
- 1zookeeper总有节点启动失败_xshell开启zookeeper其余结点打不开
- 2使用objdump objcopy查看与修改符号表_objdump 可执行文件 符号
- 3Spring Boot Jpa 的使用(转载)_springboot jpa使用getconnection
- 4华为薪资等级结构表_2020年华为工资等级对照表
- 5利用java filter 实现业务异常拦截 跳转到错误信息提示页面_拦截器过滤error页面
- 6初步探索GraalVM--云原生时代JVM黑科技_graalvm 动态生成字节码
- 7算法5分钟|如何实现整数的数字反转【首尾交换法】_数字翻转算法
- 8openGauss学习笔记-133 openGauss 数据库运维-例行维护-日维护检查项_opengauss数据库怎么查看锁
- 9阿里云服务器镜像怎么选?操作系统版本选择说明_服务器操作系统选什么知乎
- 10深入浅出 Java 虚拟机 · 通往高级 Java 开发的必经之路_java虚拟机定义
Python 一键提取PDF版论文表格数据_python提取文献pdf表格
赞
踩
在日常工作学习中,我们经常会遇到需要从PDF文件中提取表格数据的需求。今天,就来分享一个能够很好解决这一需求的Python工具库——
Camelot。首先,我们可以看看官方给出效果图(左图为论文的表格,右图为提取结果)


一、Camelot库介绍
1.1 项目地址及安装
Camelot库是由作者vinayak-mehta开发的一个基于Python语言,提取PDF文件中表格数据的工具库,项目地址为:Camelot,安装方式可以通过pip和conda的方式,具体如下所示
| 类型 | 安装命令 |
|---|---|
| Using pip | pip install camelot-py[cv] |
| Using conda | conda install -c conda-forge camelot-py |
1.2 基本参数介绍
Camelot库中主要由read_pdf函数读取PDF文档,其使用方法和参数含义如下所示,更多细节设置可参考官方文档Camelot高级使用参数设置进行学习。
import camelot
tables = camelot.read_pdf('xx.pdf',flavor="stream",pages="1",tables_area=['100,600,600,100'])
tables[0].df #转为data.frame形式
- 1
- 2
- 3
| 参数 | 含义及设置 |
|---|---|
flavor | 表格解析方式,默认lattice,常用stream |
pages | 读取页码,传入类型为字符串,不同页码用逗号分隔(如读取4、5、6页,则设置pages="4,5,6") |
table_areas | 表格定位,默认自动识别表格,传入类型为列表,用于精确定位表格位置 |
注意:
1、flavor参数说明: lattice的工作机制是利用 ghostscript 将PDF页面转换为图像,再用OpenCV进行处理的;而stream的工作机制是PDFMiner使用margin解析单元格之间有空格的表格以模拟表格。一般情况下,选择stream方式较多。但如果需要以lattice方式读入文件,必须安装ghostscript,并需要将其安装目录下的lib文件和bin文件配置到环境变量中,方可正确执行,否则会报错!
2、table_areas参数说明:
[
x
1
,
y
1
,
x
2
,
y
2
]
[x_1,y_1,x_2,y_2]
[x1,y1,x2,y2],
x
1
、
x
2
x_1、x_2
x1、x2为PDF坐标轴中的开始和结束的位置,
y
1
y_1
y1表示最高点所在行,
y
2
y_2
y2最低点所在行。这一参数会在后续示例演示中详细说明。
二、使用方法介绍
接下来,让我们以提取学术论文中规整和复杂的表格为例,详细介绍下具体使用方法。本次的案例论文为:【数字经济与长三角区域一体化发展——基于空间面板模型的分析】
2.1 提取规整表格
提取表4,考虑该表格在论文第5页,因此设置pages="5".
