
- 14.k8s:cronJob计划任务,初始化容器,污点、容忍,亲和力,身份认证和权限
- 2C语言----二维数组
- 3创建Oracle本地数据库详细步骤,Oracle-创建本地数据库
- 4Ubuntu下的STM32开发环境搭建(VScode+CubeMX+arm-none-eabi-gcc交叉编译工具链),使用JLink进行烧录(非OpenOCD),使用Ozone进行调试_ozone调试
- 5【java基础-实战3】list遍历时删除元素的方法_list 遍历删除
- 6【云计算学习教程】探讨私有云计算平台的搭建(附带3套解决方案)_私有云云平台解决方案学习路径(3)_如何学习私有云
- 7LiveGBS流媒体平台GB/T28181功能-获取GB28181接入的海康大华宇视华为摄像头硬件NVR设备通道视频直播流地址HLS/HTTP-FLV/WS-FLV/WebRTC/RTMP/RTSP_gb28181平台
- 8【附源码】流浪动物救助及领养管理系统(源码+毕业论文齐全)java开发ssm框架javaweb javaee项目,可做计算机毕业设计或课程设计_流浪动物救助系统
- 9网易 Duilib:功能全面的开源桌面 UI 开发框架_duilib 跨平台
- 10cookie,session和token的区别_chrome查看token
ACL2024主会:中科院发布表格理解大模型Table-LLaVA,刷榜23项指标_大模型理解表格
赞
踩
随着人工智能的飞速发展,让AI模型像人一样直接"看懂"表格,进而完成相关任务的能力变得越来越重要。然而,以往的表格理解方法大多依赖于将表格转换为文本格式再输入模型,这不仅耗时耗力,在实际应用中获取高质量文本格式表格也并非易事。那么,AI模型能否直接通过视觉信息理解表格呢?
近日,中科院信工所的研究者们创新性地提出了"多模态表格理解"这一问题,即让AI模型直接从表格图像中获取信息,进而完成问答、推理等下游任务。他们构建了目前最大规模的多模态表格理解数据集MMTab,涵盖了丰富多样的表格图像和任务,并在此基础上开发了一个强大的多模态表格理解模型Table-LLaVA。
通过巧妙的两阶段训练,Table-LLaVA展现出了优异的多模态表格理解能力,在23个评测任务上全面超越了现有的多模态大模型,甚至可以和强大的GPT-4V一较高下。
论文标题:Multimodal Table Understanding
论文链接:https://arxiv.org/pdf/2406.08100

