
- 1剪报浏览器:可以自己设计网页的浏览器
- 2【FFmpeg】SDL 音视频开发 ① ( SDL 窗口绘制 | SDL 视频显示函数 | SDL_Window 窗口 | SDL_Renderer 渲染器 | SDL_Texture 纹理 )
- 3AI绘画SD秒去水印,移除不想要的内容!建议收藏!_sd-webui-cleaner
- 4使用Python进行音视频剪辑:半自动追踪人脸并添加马赛克_python自动剪辑
- 5微信小程序:最新微信登录授权并获取openid等信息_微信开发工具最新唤起授权
- 6AI-知识库搭建(一)腾讯云向量数据库使用
- 72020年中国互联网数据中心行业现状及发展趋势分析
- 8Android选择题界面的设计——线性布局实操
- 9加密算法学习_加密算法中的start函数
- 10WorkTool无障碍服务实现企业微信机器人接口
redis 与 db 双写数据一致性解决方案_db+redis同时双写的一致性
赞
踩
本文的行文次序,首先介绍集中式缓存的缓存模式和数据一致性,然后介绍 二级缓存的架构和数据一致性,最后介绍 三级缓存的架构和数据一致性
指南2:
不吹牛,本文在全网数据一致性的所有博文中,绝对算是史上最全的。
本文最为全面的介绍了 redis 与 db 双写数据一致性解决方案,
当然, 会参考了最新的一些文章, 但是解决那些 复制来复制去的bug,
另外,本文增加了 L2 、L3 多级缓存的一致性问题
总之
本文非常经典,绝对的高分面试必备, 建议边学习、边思考,并且一定要实战
- 如果有问题,欢迎来疯狂创客圈找尼恩和18罗汉门一起交流
- 本文后续也会不断升级迭代,持续保持史上最全位置。
预备知识: 谈谈一致性

一致性就是数据保持一致,在分布式系统中,可以理解为多个节点中数据的值是一致的。
- 强一致性:这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往对系统的性能影响大
- 弱一致性:这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态
- 最终一致性:最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型
集中式redis缓存的三个经典的缓存模式
缓存可以提升性能、缓解数据库压力,但是使用缓存也会导致数据不一致性的问题。一般我们是如何使用缓存呢?有三种经典的缓存模式:
- Cache-Aside Pattern
- Read-Through/Write through
- Write behind
Cache-Aside Pattern
Cache-Aside Pattern,即旁路缓存模式,它的提出是为了尽可能地解决缓存与数据库的数据不一致问题。
Cache-Aside的读流程
Cache-Aside Pattern的读请求流程如下:

读的时候,先读缓存,缓存命中的话,直接返回数据;
缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
Cache-Aside 写流程
Cache-Aside Pattern的写请求流程如下:

更新的时候,先更新数据库,然后再删除缓存。
Read-Through/Write-Through(读写穿透)
Read/Write Through模式中,服务端把缓存作为主要数据存储。应用程序跟数据库缓存交互,都是通过抽象缓存层完成的。
Read-Through读流程
Read-Through的简要读流程如下
从缓存读取数据,读到直接返回
如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
这个简要流程是不是跟Cache-Aside很像呢?
其实Read-Through就是多了一层Cache-Provider,流程如下:

Read-Through的优点
Read-Through实际只是在Cache-Aside之上进行了一层封装,它会让程序代码变得更简洁,同时也减少数据源上的负载。
Write-Through写流程
Write-Through模式下,当发生写请求时,也是由缓存抽象层完成数据源和缓存数据的更新,流程如下:

Write behind (异步缓存写入)
Write behind跟Read-Through/Write-Through有相似的地方,都是由Cache Provider来负责缓存和数据库的读写。它两又有个很大的不同:Read/Write Through是同步更新缓存和数据的,Write Behind则是只更新缓存,不直接更新数据库,通过批量异步的方式来更新数据库。