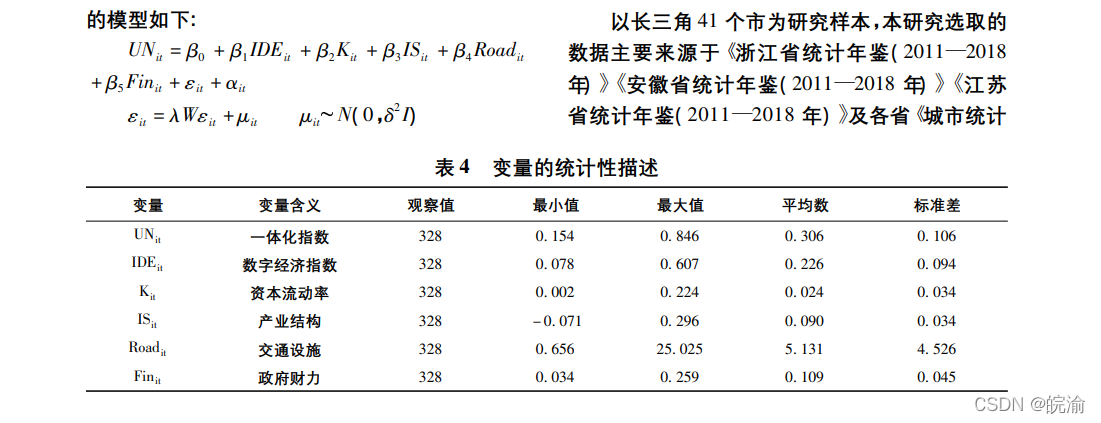
首先,需要定位表格所在位置
import camelot
import seaborn as sns #笔者jupyter背景较暗,此库只用来明亮背景
sns.set()
def extract_table(filepath,pages,table_area=['100,600,600,100']):
table = camelot.read_pdf(filepath,
flavor="stream",
pages=pages,
table_areas = table_area)
return table[0]
table = extract_table("论文.pdf",'5')
plt = camelot.plot(table,kind="textedge")
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
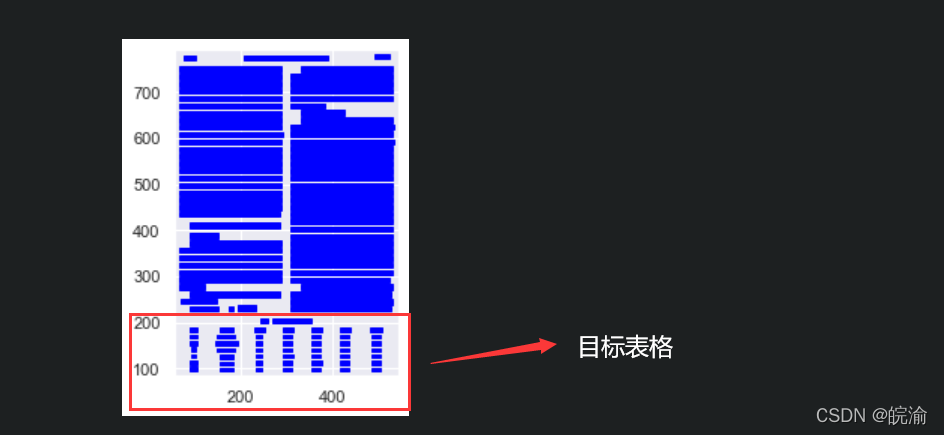
根据绘图结果,我们可以知道表格横向范围大致在90-600之间,纵向范围在100-200之间,因此我们设置table_areas为
[90,200,600,100]。提取结果如下:

从结果来看,对于这种规整性表格可以完美提取!
2.2 提取复杂表格
现提取论文第6页的表6,如下所示
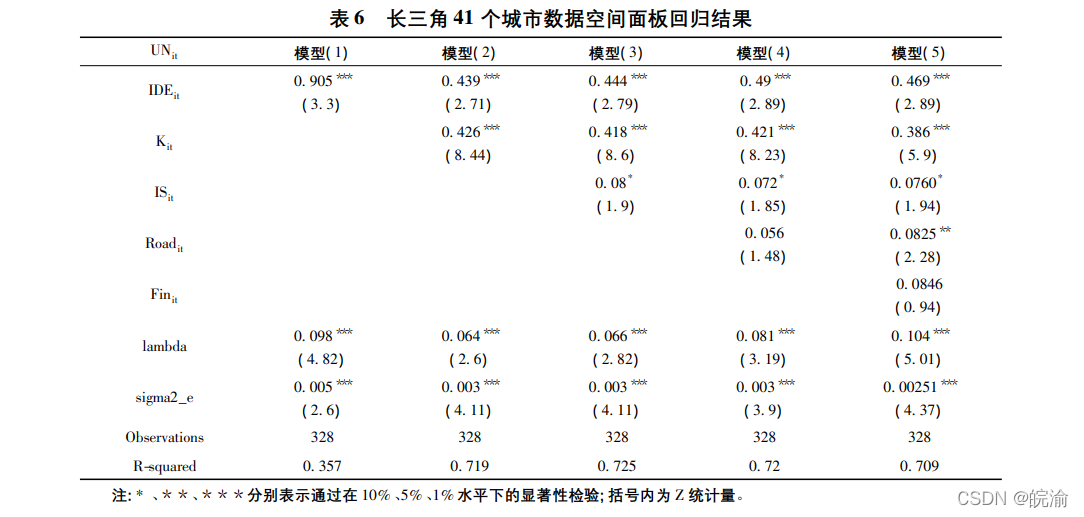
同理,我们可以按照以上方式先确定位置,再进行提取,这里直接放结果


从结果来看,提取效果依然是不错的,特别是空行的处理!这里,我们再导入Excel看下效果。从图可知,基本上只要再微调下,就与原表格保持一致。
