
- 110分钟实现dotnet程序在linux下的持续部署_dotnet linux
- 2微博高并发场景下的分布式缓存架构_请求漂移
- 3人工智能(AI)、机器学习、深度学习 的关系_机器学习 深度学习 ai
- 42024年高职云计算实验室建设及云计算实训平台整体解决方案
- 5互联网大厂需要什么样的人才
- 6mac 关闭sip 保护系统_chmod: unable to change file mode on jetbrains.vmo
- 7Zookeeper 的 Leader 选举
- 8python的JSON用法——dumps的各种参数用法(详细)_json.dump()方法
- 9docker privileged作用_docker总结
- 10ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory解决方案
Dify中创建知识库操作和实现过程_dify 教程
赞
踩
一.创建知识库操作
选择知识库选项卡,然后点击创建知识库。

1.方式一:先创建知识库,然后上传文件
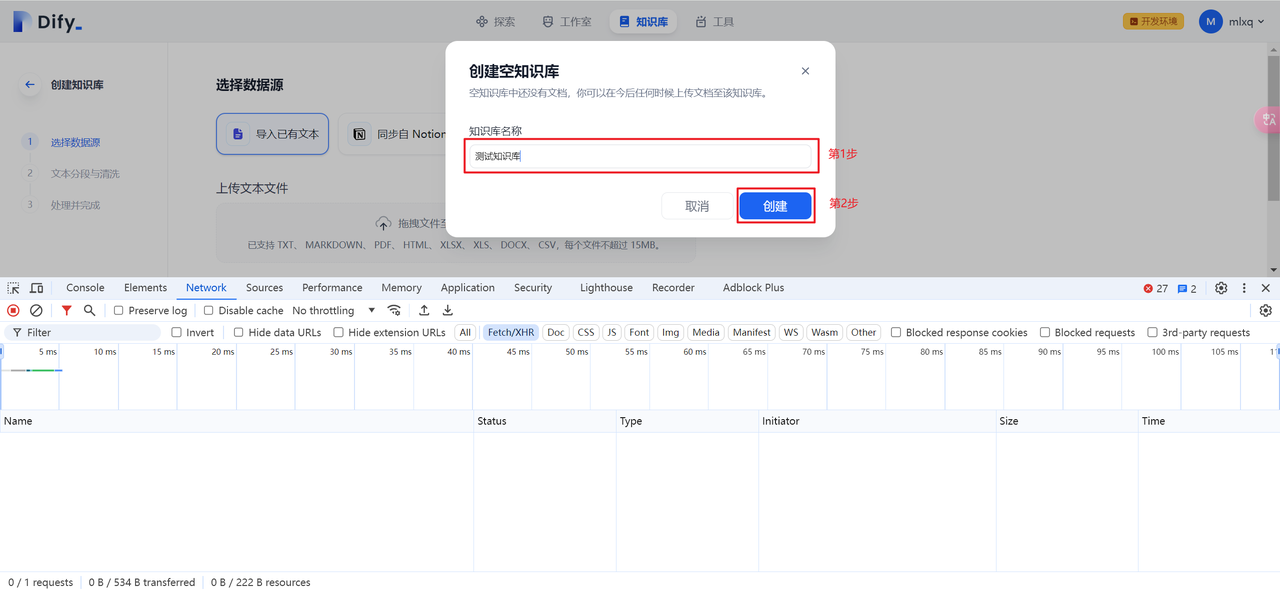
创建一个空知识库。

输入知识库名称,然后创建。
2.方式二:直接上传文件,然后创建默认知识库
除此之外也可以直接上传文本文件,然后系统会创建一个默认知识库。直接上传"QA文档.txt"后会自动创建默认知识库名称和知识库描述等信息:


二.创建知识库实现
1.方式一:先创建知识库,然后上传文件
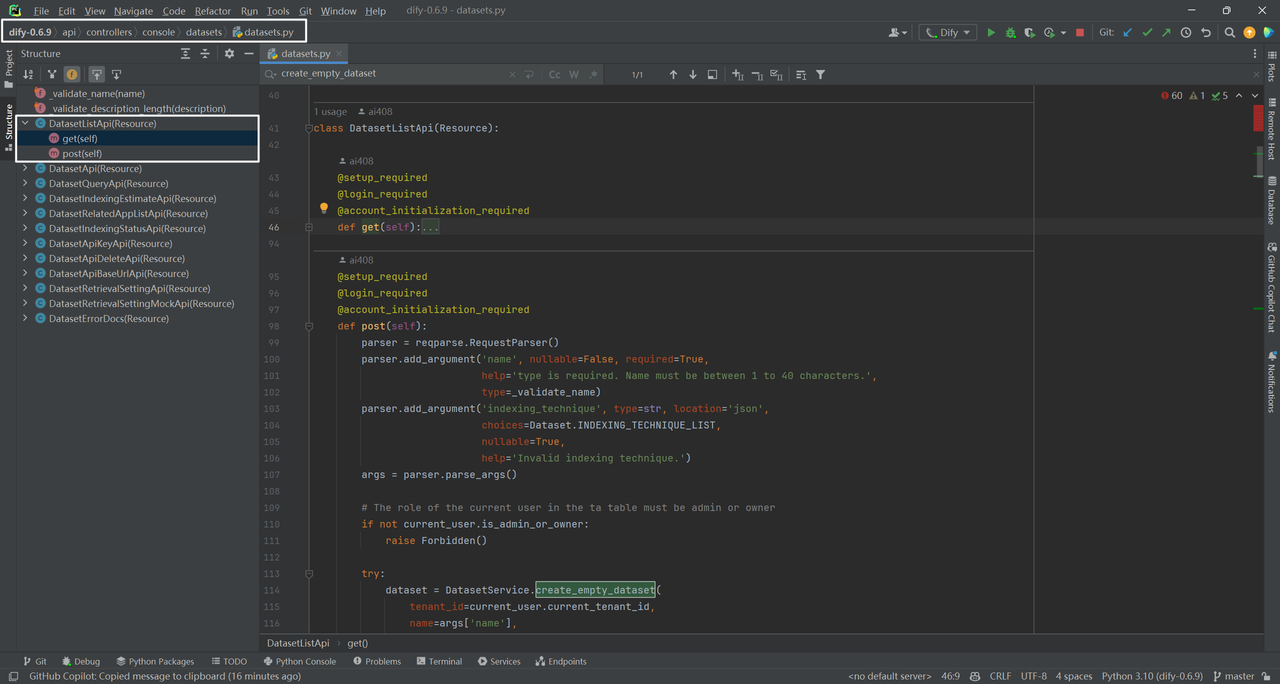
创建空白知识库的post方法:
class DatasetListApi(Resource):
@setup_required
@login_required
@account_initialization_required
def get(self):