这种方式下,缓存和数据库的一致性不强,对一致性要求高的系统要谨慎使用。
但是它适合频繁写的场景,MySQL的InnoDB Buffer Pool机制就使用到这种模式。
三种模式的比较
Cache Aside 更新模式实现起来比较简单,但是需要维护两个数据存储:
- 一个是缓存(Cache)
- 一个是数据库(Repository)。
Read/Write Through 的写模式需要维护一个数据存储(缓存),实现起来要复杂一些。
Write Behind Caching 更新模式和Read/Write Through 更新模式类似,区别是Write Behind Caching 更新模式的数据持久化操作是异步的,但是Read/Write Through 更新模式的数据持久化操作是同步的。
Write Behind Caching 的优点是直接操作内存速度快,多次操作可以合并持久化到数据库。缺点是数据可能会丢失,例如系统断电等。
Cache-Aside的问题
更新数据的时候,Cache-Aside是删除缓存呢,还是应该更新缓存?
有些小伙伴可能会问, Cache-Aside在写入请求的时候,为什么是删除缓存而不是更新缓存呢?

我们在操作缓存的时候,到底应该删除缓存还是更新缓存呢?我们先来看个例子:
操作的次序如下:
线程A先发起一个写操作,第一步先更新数据库
线程B再发起一个写操作,第二步更新了数据库
现在,由于网络等原因,线程B先更新了缓存, 线程A更新缓存。
这时候,缓存保存的是A的数据(老数据),数据库保存的是B的数据(新数据),数据不一致了,脏数据出现啦。如果是删除缓存取代更新缓存则不会出现这个脏数据问题。
更新缓存相对于删除缓存,还有两点劣势:
1 如果你写入的缓存值,是经过复杂计算才得到的话。 更新缓存频率高的话,就浪费性能啦。
2 在写多读少的情况下,数据很多时候还没被读取到,又被更新了,这也浪费了性能呢(实际上,写多的场景,用缓存也不是很划算了)
任何的措施,也不是绝对的好, 只有分场景看是不是适合,更新缓存的措施,也是有用的:
在读多写少的场景,价值大。
双写的情况下,先操作数据库还是先操作缓存?
美团二面:Redis与MySQL双写一致性如何保证?
Cache-Aside缓存模式中,有些小伙伴还是有疑问,在写入请求的时候,为什么是先操作数据库呢?为什么不先操作缓存呢?
假设有A、B两个请求,请求A做更新操作,请求B做查询读取操作。
A、B两个请求的操作流程如下:
- 线程A发起一个写操作,第一步del cache
- 此时线程B发起一个读操作,cache miss
- 线程B继续读DB,读出来一个老数据
- 然后线程B把老数据设置入cache
- 线程A写入DB最新的数据
酱紫就有问题啦,缓存和数据库的数据不一致了。
缓存保存的是老数据,数据库保存的是新数据。因此,Cache-Aside缓存模式,选择了先操作数据库而不是先操作缓存。
redis分布式缓存与数据库的数据一致性
重要:缓存是通过牺牲强一致性来提高性能的。
这是由CAP理论决定的。缓存系统适用的场景就是非强一致性的场景,它属于CAP中的AP。
强一致性还是弱一致性
CAP理论,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容错性(Partition tolerance)
最多满足其中的两个特性。也就是下图所描述的。分布式系统要么满足CA,要么CP,要么AP。无法同时满足CAP。

I. 什么是 一致性、可用性和分区容错性
分区容错性:指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供满足一致性和可用性的服务。也就是说部分故障不影响整体使用。
事实上我们在设计分布式系统是都会考虑到bug,硬件,网络等各种原因造成的故障,所以即使部分节点或者网络出现故障,我们要求整个系统还是要继续使用的
(不继续使用,相当于只有一个分区,那么也就没有后续的一致性和可用性了)
可用性: 一直可以正常的做读写操作。简单而言就是客户端一直可以正常访问并得到系统的正常响应。用户角度来看就是不会出现系统操作失败或者访问超时等问题。
一致性:在分布式系统完成某写操作后任何读操作,都应该获取到该写操作写入的那个最新的值。相当于要求分布式系统中的各节点时时刻刻保持数据的一致性。
所以,如果需要数据库和缓存数据保持强一致,就不适合使用缓存。
所以使用缓存提升性能,就是会有数据更新的延迟。这需要我们在设计时结合业务仔细思考是否适合用缓存。然后缓存一定要设置过期时间,这个时间太短、或者太长都不好:
- 太短的话请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势。
- 太长的话缓存中的脏数据会使系统长时间处于一个延迟的状态,而且系统中长时间没有人访问的数据一直存在内存中不过期,浪费内存。
但是,通过一些方案优化处理,是可以保证弱一致性,最终一致性的。
3种方案保证数据库与缓存的一致性
3种方案保证数据库与缓存的一致性
- 延时双删策略
- 删除缓存重试机制
- 读取biglog异步删除缓存
缓存延时双删
有些小伙伴可能会说,不一定要先操作数据库呀,采用缓存延时双删策略就好啦?
什么是延时双删呢?
延时双删的步骤:
1 先删除缓存
2 再更新数据库
3 休眠一会(比如1秒),再次删除缓存。