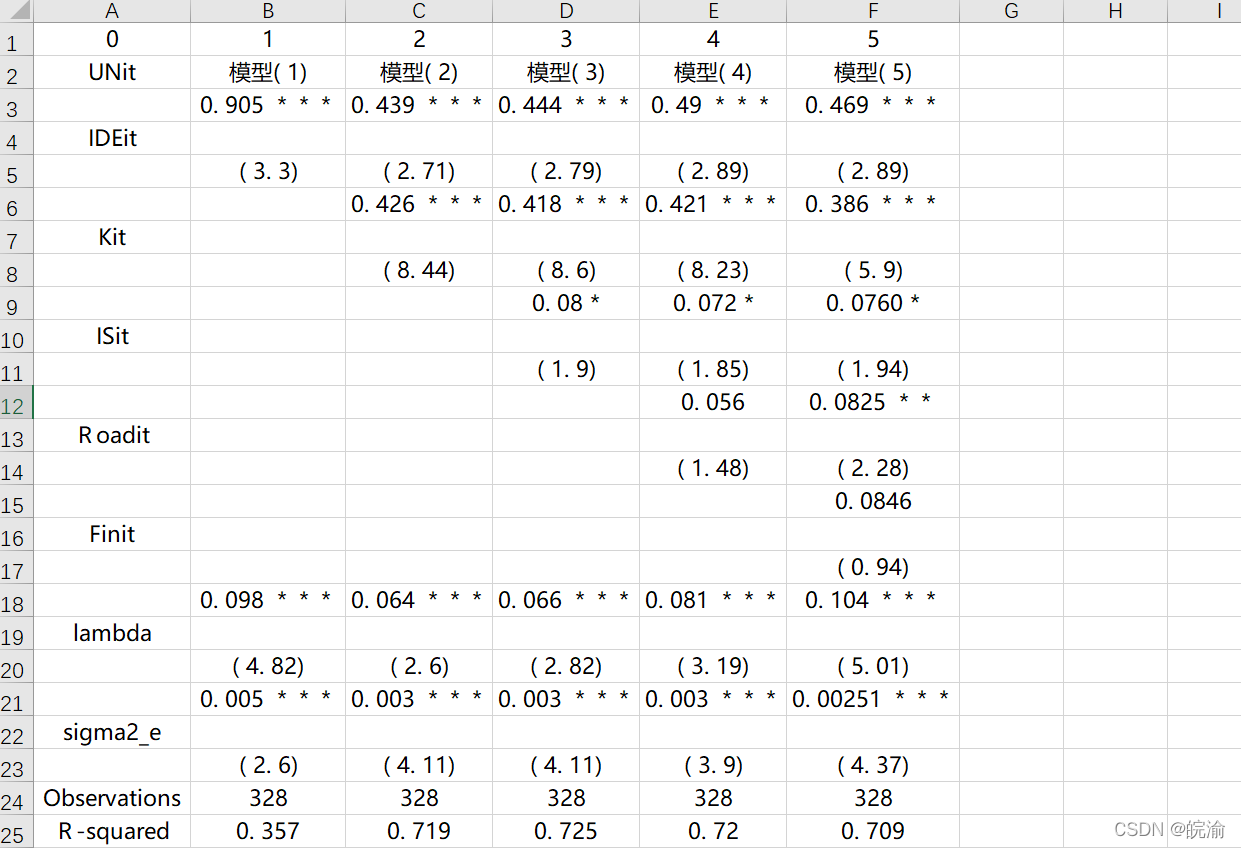
此外,如果遇到更加复杂的表格,还可以通过设置split_text和row_col进行微调,这里可参照Camelot参数进阶设置进行学习。
三、优缺点分析
优点:一旦给定表格位置后,识别效果较为优秀。(有兴趣的小伙伴也可以去了解下pdfplumber库,它与Camelot的识别结果差异还是挺大的)
缺点:无法批量导出表格,如要精准识别每次还需要人为给定表格位置,效率较低。此外,Camelot及pdfplumber只能识别文字性的pdf文档,对图片型的pdf文档不能有效识别。对于这一部分的识别,还是得依靠一些深度学习算法实现,期待未来大佬们的开发。
全部代码
import camelot import seaborn as sns #笔者jupyter背景较暗,此库只用来明亮背景 sns.set() def extract_table(filepath,pages,table_area=['100,600,600,100']): table = camelot.read_pdf(filepath, flavor="stream", pages=pages, table_areas = table_area) return table[0] #定位 table = extract_table("论文.pdf",'5') plt = camelot.plot(table,kind="textedge") plt.show() #提取 extract_table('论文.pdf','5',['90,200,600,100']).df

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
以上就是本次分享的全部内容~


