
- 1AI大模型时代,如何与大模型交流(Prompt)?应用实战告诉你!_prompt在ai领域的应用解析
- 2Hive优化的十大方法
- 3在MacOS中制作通义千问14B大模型的容器镜像_mac 搭建通义千问
- 4利用ESP32-C3将TF卡内容变成U盘进行读取_esp32 u盘
- 5Linux系统安装配置与使用_linux 操作系统服务器 的常用服务和应用的安装与配 置
- 6Python实现根据评论评分信息预测 (协同过滤,LFM,词向量)_评论预测评分代码
- 7发消息就用消息队列——kafka、rocketMQ(一)_消息队列的应用场景rockmq,kfaka
- 8Google的Apache Beam是什么_google beam
- 9Android应用开发学习笔记_下列选项中,()模式会判断要启动的activity实例是否位于栈顶,如果位于栈顶则直接复
- 10pritunl 和 JumpServer_pritunl客户端下载
Transformer 解析 超级详细版_transformer csdn
赞
踩
推荐学习视频
汉语自然语言处理-从零解读碾压循环神经网络的transformer模型(一)- 注意力机制-位置编码-attention is all you need_哔哩哔哩_bilibili
目录
1.positional \ encoding, 即位置嵌入(或位置编码);
transformer是谷歌大脑在2017年底发表的论文attention is all you need中所提出的seq2seq模型. 现在已经取得了大范围的应用和扩展, 而BERT就是从transformer中衍生出来的预训练语言模型.
应用:上游应用(训练一个预训练语言模型) 下游任务 (情感分析、分类、机器翻译)
首先下transformer和LSTM的最大区别是什么?
LSTM的训练是迭代的, 是一个接一个字的来, 当前这个字过完LSTM单元, 才可以进下一个字, 而transformer的训练是并行, 就是所有字是全部同时训练的, 这样就大大加快了计算效率,
输入的时间序列关系怎么确定呢?
transformer使用了位置嵌入来理解语言的顺序, 使用自注意力机制和全连接层来进行计算
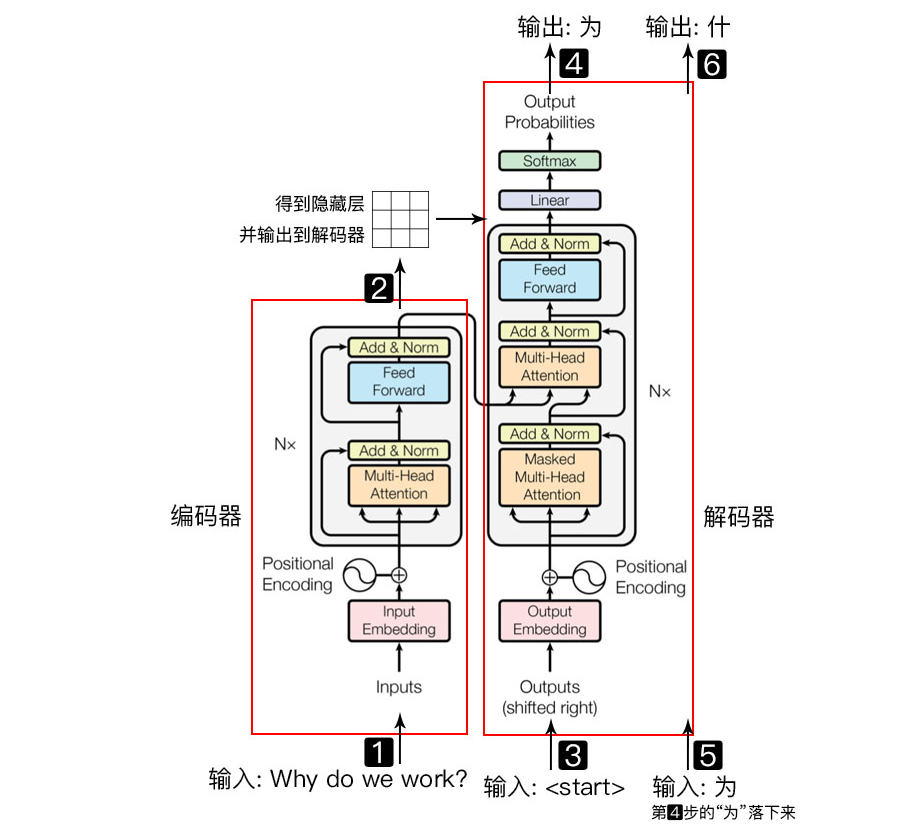
完成机器翻译的流程
句子输入进编码器 得到隐藏层输出 与start 开始符一起再输入到解码器 得到输出“为”,“为”和下一个编码器的输出隐藏层一起输入到解码器得到输出“什” 直到模型翻译结束
1.positional \ encoding, 即位置嵌入(或位置编码);
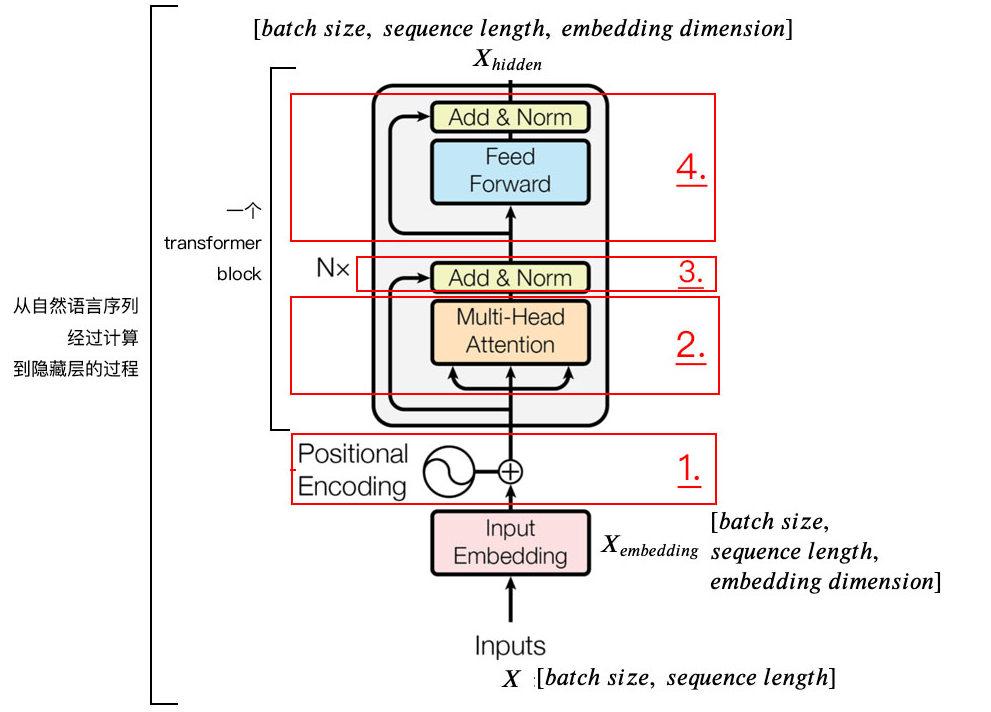
由于transformer模型没有循环神经网络的迭代操作, 所以我们必须提供每个字的位置信息给transformer, 才能识别出语言中的顺序关系

