
- 1git push 提交后撤回--图文详解_如何撤销 git reset --hard后 git push -f不会回退合并的吗
- 2GitLab: 使用用户名/密码创建Access Token的示例脚本_add gitlab account token
- 3python测试开发django-176.数据库迁移数据(manage.py dumpdata)_python manage.py dumpdata
- 4实验01:静态路由配置实验_静态配置实验
- 5应用领域宽泛 大数据浪潮席卷全球广泛应用于各行各业_大数据应用越来越广泛
- 6用lambda表达式创建文件过滤器_lamda创建文件过滤器
- 7咪咕视频m3u8地址二次解析 最新ddCalcu算法(5.10号)_咪咕 m3u
- 8常见的二十种软件测试方法详解(史上最全)
- 9求数学系或计算机系姓张的学生的信息,实验二数据库的简单查询和连接查询.docx...
- 10Springboot项目中定时任务的四种实现方式_spring boot 定时任务
【文献翻译-部分】用自监督学习揭示临床脑电信号的结构(SSL与RP原理 / 数据/ 预处理)_uncovering the structure of clinical eeg signals w
赞
踩
《Uncovering the structure of clinical EEG signals with
self-supervised learning》原文地址
截取第一和第二部分(仅作RP方法)的翻译
摘要
目标:监督学习范式通常受到可用标记数据量的限制。这种现象在临床相关数据中尤其存在问题,例如脑电图(EEG),在EEG中,标记可能会在专业知识和人类处理时间方面代价高昂。因此,设计用于学习EEG数据的深度学习体系结构产生了相对浅的模型,其性能充其量与传统的基于特征的方法类似。然而,在大多数情况下,大量未标记的数据可用。通过从这些未标记的数据中提取信息,尽管对标签的访问有限,但通过深度神经网络可能达到具有竞争力的性能。
方法:我们研究了自监督学习(SSL),这是一种在未标记数据中发现结构的有前途的技术,用于学习EEG信号的表示。具体来说,我们探索了两个基于时间上下文预测的任务,以及两个临床相关问题的对比预测编码:基于EEG的睡眠分期和病理检测。我们在两个拥有数千条记录的大型公共数据集上进行了实验,并与纯监督和手工设计的方法进行了基线比较。
主要结果:基于SSL学习特征训练的线性分类器在低标记数据状态下始终优于纯监督深度神经网络,同时在所有标记可用时达到竞争性能。此外,通过每种方法学习的嵌入(embeddings)揭示了与生理和临床现象(如年龄效应)相关的清晰潜在结构。
意义:我们展示了自我监督学习方法对脑电数据的好处。我们的研究结果表明,SSL可能为在脑电数据上更广泛地使用深度学习模型铺平道路。
关键词:自监督学习、表征学习、机器学习、脑电图、睡眠分期、病理检测、临床神经科学
1 介绍
脑电图(EEG)和其他生物信号模式已经在临床领域内外实现了许多应用,例如,研究睡眠模式及其干扰[1], 监测癫痫发作[2]和脑-机接口[3]。在过去几年中,这些设备的可用性和便携性显著增加,有效地实现了使用的民主化,并释放了对人们生活产生积极影响的潜力[4,5]。例如,家庭睡眠分期和呼吸暂停检测、病理性脑电图检测、精神负荷监测等应用现在完全可以实现。
在所有这些情况下,监测模式会产生越来越多需要解释的数据。因此,需要能够分类、检测并最终“理解”生理数据的预测模型。传统上,这种类型的建模主要依赖于监督方法,在监督方法中,需要大量带注释的示例数据集来训练具有高性能的模型。
然而,在生理数据上获得准确的标注可能是昂贵的、耗时的或根本不可能的。例如,注释睡眠记录需要经过培训的技术人员以视觉方式查看数小时的数据,并逐个标记30秒的窗口[6]。临床记录,如用于诊断癫痫或脑损伤的记录,必须由神经科医生审查,他们可能并不总是可用的。更广泛地说,数据中的噪声和感兴趣的大脑过程的复杂性会使解释和注释EEG信号变得困难,这会导致评分者之间的高度可变性,即标签噪声[7,8]。此外,在某些情况下,准确了解参与者在认知神经科学实验中的想法或行为可能是一项挑战,这使得很难获得准确的标签。例如,在想象任务中,受试者可能没有遵循指示,或者研究过程可能难以客观量化(例如冥想、情绪)。因此,一种不主要依赖于监督学习的新范式对于利用大型未标注的记录集(如上述场景中生成的记录集)是必要的。然而,传统的无监督学习方法(如聚类和潜在因素模型)并不能提供完全令人满意的答案,因为它们的性能不像有监督的方法那样易于量化和解释。
“自监督学习”(SSL)是一种无监督学习方法,它从未标记的数据中学习表示,利用数据的结构提供监督[9]。通过将无监督学习问题重新定义为有监督学习问题,SSL允许使用标准的、更好理解的优化过程。SSL包括“辅助”和“下游”任务。下游任务是用户实际感兴趣的任务,但其标注有限或没有标注。另一方面,辅助任务必须与下游任务充分相关,以便使用类似的表示来执行;重要的是,必须能够单独使用未标记的数据为这个辅助任务生成标注。
例如,在计算机视觉场景中,可以使用拼图任务,从图像中提取补丁,随机置乱,然后输入神经网络,神经网络经过训练以恢复补丁的原始空间顺序[10]。如果网络能够很好地完成这项任务,那么可以想象,它已经学习了自然图像的一些结构,并且经过训练的网络可以在较小规模的有监督学习问题(如目标识别)上重新用作特征提取或权重初始化。
除了促进下游任务和/或减少必要的标注示例的数量外,自监督还可以发现比在专门监督任务中学习到的更普遍、更稳健的特征[11]。因此,考虑到SSL的潜在好处,它可以用于增强EEG的分析吗?
