
- 1【Gensim概念】03/3 NLP玩转 word2vec
- 2C#之调用海康工业相机SDK采集图像并在Halcon窗口中显示_c#海康相机读取显示
- 3git配置过程中fatal:拒绝合并无关的历史
- 4autojs 连接电脑 vs code过程_autojs code
- 5sccb协议
- 6啥移动硬盘格式能更好兼容Windows和Mac系统 NTFS格式苹果电脑不能修改 paragon ntfs for mac激活码_mac和windows都能用的硬盘格式
- 7安装grub到U盘分区,实现多系统引导(BIOS,UEFI)_efibootmgr not found
- 8Python小白的数学建模课-01.新手必读_优化算法 是个小白的数学建模工具
- 9Mysql5.6.40 主从复制故障_mysql 5.6.40-log
- 10Java后端面经精简(集合篇)_java后端 csdn
满满的干货:AI大模型对网络五大需求及技术应对方案_ai网络
赞
踩
AI大模型对网络的需求主要体现在五个方面,即超大规模组网、超高带宽、超低时延、超高稳定性及网络自动化部署。为了应对这五个方面的需求,本文对业内一些主要的应对技术、思路和方案进行了梳理,供读者进行系统优化时做参考,不对具体技术实现细节做过多论述,对应的思维导图如下,仅供参考!
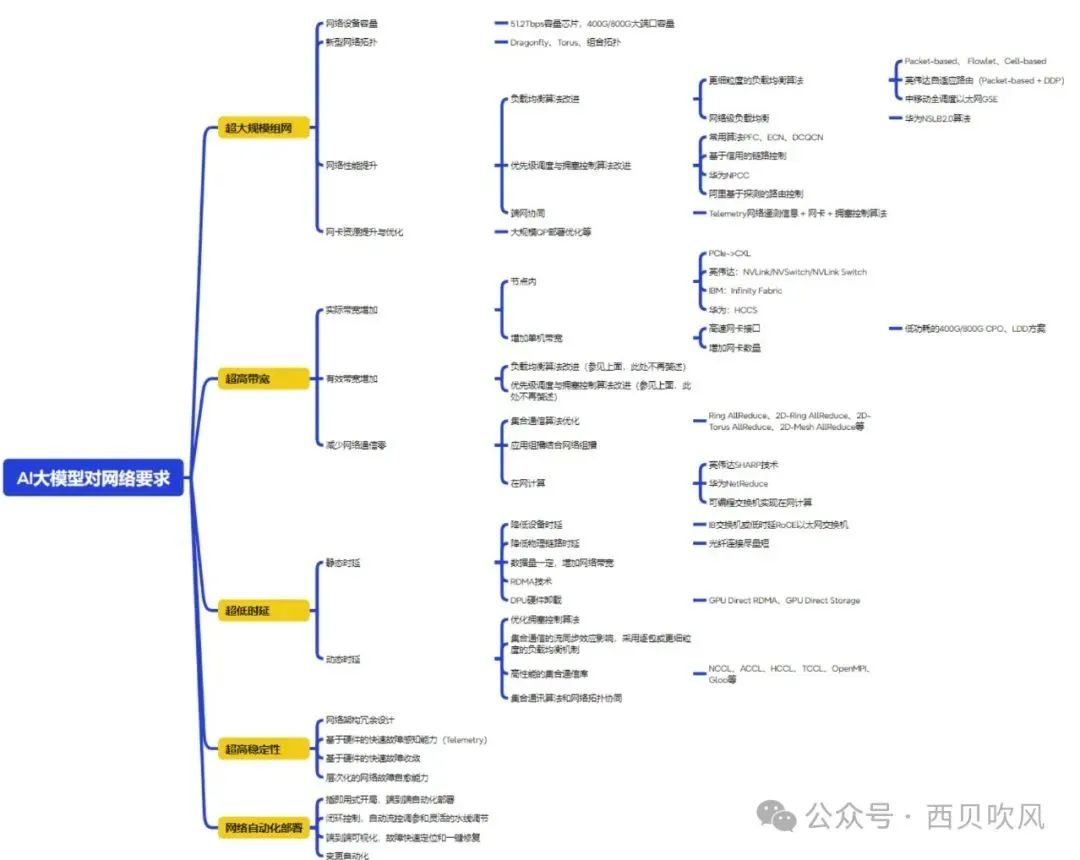
No.1
超大规模组网需求及应对
-
网络设备容量制约组网规模:400G/800G高速端口开始规模商用
使用大容量、高密度网络设备,51.2Tbps容量芯片开始商用,可倍增设备400G/800G接口的密度,通过增加单个网元容量,减少所需的网络层次,扩展网络规模。
-
网络拓扑架构制约组网规模:多级CLOS可以支持大规模,但是多跳情况下时延增加
研究使用新型网络拓扑,如Dragonfly(网络直径短,具备低成本、端到端通信跳数少等优点,同等情况下是Fat-tree组网规模的几倍)、Torus(采用多轨网络架构,可以实现整网规模成倍增长,Torus网络维度已从3D进化到了6D)等网络架构或多种拓扑组合使用。
-
网络性能需求制约组网规模:传统拥塞控制算法无法有效应对Incast流量模型的影响,传统的微突发流量应对策略导致低带宽利用率,拥塞控制算法能力不足限制集群规模扩展
负载均衡算法改进
AI训练的流量模型特征是“少流”和“大流”。解决思路有两个:一个是更细粒度的负载均衡算法(包级别),另一个是网络级负载均衡算法。
- 使用更细粒度的负载均衡算法,如Packet-based、 Flowlet、Cell-based等负载均衡,几种方案各有优劣,如Packet-base存在乱序问题;Flowlet是针对TCP特性设计的,不适合RDMA流量;Cell-based时延高且需要硬件支持,不适合超算类高性能要求业务;
- 英伟达采用了Packet-based负载均衡技术,在其自适应路由解决方案中,为解决乱序的问题,使用BlueField-3 DPU通过DDP(直接数据放置)处理无序数据,Spectrum交换机通过带内遥测获取用于准确估计拥塞的排队信息及用于快速恢复的端口利用率指示,交换机通过拥塞最小的端口传输数据包,在路径之间距离不同的其他拓扑中,交换机倾向于通过最短路径发送流量,如果拥塞发生在最短路径上,则选择拥塞最小的备选路径,确保网络带宽得到有效利用,从而和网络设备形成端到端的完整解决方案;