这个休眠一会,一般多久呢?都是1秒?
这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。
为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
删除缓存重试机制
不管是延时双删还是Cache-Aside的先操作数据库再删除缓存,如果第二步的删除缓存失败呢?
删除失败会导致脏数据哦~
删除失败就多删除几次呀,保证删除缓存成功呀~ 所以可以引入删除缓存重试机制

删除缓存重试机制的大致步骤:
-
写请求更新数据库
-
缓存因为某些原因,删除失败
-
把删除失败的key放到消息队列
-
消费消息队列的消息,获取要删除的key
-
重试删除缓存操作
同步biglog异步删除缓存
重试删除缓存机制还可以,就是会造成好多业务代码入侵。
其实,还可以通过数据库的binlog来异步淘汰key。

以mysql为例 可以使用阿里的canal将binlog日志采集发送到MQ队列里面,然后编写一个简单的缓存删除消息者订阅binlog日志,根据更新log删除缓存,并且通过ACK机制确认处理这条更新log,保证数据缓存一致性
如何确保消费成功
PushConsumer为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功。中途断电,抛出异常等都不会认为成功——即都会重新投递。首先,消费的时候,我们需要注入一个消费回调,具体sample代码如下:
consumer.registerMessageListener(new MessageListenerConcurrently() { @Override public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) { System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs); delcache(key);//执行真正删除 return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;//返回消费成功 } });
业务实现消费回调的时候,当且仅当此回调函数返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS,RocketMQ才会认为这批消息(默认是1条)是消费完成的。
如果这时候消息消费失败,例如数据库异常,余额不足扣款失败等一切业务认为消息需要重试的场景,只要返回ConsumeConcurrentlyStatus.RECONSUME_LATER,RocketMQ就会认为这批消息消费失败了。
为了保证消息是肯定被至少消费成功一次,RocketMQ会把这批消费失败的消息重发回Broker(topic不是原topic而是这个消费租的RETRY topic),在延迟的某个时间点(默认是10秒,业务可设置)后,再次投递到这个ConsumerGroup。而如果一直这样重复消费都持续失败到一定次数(默认16次),就会投递到DLQ死信队列。应用可以监控死信队列来做人工干预。
pub/sub的订阅实现
Pub/Sub功能(means Publish, Subscribe)即发布及订阅功能。Pub/Sub是目前广泛使用的通信模型,它采用事件作为基本的通信机制,提供大规模系统所要求的松散耦合的交互模式:订阅者(如客户端)以事件订阅的方式表达出它有兴趣接收的一个事件或一类事件;发布者(如服务器)可将订阅者感兴趣的事件随时通知相关订阅者。熟悉设计模式的朋友应该了解这与23种设计模式中的观察者模式极为相似。
Redis 的 pub/sub订阅实现
Redis通过publish和subscribe命令实现订阅和发布的功能。订阅者可以通过subscribe向redis server订阅自己感兴趣的消息类型。redis将信息类型称为通道(channel)。当发布者通过publish命令向redis server发送特定类型的信息时,订阅该消息类型的全部订阅者都会收到此消息。
主从数据库通过biglog异步删除
但是呢还有个问题, 「如果是主从数据库呢」?
因为主从DB同步存在延时时间。如果删除缓存之后,数据同步到备库之前已经有请求过来时, 「会从备库中读到脏数据」,如何解决呢?解决方案如下流程图:

