- 1Mac 上的新利器-Visual Studio Code_visual studio code mac暗转
- 22023年的深度学习入门指南(22) - 百川大模型13B的运行及量化_百川13b需要多少显存
- 3SpringBoot+JPA数据源配置&解决springboot2.1.x之后jpaProperties报错的问题_jpaproperties.gethibernateproperties
- 4C语言字符数组的输入输出处理_c输出char数组
- 5adb无法连接夜神模拟器处理以及文件传输_adb文件传输 传不进去
- 6Linux - find命令详解_find -exec命令 linux
- 7spring data jpa repository一套代码兼容多种数据库_java 封装repository适配多种数据库
- 8git在Visual Studio Code如何使用以及git stash的使用_visual studio code git
- 9排序算法浅谈_public int[] sort(int[] sourcearray) throws except
- 10Dockerfile之优化经验浅谈
Flink IDEA项目创建_fflink idea provide
赞
踩
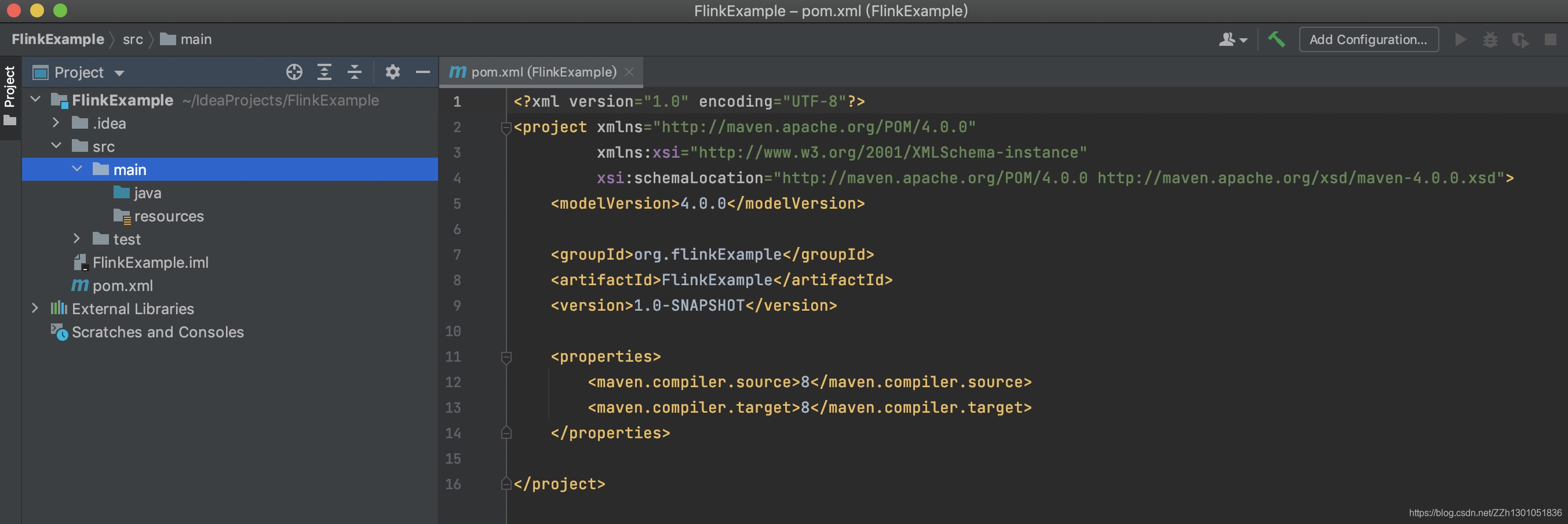
1 创建maven项目