表格处理,AI的新战场
在大数据时代,表格无处不在。传统的表格理解方法需要将表格转换为文本格式,存在诸多不便。直接从图像中"读懂"表格更加直观高效,但对AI而言是一个巨大挑战。它需要像人一样通过视觉理解表格,进而执行相关任务。这正是多模态表格理解要攻克的难题,如何赋予AI直接理解表格图像的能力,成为了当前AI领域的重要课题。
多模态表格理解正是为了解决这一问题而提出的新兴研究方向。它的目标是赋予AI系统直接从表格图像中提取、转换、解释关键信息的能力,并以端到端的方式生成针对不同表格相关请求(如问题)的正确响应。尽管最新的多模态大语言模型在许多任务上表现出色,但它们在理解表格数据方面的能力还有待加强。以MiniGPT-4和BLIP2等热门模型为例,它们在大多数表格理解任务上的性能接近于零。这凸显了当前多模态大模型在这一领域的局限性。

表格理解是AI发展的新方向。突破传统的文本表格理解,直接利用视觉分析表格,是大模型走向真正智能化的关键。它不仅能提升处理真实表格数据的效率,也将拓展AI的应用场景。
MMTab与Table-LLaVA
要让AI像人一样"读懂"表格图像,离不开两个关键要素:高质量的数据集和强大的模型。MMTab数据集和Table-LLaVA模型就是这两把利剑,共同推动了多模态表格理解的研究进程。