......
return response, 200
@setup_required # 确保系统已经初始化
@login_required # 确保用户已经登录
@account_initialization_required # 确保用户已经初始化
def post(self):
parser = reqparse.RequestParser() # 创建请求参数解析器
parser.add_argument('name', nullable=False, required=True,
help='type is required. Name must be between 1 to 40 characters.',
type=_validate_name) # 添加请求参数
parser.add_argument('indexing_technique', type=str, location='json',
choices=Dataset.INDEXING_TECHNIQUE_LIST,
nullable=True,
help='Invalid indexing technique.') # 添加请求参数
args = parser.parse_args() # 解析请求参数
# The role of the current user in the ta table must be admin or owner
if not current_user.is_admin_or_owner:
raise Forbidden()
try:
dataset = DatasetService.create_empty_dataset( # 创建空白知识库
tenant_id=current_user.current_tenant_id, # 租户ID
name=args['name'], # 名称
indexing_technique=args['indexing_technique'], # 索引技术
account=current_user # 用户
)
except services.errors.dataset.DatasetNameDuplicateError: # 数据集名称重复
raise DatasetNameDuplicateError() # 数据集名称重复错误
return marshal(dataset, dataset_detail_fields), 201 # 返回数据集详情
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
调用http://localhost:5001/console/api/datasets接口:
{
"id": "cbd8a746-a9ab-4d79-8337-99d4ac989691",
"name": "\u6d4b\u8bd5\u77e5\u8bc6\u5e93",
"description": null,
"provider": "vendor",
"permission": "only_me",
"data_source_type": null,
"indexing_technique": null,
"app_count": 0,
"document_count": 0,
"word_count": 0,
"created_by": "c17d706d-6418-4ca0-9ba5-34b43bb7e32c",
"created_at": 1719337063,
"updated_by": "c17d706d-6418-4ca0-9ba5-34b43bb7e32c",
"updated_at": 1719337063,
"embedding_model": null,
"embedding_model_provider": null,
"embedding_available": null,