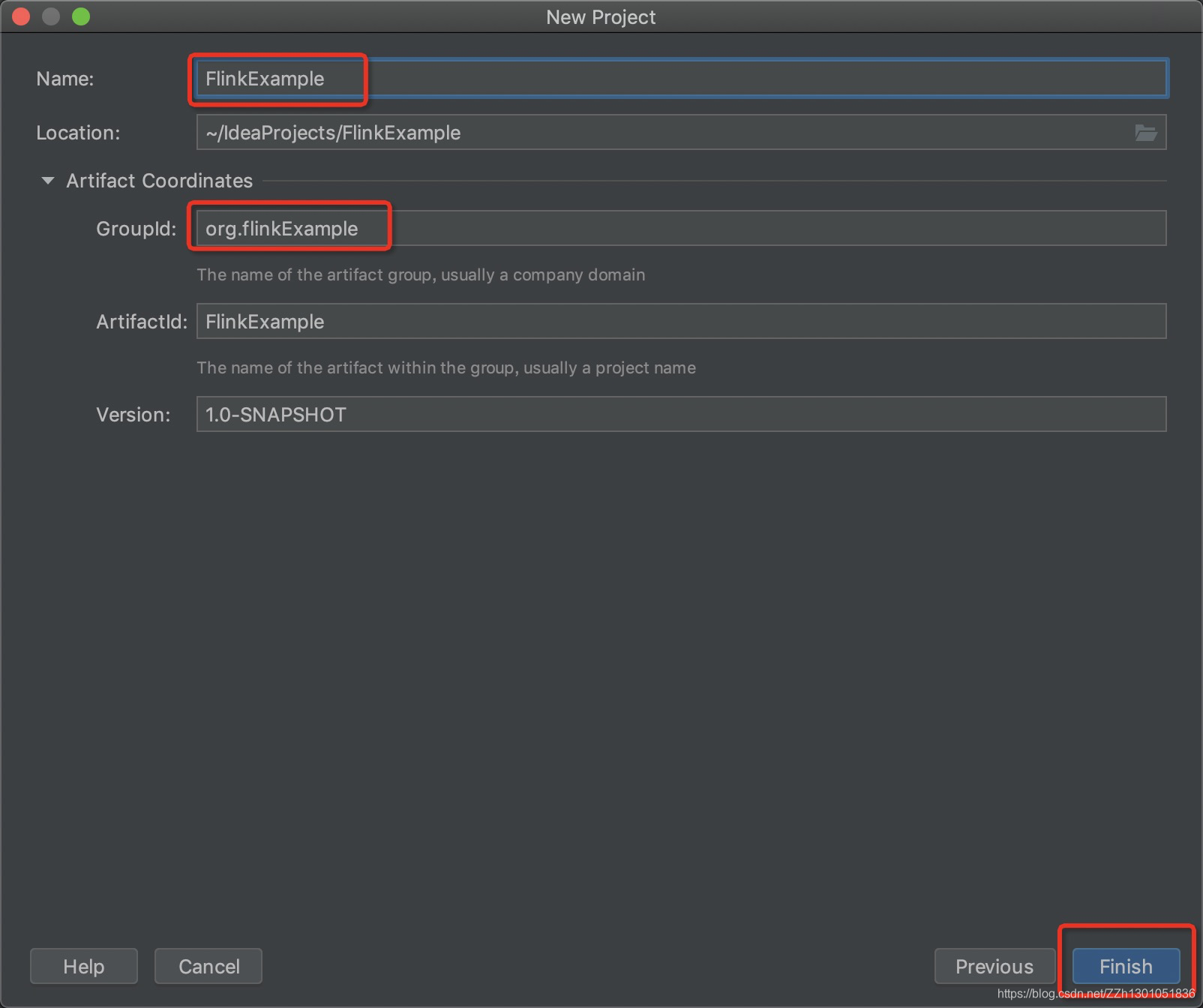
创建完成后,项目结构如下图所示:
2 添加最低限度的API依赖
开发Flink程序需要最低限度的API依赖,最低的依赖库包括flink-scala,flink-Streaming-scala。大多数应用需要依赖其他类库或连接器,例如kafka连接器,TableAPI,CEP库等,这些不是Flink核心依赖库的一部分,因此必须作为依赖项手动添加到应用程序中。
打开Flink官网中的,复制最低依赖项:
https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh/dev/projectsetup/dependencies.html
在pom.xml文件中,建立dependency根结点,并添加最低依赖项,如下。最好不要用x.x.0版本,这是首次发布的,可能不稳定。
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.9.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.9.1</version>
<scope>compile</scope>
</dependency>
</dependencies>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