缓存与数据的一致性的保障策略总结
综上所述,在分布式系统中,缓存和数据库同时存在时,如果有写操作的时候,「先操作数据库,再操作缓存」。如下:
1.读取缓存中是否有相关数据
2.如果缓存中有相关数据value,则返回
3.如果缓存中没有相关数据,则从数据库读取相关数据放入缓存中key->value,再返回
4.如果有更新数据,则先更新数据库,再删除缓存
5.为了保证第四步删除缓存成功,使用binlog异步删除
6.如果是主从数据库,binglog取自于从库
7.如果是一主多从,每个从库都要采集binlog,然后消费端收到最后一台binlog数据才删除缓存,或者为了简单,收到一次更新log,删除一次缓存
实战:Canal+RocketMQ同步MySQL到Redis/ES
在很多业务情况下,我们都会在系统中加入redis缓存做查询优化, 使用es 做全文检索。
如果数据库数据发生更新,这时候就需要在业务代码中写一段同步更新redis的代码。这种数据同步的代码跟业务代码糅合在一起会不太优雅,能不能把这些数据同步的代码抽出来形成一个独立的模块呢,答案是可以的。
biglog同步保障数据一致性的架构

技术栈
如果你还对SpringBoot、canal、RocketMQ、MySQL、ElasticSearch 不是很了解的话,这里我为大家整理个它们的官网网站,如下
- SpringBoot:https://spring.io/projects/spring-boot
- canal :https://github.com/alibaba/canal
- RocketMQ:http://rocketmq.apache.org/
- MySQL:https://www.mysql.com/
- ElasticSearch:https://www.elastic.co/cn/elasticsearch/
这里主要介绍一下canal,其他的自行学习。
canal工作原理
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费.。
canal工作原理
canal是一个伪装成slave订阅mysql的binlog,实现数据同步的中间件。

- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
canal架构
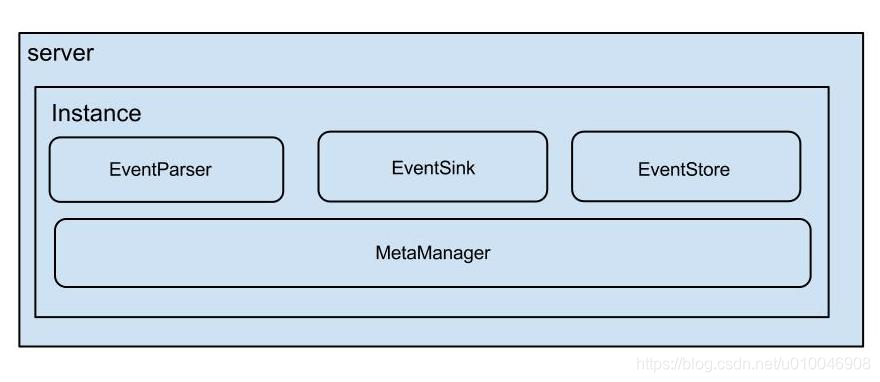
说明:
- server代表一个canal运行实例,对应于一个jvm
- instance对应于一个数据队列 (1个server对应1…n个instance)
instance模块:
- eventParser (数据源接入,模拟db的slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
到这里我们对canal有了一个初步的认识,接下我们就进入实战环节。
3.环境准备
3.1 MySQL 配置
对于自建 MySQL , 需要先开启 Binlog写入功能,配置binlog-format为ROW 模式,my.cnf 中配置如下
[mysqld] log-bin=mysql-bin # 开启 binlog binlog-format=ROW # 选择 ROW 模式 server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
**
注意:**针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
授权canal 连接 MySQL 账号具有作为 MySQL slave的权限, 如果已有账户可直接 使用grant 命令授权。
#创建用户名和密码都为canal CREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; FLUSH PRIVILEGES;
3.2 canal的安装和配置
3.2 .1canal.admin安装和配置
canal提供web ui 进行Server管理、Instance管理。
下载 canal.admin, 访问 release 页面 , 选择需要的包下载, 如以 1.1.4版本为例
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.admin-1.1.4.tar.gz
解压完成可以看到如下结构:
我们先配置canal.admin之后。通过web ui来配置 cancal server,这样使用界面操作非常的方便。
配置修改
vi conf/application.yml server: port: 8089 spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 spring.datasource: address: 127.0.0.1:3306 database: canal_manager username: canal password: canal driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false hikari: maximum-pool-size: 30 minimum-idle: 1 canal: adminUser: admin adminPasswd: admin
初始化元数据库
初始化元数据库
mysql -h127.0.0.1 -uroot -p # 导入初始化SQL > source conf/canal_manager.sql
- 初始化SQL脚本里会默认创建canal_manager的数据库,建议使用root等有超级权限的账号进行初始化
- canal_manager.sql默认会在conf目录下,也可以通过链接下载
canal_manager.sql
启动
sh bin/startup.sh
启动成功,使用浏览器输入http://ip:8089/ 会跳转到登录界面

