
- 1ofbiz部署异常(一)
- 22023年数维杯C题思路——AI生成文本的智能识别与检测_ai生成文本的智能识别与检测数学模型
- 3毕业设计:基于区块链的物联网设备身份认证与敏感数据访问控制机制设计与实现_区块链数字身份认证论文
- 4一文了解预训练模型 Prompt 调优(比较详细)_prompt优化
- 5大语言模型-基础及拓展应用
- 6微信小程序文件下载及在线打开指定文档,解压Zip格式压缩包_微信小游戏加载的zip包
- 7Linux(CentOs)安装Redis教程_centos redis
- 8Python爬虫教你爬取视频信息_pycharm爬取视频源码
- 9基于YOLO的安全头盔佩戴识别与报警系统及PyQt界面设计(代码和警报仿真)_yolo pyqt
- 10http状态码大全304、201、203等等_203 状态码
Kafka入门(安装和SpringBoot整合)_spring boot kafka
赞
踩
一、Docker安装Kafka
1. 创建网络
app-tier:网络名称
–driver:网络类型为bridge
docker network create app-tier --driver bridge
- 1
2. 安装zookeeper
Kafka依赖zookeeper所以先安装zookeeper
-p:设置映射端口(默认2181)
-d:后台启动
docker run -d --name zookeeper-server \
--network app-tier \
-e ALLOW_ANONYMOUS_LOGIN=yes \
bitnami/zookeeper:latest
- 1
- 2
- 3
- 4
3. 安装Kafka
安装并运行Kafka,
–name:容器名称
-p:设置映射端口(默认9092 )
-d:后台启动
ALLOW_PLAINTEXT_LISTENER任何人可以访问
KAFKA_CFG_ZOOKEEPER_CONNECT链接的zookeeper
KAFKA_ADVERTISED_HOST_NAME当前主机IP或地址(重点:如果是服务器部署则配服务器IP或域名否则客户端监听消息会报地址错误)
-e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.101:9092 \
docker run -d --name kafka-server \
--network app-tier \
-p 9092:9092 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
-e KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper-server:2181 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 \
bitnami/kafka:latest
- 1
- 2
- 3
- 4
- 5
- 6
- 7
二、Kafka介绍
1. Kafka简介
Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做日志的处理。既然是消息队列,那么Kafka也就拥有消息队列的相应的特性了。
消息队列的好处
解耦合
- 耦合的状态表示当你实现某个功能的时候,是直接接入当前接口,而利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果接口出了问题,将不会影响到当前的功能。
异步处理
- 异步处理替代了之前的同步处理,异步处理不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可。
流量削峰
- 高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力。

Kafka像其他Mq一样,也有自己的基础架构,主要存在生产者Producer、Kafka集群Broker、消费者Consumer、注册消息Zookeeper.
- Producer:消息生产者,向Kafka中发布消息的角色。
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
- Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
- Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
- Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
- Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
- Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
Kafka 基础概念
生产者与消费者

对于 Kafka 来说客户端有两种基本类型:生产者(Producer)和消费者(Consumer)。除此之外,还有用来做数据集成的 Kafka Connect API 和流式处理的 Kafka Streams 等高阶客户端,但这些高阶客户端底层仍然是生产者和消费者API,它们只不过是在上层做了封装。
这很容易理解,生产者(也称为发布者)创建消息,而消费者(也称为订阅者)负责消费or读取消息。
主题(Topic)与分区(Partition)

在 Kafka 中,消息以主题(Topic)来分类,每一个主题都对应一个「消息队列」,这有点儿类似于数据库中的表。但是如果我们把所有同类的消息都塞入到一个“中心”队列中,势必缺少可伸缩性,无论是生产者/消费者数目的增加,还是消息数量的增加,都可能耗尽系统的性能或存储。
我们使用一个生活中的例子来说明:现在 A 城市生产的某商品需要运输到 B 城市,走的是公路,那么单通道的高速公路不论是在「A 城市商品增多」还是「现在 C 城市也要往 B 城市运输东西」这样的情况下都会出现「吞吐量不足」的问题。所以我们现在引入分区(Partition)的概念,类似“允许多修几条道”的方式对我们的主题完成了水平扩展。
Broker 和集群(Cluster)
一个 Kafka 服务器也称为 Broker,它接受生产者发送的消息并存入磁盘;Broker 同时服务消费者拉取分区消息的请求,返回目前已经提交的消息。使用特定的机器硬件,一个 Broker 每秒可以处理成千上万的分区和百万量级的消息。(现在动不动就百万量级…我特地去查了一把,好像确实集群的情况下吞吐量挺高的…摁…)
若干个 Broker 组成一个集群(Cluster),其中集群内某个 Broker 会成为集群控制器(Cluster Controller),它负责管理集群,包括分配分区到 Broker、监控 Broker 故障等。在集群内,一个分区由一个 Broker 负责,这个 Broker 也称为这个分区的 Leader;当然一个分区可以被复制到多个 Broker 上来实现冗余,这样当存在 Broker 故障时可以将其分区重新分配到其他 Broker 来负责。下图是一个样例:
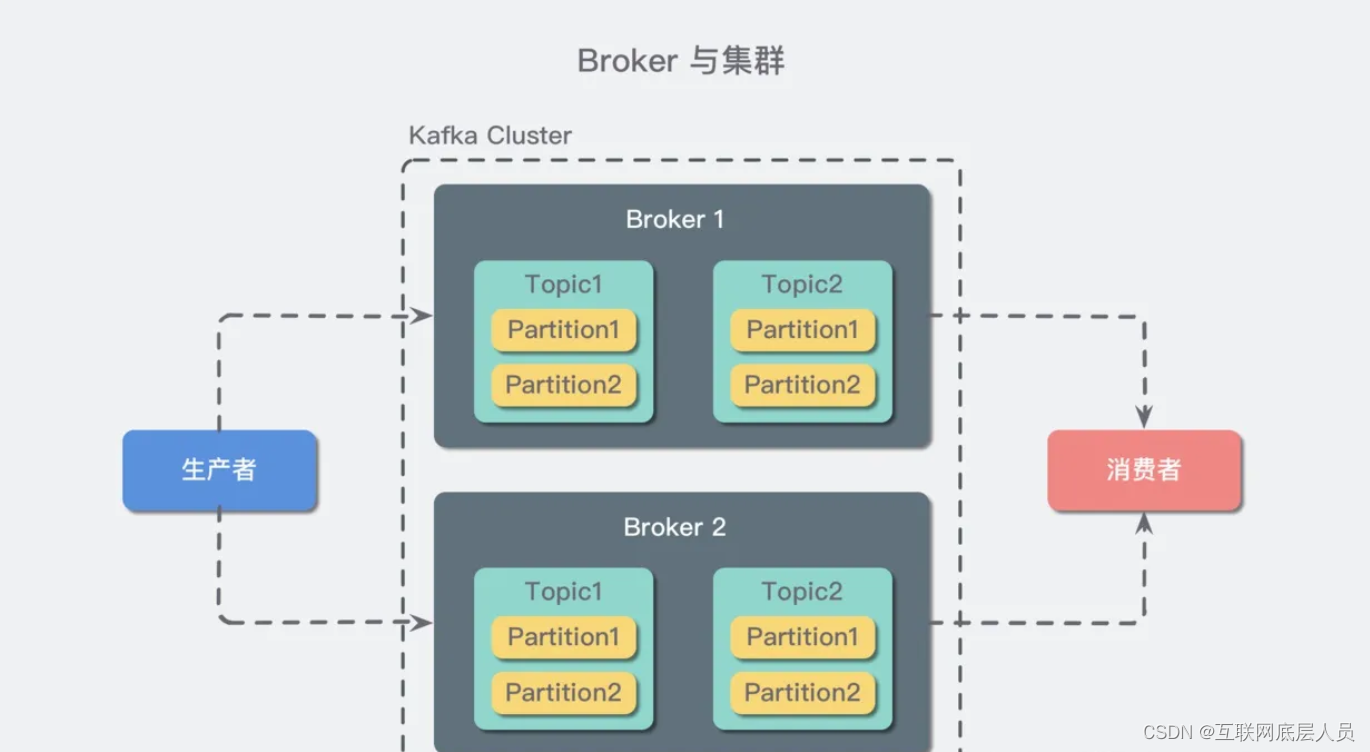
Kafka 的一个关键性质是日志保留(retention),我们可以配置主题的消息保留策略,譬如只保留一段时间的日志或者只保留特定大小的日志。当超过这些限制时,老的消息会被删除。我们也可以针对某个主题单独设置消息过期策略,这样对于不同应用可以实现个性化。
多集群
随着业务发展,我们往往需要多集群,通常处于下面几个原因:
基于数据的隔离;
基于安全的隔离;
多数据中心(容灾)
当构建多个数据中心时,往往需要实现消息互通。举个例子,假如用户修改了个人资料,那么后续的请求无论被哪个数据中心处理,这个更新需要反映出来。又或者,多个数据中心的数据需要汇总到一个总控中心来做数据分析。
上面说的分区复制冗余机制只适用于同一个 Kafka 集群内部,对于多个 Kafka 集群消息同步可以使用 Kafka 提供的 MirrorMaker 工具。本质上来说,MirrorMaker 只是一个 Kafka 消费者和生产者,并使用一个队列连接起来而已。它从一个集群中消费消息,然后往另一个集群生产消息。
三、SpringBoot整合Kafka
1. 引入pom依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- 1
- 2
- 3
- 4
2. application.propertise配置
###########【Kafka集群】########### spring.kafka.bootstrap-servers=112.126.74.249:9092,112.126.74.249:9093 ###########【初始化生产者配置】########### # 重试次数 spring.kafka.producer.retries=0 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1) spring.kafka.producer.acks=1 # 批量大小 spring.kafka.producer.batch-size=16384 # 提交延时 spring.kafka.producer.properties.linger.ms=0 # 