上面这两个依赖项,在官网中源代码的作用域为provided,即“provided”,这意味着需要这些依赖进行编译,但是不应把他们打包到项目生成的应用程序jar文件中。因为这些依赖项是Flink的核心依赖,在应用启动前已经是可用状态。
若作用域未设置为provided,会出现两个问题:
(1)jar文件过大。
(2)自己新打包进去的Flink依赖项与应用程序中的Flink依赖项冲突。
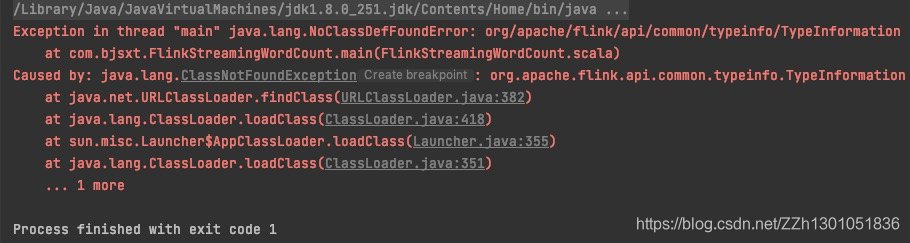
然而,为了在IntelliJ IDEA中运行,这些依赖项的作用域需要设置为compile或runtime或直接删除不限制作用域,否则flink不会添加这些依赖到classpath。运行时报如下错误:
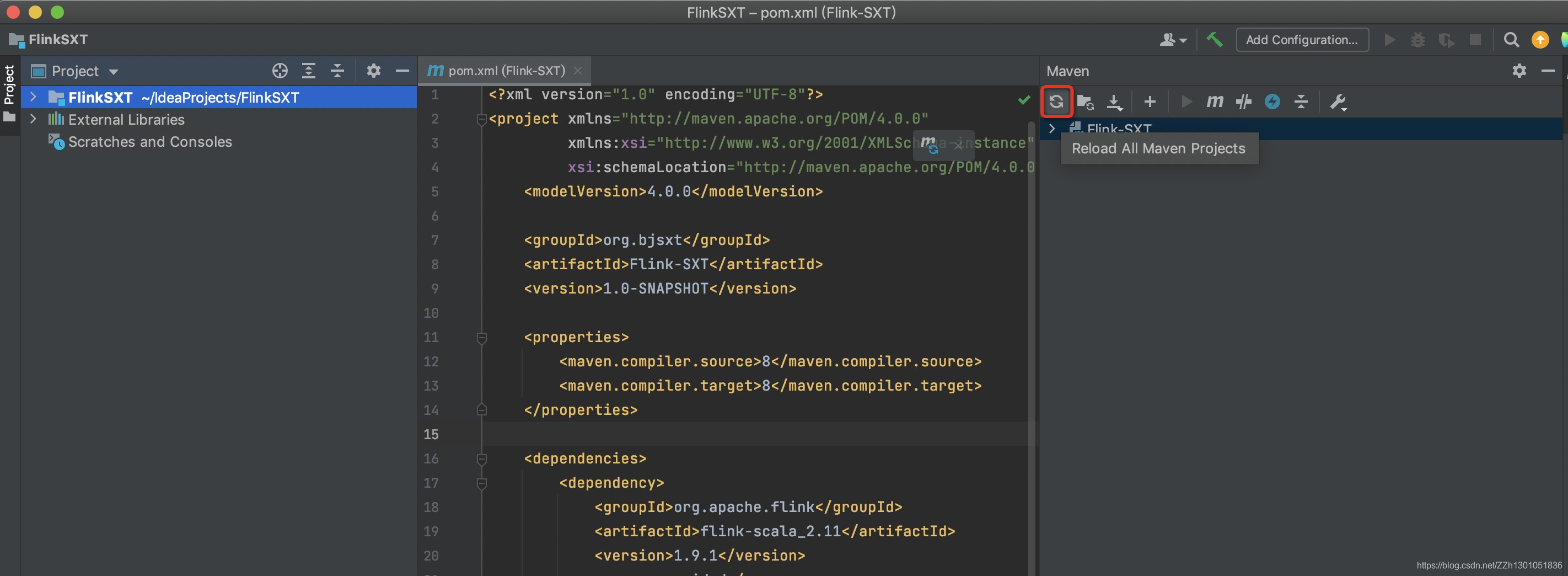
然后,点击Maven中的刷新,下载依赖的包:
3 scala的编译工具和打包工具
<build> <plugins> <!-- 该插件用于将scala代码编译成class文件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.4.6</version> <executions> <execution> <!-- 声明绑定到maven的compile阶段 --> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
4 编程并运行