到目前为止,SSL的大多数应用都集中在已有大量标注数据的领域,如计算机视觉[9]和自然语言处理[12,13]。特别是在计算机视觉中,深度网络通常是通过完全监督的任务(例如,ImageNet预训练)来训练的。在这种情况下,有足够的标记数据可用,这样下游任务的直接监督学习本身就已经具有竞争力[14]。SSL在低标记数据模式普遍且监督学习的有效性有限的领域,例如生物信号和EEG处理,具有更大的潜力。尽管如此,很少有关于SSL和生物信号的研究发表。这些研究要么专注于有限的下游任务和数据集[15],要么在EEG以外的信号上测试他们的方法[16]
因此,自监督是否能真正改善EEG的标准监督方法还有待证明,如果是这样,应用它的最佳方式是什么。具体来说,我们能否通过自监督学习EEG的通用表示,并在这样做时减少对昂贵EEG标注的需求?鉴于深度学习作为EEG处理工具的日益普及[17],答案可能会对EEG处理领域的当前实践产生重大影响。事实上,尽管深度学习以数据饥渴著称,但所有神经科学研究中绝大部分都发生在低标记数据领域,包括脑电图研究:数百名受试者的临床研究通常被认为是大数据,而大规模研究则更为罕见,通常来源于研究联盟[18,19,20,21]。因此,可以预期的是,大多数深度学习脑电图研究(通常在低标记数据状态下)报告的性能到目前为止仍然有限,并且没有明显优于传统方法[17]。通过利用未标记的数据,SSL可以有效地创建更多的示例,从而使深度学习能够更成功地应用于EEG。
在本文中,我们研究了自监督作为从脑电数据学习表征的一般方法的使用。据我们所知,我们首次详细分析了多种类型脑电图记录的SSL任务。我们的目标是回答以下问题:
- 捕捉脑电数据中相关结构的好SSL任务是什么?
- 在下游分类性能方面,SSL特性与其他无监督和有监督的方法相比如何?
- SSL学习到的特性有哪些特点?具体来说,SSL能否从未标记的脑电图中捕捉生理和临床相关的结构?
论文的其余部分结构如下。第2节概述了SSL文献,然后描述了我们研究中考虑的不同SSL任务和学习问题。我们还介绍了我们实验中使用的神经结构、基线方法和数据。接下来,第3节将报告我们在脑电图上的实验结果。最后,我们将在第4节中讨论结果。
2 方法
2.1 最先进的自监督学习方法
虽然人们并不总是这么认为,但SSL已经在许多其他领域得到了应用。在计算机视觉中,有多种方法被提出,它们依赖于图像的空间结构和视频的时间结构。例如,在[22]中,上下文预测任务用于通过预测随机采样的图像patch相对于第二个patch的位置,对未标记图像上的特征提取器进行训练。使用这种方法对神经网络进行预训练,作者报告了在Pascal VOC目标检测挑战上,与纯监督模型相比,性能有所提高。这些结果首次表明,当有限的标注数据可用时,自监督的预训练有助于提高绩效。类似地,上面提到的拼图任务[10]提高了同一数据集的下游性能。在视频处理领域,也提出了基于时间结构的方法:例如,在[23]中,预测视频帧序列是有序的还是无序的被用作辅助任务,并在人类活动识别下游任务中进行测试。感兴趣的读者可以在[9]中找到SSL对图像的其他应用。
类似地,现代自然语言处理(NLP)任务通常依靠自监督来学习单词嵌入,这是许多应用的核心[24]。例如,最初的word2vec模型经过训练,可以预测中心词周围的词或基于周围的词预测中心词[12],然后在各种下游任务中重复使用[25]。最近,一种双任务自监督方法BERT在11项NLP任务(如问答和命名实体识别)上取得了最先进的性能[13]。这种方法实现的高性能展示了SSL在学习通用表示方面的潜力。
最近,更普遍的辅助任务以及改进的方法已经产生了强有力的结果,这些结果已经开始与纯粹的监督方法相抗衡。例如,对比预测编码(CPC)是一种潜在空间中的自回归预测任务,已成功用于图像、文本和语音[11]。给定一个编码器和一个自回归模型,任务包括在给定多个窗口的上下文中预测未来窗口(或图像补丁或单词)的编码器输出。作者在各种下游任务上给出了一些改进的结果;后续研究进一步表明,更高容量的网络可以进一步改善下游性能,尤其是在低标记数据区域[26]。动量对比(MoCo)不是提出一个新的辅助任务,而是对对比任务的改进,即分类器必须预测两个或更多输入中的哪个是真实样本[27,28]。通过改进对比任务中负样本的抽样,MoCo帮助提高了SSL培训的效率以及所学表征的质量。类似地,在[29]中发现,使用正确的数据增强变换(例如,图像上的随机裁剪和颜色失真)和增加批量可以显著改善下游性能。
经过SSL训练的特性能够明显地推广到下游任务,因此有必要仔细研究它们的统计结构。Hyvärinen等人[30,31]最近从非线性独立分量分析的角度正式确定了一种普遍的、理论上有根据的方法。在这个广义框架中,使用可逆神经网络嵌入观测x,并与辅助变量u(例如,时间指数、segment指数或数据历史)进行对比。鉴别器通过学习预测x是与其对应的辅助变量u配对,还是与扰动(随机)变量u配对,来对x对进行分类。当数据显示出某种结构(例如,自相关、非平稳性、非高斯性)时,在对比任务中训练的嵌入者将执行可识别的非线性ICA[31]。以前引入的大多数SSL任务都可以通过该框架查看。鉴于线性独立分量分析作为预处理和特征提取工具在脑电领域的广泛应用[32,33,34,35],对非线性领域的扩展是一个自然的进步,可能有助于改进传统的处理pipeline。
值得注意的是,很少有研究将SSL应用于生物信号,尽管它有可能利用大量未标记数据。在[15]中,受word2vec启发开发了一个名为wave2vec的模型,用于处理EEG和心电图(ECG)时间序列。通过从EEG信号的时频表示和人口统计信息的串联预测相邻窗口的特征来学习表示。然而,该方法仅在单个EEG数据集上进行了测试,没有与完全监督的深度学习方法或专家特征分类进行基准测试。SSL还被应用于ECG,作为学习下游情绪识别任务特征的一种方法:在[16]中,使用了一个转换识别辅助任务,模型必须预测哪些转换应用于原始信号。虽然这些结果显示了生物信号自我监督学习的潜力,但需要对针对EEG的SSL进行更广泛的分析,为实际应用铺平道路。
2.2 脑电图的自监督学习辅助任务