"retrieval_model_dict": {
"search_method": "semantic_search",
"reranking_enable": false,
"reranking_model": {
"reranking_provider_name": "",
"reranking_model_name": ""
},
"top_k": 2,
"score_threshold_enabled": false,
"score_threshold": null
},
"tags": []
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
实际调用的create_empty_dataset方法:
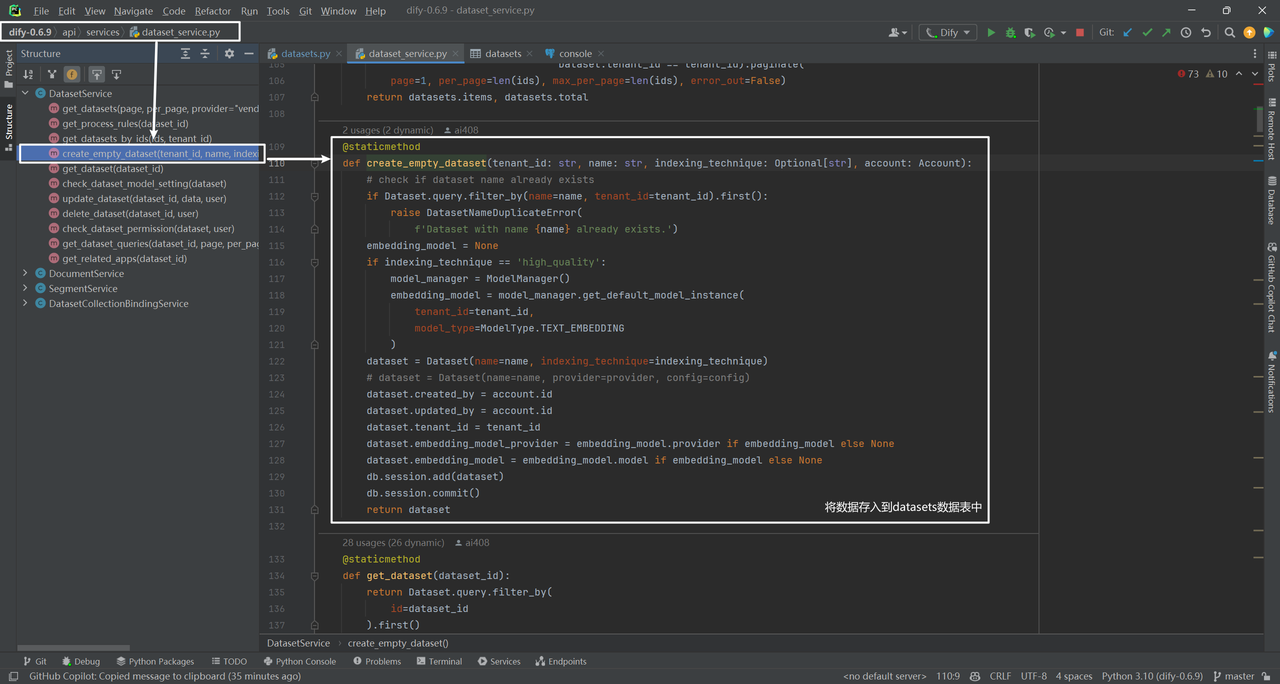
创建空白知识库中,数据存入数据表datasets中。
2.方式二:直接上传文件,然后创建默认知识库
(1)save_document_without_dataset_id
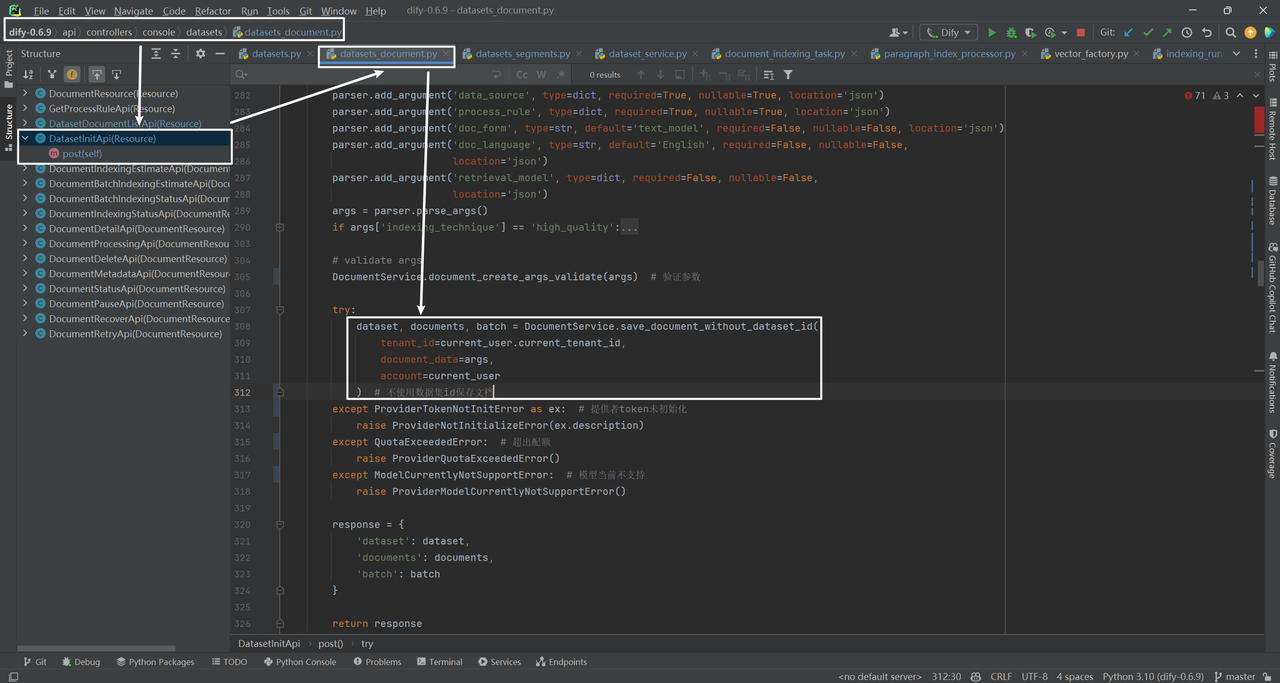
DatasetInitApi类是一个资源类,它继承自Resource类。在这个类中,定义了一个post方法,这个方法对应HTTP的POST请求。
post方法的主要功能是初始化一个数据集。首先检查用户是否已经设置、登录并完成了初始化。然后,它会检查用户是否有足够的权限来创建一个新的向量空间。
在post方法中,首先通过reqparse.RequestParser()解析请求中的参数,包括索引技术(indexing_technique)、数据源(data_source)、处理规则(process_rule)、文档形式(doc_form)、文档语言(doc_language)和检索模型(retrieval_model)。