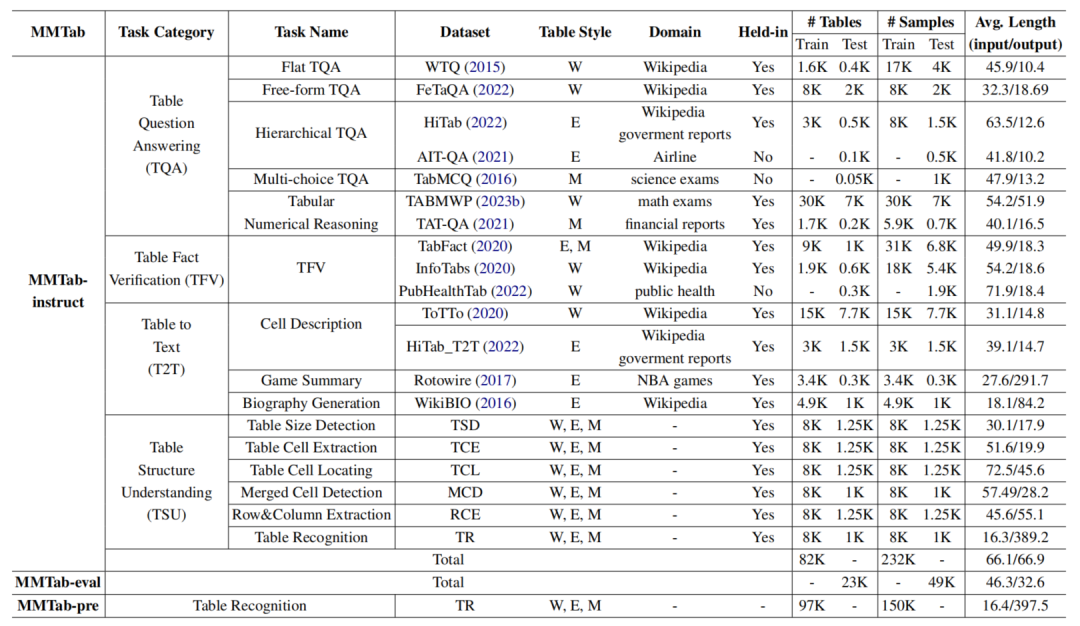
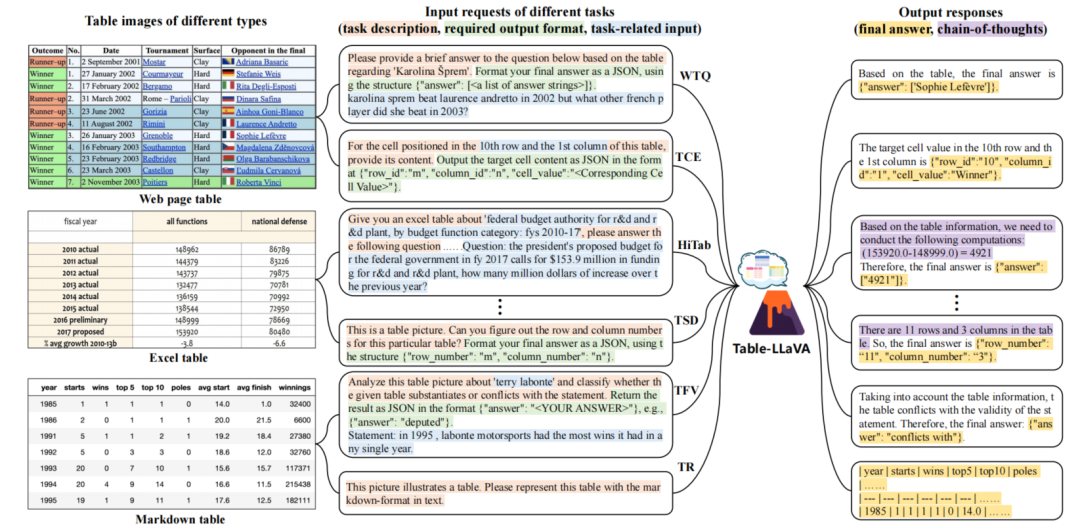
MMTab是目前规模最大、覆盖最全面的多模态表格理解数据集。其包含了来自14个公开数据集的大量表格,涵盖维基百科、政府报告、科学试卷等8个领域。通过精心设计的转换脚本,研究者将原始的文本格式表格转化为高质量图像,并生成统一格式的指令数据。下图展示了MMTab的样本示例,由表格图像、输入指令、输出答案三部分组成。
为进一步提升数据多样性,研究者还实施了表格、指令、任务三个层面的增强策略。其中尤为创新的是引入了6个全新的表格结构理解任务,如表格尺寸检测等。最终,MMTab包含了15万训练样本、23.2万指令调优样本和4.9万测试样本,总计超过105万张表格图像。
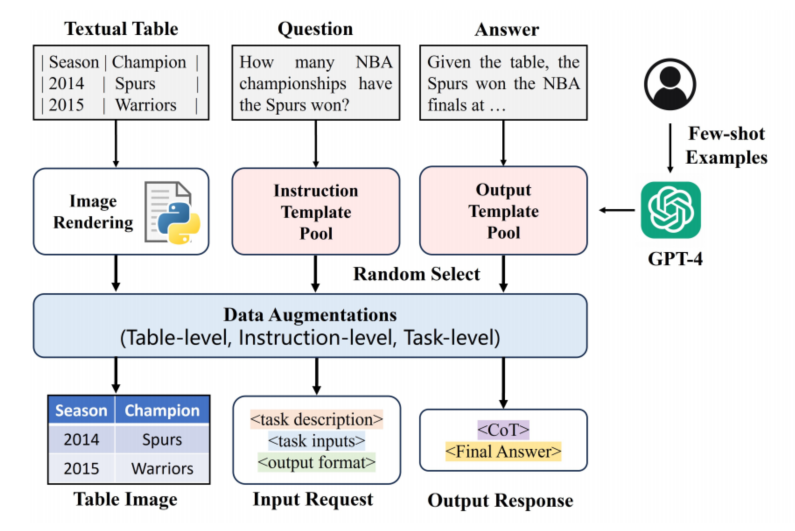
有了MMTab这个高质量的数据集,Table-LLaVA就成为了探索多模态表格理解的有力工具。它采用了独特的两阶段训练范式:先在MMTab-pre上进行表格识别预训练,再在MMTab-instruct上进行指令调优。视觉编码器通过连接器与语言模型紧密结合,实现了跨模态信息的无缝交互。