在本节中,我们将介绍本文中使用的三个SSL辅助任务。任务的视觉解释如图1所示。

2.2.1 相关定位(Relative Positioning)
为了从多变量时间序列 S S S中产生带标签的样本,我们建议对时间窗口 ( x t , x t ′ ) (x_t,x_{t^{'}}) (xt,xt′)进行采样,其中每个窗口 x t x_t xt, x t ′ x_{t^{'}} xt′以 R C × T R^{C×T} RC×T表示, T T T是每个窗口的持续时间,其中索引 t t t表示窗口以 S S S开始的时间样本。第一个窗口 x t x_t xt被称为“锚定窗口(anchor window)”。我们的假设是,数据的适当表示应随时间缓慢演变(类似于慢特征分析(SFA)[36,37]背后的驱动假设),这表明时间窗口在时间上关闭时应具有相同的标签。
例如,在睡眠阶段,通常持续1到40分钟[38];因此,附近的窗口可能来自同一个睡眠阶段,而远处的窗口可能来自不同的睡眠阶段。
给定
τ
p
o
s
τ_{pos}
τpos∈
N
N
N、 它控制正上下文的持续时间,以及
τ
n
e
g
τ_{neg}
τneg∈
N
N
N,对应于每个窗口周围的负上下文,我们采样n个标记对:
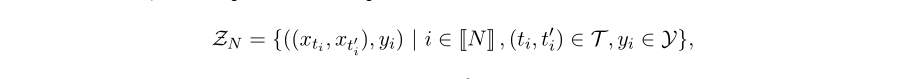
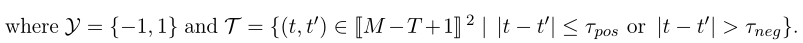
直观地说,是所有时间指数对
(
t
,
t
′
)
(t,t^{'})
(t,t′)的集合,可以从大小为
M
M
M的时间序列中的大小为
T
T
T的窗口构造,给定由
τ
p
o
s
τ_{pos}
τpos和
τ
n
e
g
τ_{neg}
τneg的特定选择施加的持续时间约束。这里
y
i
∈
Y
y_i∈ Y
yi∈Y由正或负上下文参数指定:
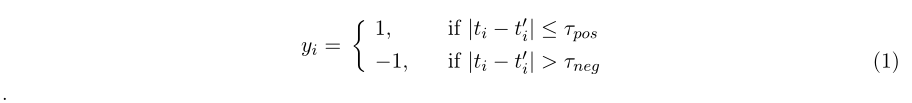

图1 | 本研究中使用的三个SSL辅助任务的视觉解释。第一列说明了在每个辅助任务中获取样本的抽样过程。第二列描述了训练过程,其中使用样本对特征提取器
h
Θ
h_Θ
hΘ进行端到端训练。
我们忽略 x t ′ x_{t^{'}} xt′不在锚定窗口 x t x_t xt的正负上下文中的窗口对。换句话说,标签表明两个时间窗口在时间上是比 τ p o s τ_{pos} τpos更近还是比 τ n e g τ_{neg} τneg更远。注意到与[22]中任务的联系,我们将此辅助任务称为“相对定位”(RP)。
为了学习端到端如何根据时间窗口对的相对位置来区分它们,我们引入了两个函数 h Θ h_Θ hΘ和gRP。 h Θ : R C × T → R D hΘ:R^{C×T}→ R^D hΘ:RC×T→RD是一个具有参数Θ的特征提取器,它将窗口 x x x映射到其在特征空间中的表示。最终,我们期望 h Θ h_Θ hΘ学习原始脑电输入的信息表示,这些信息可以在不同的下游任务中重用。然后使用对比模块 g R P g_{RP} gRP来聚合每个窗口的特征表示。对于RP任务, g R P : R D × R D → R D g_{RP}:R^D×R^D→ R^D gRP:RD×RD→RD通过计算元素级绝对差来组合来自成对窗口的表示,由|·|运算符表示:
g R P ( h Θ ( x ) , h Θ ( x ′ ) ) = ∣ h Θ ( x ) − h Θ ( x ′ ) ∣ ∈ R D g_{RP}(h_Θ(x),h_Θ(x^{'}))=|hΘ(x)− hΘ(x^{'})|∈ R^D gRP(hΘ(x),hΘ(x′))=∣hΘ(x)−hΘ(x′)∣∈RD。
g
R
P
g_{RP}
gRP的作用是聚合
h
Θ
h_Θ
hΘ在两个输入窗口上提取的特征向量,并突出它们的差异,以简化对比任务。最后,给出了一个系数为
w
w
w的线性上下文判别模型
w
w
w∈
R
D
R_{D}
RD和偏差项
w
0
∈
R
w_0∈ R
w0∈R负责预测相关目标
y
y
y。利用
g
R
P
g_{RP}
gRP预测的二元逻辑损失,我们可以将联合损失函数
L
(
Θ
,
w
,
w
0
)
L(Θ,w,w_0)
L(Θ,w,w0)写成
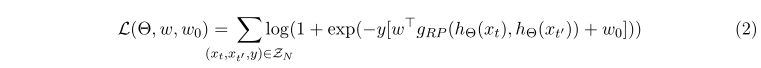
我们假设它对于参数
(
Θ
,
w
,
w
0
)
(Θ,w,w_0)
(Θ,w,w0)是完全可微的。根据
y
y
y的约定,预测目标是
w
T
g
(
h
Θ
(
x
t
)
,
h
Θ
(
x
t
′
)
)
+
w
0
w^Tg(h_Θ(x_t),h_Θ(x_t^{'}))+w_0
wTg(hΘ(xt),hΘ(xt′))+w0的符号。
2.3 下游任务
我们对基于机器学习的脑电图分析中代表当前挑战的两个临床问题:睡眠监测和病理筛查,进行了基于脑电图的经验基准测试。这两个临床问题通常会导致分类任务,尽管分类数量不同,数据生成机制也不同:睡眠监测与生物事件(事件级别)有关,而病理筛查与人群(受试者级别)相比与单个患者有关。这两个临床问题在研究界引起了相当大的关注,这导致了大型公共数据库的管理。为了与有监督的方法进行公平比较,我们对2018年生理网挑战[1,39]和TUH异常脑电图[40]数据集的SSL进行了基准测试 。
首先,我们考虑了睡眠分期,它是典型睡眠监测评估的关键组成部分,是诊断和研究睡眠障碍(如呼吸暂停和嗜睡症)的关键[41]。机器(和深度)学习文献[42,43,17]对睡眠分期进行了广泛的研究(约占[17]综述论文的10%),尽管没有从SSL的角度进行研究。实现完全自动化的睡眠分期可能会对临床实践产生重大影响,因为
- 人类评分员之间的一致性通常有限[7],
- 注释过程耗时且仍主要是手动的[6]。
睡眠分期通常会导致5级分类问题,其中可能的预测是W(唤醒)、N1、N2、N3(不同睡眠水平)和R(快速眼动周期)。在这里,这项任务包括预测对应于30秒EEG窗口的睡眠阶段。