因为用scala开发,所以将java重命名为scala。
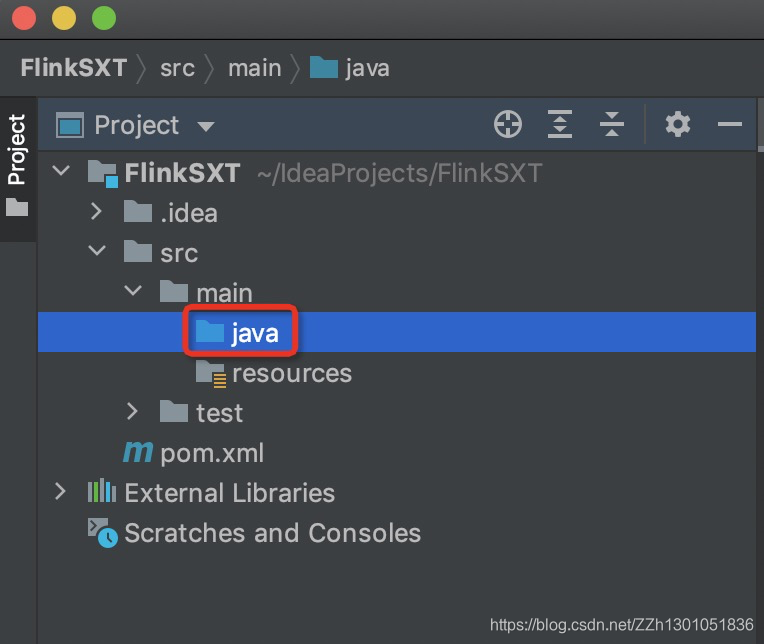
新建一个scala class
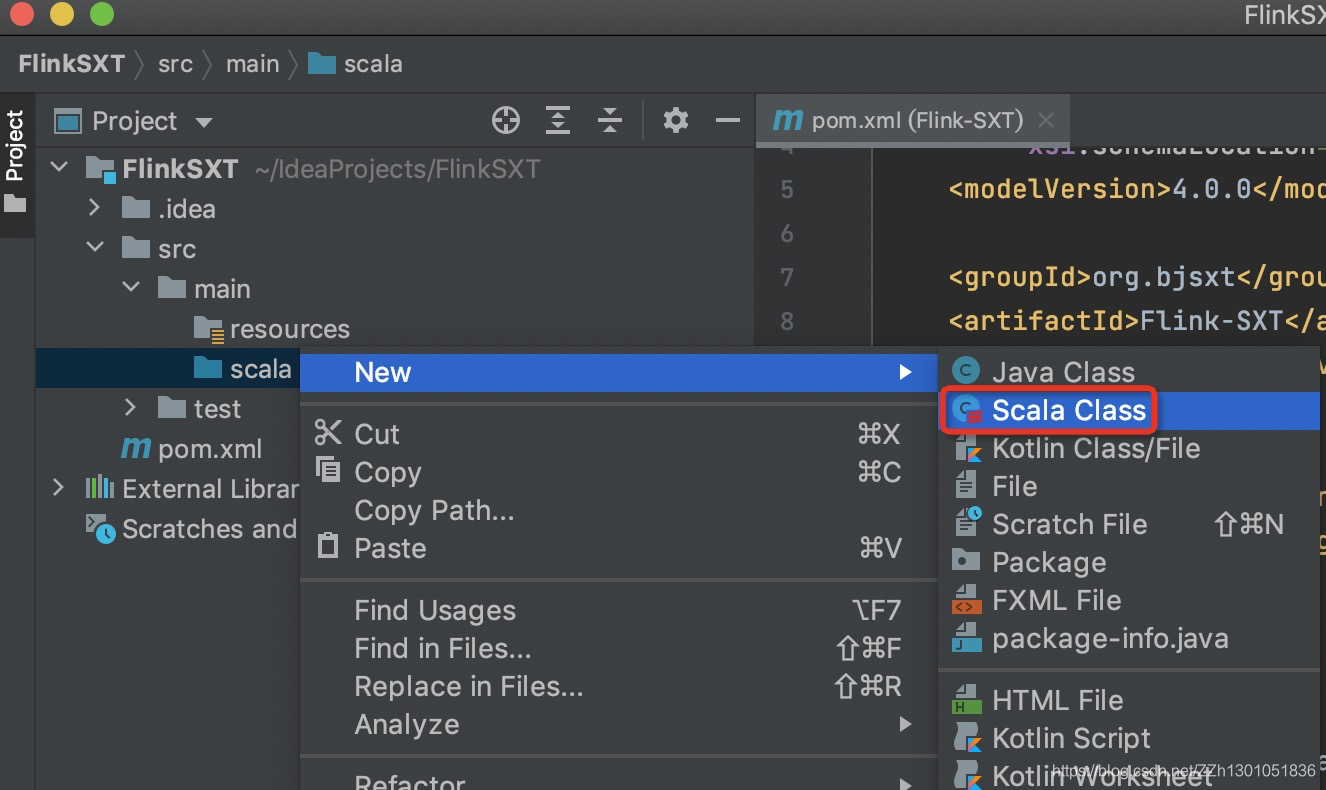
放在包com.bjsxt下,名字叫FlinkStreamingWordCount
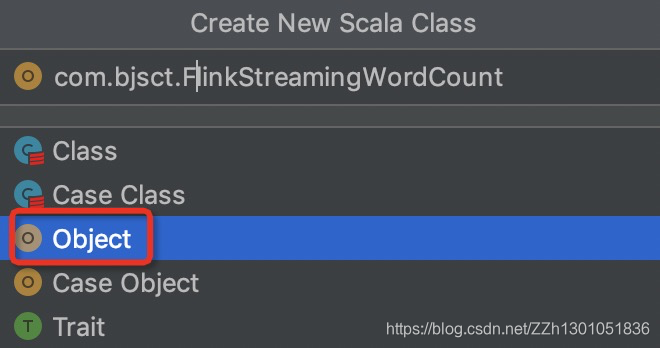
WordCount程序如下:
package com.bjsxt import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment object FlinkStreamingWordCount { def main(args: Array[String]): Unit = { //1、初始化流计算的环境:用于流计算和批计算环境的对象不同 val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment //2、导入隐式转换 import org.apache.flink.streaming.api.scala._ //3、读取数据,读取sock流中的数据,DataStrem等同于Spark中DStream val stream: DataStream[String] = streamEnv.socketTextStream("hadoop01", 