如果索引技术是’high_quality’,则会尝试获取默认的嵌入模型实例。如果获取失败,会抛出相应的错误。然后,它会验证请求参数是否有效。如果参数有效,它会调用DocumentService.save_document_without_dataset_id方法来创建一个新的数据集并在其中保存文档。
最后,它会返回一个包含新创建的数据集、文档和批次信息的响应。

save_document_without_dataset_id方法的主要功能是在没有给定数据集ID的情况下保存文档。这个方法主要用于创建一个新的数据集,并在其中保存文档,返回新创建的数据集、保存的文档和批次信息。以下是该方法的主要步骤:
首先,它会检查是否启用了计费功能。如果启用了计费,它会计算上传的文档数量,并检查是否超过了批量上传的限制或者文档上传的配额。
如果文档的索引技术是’high_quality’,它会尝试获取默认的嵌入模型实例,并获取数据集集合绑定和检索模型。
然后,它会创建一个新的数据集,包括租户ID、数据源类型、索引技术、创建者、嵌入模型、嵌入模型提供者、集合绑定ID和检索模型等信息。
接着,它会调用save_document_with_dataset_id方法来在新创建的数据集中保存文档。
最后,它会更新数据集的名称和描述,并提交数据库事务。
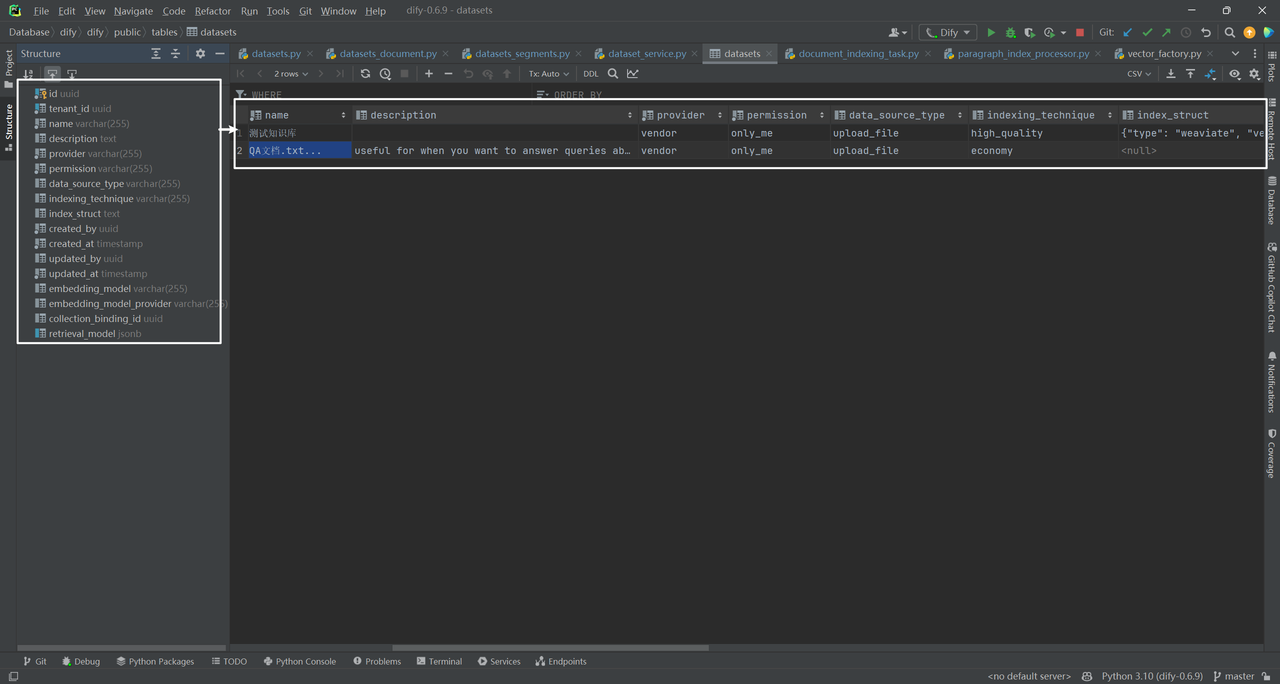
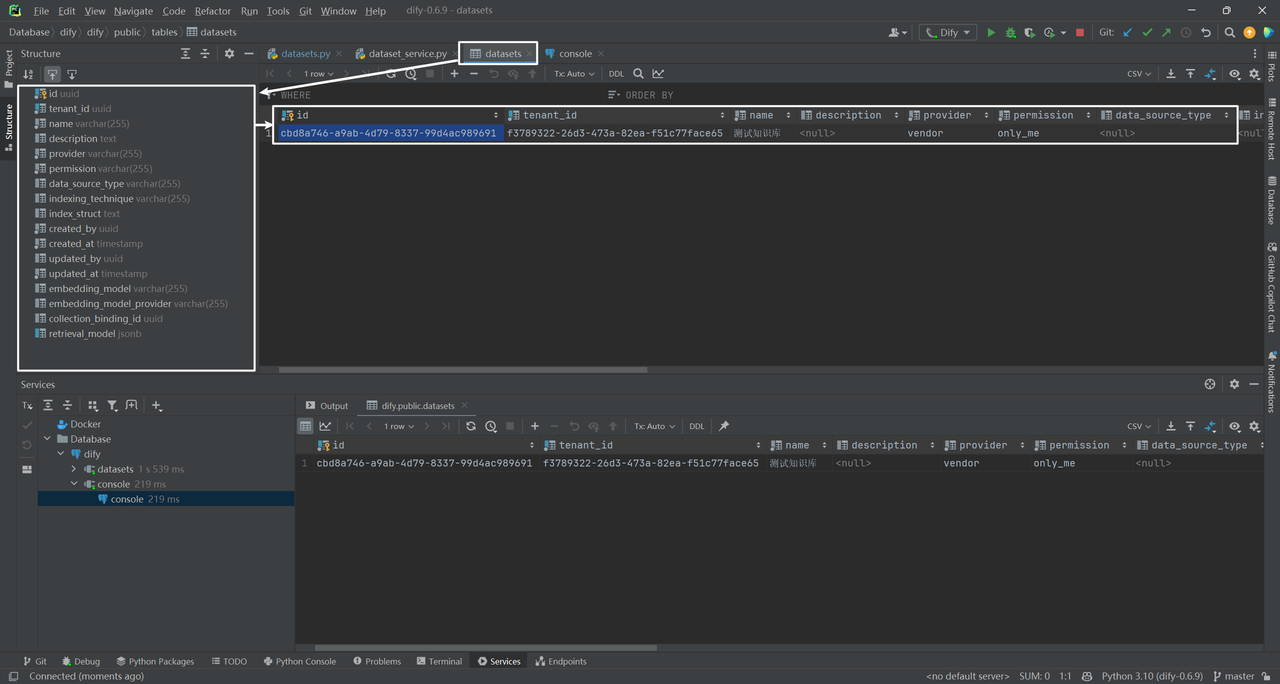
以上是在datasets数据表中插入的一条知识库记录。
(2)save_document_with_dataset_id
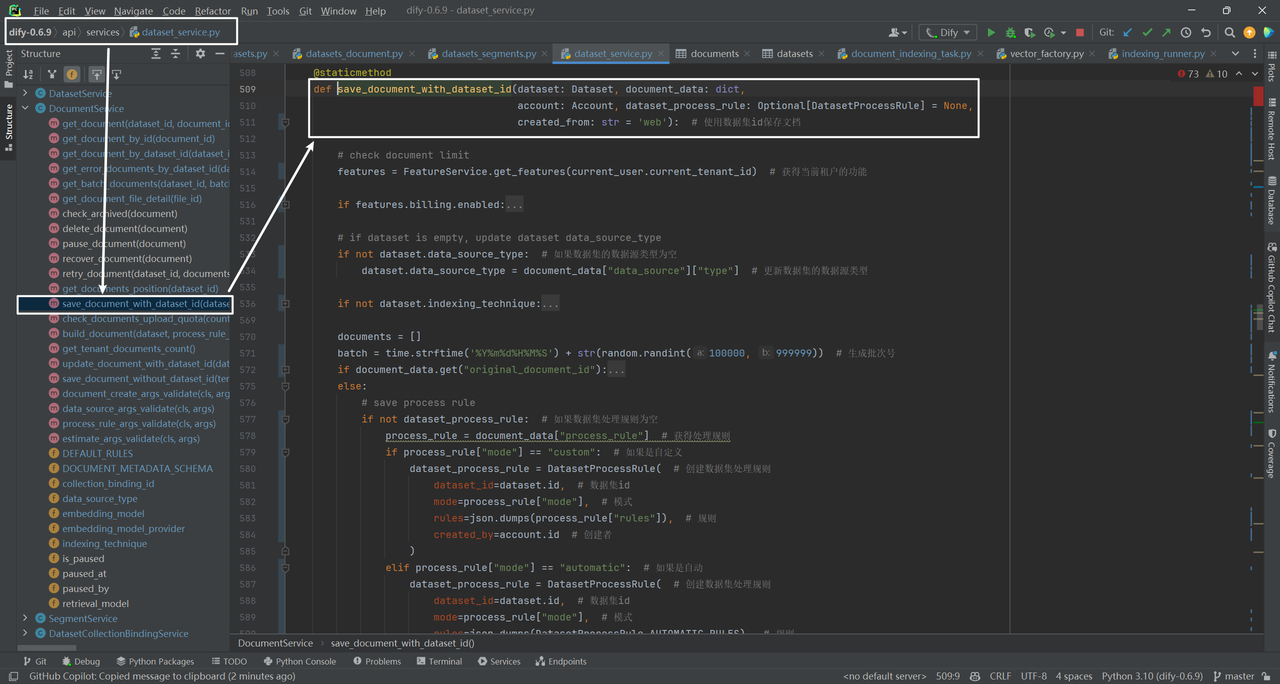
通过调试得到document_data一个示例数据如下所示:
{
'indexing_technique': 'high_quality',
'data_source': {