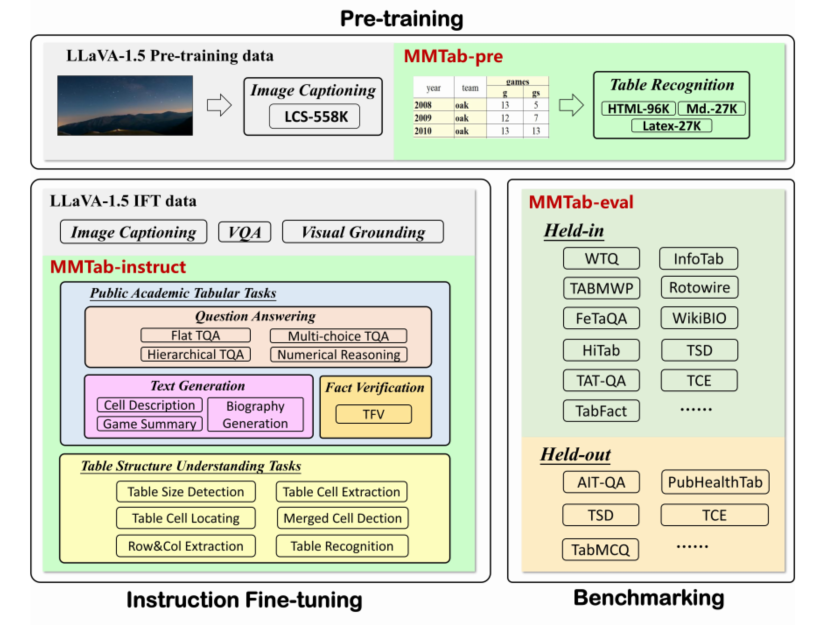
Table-LLaVA:实力与潜力并存的多模态表格理解"选手"
为全面评估Table-LLaVA的性能,研究者在MMTab数据集上设计了一系列实验。这些实验涵盖了已见和未见任务、学术基准测试和真实场景应用等多个维度,力求客观公正地展现模型的实力。
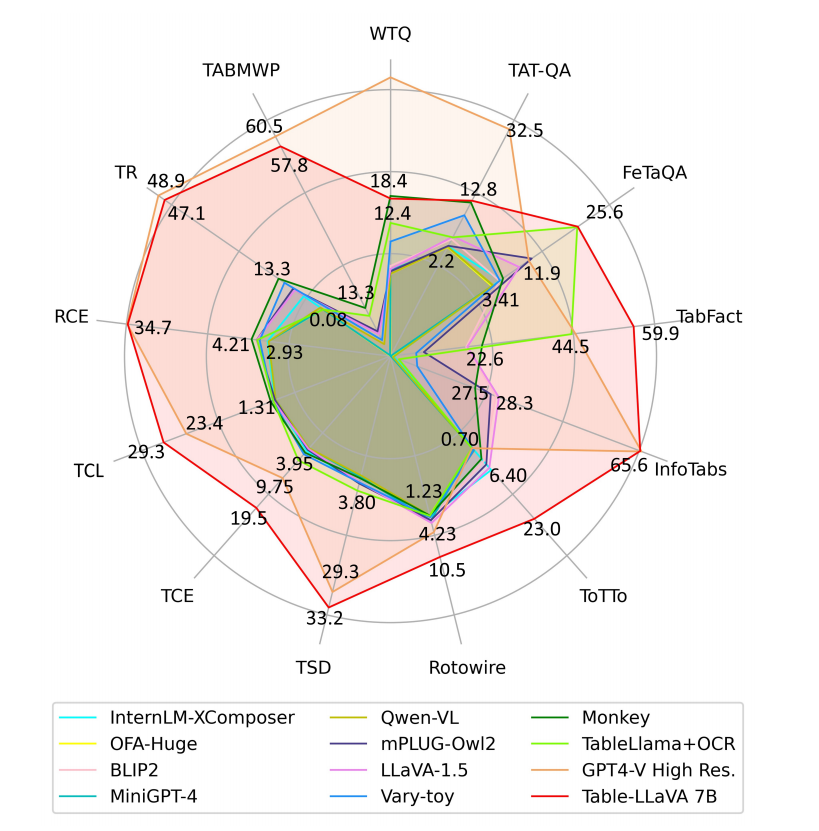
研究者首先评估了Table-LLaVA在MMTab学术基准测试中的性能。实验结果表明,在绝大多数任务上,无论是Table-LLaVA的7B版本还是13B版本,都明显优于其他开源模型。
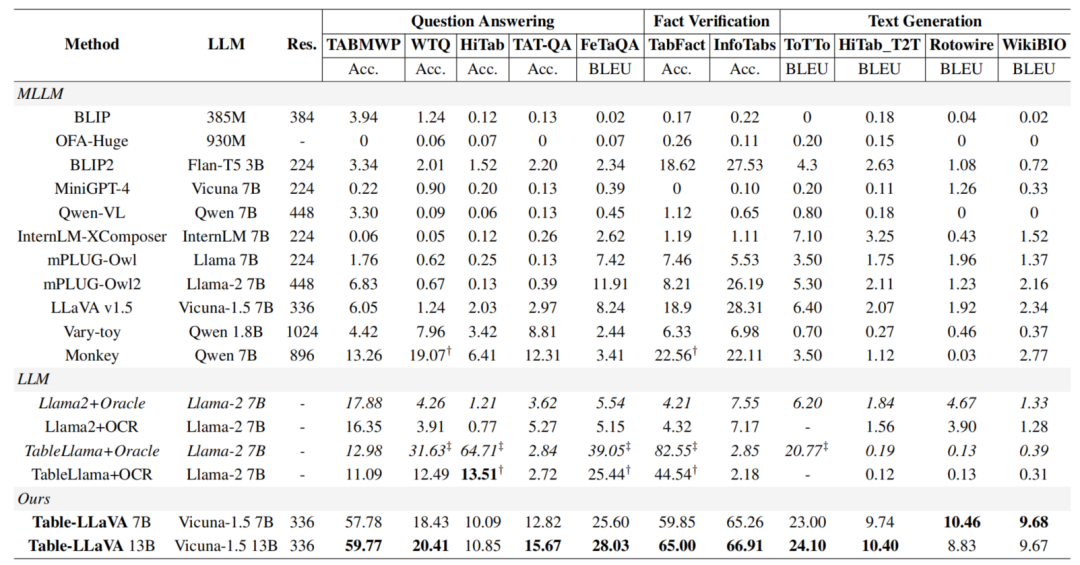
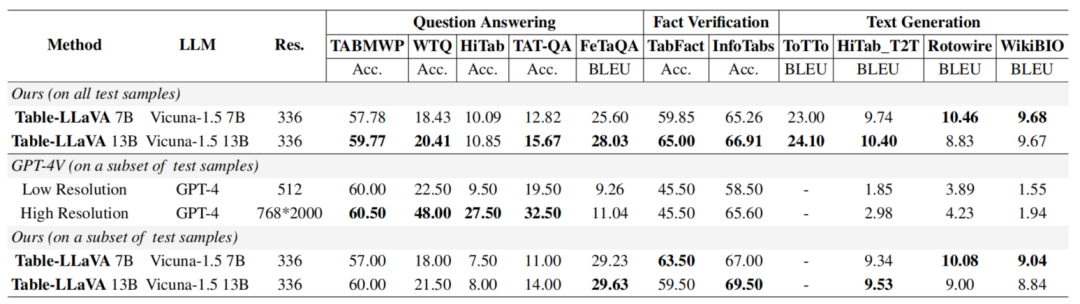
即使与强大的GPT-4V模型相比,Table-LLaVA在许多任务上也展现出了非常有竞争力的性能。这些结果充分证实了Table-LLaVA在表格理解领域的领先地位。
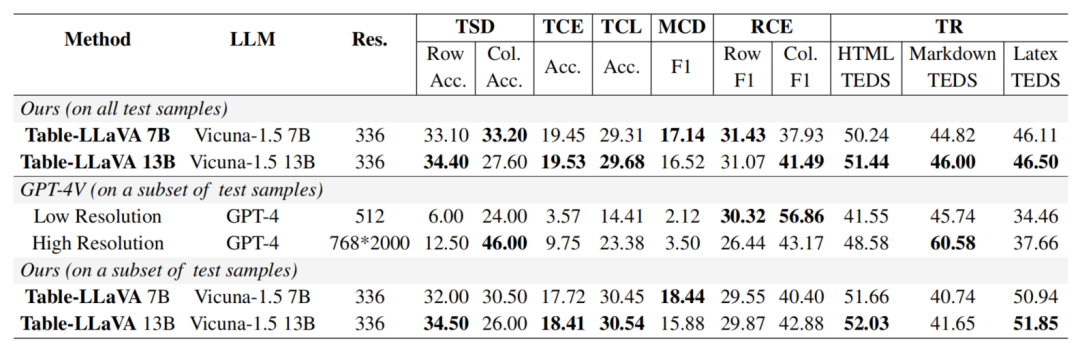