- 中移动主导的全调度以太网GSE,采用定长的PKTC进行报文转发及动态负载均衡,区别于CELL转发,该机制下以太网报文在逻辑上组成虚拟容器,并以该容器为最小单元在交换网络中传输,通过构建基于PKTC的DGSQ全调度机制、精细的反压机制和无感知自愈机制,实现微突发及故障场景下的精准控制。该技术主要通过网络层面解决,不需要网卡协同;
- 网络级负载均衡,也可以理解为感知路由的负载均衡,如华为NSLB2.0算法,可根据整网交换机节点流拥塞状态和全网拓扑,计算出最佳的流量分布,然后自动进行导流,拥有纵观全局的上帝视角,从而达到全网吞吐最优。
拥塞控制算法
- RDMA网络应用常见的优先级调度和拥塞控制算法PFC、ECN、DCQCN;
- 流量控制技术除基于优先级的PFC外,还可以使用基于信用的链路控制,在通过连接发送数据之前,发送端需要接收接受端通过虚拟回路发送的信用值,在不同时期,接收端发送信用额到发送端,说明接收端可用的缓冲区大小,当接收到信用额,发送端就按照信用额发送数据到接收端,每次发送端发送数据后,相应的信用额减少,这样可以有效减少失败重传造成网络阻塞;
- 华为的NPCC(Network-based Proactive Congestion Control)是一种以网络设备为核心的主动拥塞控制技术,支持在网络设备上智能识别拥塞状态,主动发送CNP拥塞通知报文,准确控制服务器发送RoCEv2报文的速率,既可以确保拥塞时的及时降速,又可以避免拥塞已经缓解时的过度降速;
- 阿里:基于探测的路由控制,服务器通过改变源/目的端口向对等服务器发送多个探测数据包,每个探测数据包都需要记录它所经过的交换机,以便发送者可以知道映射的完整路由路径,最后为这两台服务器构建一个连接路径表。
- 端网协同,基于Telemetry网络遥测信息配合网卡和拥塞控制算法,达到精确控制流量、快速收敛、充分利用空闲带宽,最终达到避免拥塞,提高带宽利用率的效果。
\4. 网卡资源不足限制组网规模:RDMA网卡需为每个连接
维护协议状态,进而消耗掉大量的片上缓存,如何减少
QP需求以及优化QP可支持数量成为关键
网卡资源优化措施包括:针对大规模QP部署措施优化,
每连接多路径的能力优化,从RC模式往连接数依赖更小
的模式演进,从go back N重传往选择性重传演进,可编
程能力优化。
No.2
超高带宽需求及应对
1. 实际带宽增加
- 节点内,传统PCIe通信带宽不足
- 高带宽互联技术,CXL、英伟达NVLink/NVSwitch/NVLink Switch、华为HCCS、IBM Infinity Fabric
- 增加单机带宽
- 高速网卡端口(低功耗的400G/800G CPO、LDD方案)
- 增加网卡数量
\2. 有效带宽增加
- 负载均衡算法改进(参见上节,这里不再赘述)
- 拥塞控制算法优化(参见上节,这里不再赘述)
\3. 减少网络通信量
- 集合通信算法优化,减少网络通信量:如Ring AllReduce、2D-Ring AllReduce、2D-Torus AllReduce、2D-Mesh AllReduce等;