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka # linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了 # 生产端缓冲区大小 spring.kafka.producer.buffer-memory = 33554432 # Kafka提供的序列化和反序列化类 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer # 自定义分区器 # spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner ###########【初始化消费者配置】########### # 默认的消费组ID spring.kafka.consumer.properties.group.id=defaultConsumerGroup # 是否自动提交offset spring.kafka.consumer.enable-auto-commit=true # 提交offset延时(接收到消息后多久提交offset) spring.kafka.consumer.auto.commit.interval.ms=1000 # 当kafka中没有初始offset或offset超出范围时将自动重置offset # earliest:重置为分区中最小的offset; # latest:重置为分区中最新的offset(消费分区中新产生的数据); # none:只要有一个分区不存在已提交的offset,就抛出异常; spring.kafka.consumer.auto-offset-reset=latest # 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作) spring.kafka.consumer.properties.session.timeout.ms=120000 # 消费请求超时时间 spring.kafka.consumer.properties.request.timeout.ms=180000 # Kafka提供的序列化和反序列化类 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer # 消费端监听的topic不存在时,项目启动会报错(关掉) spring.kafka.listener.missing-topics-fatal=false # 设置批量消费 # spring.kafka.listener.type=batch # 批量消费每次最多消费多少条消息 # spring.kafka.consumer.max-poll-records=50

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
3. Hello Kafka(Producer)
创建生产者,用于给Kafka发送消息
@RestController
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
// 发送消息
@GetMapping("/kafka/normal/{message}")
public void sendMessage1(@PathVariable("message") String normalMessage) {
kafkaTemplate.send("topic1", normalMessage);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4. Consumer Kafka
消费者
@Component
public class KafkaConsumer {
// 消费监听
@KafkaListener(topics = {"topic1"})
public void onMessage1(ConsumerRecord<?, ?> record){
// 消费的哪个topic、partition的消息,打印出消息内容
System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上面示例创建了一个生产者,发送消息到topic1,消费者监听topic1消费消息。监听器用@KafkaListener注解,topics表示监听的topic,支持同时监听多个,用英文逗号分隔。启动项目,postman调接口触发生产者发送消息,

5. 带回调的生产者
kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功 或 失败时做补偿处理.