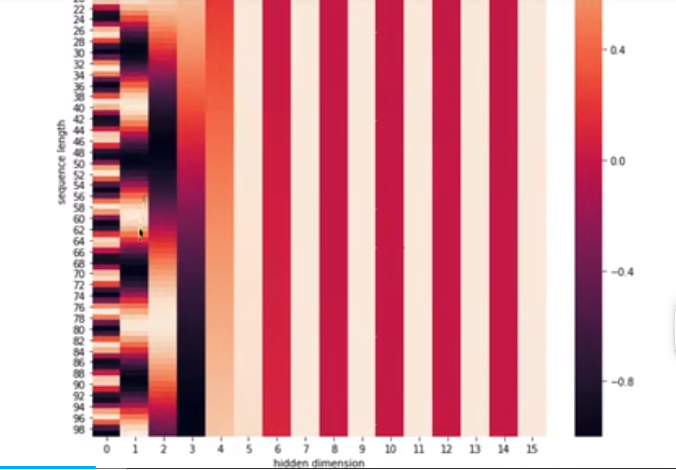
位置嵌入的维度和字向量的维度是一样的,可以直接元素相加
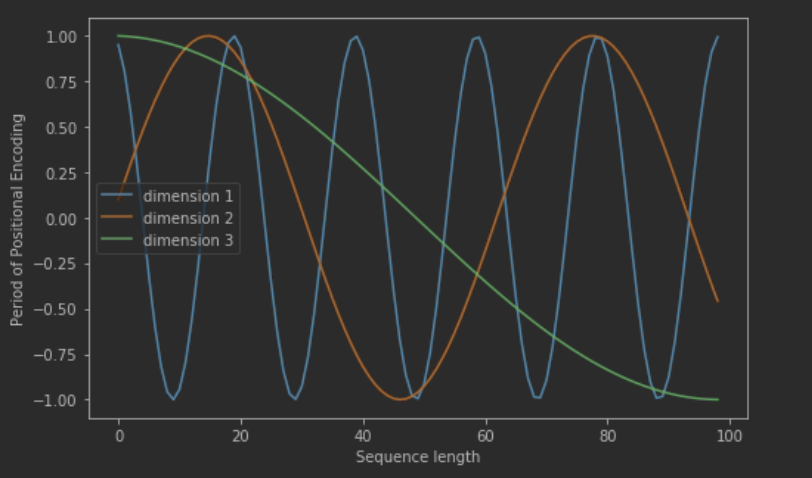
奇数偶数 使用不同的编码方式,
在时间维度(句子长度维度)产生一种独特的纹理信息使得模型能够区分出时间序列关系
2 自注意力机制