- 应用组播结合网络组播,交换机完成组播报文的复制分发,以网络层组播替代应用层组播,避免相同数据的重复发送,减少网络通信量;
- 在网计算,减少网络通信量
- 英伟达SHARP在网计算,达成在交换机上的数据聚合(Aggregation)和归约(Reduction),有效拓宽网络带宽极限,英伟达的Infiniband交换机和NVSwitch/NVLink Switch都支持,上述交换机中都扩展有计算芯片;
- 华为NetReduce基于RoCEv2,使用FPGA来实现了交换机的在网计算;
- 基于可编程交换机实现在网计算压缩数据流量,理论上是一个思路,但是目前没有看到实际落地方案;
- 另外,移动研究院也发布了《在网计算(NACA)技术白皮书》,相关技术和架构可供参考。
No.3
超低时延需求及应对
1. 降低静态时延
- 降低设备时延:采用IB网络或低时延的RoCE以太网交换机;
- 降低链路时延(传输的距离):尾纤连接足够短;
- 数据量一定的情况下,可以通过增加网络带宽,降低时延;
- 采用RDMA技术,缩短通信路径,降低端到端时延;
- DPU硬件全卸载:GPU Direct RDMA、GPU Direct Storage。
2. 动态时延
- 优化拥塞控制算法,降低拥塞导致的排队时延;
- 集合通信的流同步效应不仅要求低时延,且要求时延抖动尽可能低,可以采用逐包或更细粒度的负载均衡机制降低时延和时延抖动;
- 高性能的集合通信库降低时延,NCCL、OpenMPI、Gloo、ACCL、HCCL、TCCL等;
- 集合通讯算法和网络拓扑协同,降低时延。
No.4
超高稳定性需求及应对
1. 网络架构冗余设计
基于硬件的快速故障感知能力
2. 基于Telemetry的数据采集机制实现基于硬件的快速故障感知
最小数据采集精度可以达到毫秒级粒度,同时,除基础网络性能数据采集和感知外,覆盖队列吞吐、丢包、PFC、ECN、队列缓存等RoCE网络关键指标项。同时,在采集的性能指标基础之上,提供PFC风暴、死锁故障检测、高速光模块异常检测、队列一致性检测等上层故障、风险识别能力,主动评估、预测网络健康情况。
3. 基于硬件的快速故障收敛
重新定义数据面的故障传递和收敛协议,仅通过数据面,就可以支持全网微秒级路径切。
4. 层次化的网络故障自愈能力
在链路层面,通过充分挖掘网络多路径的资源价值,在最合适的节点以最快的速度实现流量转发路径的切换保护;在设备层面,通过利用节点级保护技术,实现流量的快速重路由;在网络层面,借助自动化和智能化的手段对常见的网络级故障开展根因分析和问题关联,通过快速响应预案的积累形成网络自动止血的能力,确保网络故障恢复指标在可预期的范围内。
No.5
自动化部署需求及应对
1. 即插即用式开局,端到端自动化部署配置能力
2. 自动流控调参和灵活的水线调节
通过网络遥测Telemetry、AI的智能分析与控制(统一的控制器,即AI大脑),实现闭环控制,自动流控调参和灵活的水线调节。
3. 端到端可视化,实现故障的快速定位
通过呈现网络的拥塞状态、负载不均状态等,为自动化调度调优提供数据支持,可实现端到端可视化、自动化运维等,实现故障的快速定位和一键修复的能力。
4. 变更自动化
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