其次,我们将SSL应用于病理检测:EEG在临床环境中常规用于筛查癫痫和痴呆等神经疾病的个体[44,45]。然而,成功的病理检测需要高度专业化的医学专业知识,其质量取决于专家的培训和经验。因此,自动病理检测可以通过促进神经系统筛查对临床实践产生重大影响。这就产生了学科层面的分类任务,其中的挑战是从脑电图记录中推断患者的诊断或健康状况。在TUH数据集中,医学专家将记录标记为病理性或非病理性,由此产生了二元分类问题。重要的是,这两个标签反映了高度异质性的情况:病理记录可能反映由于各种医疗条件引起的异常,这表明一个相当复杂的数据生成机制。同样,各种受监督的方法,其中一些利用了深层架构,在文献[46,47,48]中解决了这一任务,尽管没有一种方法依赖于自我监督。
在讨论我们实验中使用的数据时,第2.6节将进一步描述这两项任务。
2.4 深度学习架构
在我们的实验中,我们使用了两种不同的深度学习体系结构作为嵌入器 h Θ h_Θ hΘ(详细描述请参见图2)。这两种结构都是由空间和时间卷积层组成的卷积神经网络,分别学习执行EEG处理管道典型的空间和时间滤波操作。
第一个,我们称之为StagerNet,是根据之前关于睡眠分期的工作改编而来的,在睡眠分期的窗口分类中,它表现得很好[42]。StagerNet是一个三层卷积神经网络,优化用于处理30秒的多通道EEG窗口。与最初的架构相反,
- 我们使用了两倍多的卷积通道(16而不是8)
- 我们在两个时间卷积层之后添加了批量规范化
- 我们没有填充时间卷积
- 我们将输出层的维数改为D=100,而不是类数(见图2-1)。
这产生了总共62307个可训练参数。
第二种,嵌入式架构ShallowNet直接取自之前关于TUH异常数据集的文献[47,48]。ShallowNet最初设计为脑-机接口中常见的滤波器组公共空间模式(FBCSP)处理管道的参数化版本,它有一个单一(分割)卷积层,然后是平方非线性、平均池、对数非线性和线性输出层。在时间卷积层之后使用批标准化。尽管简单,但在[48]中显示,该体系结构在TUH异常数据集的病理检测任务中的表现几乎与最佳模型一样好。因此,我们按原样使用它,除了输出层的维度,我们也将其更改为D=100(见图2-2)。这产生了总共170860个可训练参数。
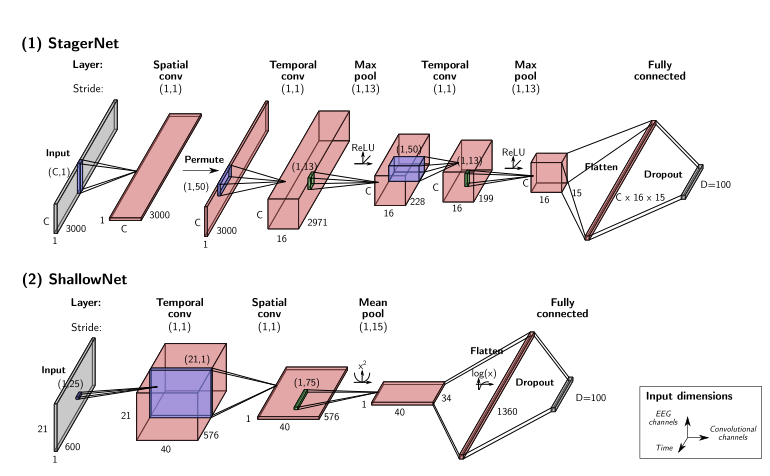
图2 | 神经网络结构用作(1)睡眠脑电图和(2)病理检测实验的嵌入器
h
Θ
h_Θ
hΘ。
对于CPC任务的 g A R g_{AR} gAR,我们使用了一个隐藏层大小为 D A R = 100 D_{AR}=100 DAR=100的GRU,用于两个数据集上的实验。
Adam优化器[50], β 1 = 0.9 , β 2 = 0.999 β_1=0.9,β_2=0.999 β1=0.9,β2=0.999,学习率为 5 × 1 0 − 4 5×10^{−4} 5×10−4。除CPC设置为32外,所有深度模型的batch大小都设置为256。训练最多持续150个时期,或直到验证损失停止减少至少10个epoch(或CPC的6个epoch)。以50%的速率对全连接层应用dropout,对所有层的可训练参数应用0.001的权重衰减。最后,所有神经网络的参数都是使用uniform He初始化随机初始化的[51]。
2.5 基线(Baseline)
SSL任务与下游任务的四种基线方法进行了比较:(1)随机权重,(2)卷积自动编码器,(3)纯监督学习和(4)手工特征。
随机权重基线使用了一个嵌入器(embedder),其权重在随机初始化后被冻结。自编码器(AE)是一种更基本的表征学习方法,由编码器和解码器组成的神经网络学习输入和输出之间的身份映射,例如,均方误差损失[52]。在这里,我们使用 h Θ h_Θ hΘ作为编码器,并设计了一个卷积解码器来反转 h Θ h_Θ hΘ的操作。纯监督模型直接针对下游分类问题进行训练,即它可以访问标记的数据。为此,我们在嵌入器中添加了一个额外的线性分类层,然后使用多类交叉熵损失对整个模型进行训练。
最后,我们还包括基于手工特征的传统机器学习基线。
对于睡眠分期,我们提取了以下特征[42]:均值、方差、偏度、峰度、标准偏差、频率对数功率带(0.5、4.5、8.5、11.5、15.5、30)Hz之间,以及所有可能的比率、峰峰值、赫斯特指数、近似熵和Hjorth复杂度。这导致每个EEG通道有37个特征,这些特征被连接成一个向量。如果人工伪迹导致窗口特征向量中的缺失值,我们使用在训练集计算的特征平均值以特征方式估算缺失值。
对于病理检测,如[48]中所述,使用了黎曼几何特征,据报道,基于切线空间特征训练的非线性分类器在TUH异常数据集的评估集上达到了高精度。我们没有平均每个记录的协方差矩阵,以便与其他窗口工作的方法进行公平比较。因此,对于脑电的C通道,分类器的输入具有维数 C ( C + 1 ) / 2 C(C+1)/2 C(C+1)/2。
对于下游任务,通过RP、TS、CPC和AE学习的特征使用L2正则化参数C=1的线性逻辑回归进行分类,而手工制作的特征则使用随机森林分类器进行分类,该分类器包含300棵树,最大深度为15棵,每一个树的最大特征数为 F \sqrt F F (其中F是特征数)。平衡准确度(bal acc)定义为每类平均recall,用于评估下游任务的模型性能。此外,在训练期间,损失被加权以解释类别的失衡。使用braindecode[53]、MNE Python[54]、Pytork[55]、pyRiemann[56]和scikit learn[57]软件包对模型进行训练。最后,深度学习模型在1或2个Nvidia Tesla V100 GPU上进行训练,时间从几分钟到7小时不等,具体取决于数据量、提前停止和GPU配置。
2.6 数据
实验在两个公开的EEG数据集上进行,如表1和表2所示。

2.6.1 Physionet Challenge 2018 dataset