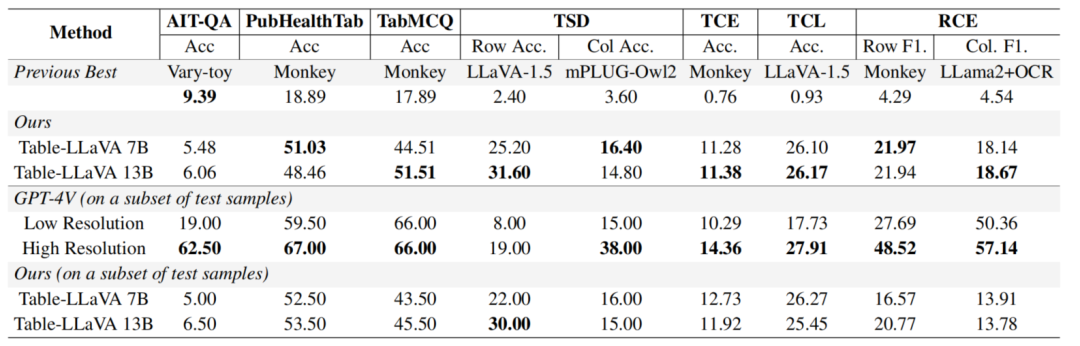
在真实场景任务方面,Table-LLaVA同样表现出色。下表展示了其在6个表格结构理解任务上的性能,这些任务对模型理解表格的基本结构提出了更高要求。结果显示,Table-LLaVA在行列检测、单元格提取、合并单元格识别等任务上大幅领先于其他模型,体现了其优异的表格结构感知能力。
为进一步考察模型的泛化能力,研究者还特意设计了7个未见任务。令人惊喜的是,尽管这些任务的数据域与训练集完全不同,Table-LLaVA依然取得了最佳表现。这有力地展现了其出色的迁移和泛化能力。
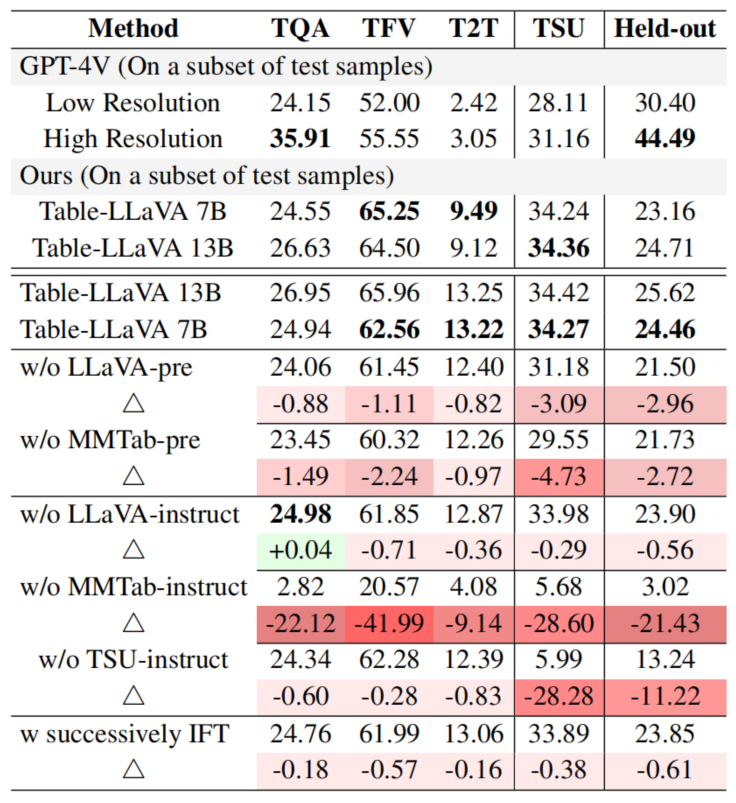
除了以上实验,研究者还进行了详尽的消融研究。结果表明,MMTab数据集对模型性能的提升至关重要,去除MMTab训练数据会导致模型性能大幅下降。同时,不同的训练策略如数据混合方式等,也会对模型性能产生一定影响。这为后续的模型优化提供了重要启示。
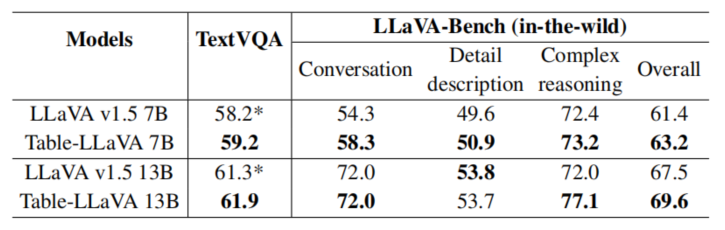
