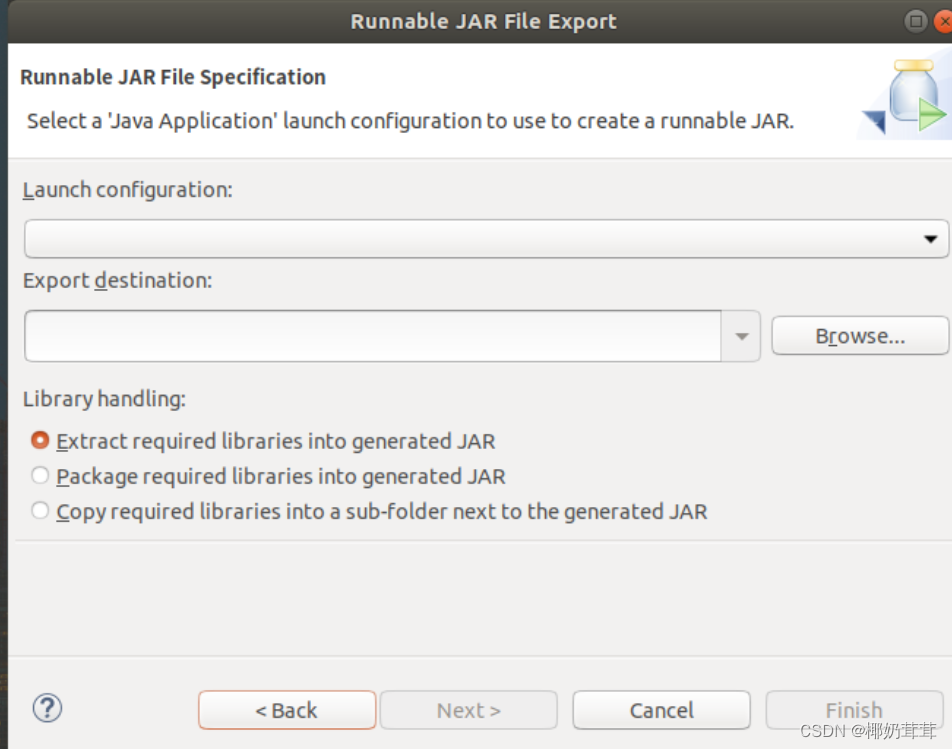
在该界面中,“Launch configuration”用于设置生成的JAR包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类“WordCount-WordCount”。在“Export destination”中需要设置JAR包要输出保存到哪个目录,比如,这里设置为“/usr/local/hadoop/myapp/WordCount.jar”。在“Library handling”下面选择“Extract required libraries into generated JAR”。

然后,点击“Finish”按钮。
会出现一个警告信息界面,不管它直接点OK,然后又会有一个警告信息界面,还是同样不管它,直接点OK。至此,已经顺利把WordCount工程打包生成了WordCount.jar。可以到Linux系统中查看一下生成的WordCount.jar文件,可以在Linux的终端中执行如下命令:

可以看到,“/usr/local/hadoop/myapp”目录下已经存在一个WordCount.jar文件。
6.运行程序
在运行程序之前,需要启动Hadoop。

在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户hadoop对应的input和output目录(即HDFS中的“/user/hadoop/input”和“/user/hadoop/output”目录)


再在HDFS中新建与当前Linux用户hadoop对应的input目录,即“/user/hadoop/input”目录。

然后,把之前在Linux本地文件系统中新建的两个文件wordfile1.txt和wordfile2.txt,上传到HDFS中的“/user/hadoop/input”目录下。
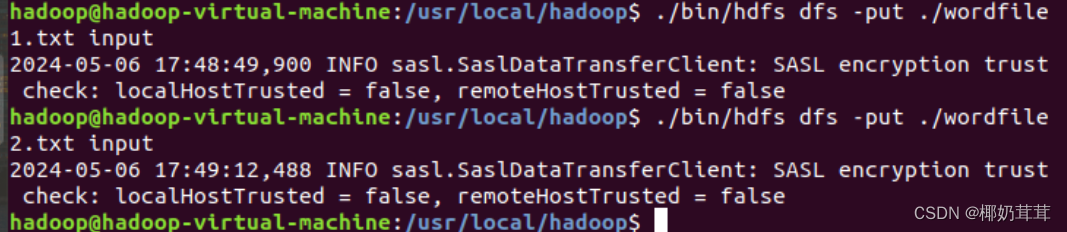
然后就可以在Linux系统中,使用hadoop jar命令运行程序,如下:

