
热门标签
热门文章
- 1ros2配合yolov8具体实现
- 2HarmonyOS鸿蒙学习笔记(9)Navigator组件实现页面路由跳转_鸿蒙购物车点击跳转
- 3有效的github下载提速方法_github 下载加速
- 4python入门教程(非常详细)
- 5PHP-MYSQL学生信息管理系统(附源码免费)_php学生管理系统源码免费
- 62024年网络安全人才市场的十大趋势_数读网安人才
- 7利用遗传算法求解TSP问题_用遗传算法解决tsp问题 编码、初始群体的产生、适应度计算、选择运算、交叉运算、
- 8【kubernetes系列】Kubernetes之Taints和tolerations_kubernetes tolerations
- 9python提取图片型pdf中的文字(提取pdf扫描件文字)_pyhon pdf中图片的文字
- 10git用法总结
当前位置: article > 正文
python学习笔记(27)——pdfplumber库提取文本及表格内容基础操作_extract_tables
作者:nx123 | 2024-01-31 18:56:57
赞
踩
extract_tables
pdfplumber库安装地址:Search results · PyPI
安装后pip安装即可
1、提取文本:extract_text()解析文本
代码练习:
- import pdfplumber#引进pdfplumber库
- #print(pdfplumber.__version__)#通过测试证明pdfplumber库安装成功
- pdf=pdfplumber.open('F:\\XX公告.PDF')#打开pdf文件,路径之间符号用\\
- pages=pdf.pages#通过pages属性获取所有页的信息,此时pages是一个列表
- text_all=[]#创建一个空列表
- for page in pages:#遍历所有页的数据
- text = page.extract_text() # 用extract_text函数获取当前页的文本内容
- text_all.append(text)#把遍历的数据加到text_all列表中
- text_all=''.join(text_all)#把text_all的列表转化成字符串
- print(text_all)# 打印全部文本
- pdf.close()# 关闭Pdf文件
运行结果:
2、提取表格:extract_tables()解析表格
代码练习1:直接打印extract_tables()函数提取到的列表内容
- import pdfplumber
- pdf=pdfplumber.open('F:\\05pycharm\\20220227学习\\珈伟新能:珈伟新能源股份有限公司关于公司实际控制人签署《纾困投资协议》《表决权委托协议》暨控制权拟发生变更的提示性公告.PDF')#打开PDF文件
- pages=pdf.pages#pages属性获取所有页内容
- page=pages[2]#提取第三页,因为表格在第三页
- tables=page.extract_tables()#extract_tables()函数提取该页所有表格
- table=tables[0]#取第一个表格
- print(table)
运行结果:显示的试列表格式,需要进一步美化

通过整理分析:有1个大列表,里面嵌套了10个小列表

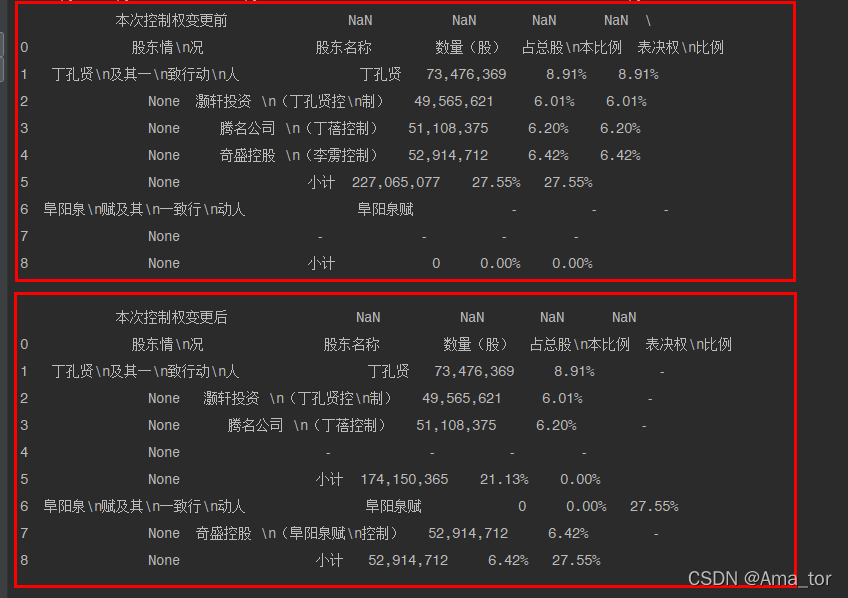
代码练习2:把获取的表格内容用DataFrame展示
- import pdfplumber
- import pandas as pd
- pdf=pdfplumber.open('F:\\05pycharm\\20220227学习\\珈伟新能:珈伟新能源股份有限公司关于公司实际控制人签署《纾困投资协议》《表决权委托协议》暨控制权拟发生变更的提示性公告.PDF')#打开PDF文件