'type': 'upload_file',
'info_list': {
'data_source_type': 'upload_file',
'file_info_list': {
'file_ids': ['6f393937-d0ec-41b3-a6cb-56f38081eb94']
}
}
},
'process_rule': {
'rules': {},
'mode': 'automatic'
},
'duplicate': True,
'original_document_id': None,
'doc_form': 'text_model',
'doc_language': 'Chinese',
'retrieval_model': {
'search_method': 'semantic_search',
'reranking_enable': False,
'reranking_model': {
'reranking_provider_name': '',
'reranking_model_name': ''
},
'top_k': 2,
'score_threshold_enabled': False,
'score_threshold': None
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
save_document_with_dataset_id方法的主要功能是在给定数据集ID的情况下保存文档。这个方法主要用于在已存在的数据集中创建或更新文档,返回保存的文档和批次信息。以下是该方法的主要步骤:
首先,它会检查是否启用了计费功能。如果启用了计费,它会计算上传的文档数量,并检查是否超过了批量上传的限制或者文档上传的配额。
如果数据集是空的,它会更新数据集的数据源类型和索引技术。
如果是更新文档,它会调用update_document_with_dataset_id方法来更新文档。如果是新建文档,它会保存处理规则,然后根据数据源类型(如上传文件或导入notion)创建文档。
最后,它会触发异步任务来处理文档索引。
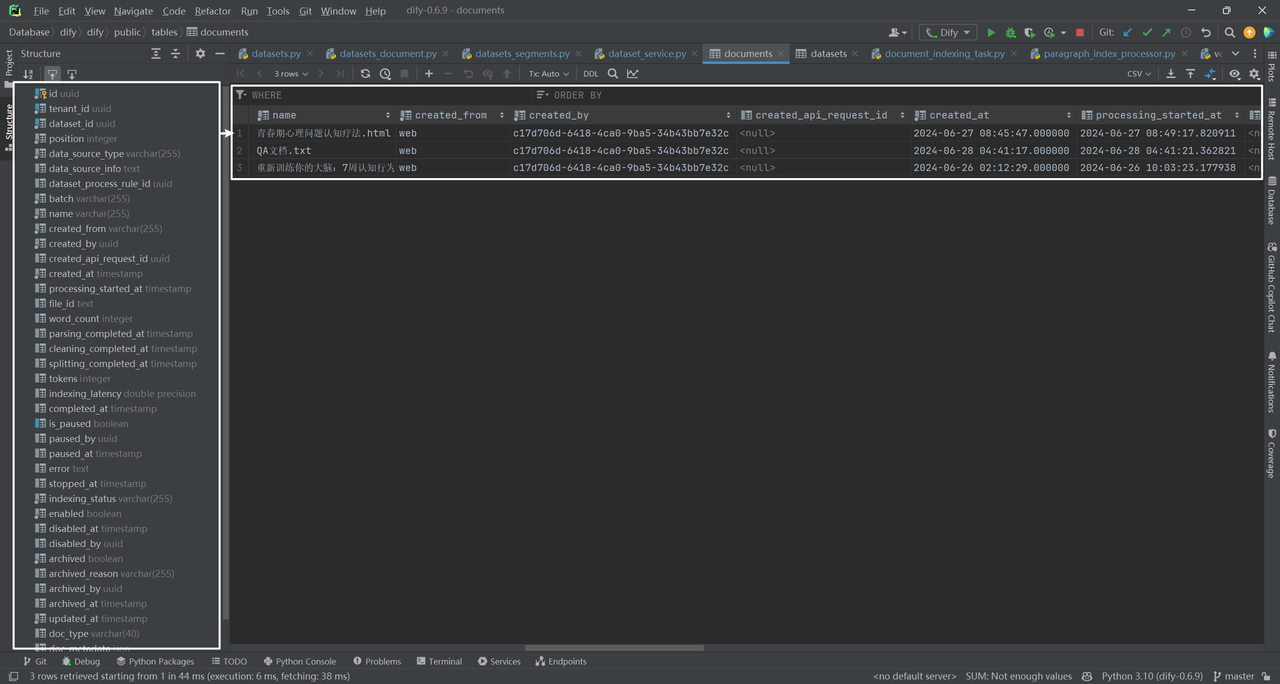
以上是在documents数据表中插入的一条文件记录。
三.知识库文档操作
在知识库中添加文档:

数据源可以是导入已有文本,同步自Notion内容,同步自Web站点(暂未实现)。文档类型已支持 TXT、 MARKDOWN、 PDF、 HTML、 XLSX、 XLS、 DOCX、 CSV,每个文档不超过 15MB。

上传文档后,可以分段设置、索引方式、检索设置。分段设置包括自动分段与清洗和自定义2种情况。索引方式包括高质量和经济2种情况。检索设置包括向量检索、全文检索和混合检索3种情况。

TopK表示用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整分段数量。Score阈值表示用于设置文本片段筛选的相似度阈值。
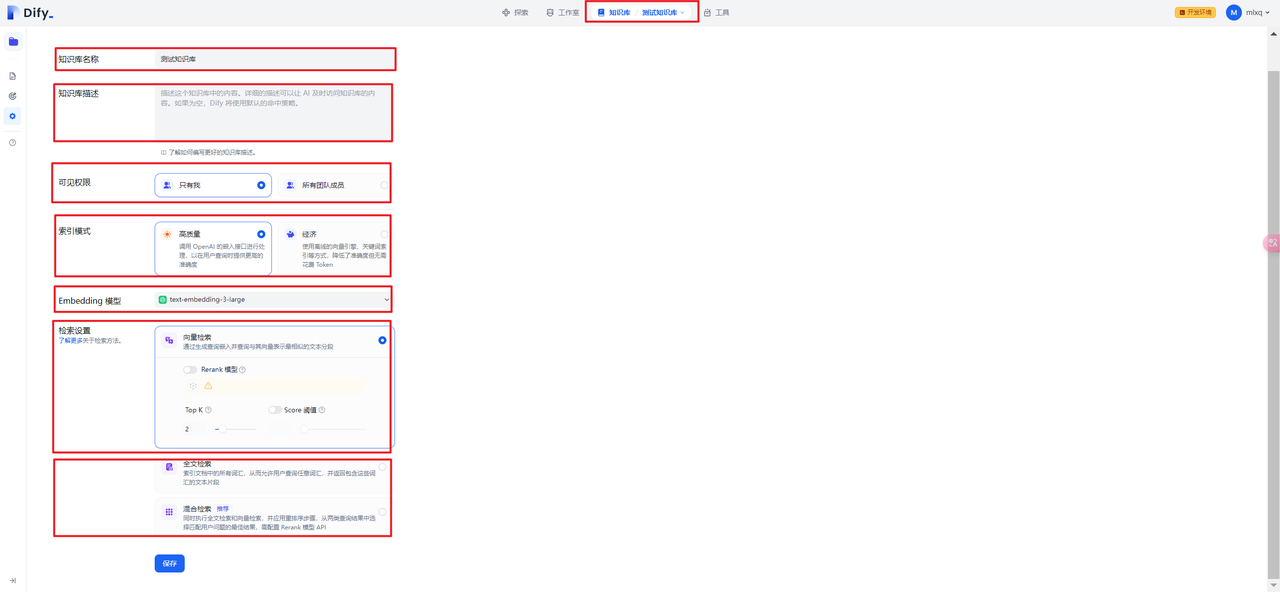
文档上传后就可以进行Embedding处理。

点击"前往文档"可以查看文档的处理信息。

点击文档可查看文档的段落、元数据(需要自行设置)和技术参数信息。
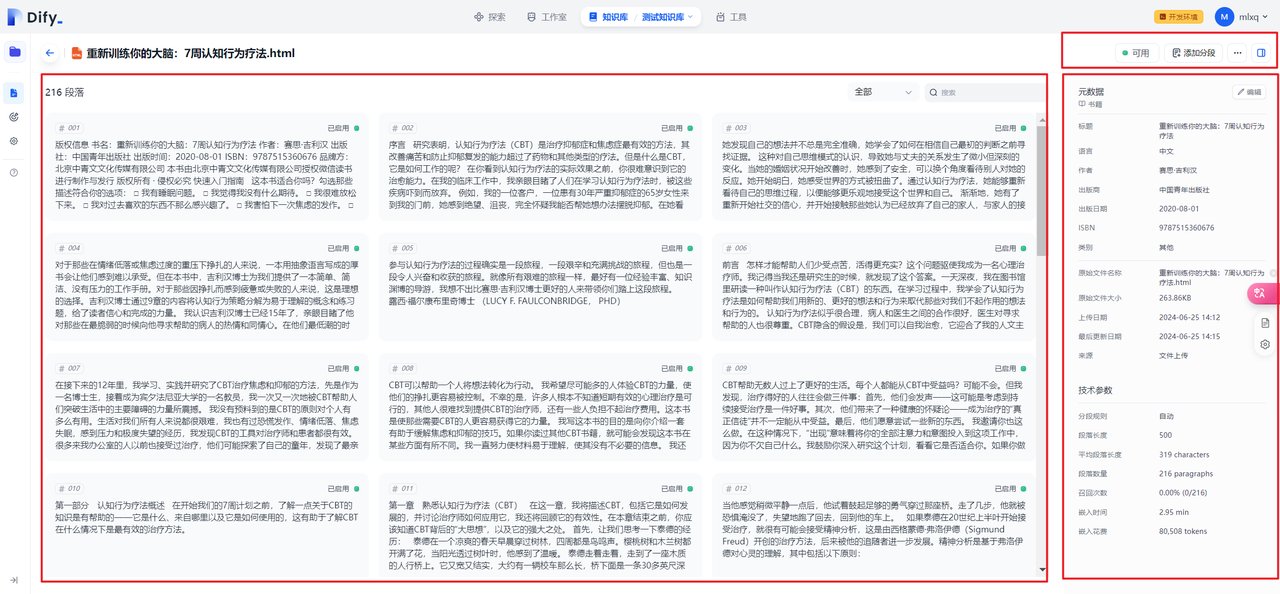
四.上传文档实现
调用接口http://localhost:5001/console/api/files/upload:
{
"id": "d0bd9b1e-49f4-4bfa-ac7f-24e5d9ac1030",
"name": "疲劳自救手册:用认知行为疗法找回元气满满的自己.html",
"size": 292535, # 0.28MB
"extension": "html",
"mime_type": "text/html",