使用用户名:admin 密码为:123456 登录
登录成功,会自动跳转到如下界面。这时候我们的canal.admin就搭建成功了。

3.2.2 canal.deployer部署和启动
下载 canal.deployer, 访问 release 页面 , 选择需要的包下载, 如以 1.1.4版本为例
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
解压完成可以看到如下结构:
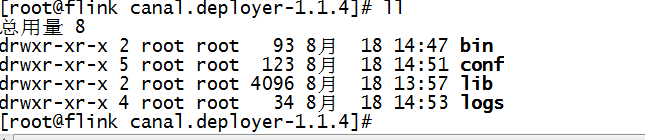
进入conf 目录。可以看到如下的配置文件。

我们先对canal.properties 不做任何修改。
使用canal_local.properties的配置覆盖canal.properties
# register ip canal.register.ip = # canal admin config canal.admin.manager = 127.0.0.1:8089 canal.admin.port = 11110 canal.admin.user = admin canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441 # admin auto register canal.admin.register.auto = true canal.admin.register.cluster =
使用如下命令启动canal server
sh bin/startup.sh local
启动成功。同时我们在canal.admin web ui中刷新 server 管理,可以到canal server 已经启动成功。

这时候我们的canal.server 搭建已经成功。
3.2.3在canal admin ui 中配置Instance管理
新建 Instance
选择Instance 管理-> 新建Instance
填写 Instance名称:cms_article
大概的步骤
- 选择 选择所属主机集群
- 选择 载入模板
- 修改默认信息
#mysql serverId canal.instance.mysql.slaveId = 1234 #position info,需要改成自己的数据库信息 canal.instance.master.address = 127.0.0.1:3306 canal.instance.master.journal.name = canal.instance.master.position = canal.instance.master.timestamp = #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #username/password,需要改成自己的数据库信息 canal.instance.dbUsername = canal canal.instance.dbPassword = canal #改成自己的数据库信息(需要监听的数据库) canal.instance.defaultDatabaseName = cms-manage canal.instance.connectionCharset = UTF-8 #table regex 需要过滤的表 这里数据库的中所有表 canal.instance.filter.regex = .\*\\..\* # MQ 配置 日志数据会发送到cms_article这个topic上 canal.mq.topic=cms_article # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..* #单分区处理消息 canal.mq.partition=0
我们这里为了演示之创建一张表。
配置好之后,我需要点击保存。此时在Instances 管理中就可以看到此时的实例信息。
3.2.4 修改canal server 的配置文件,选择消息队列处理binlog
canal 1.1.1版本之后, 默认支持将canal server接收到的binlog数据直接投递到MQ, 目前默认支持的MQ系统有:
- kafka: https://github.com/apache/kafka
- RocketMQ : https://github.com/apache/rocketmq
本案例以RocketMQ为例
我们仍然使用web ui 界面操作。点击 server 管理 - > 点击配置
修改配置文件
# ... # 可选项: tcp(默认), kafka, RocketMQ canal.serverMode = RocketMQ # ... # kafka/rocketmq 集群配置: 192.168.1.117:9092,192.168.1.118:9092,192.168.1.119:9092 canal.mq.servers = 192.168.0.200:9078 canal.mq.retries = 0 # flagMessage模式下可以调大该值, 但不要超过MQ消息体大小上限 canal.mq.batchSize = 16384 canal.mq.maxRequestSize = 1048576 # flatMessage模式下请将该值改大, 建议50-200 canal.mq.lingerMs = 1 canal.mq.bufferMemory = 33554432 # Canal的batch size, 默认50K, 由于kafka最大消息体限制请勿超过1M(900K以下) canal.mq.canalBatchSize = 50 # Canal get数据的超时时间, 单位: 毫秒, 空为不限超时 canal.mq.canalGetTimeout = 100 # 是否为flat json格式对象 canal.mq.flatMessage = false canal.mq.compressionType = none canal.mq.acks = all # kafka消息投递是否使用事务 canal.mq.transaction = false
修改好之后保存。会自动重启。