上面命令执行以后,当运行顺利结束时,屏幕上会显示类似如下的信息:
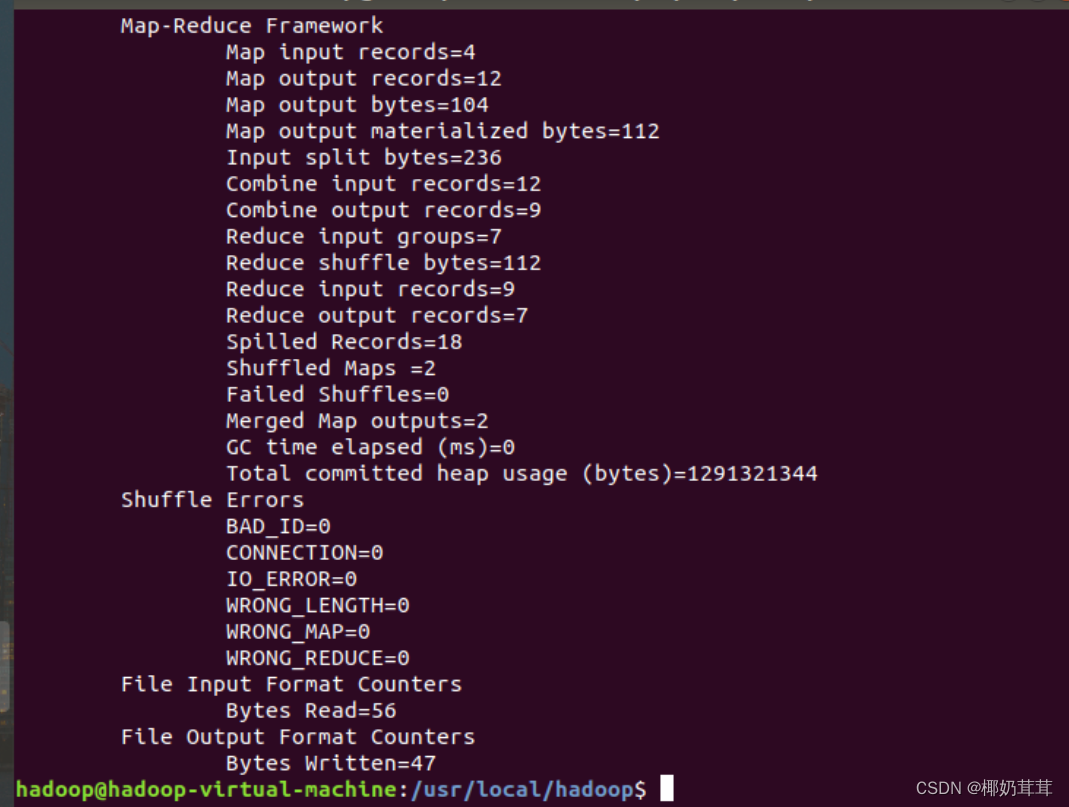
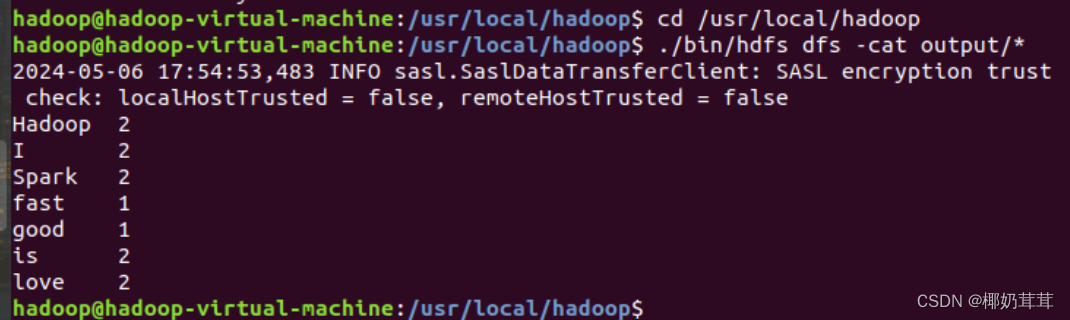
词频统计结果已经被写入了HDFS的“/user/hadoop/output”目录中,可以执行如下命令查看词频统计结果:

上面命令执行后,会在屏幕上显示如下词频统计结果:
四、出现的问题及解决方案
1. 使用如下代码删不了Hadoop里的input

所以后面新建input的时候也出问题了,如下:

后面我就直接改成如下命令就行了:



- 把wordfile1.txt和wordfile2.txt上传到HDFS中的“/user/hadoop/input”目录下时出现不存在文件这个问题,后面才发现之前创建时不在Hadoop下创的。
![]()
![]()
后面重新在Hadoop里面创建,并加上了之前的内容,就可以了。
五、实验总结
1.环境搭建与配置:在开始实践之前,我首先学习了如何搭建Hadoop 3.1.3的集群环境,包括配置文件、启动服务等步骤。这一过程中,我掌握了Hadoop集群的基本架构和组件,为后续编程实践奠定了基础。
2.WordCount实践:我实现了经典的WordCount程序,该程序通过MapReduce模型统计文本中每个单词出现的次数。
3.调试与错误处理:在编程过程中,我遇到了各种错误和异常。通过调试和分析错误日志,我学会了如何定位和解决这些问题。这些经验不仅提高了我的编程能力,也增强了我解决问题的能力。
4.扩展性与灵活性:Hadoop 3.1.3提供了丰富的API和配置选项,使得MapReduce程序具有很高的扩展性和灵活性。
综上所述,基于Hadoop 3.1.3的MapReduce编程实践让我深入理解了MapReduce模型的基本原理和编程模式,并掌握了在分布式环境中处理大规模数据的技能。这次实践不仅提高了我的编程能力,也为我未来的学习和工作提供了宝贵的经验。