首先,我们在Physionet Challenge 2018(PC18)数据集[1,39]上进行了睡眠分期实验。这个数据集最初是在一个开源竞赛的背景下发布的,该竞赛旨在检测睡眠记录中的觉醒,即夜间短暂的清醒时刻。对1983名(疑似)睡眠呼吸暂停患者进行夜间监测,并测量他们的EEG、EOG、下巴EMG、呼吸气流和血氧饱和度。具体而言,国际10/20系统的6个EEG通道在200 Hz下记录:F3-M2、F4-M1、C3-M2、C4-M1、O1-M2和O2-M1。然后,7名经过培训的计分员按照AASM手册[58]将记录的数据注释到睡眠阶段(W、N1、N2、N3和R)。此外,记录中还发现了9种不同类型的觉醒和4种类型的睡眠呼吸暂停事件。由于睡眠阶段标注仅在大约一半的记录(比赛期间用作训练集)上公开,我们将分析重点放在这994张记录上。在这部分数据中,平均年龄为55岁(最低18岁,最高93岁),33%的参与者为女性 。
2.6.2 TUH Abnormal EEG dataset
我们使用了TUH异常脑电图数据集V2.0.0(TUHab)进行病理性脑电图检测实验[40]。该数据集是[19]的一个子集,包含2329名在医院接受临床脑电图检查的不同患者的2993次15分钟或更长时间的记录。根据详细的医生报告,每条记录被标记为“正常”(1385次记录)或“异常”(998次记录)。大多数记录的采样频率为250 Hz(尽管有些记录的采样频率为256或512 Hz),包含27到36个电极。此外,语料库被分为一个训练集和一个评估集,每个训练集和评估集分别有2130次和253次记录。所有记录的平均年龄为49.3岁(最小1岁,最大96岁),53.5%的记录为女性患者。
2.6.3 数据拆分与采样
我们将PC18和TUHab的可用记录分为训练、验证和测试集,以便每个记录中的样本仅在其中一个集中(见表3)。
对于PC18,我们使用了60-20-20%的随机分割,这意味着在训练、验证和测试集中分别有595、199和199次记录。对于RP和TS,从每次记录中抽取2000对或三对窗口。对于CPC,从每个记录中提取的batch数计算为该记录中窗口数的0.05倍;此外,我们将batch大小设置为32。
对于TUHab,我们使用提供的评估集作为测试集。开发集的记录被分成80-20%的训练集和验证集。因此,我们在培训、验证和测试集中使用了2171、543和276次记录。由于TUHab的记录较短,我们随机抽取了400个RP对或TS三胞胎,而不是每个记录中的2000个。我们使用了与PC18相同的CPC采样参数。
2.6.4 数据预处理
这两个数据集的EEG记录预处理不同。
在PC18上,首先使用带有汉明窗的30 Hz FIR低通滤波器对原始EEG进行滤波,以拒绝对睡眠分期不重要的更高频率[42,59]。然后将EEG通道下采样至100Hz,以降低输入数据的维数。出于同样的原因,我们将分析重点放在通道F3-M2和F4-M1上。最后,提取大小为30秒(3000 x 2)的非重叠窗口。
在TUHab上,使用了与[48]中所述类似的程序。对每次记录的第一分钟进行裁剪,以删除录制开始时出现的嘈杂数据。更长的文件也被裁剪,这样每次录音最多使用20分钟。然后,选择了所有录音共有的21个频道(Fp1、Fp2、F7、F8、F3、Fz、F4、A1、T3、C3、Cz、C4、T4、A2、T5、P3、Pz、P4、T6、O1和O2)。将EEG通道下采样至100 Hz,并在±800µV处截断,以减轻原始数据中较大伪偏差的影响。提取非重叠的6-s窗口,得到大小为600×21的窗口。
最后,两个数据集中峰值间振幅低于1µV的窗口均被拒绝。其余窗口按通道进行标准化,平均值和单位标准偏差为零。
3 代码
跑不出来啊!!!!例程地址
# 使用SSL-Relative Positioning对EEG信号进行睡眠分期 # Written By FelicityXu # 20220226 import os import numpy as np import torch from braindecode import EEGClassifier from braindecode.datasets import SleepPhysionet, BaseConcatDataset from braindecode.models import SleepStagerChambon2018 from braindecode.preprocessing import Preprocessor, scale, preprocess, create_windows_from_events from braindecode.samplers import RelativePositioningSampler from braindecode.util import set_random_seeds from sklearn.linear_model import LogisticRegression from sklearn.metrics import balanced_accuracy_score, confusion_matrix, classification_report from sklearn.model_selection import train_test_split from sklearn.pipeline import make_pipeline from sklearn.preprocessing import scale as standard_scale, StandardScaler from skorch.callbacks import Checkpoint, EarlyStopping, EpochScoring from skorch.helper import predefined_split from torch import nn # # import sys # # sys.setrecursionlimit(1000000) from torch.utils.data import DataLoader random_state = 87 n_jobs = 1 ''' 加载SleepPhysionet数据集 ''' # crop_wake_mins:Number of minutes of wake time to keep before # the first sleep event and after the last sleep event. # Used to reduce the imbalance in this dataset. Default of 30 mins. dataset = SleepPhysionet( subject_ids=[0, 1, 2], recording_ids=[1], crop_wake_mins=30) ''' 数据预处理 ''' # 接下来,我们对原始数据进行预处理。 # 我们将数据转换为微伏并应用低通滤波器。由于Sleep Physionet数据已经以 100 Hz 采样,我们不需要应用重新采样。 high_cut_hz = 30 preprocessors = [ Preprocessor(scale, factor=1e6, apply_on_array=True), Preprocessor('filter', l_freq=None, h_freq=high_cut_hz, n_jobs=n_jobs) ] # 数据预处理 preprocess(dataset, preprocessors) ''' 提取窗口 我们提取 30 秒的窗口以用于辅助和下游任务。 由于RP(和一般的 SSL)不需要标记数据,因此可以使用braindecode.datautil.windower.create_fixed_length_window(). 然而,在这里,纯粹为了方便,我们直接提取标记的窗口,以便我们可以在稍后的睡眠分阶段下游任务中重用它们。 ''' window_size_s = 30 sfreq = 100 window_size_samples = window_size_s * sfreq # 窗口有多少个样本点 mapping = { # We merge stages 3 and 4 following AASM standards. 'Sleep stage W': 0, 'Sleep stage 1': 1, 'Sleep stage 2': 2, 'Sleep stage 3': 3, 'Sleep stage 4': 3, 'Sleep stage R': 4, } windows_dataset = create_windows_from_events( dataset, trial_start_offset_samples=0, trial_stop_offset_samples=0, window_size_samples=window_size_samples, window_stride_samples=window_size_samples, preload=True, mapping=mapping ) # 预处理窗口 z-score归一化 preprocess(windows_dataset, [Preprocessor(standard_scale, channel_wise=True)]) ''' 数据拆分为训练集、验证集与测试集 我们将记录按subject随机分成训练集、验证集和测试集。 我们进一步定义了一个新的 Dataset 类,它可以接收一对索引并返回相应的窗口。 在对辅助任务进行训练和评估时,这将是必需的。 ''' subjects = np.unique(windows_dataset.description['subject']) # 去除数组中的重复数字,进行排序之后输出 subj_train, subj_test = train_test_split( subjects, test_size=0.4, random_state=random_state) subj_valid, subj_test = train_test_split( subjects, test_size=0.5, random_state=random_state) class RelativePositioningDataset(BaseConcatDataset): """BaseConcatDataset with __getitem__ that expects 2 indices and a target. """ def __init__(self, list_of_ds): super().__init__(list_of_ds) # 将父类和子类关联起来,调用父类的__init__方法,让实例包含父类的所有属性 self.return_pair = True def __getitem__(self, index): if self.return_pair: ind1, ind2, y = index return(super().__getitem__(ind1)[0], super().__getitem__(ind2)[0]), y else: return super().__getitem__(index) @property # 修饰方法,方法可以像属性一样访问 def return_pair(self): return self.return_pair @return_pair.setter # @*.setter 允许你对已用@property装饰的函数赋值: def return_pair(self, value): self._return_pair = value split_ids = {'train': subj_train, 'valid': subj_valid, 'test': subj_test} splitted = dict() for name, values in split_ids.items(): # name:"train" "valid" "test" splitted[name] = RelativePositioningDataset( [ds for ds in windows_dataset.datasets if ds.description['subject'] in values]) ''' 创建采样器 接下来,我们需要创建采样器。这些采样器将用于随机采样成对的样本,以通过自监督来训练和验证我们的模型。 