此时我们就可以在rocketmq的控制台看到一个cms_article topic已经自动创建了。
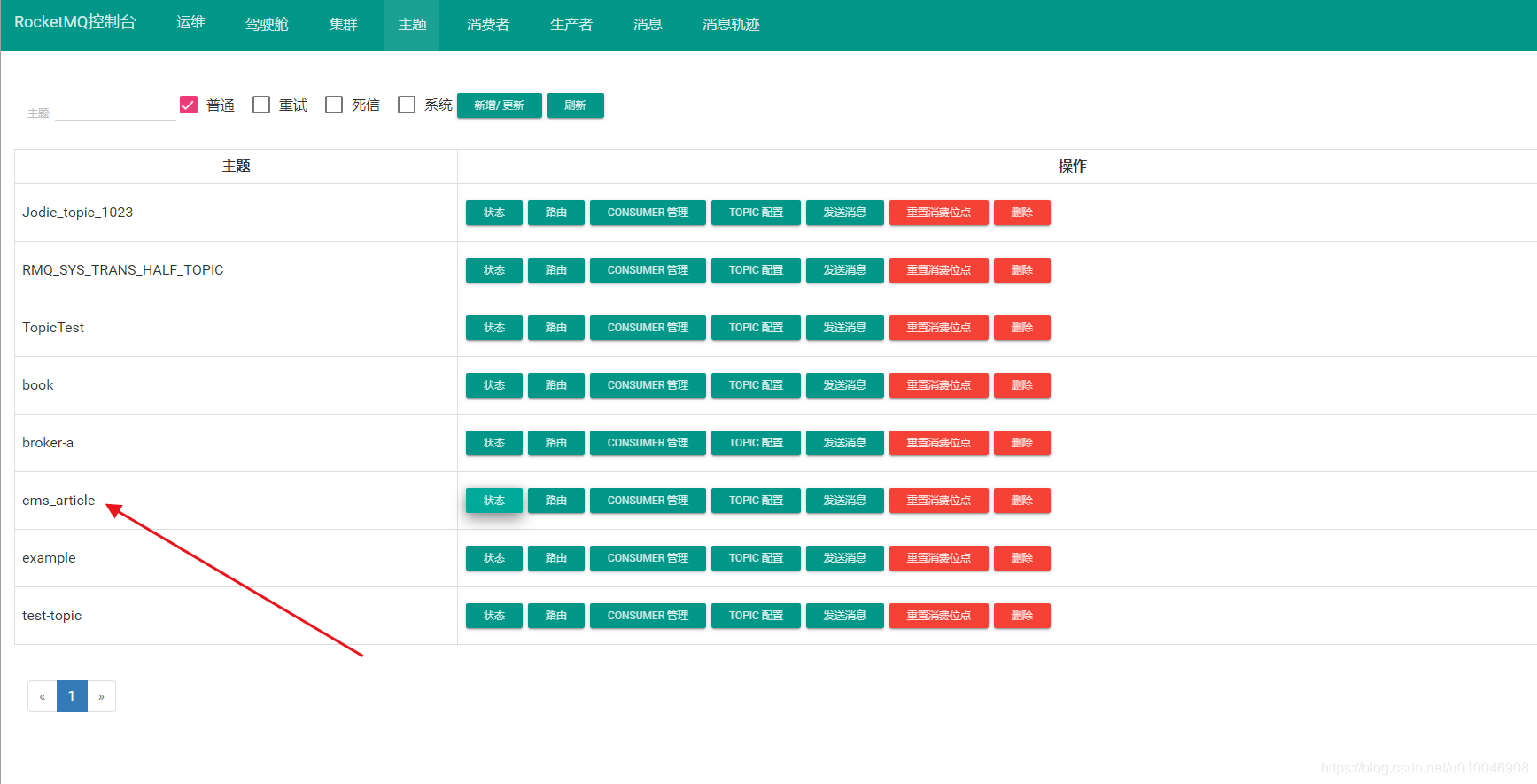
4 更新Redis的MQ消息者开发
4.1 引入依赖
<dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId> <version>1.1.4</version> </dependency> <dependency> <groupId>org.apache.rocketmq</groupId> <artifactId>rocketmq-spring-boot-starter</artifactId> <version>2.0.2</version> </dependency> <!-- 根据个人需要依赖 --> <dependency> <groupId>javax.persistence</groupId> <artifactId>persistence-api</artifactId> </dependency>
4.2 canal消息的通用解析代码
package com.crazymaker.springcloud.stock.consumer; import com.alibaba.otter.canal.protocol.FlatMessage; import com.crazymaker.springcloud.common.exception.BusinessException; import com.crazymaker.springcloud.common.util.JsonUtil; import com.crazymaker.springcloud.standard.redis.RedisRepository; import com.google.common.collect.Sets; import lombok.extern.slf4j.Slf4j; import org.springframework.data.redis.connection.RedisConnection; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.RedisSerializer; import org.springframework.util.ReflectionUtils; import javax.annotation.Resource; import javax.persistence.Id; import java.lang.reflect.Field; import java.lang.reflect.ParameterizedType; import java.util.Collection; import java.util.List; import java.util.Map; import java.util.Set; /** * 抽象CanalMQ通用处理服务 **/ @Slf4j public abstract class AbstractCanalMQ2RedisService<T> implements CanalSynService<T> { @Resource private RedisTemplate<String, Object> redisTemplate; @Resource RedisRepository redisRepository; private Class<T> classCache; /** * 获取Model名称 * * @return Model名称 */ protected abstract String getModelName(); @Override public void process(FlatMessage flatMessage) { if (flatMessage.getIsDdl()) { ddl(flatMessage); return; } Set<T> data = getData(flatMessage); if (SQLType.INSERT.equals(flatMessage.getType())) { insert(data); } if (SQLType.UPDATE.equals(flatMessage.getType())) { update(data); } if (SQLType.DELETE.equals(flatMessage.getType())) { delete(data); } } @Override public