@GetMapping("/kafka/callbackOne/{message}")
public void sendMessage2(@PathVariable("message") String callbackMessage) {
kafkaTemplate.send("topic1", callbackMessage).addCallback(success -> {
// 消息发送到的topic
String topic = success.getRecordMetadata().topic();
// 消息发送到的分区
int partition = success.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = success.getRecordMetadata().offset();
System.out.println("发送消息成功:" + topic + "-" + partition + "-" + offset);
}, failure -> {
System.out.println("发送消息失败:" + failure.getMessage());
});
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
6. 自定义分区器
我们知道,kafka中每个topic被划分为多个分区,那么生产者将消息发送到topic时,具体追加到哪个分区呢?这就是所谓的分区策略,Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。其路由机制为:
① 若发送消息时指定了分区(即自定义分区策略),则直接将消息append到指定分区;
② 若发送消息时未指定 patition,但指定了 key(kafka允许为每条消息设置一个key),则对key值进行hash计算,根据计算结果路由到指定分区,这种情况下可以保证同一个 Key 的所有消息都进入到相同的分区;
③ patition 和 key 都未指定,则使用kafka默认的分区策略,轮询选出一个 patition;
※ 我们来自定义一个分区策略,将消息发送到我们指定的partition,首先新建一个分区器类实现Partitioner接口,重写方法,其中partition方法的返回值就表示将消息发送到几号分区
public class CustomizePartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { // 自定义分区规则(这里假设全部发到0号分区) // ...... return 0; } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在application.propertise中配置自定义分区器,配置的值就是分区器类的全路径名
spring.kafka.producer.properties.partitioner.class=com.example.kafkademo.conf.CustomizePartitioner
- 1
7. kafka事务提交
如果在发送消息时需要创建事务,可以使用 KafkaTemplate 的 executeInTransaction 方法来声明事务.
@GetMapping("/kafka/transaction")
public void sendMessage7(){
// 声明事务:后面报错消息不会发出去
kafkaTemplate.executeInTransaction(operations -> {
operations.send("topic1","test executeInTransaction");
throw new RuntimeException("fail");
});
// 不声明事务:后面报错但前面消息已经发送成功了
kafkaTemplate.send("topic1","test executeInTransaction");
throw new RuntimeException("fail");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
8. 指定topic、partition、offset消费
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
* @Author long.yuan
* @Date 2020/3/22 13:38
* @Param [record]
* @return void
**/
@KafkaListener(id = "consumer1",groupId = "felix-group",topicPartitions = {
@TopicPartition(topic = "topic1", partitions = { "0" }),
@TopicPartition(topic = "topic2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))
})
public void onMessage2(ConsumerRecord<?, ?> record) {
System.out.println("topic:"+record.topic()+"|partition:"+record.partition()+"|offset:"+record.offset()+"|value:"+record.value());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
9. ConsumerAwareListenerErrorHandler 异常处理器
通过异常处理器,我们可以处理consumer在消费时发生的异常。
新建一个 ConsumerAwareListenerErrorHandler 类型的异常处理方法,用@Bean注入,BeanName默认就是方法名,然后我们将这个异常处理器的BeanName放到@KafkaListener注解的errorHandler属性里面,当监听抛出异常的时候,则会自动调用异常处理器
// 新建一个异常处理器,用@Bean注入 @Bean public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler() { return (message, exception, consumer) -> { System.out.println("消费异常:"+message.getPayload()); return null; }; } // 将这个异常处理器的BeanName放到@KafkaListener注解的errorHandler属性里面 @KafkaListener(topics = {"topic1"},errorHandler = "consumerAwareErrorHandler") public void onMessage4(ConsumerRecord<?, ?> record) throws Exception { throw new Exception("简单消费-模拟异常"); } // 批量消费也一样,异常处理器的message.getPayload()也可以拿到各条消息的信息 @KafkaListener(topics = "topic1",errorHandler="consumerAwareErrorHandler") public void onMessage5(List<ConsumerRecord<?, ?>> records) throws Exception { System.out.println("批量消费一次..."); throw new Exception("批量消费-模拟异常"); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