RP 采样器有两个主要的超参数。tau_pos和tau_neg 分别 控制“正”和“负”上下文的大小。 被小于tau_pos样本分隔的窗口对将被赋予标签1,而被超过 tau_neg样本分隔的窗口对将被赋予标签0。 在这里,我们使用与1中相同的值,即` tau_pos`= 1 分钟和` tau_neg`= 15 分钟。 采样器还控制要采样的对数(使用 n_examples定义)。 这个数字可以很大,以帮助规范辅助任务训练,例如每个记录 2,000 对 在这里,我们每次记录使用较少的 250 对来减少训练时间。 ''' tau_pos, tau_neg = int(sfreq * 60), int(sfreq * 15 * 60) # 正负上下文采样点的大小 n_examples_train = 250 * len(splitted['train'].datasets) n_examples_valid = 250 * len(splitted['valid'].datasets) n_examples_test = 250 * len(splitted['test'].datasets) train_sampler = RelativePositioningSampler( splitted['train'].get_metadata(), tau_pos=tau_pos, tau_neg=tau_neg, n_examples=n_examples_train, same_rec_neg=True, random_state=random_state) valid_sampler = RelativePositioningSampler( splitted['valid'].get_metadata(), tau_pos=tau_pos, tau_neg=tau_neg, n_examples=n_examples_valid, same_rec_neg=True, random_state=random_state).presample() test_sampler = RelativePositioningSampler( splitted['test'].get_metadata(), tau_pos=tau_pos, tau_neg=tau_neg, n_examples=n_examples_test, same_rec_neg=True, random_state=random_state).presample() ''' 创建深度学习模型。 使用4中介绍的睡眠分级架构的修改版本——一个四层卷积神经网络——作为我们的嵌入器。 我们改变最后一层的维度以获得 100 维嵌入,使用 16 个卷积通道而不是 8 个,并在两个时间卷积层之后添加批量归一化。 我们使用下面定义的 # ContrastiveNet类进一步将模型包装成连体架构。这使我们能够端到端地训练特征提取器。 ''' # device = 'cuda' if torch.cuda.is_available() else 'cpu' device = 'cpu' # if device == 'cuda': # torch.backends.cudnn.benchmark = True set_random_seeds(seed=random_state, cuda=device == 'cuda') # Extract number of channels and time steps from dataset n_channels, input_size_samples = windows_dataset[0][0].shape emb_size = 100 # 来自 Chambon 等人 2018 的睡眠分期架构。 emb = SleepStagerChambon2018( n_channels, sfreq, n_classes=emb_size, n_conv_chs=16, input_size_s=input_size_samples / sfreq, dropout=0, apply_batch_norm=True ) class ContrastiveNet(nn.Module): """Contrastive module with linear layer on top of siamese embedder. Parameters ---------- emb : nn.Module Embedder architecture. emb_size : int Output size of the embedder. dropout : float Dropout rate applied to the linear layer of the contrastive module. """ def __init__(self, emb, emb_size, dropout=0.5): super().__init__() self.emb = emb self.clf = nn.Sequential( nn.Dropout(dropout), nn.Linear(emb_size, 1) ) def forward(self, x): x1, x2 = x z1, z2 = self.emb(x1), self.emb(x2) return self.clf(torch.abs(z1 - z2)).flatten() model = ContrastiveNet(emb, emb_size).to(device) ''' 训练 我们现在可以在辅助任务上训练我们的网络。 我们使用与1中类似的超参数,但减少了 epoch 的数量并提高了学习率,以解决此样本的较小设置。 ''' lr = 5e-3 batch_size = 512 n_epochs = 25 num_workers = 0 if n_jobs <= 1 else n_jobs cp = Checkpoint(dirname='', f_criterion=None, f_optimizer=None, f_history=None) early_stopping = EarlyStopping(patience=10) train_acc = EpochScoring( scoring='accuracy', on_train=True, name='train_acc', lower_is_better=False) valid_acc = EpochScoring( scoring='accuracy', on_train=False, name='valid_acc', lower_is_better=False) callbacks = [ ('cp', cp), ('patience', early_stopping), ('train_acc', train_acc), ('valid_acc', valid_acc) ] clf = EEGClassifier( model, criterion=torch.nn.BCEWithLogitsLoss, optimizer=torch.optim.Adam, max_epochs=n_epochs, iterator_train__shuffle=False, iterator_train__sampler=train_sampler, iterator_valid__sampler=valid_sampler, iterator_train__num_workers=num_workers, iterator_valid__num_workers=num_workers, train_split=predefined_split(splitted['valid']), optimizer__lr=lr, batch_size=batch_size, callbacks=callbacks, device=device ) # Model training for a specified number of epochs. `y` is None as it is already # supplied in the dataset. clf.fit(splitted['train'], y=None) clf.load_params(checkpoint=cp) # Load the model with the lowest valid_loss os.remove('./params.pt') # Delete parameters file ''' 使用学习的表示进行睡眠分期 我们现在可以使用经过训练的卷积神经网络作为特征提取器。 我们使用线性逻辑回归分类器从学习的特征表示中执行睡眠阶段分类。 ''' # Extract features with the trained embedder data = dict() for name, split in splitted.items(): split.return_pair = False # Return single windows loader = DataLoader(split, batch_size=batch_size, num_workers=num_workers) with torch.no_grad(): feats = [emb(batch_x.to(device)).cpu().numpy() for batch_x, _, _ in loader] data[name] = (np.concatenate(feats), split.get_metadata()['target'].values) # Initialize the logistic regression model log_reg = LogisticRegression( penalty='l2', C=1.0, class_weight='balanced', solver='lbfgs', multi_class='multinomial', random_state=random_state) clf_pipe = make_pipeline(StandardScaler(), log_reg) # Fit and score the logistic regression clf_pipe.fit(*data['train']) train_y_pred = clf_pipe.predict(data['train'][0]) valid_y_pred = clf_pipe.predict(data['valid'][0]) test_y_pred = clf_pipe.predict(data['test'][0]) train_bal_acc = balanced_accuracy_score(data['train'][1], train_y_pred) valid_bal_acc = balanced_accuracy_score(data['valid'][1], valid_y_pred) test_bal_acc = balanced_accuracy_score(data['test'][1], test_y_pred) print('Sleep staging performance with logistic regression:') print(f'Train bal acc: {train_bal_acc:0.4f}') print(f'Valid bal acc: {valid_bal_acc:0.4f}') print(f'Test bal acc: {test_bal_acc:0.4f}') print('Results on test set:') print(confusion_matrix(data['test'][1], test_y_pred)) print(classification_report(data['test'][1], test_y_pred))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308

