
- 1完美解决 studio sdk tools 缺失下载选项问题_mac android-sdk 缺少 tools
- 215种图神经网络的应用场景总结_图神经网络 案例
- 3python 如何控制鼠标键盘_python控制鼠标和键盘
- 4【2024】基于springboot的机械设备租赁系统设计(源码+文档+学习资料)_springboot基于javaweb的畅丰农机器械租赁系统的设计与实现摘要
- 5leetcode203.移除链表元素
- 6大龄程序员的出路究竟在何处?从369个过来人问答贴里,我们得到了答案_40到50岁程序员吃香吗
- 7国内接口 四行代码搭建一个属于自己的AI聊天机器人_国内聊天ai代码
- 8【本科生电子类竞赛】小白入门学习路线_电子设计大赛控制类硬件要学什么知识
- 9P2-AI产品经理-九五小庞
- 10flink 大数据处理资源分配_十亿数据 flink 资源分配
布隆过滤器(Bloom Filter)详解_bitmap布隆过滤
赞
踩
上一篇文章介绍了Bitmap基础原理以及优化之后的高级数据结构Roaring Bitmap,本篇将介绍bitmap的一个经典应用Bloom Filter
简介
Bloom filter是一种高效的数据结构,它可以用来判断一个元素是否在一个集合中。相比于传统的数据结构,如HashSet和HashMap,Bloom filter具有更高的空间效率和查询速度。
不过,Bloom Filter有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter判断元素不再集合,那肯定不在。如果判断元素存在集合中的话,会有一定的概率判断错误。因此,Bloom Filter不适合需要零错误的场景,但在可以容忍低错误率的应用场合下,Bloom Filter比其他常见的算法相比极大地节省了空间。
基本思想
bloom-filter实际上是一个很长的二进制向量和一系列随机映射函数,可以看做是对 bit-map 的扩展。下面来说说其工作原理。
Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突(只能减少冲突,但是不采用其他手段例如hashmap,那么是无法解决冲突的),我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。
当一个元素被加入集合时,会通过 K 个 Hash函数将该元素映射成到位阵列(Bit array)中的 K 个坐标(点)并把它们置为1。检索时,我们只要看看这些位置是不是都是1就行了。此时会有两种情况:
- 如果这些点有任何一个 0,则被检索元素一定不在;
- 如果都是1,则被检索元素可能在。
简而言之:有的不一定有,没有的一定没有
在bloom filter中包含一个位数组和k个独立hash函数。
位数组
假设Bloom Filter使用一个m比特的数组来保存信息,初始状态时,Bloom Filter是一个包含m位的位数组,每个位都置为0,即BF整个数组的元素都设置为0。

hash函数
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数,它们分别将集合中的每个元素映射到{1,…,m}的范围中。
当我们往Bloom Filter中增加任意一个元素x时候,我们使用k个哈希函数得到k个哈希值,然后将数组中对应的比特位设置为1。即第i个哈希函数映射的位置hash(x)就会被置为1(1≤i≤k)。
注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第9位,即第5个“1”处)。
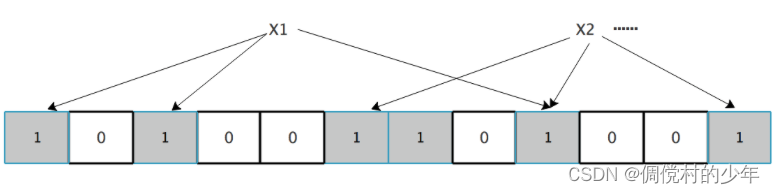
判断元素是否存在
在判断y是否属于这个集合时,我们只需要对y使用k个哈希函数得到k个哈希值。
- 如果所有hash(y)的位置都是1(1≤i≤k),即k个位置都被设置为1了,那么我们就认为y是集合中的元素。
- 否则就认为y不是集合中的元素。下图中y1就不是集合中的元素(因为y1有一处指向了“0”位)。对于y2来说,可能属于这个集合,但也可能不是,因为有个指向“1”的位置和y1“共用”了,也即发生了hash冲突。
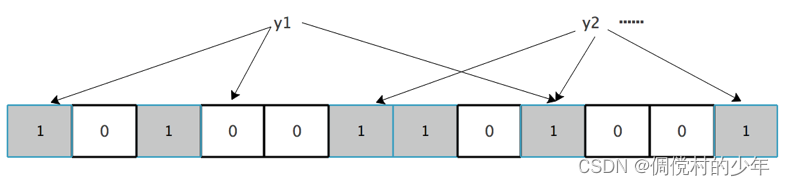
存在的问题
准确率问题
通过上面的介绍,我们知道BloomFilter可能有误判,误判的几率取决于Hash函数的个数、Hash函数冲撞的概率、位数组的大小。其中为了保证效果,Hash函数的个数要取个合适的值。因为大了会造成效率问题,少了可能误判高(hash冲突高)。一般在工程里hash函数用3~5个,当然具体多少需要视需求而定。
假设输入的元素个数为n,数组的大小为m,hash函数个数为k,错误率要求为w的话,下面的公式可以作为选择参数的参考。
当hash函数 k = m / n ∗ ln 2 k=m/n*\ln2 k=m/n∗ln2个数时,错误率最小。
使用场景的局限
由于是采用hash算法,对于一些字符串类型的数据做检索很适合,但对于数值型就比较麻烦了,因为一旦对数值做了hash映射,那么还需要做一次转换操作。
bloom filter虽然在判断某个元素是否在一个集合中比较有效,但通过对其数据结构的了解,可以发现其并不适用于多个集合间的交并差操作,也即其并不支持集合运算,即使可以实现,也非常别扭和低效。
一个大致的思路是:如果两个集合元素通过hash存放于bloom filter,要对其做交集运算,那么需要分别读取这两个集合元素本身,分别判断各个集合元素是否在2个bloom filter中是否存在,且其有一定的误判率,因此并不适合。