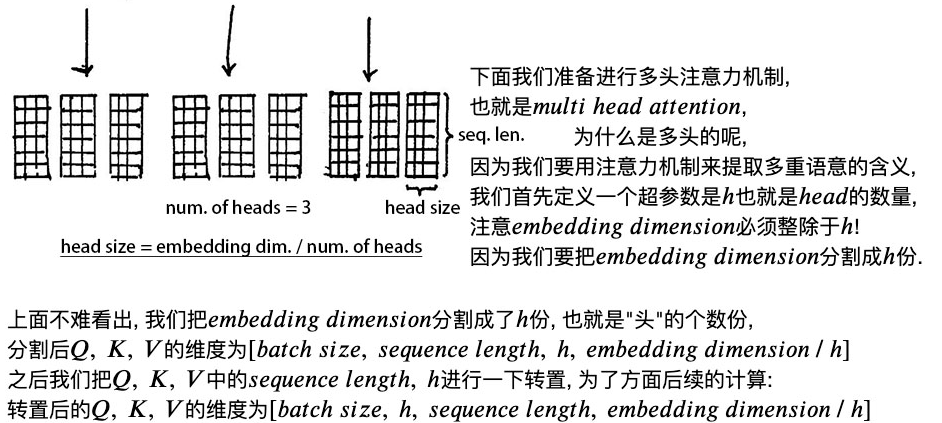

点积的意义:两个向量之间的相似度 越相似 点积越大
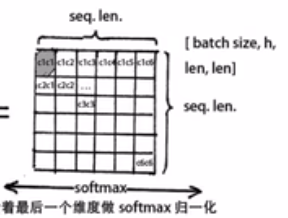
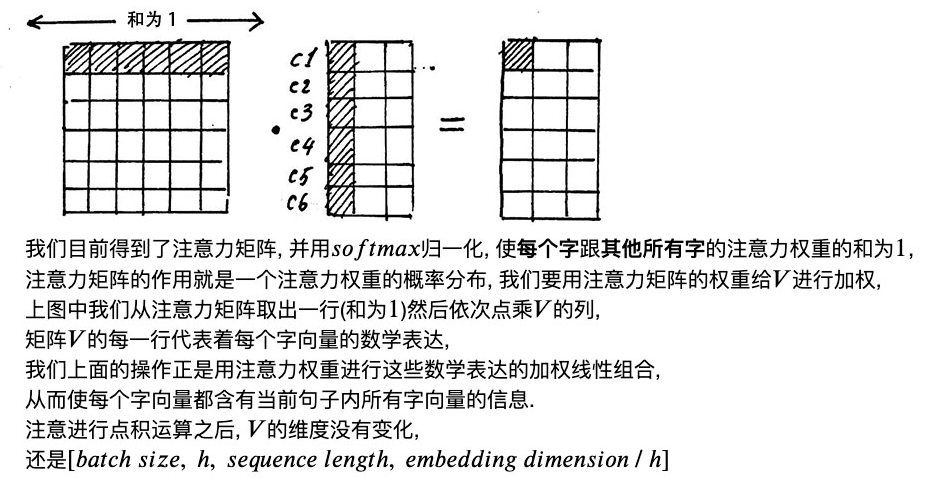
Q*KT 得到的是当前字和其他所有字的联系,第一行 c1和其他字的相关程度,
然后沿列的维度做归一化softmax 让相关程度 之和变为一
当前字和其他所字的关系和为1
在沿列的维度做归一化softmax之前要除以 根号dk why?
假设 q 和 k 的组件是均值为 0 和方差为 1 的自变量。那么它们的点积 q · k = ∑dki=1 qiki 的均值为 0 和方差 dk。QK 的点积相当于放大了dk 倍,把注意力矩阵 缩放回原来的分布,还有一个原因是避免因为softmax 计算的值过大 或者过小,导致出现接近0 1 的不均匀分布
归一化后的注意力矩阵和V加权 ,让所有字的信息 融入到当前字中,让每一个字含有当前句子中所有的信息,attention机制其实使用这句话中所有字来表达句子中的一个字
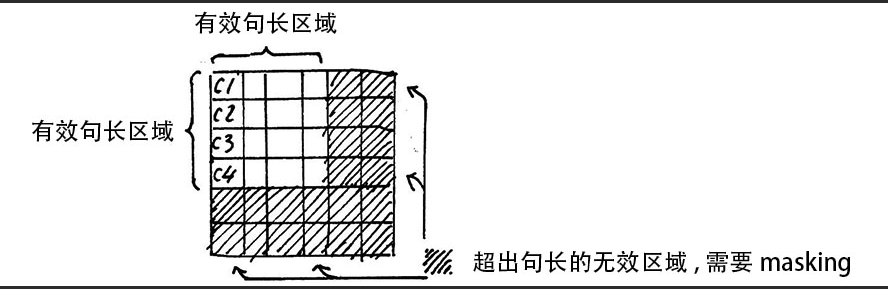
Attention Mask
要给无效的区域加一个 很大的负数 偏置 似的进行 softmaix之后 无效的区域结果还是0

3. layernorm和残差连接.

加快训练 加快收敛
4.整体结构. 

GitHub - aespresso/a_journey_into_math_of_ml: 汉语自然语言处理视频教程-开源学习资料