10. 消息过滤器
消息过滤器可以在消息抵达consumer之前被拦截,在实际应用中,我们可以根据自己的业务逻辑,筛选出需要的信息再交由KafkaListener处理,不需要的消息则过滤掉。
配置消息过滤只需要为 监听器工厂 配置一个RecordFilterStrategy(消息过滤策略),返回true的时候消息将会被抛弃,返回false时,消息能正常抵达监听容器。
@Component public class KafkaConsumer { @Autowired ConsumerFactory consumerFactory; // 消息过滤器 @Bean public ConcurrentKafkaListenerContainerFactory filterContainerFactory() { ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory(); factory.setConsumerFactory(consumerFactory); // 被过滤的消息将被丢弃 factory.setAckDiscarded(true); // 消息过滤策略 factory.setRecordFilterStrategy(consumerRecord -> { if (Integer.parseInt(consumerRecord.value().toString()) % 2 == 0) { return false; } //返回true消息则被过滤 return true; }); return factory; } // 消息过滤监听 @KafkaListener(topics = {"topic1"},containerFactory = "filterContainerFactory") public void onMessage6(ConsumerRecord<?, ?> record) { System.out.println(record.value()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
11. 消息转发
在实际开发中,我们可能有这样的需求,应用A从TopicA获取到消息,经过处理后转发到TopicB,再由应用B监听处理消息,即一个应用处理完成后将该消息转发至其他应用,完成消息的转发。
在SpringBoot集成Kafka实现消息的转发也很简单,只需要通过一个@SendTo注解,被注解方法的return值即转发的消息内容
/**
* @Title 消息转发
* @Description 从topic1接收到的消息经过处理后转发到topic2
* @Author long.yuan
* @Date 2020/3/23 22:15
* @Param [record]
* @return void
**/
@KafkaListener(topics = {"topic1"})
@SendTo("topic2")
public String onMessage7(ConsumerRecord<?, ?> record) {
return record.value()+"-forward message";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
12. 定时启动、停止监听器
默认情况下,当消费者项目启动的时候,监听器就开始工作,监听消费发送到指定topic的消息,那如果我们不想让监听器立即工作,想让它在我们指定的时间点开始工作,或者在我们指定的时间点停止工作,该怎么处理呢——使用KafkaListenerEndpointRegistry,下面我们就来实现:
① 禁止监听器自启动;
② 创建两个定时任务,一个用来在指定时间点启动定时器,另一个在指定时间点停止定时器;
新建一个定时任务类,用注解@EnableScheduling声明,KafkaListenerEndpointRegistry 在SpringIO中已经被注册为Bean,直接注入,设置禁止KafkaListener自启动
@EnableScheduling @Component public class CronTimer { /** * @KafkaListener注解所标注的方法并不会在IOC容器中被注册为Bean, * 而是会被注册在KafkaListenerEndpointRegistry中, * 而KafkaListenerEndpointRegistry在SpringIOC中已经被注册为Bean **/ @Autowired private KafkaListenerEndpointRegistry registry; @Autowired private ConsumerFactory consumerFactory; // 监听器容器工厂(设置禁止KafkaListener自启动) @Bean public ConcurrentKafkaListenerContainerFactory delayContainerFactory() { ConcurrentKafkaListenerContainerFactory container = new ConcurrentKafkaListenerContainerFactory(); container.setConsumerFactory(consumerFactory); //禁止KafkaListener自启动 container.setAutoStartup(false); return container; } // 监听器 @KafkaListener(id="timingConsumer",topics = "topic1",containerFactory = "delayContainerFactory") public void onMessage1(ConsumerRecord<?, ?> record){ System.out.println("消费成功:"+record.topic()+"-"+record.partition()+"-"+record.value()); } // 定时启动监听器 @Scheduled(cron = "0 42 11 * * ? ") public void startListener() { System.out.println("启动监听器..."); // "timingConsumer"是@KafkaListener注解后面设置的监听器ID,标识这个监听器 if (!registry.getListenerContainer("timingConsumer").isRunning()) { registry.getListenerContainer("timingConsumer").start(); } //registry.getListenerContainer("timingConsumer").resume(); } // 定时停止监听器 @Scheduled(cron = "0 45 11 * * ? ") public void shutDownListener() { System.out.println("关闭监听器..."); registry.getListenerContainer("timingConsumer").pause(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49