8888) //4、转换和处理数据 val result: DataStream[(String, Int)] = stream.flatMap(_.split(" ")) // 以空格分隔,得到单词 .map((_, 1)) //元组中,以单词为键,即下划线,以1为value。 .keyBy(0) // 分组:0或1代表下标,是DataStream[(String, Int)]中二元组的下标。0就代表单词,1代表单词出现的次数 .sum(1) // 求和:聚合累加算子。单词出现的次数,在DataStream[(String, Int)]中二元组的下标是1。 //5、打印结果 result.print("结果") //6、启动流计算程序 streamEnv.execute("wordCount") } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
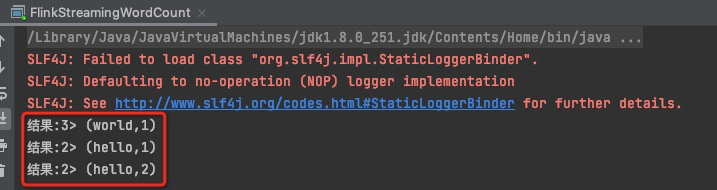
通过终端,进入flink解压缩后的jar包,进入bin目录,通过./start-cluster.sh启动flink集群
然后启动一个本地服务,nc -l 8888,8888是wordcount程序中使用的端口号,
然后运行WordCount程序

然后在终端中输入想统计的字符:
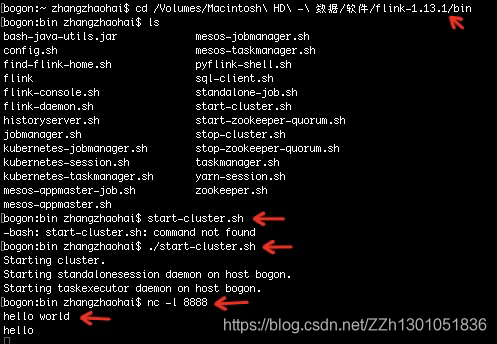
便会实时统计了。