void ddl(FlatMessage flatMessage) { //TODO : DDL需要同步,删库清空,更新字段处理 } @Override public void insert(Collection<T> list) { insertOrUpdate(list); } @Override public void update(Collection<T> list) { insertOrUpdate(list); } private void insertOrUpdate(Collection<T> list) { redisTemplate.executePipelined((RedisConnection redisConnection) -> { for (T data : list) { String key = getWrapRedisKey(data); RedisSerializer keySerializer = redisTemplate.getKeySerializer(); RedisSerializer valueSerializer = redisTemplate.getValueSerializer(); redisConnection.set(keySerializer.serialize(key), valueSerializer.serialize(data)); } return null; }); } @Override public void delete(Collection<T> list) { Set<String> keys = Sets.newHashSetWithExpectedSize(list.size()); for (T data : list) { keys.add(getWrapRedisKey(data)); } //Set<String> keys = list.stream().map(this::getWrapRedisKey).collect(Collectors.toSet()); redisRepository.delAll(keys); } /** * 封装redis的key * * @param t 原对象 * @return key */ protected String getWrapRedisKey(T t) { // return new StringBuilder() // .append(ApplicationContextHolder.getApplicationName()) // .append(":") // .append(getModelName()) // .append(":") // .append(getIdValue(t)) // .toString(); throw new IllegalStateException( "基类 方法 'getWrapRedisKey' 尚未实现!"); } /** * 获取类泛型 * * @return 泛型Class */ protected Class<T> getTypeArguement() { if (classCache == null) { classCache = (Class) ((ParameterizedType) this.getClass().getGenericSuperclass()).getActualTypeArguments()[0]; } return classCache; } /** * 获取Object标有@Id注解的字段值 * * @param t 对象 * @return id值 */ protected Object getIdValue(T t) { Field fieldOfId = getIdField(); ReflectionUtils.makeAccessible(fieldOfId); return ReflectionUtils.getField(fieldOfId, t); } /** * 获取Class标有@Id注解的字段名称 * * @return id字段名称 */ protected Field getIdField() { Class<T> clz = getTypeArguement(); Field[] fields = clz.getDeclaredFields(); for (Field field : fields) { Id annotation = field.getAnnotation(Id.class); if (annotation != null) { return field; } } log.error("PO类未设置@Id注解"); throw new BusinessException("PO类未设置@Id注解"); } /** * 转换Canal的FlatMessage中data成泛型对象 * * @param flatMessage Canal发送MQ信息 * @return 泛型对象集合 */ protected Set<T> getData(FlatMessage flatMessage) { List<Map<String, String>> sourceData = flatMessage.getData(); Set<T> targetData = Sets.newHashSetWithExpectedSize(sourceData.size()); for (Map<String, String> map : sourceData) { T t = JsonUtil.mapToPojo(map, getTypeArguement()); targetData.add(t); } return targetData; } }