"created_by": "c17d706d-6418-4ca0-9ba5-34b43bb7e32c",
"created_at": 1719341969
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
源码位置:dify\api\controllers\console\datasets\file.py
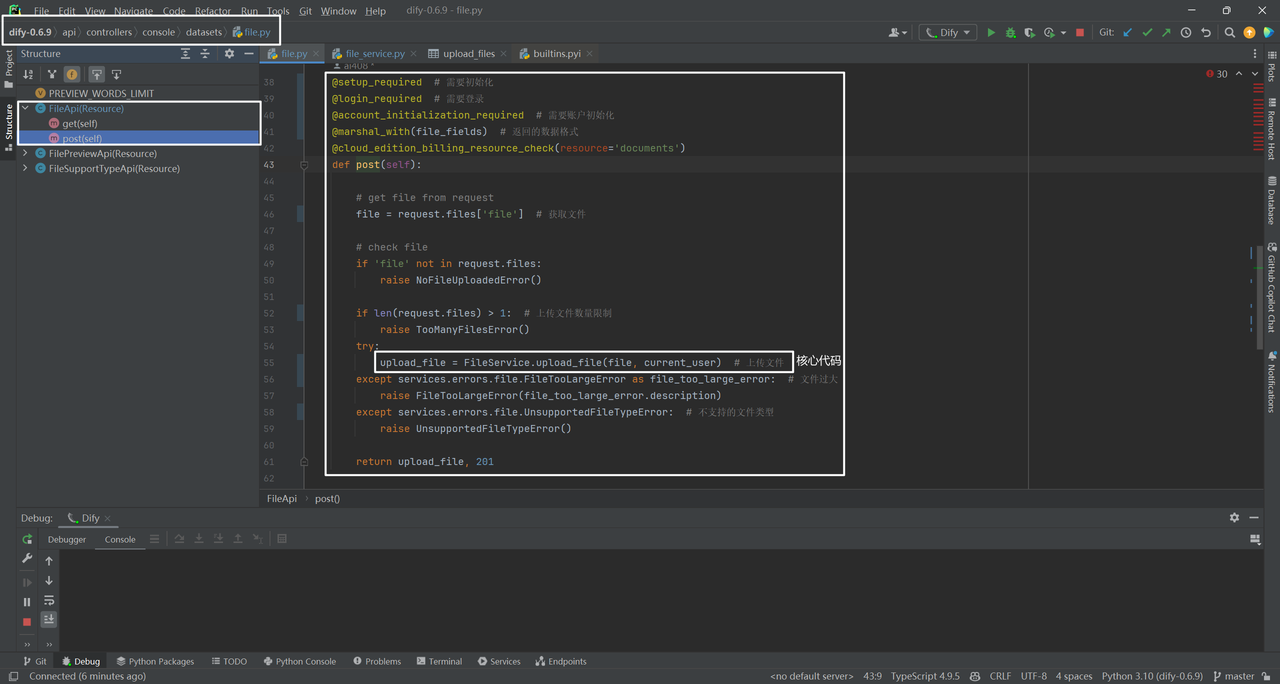
源码位置:dify\api\services\file_service.py

存储到数据表upload_files中的记录如下:
id:d0bd9b1e-49f4-4bfa-ac7f-24e5d9ac1030
tenant_id:f3789322-26d3-473a-82ea-f51c77face65
storage_type:local
key:upload_files/f3789322-26d3-473a-82ea-f51c77face65/4e7b05eb-fa25-48ec-ae37-9088cb265e64.html
name:疲劳自救手册:用认知行为疗法找回元气满满的自己.html
size:292535
extension:html
mime_type:text/html
created_by:c17d706d-6418-4ca0-9ba5-34b43bb7e32c
created_at:2024-06-26 02:59:29.144151
used:false
used_by:
used_at:
hash:d6c38b0743dd6edfa95dac39fed49f4b8e75e79ee8bc47617b1f1e8b519d3d7f
created_by_role:account
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