研究者还比较了Table-LLaVA在非表格任务上的表现。结果显示,MMTab数据的加入非但没有削弱模型在非表格任务上的性能,反而起到了促进作用。这表明表格理解能力已经成为多模态大模型的一项基础性、不可或缺的能力。
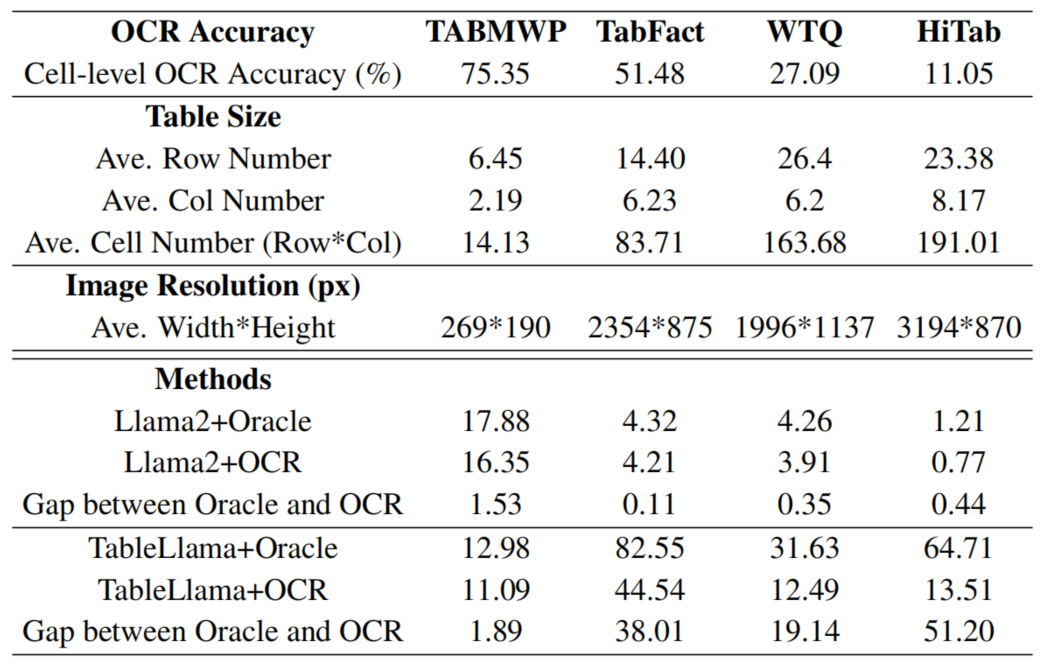
下图展现了输入图像分辨率对模型性能的影响。可以看到,随着图像尺寸的增加,模型性能逐渐下降。这启示我们为了更好地处理超大尺寸的真实表格图像,提高模型的输入分辨率至关重要。这也是未来工作中值得深入探索的方向之一。
综合以上实验结果,Table-LLaVA是一个实力与潜力并存的多模态表格理解"选手"。它在已有的公开数据集上取得了优异的成绩,展现了非凡的实力。同时,其在未见任务和真实场景中的出色表现,也凸显了其巨大的发展潜力。
总结与展望
Table-LLaVA的提出,标志着多模态表格理解研究迈出了关键的一步。基于MMTab数据集,它在各项表格理解任务上取得了瞩目的成绩,展现了巨大的潜力。
然而这只是一个开始。未来,扩大数据集规模、优化模型性能、拓展现实应用场景,以及与知识图谱等技术的结合,都是值得深入探索的方向。
多模态表格理解必将在未来的人工智能发展中扮演越来越重要的角色,有望极大地提升信息处理的智能化水平,为各行各业带来变革。这场"多模态表格理解"的新征程才刚刚开启。