4.3 canal消息的订阅代码
rocketMQ是支持广播消费的,只需要在消费端进行配置即可,默认情况下使用的是集群消费,这就意味着如果我们配置了多个消费者实例,只会有一个实例消费消息。
对于更新Redis来说,一个实例消费消息,完成redis的更新,这就够了。
package com.crazymaker.springcloud.stock.consumer; import com.alibaba.otter.canal.protocol.FlatMessage; import com.crazymaker.springcloud.seckill.dao.po.SeckillGoodPO; import com.google.common.collect.Sets; import lombok.Data; import lombok.extern.slf4j.Slf4j; import org.apache.rocketmq.spring.annotation.MessageModel; import org.apache.rocketmq.spring.annotation.RocketMQMessageListener; import org.apache.rocketmq.spring.core.RocketMQListener; import org.springframework.stereotype.Service; import java.util.List; import java.util.Map; import java.util.Set; @Slf4j @Service //广播模式 //@RocketMQMessageListener(topic = "seckillgood", consumerGroup = "UpdateRedis", messageModel = MessageModel.BROADCASTING) //集群模式 @RocketMQMessageListener(topic = "seckillgood", consumerGroup = "UpdateRedis") @Data public class UpdateRedisGoodConsumer extends AbstractCanalMQ2RedisService<SeckillGoodPO> implements RocketMQListener<FlatMessage> { private String modelName = "seckillgood"; @Override public void onMessage(FlatMessage s) { process(s); } // @Cacheable(cacheNames = {"seckill"}, key = "'seckillgood:' + #goodId") /** * 封装redis的key * * @param t 原对象 * @return key */ protected String getWrapRedisKey(SeckillGoodPO t) { return new StringBuilder() // .append(ApplicationContextHolder.getApplicationName()) .append("seckill") .append(":") // .append(getModelName()) .append("seckillgood") .append(":") .append(t.getId()) .toString(); } /** * 转换Canal的FlatMessage中data成泛型对象 * * @param flatMessage Canal发送MQ信息 * @return 泛型对象集合 */ protected Set<SeckillGoodPO> getData(FlatMessage flatMessage) { List<Map<String, String>> sourceData = flatMessage.getData(); Set<SeckillGoodPO> targetData = Sets.newHashSetWithExpectedSize(sourceData.size()); for (Map<String, String> map : sourceData) { SeckillGoodPO po = new SeckillGoodPO(); po.setId(Long.valueOf(map.get("id"))); //省略其他的属性 targetData.add(po); } return targetData; } }
2.3.2 注意事项
根据需要可以重写里面的方法,DDL处理暂时还没完成,只是整个Demo,完整的实战活儿,还是留给大家自己干吧。
尼恩的忠实建议:
-
理论水平的提升,看看视频、看看书,只有两个字,就是需要:多看。
-
实战水平的提升,只有两个字,就是需要:多干。