- pages=pdf.pages#pages属性获取所有页内容
- page=pages[2]#提取第三页,因为表格在第三页
- tables=page.extract_tables()#extract_tables()函数提取该页所有表格
- table=tables[0]#取第一个表格
- pd.set_option('display.max_columns',None)#把表格内容全部显示,默认显示部分
- df=pd.DataFrame(table[1:],columns=table[0])#table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
-
- print(df)
运行结果:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/blog/article/detail/51432
推荐阅读
- 作者:禅与计算机程序设计艺术1.简介1.1游戏AI介绍在计算机游戏领域中,有着非常成熟且广泛使用的AI技术,比如AlphaGo和DotA2。那么为什么我们需要自己开发一个游戏AI呢?游戏AI可以提高游戏的竞技水平、增加玩家的娱乐体验。对于个... [详细]
赞
踩
- 做项目的时候,经常会看到zip这个函数,索性深入了解,方便之后的学习。_pythonzippythonzip目录前言1.zip函数2.实战展示前言做项目的时候,经常会看到zip这个函数,索性深入了解,方便之后的学习1.zip函数源码:zip... [详细]
赞
踩
- 随着软件规模和复杂性的增加,手动测试变得越来越繁琐且容易出错。自动化测试通过脚本化测试用例,能够更迅速、一致地验证软件的功能和性能。Selenium是一款强大的自动化测试工具,而Python语言则因其简洁性和易读性而成为自动化测试的首选之一... [详细]
赞
踩
- 已解决ERROR:Failedbuildingwheelforopencv-python-headlessFailedtobuildopencv-python-headlessERROR:Couldnotbuildwheelsforopen... [详细]
赞
踩
- 用于搭建Web应用程序免去不同Web应用相同代码部分的重复编写,只需关心Web应用核心的业务逻辑实现Django介绍Django,发音为[`dʒæŋɡəʊ],是用python语言写的开源web开发框架,并遵循MVC设计。劳伦斯出版集团为了开... [详细]
赞
踩
- Python使用Web3_web3.pyweb3.py1、安装Web3.pypipinstallweb3.py12、注册Infura获得节点服务使用邮箱注册Infura账户后,创建一个项目,即可获得以太坊节点服务,进入设置即可看到链接的UR... [详细]
赞
踩
- UI自动化测试实践,随着云计算时代的进一步深入,越来越多的中小企业企业与开发者需要一款简单易用、高能高效的云计算基础设施产品来支撑自身业务运营和创新开发。基于这种需求,华为云焕新推出华为云云服务器实例新品。这边文章由我带大家走一遍华为云云耀... [详细]
赞
踩
- 【pythonselenium报错】selenium.common.exceptions.WebDriverException:Message:三种解决方案!【pythonselenium报错】selenium.common.excepti... [详细]
赞
踩
 在Python图形用户界面(GUI)应用程序中,创建和管理多个窗口是一项重要的任务。这些窗口可以用于不同的用途,例如显示附加信息、执行特定操作或以其他方式改善用户体验。在本文中,我们将深入研究如何使用Python的Tkinter库来打开和关... [详细]
在Python图形用户界面(GUI)应用程序中,创建和管理多个窗口是一项重要的任务。这些窗口可以用于不同的用途,例如显示附加信息、执行特定操作或以其他方式改善用户体验。在本文中,我们将深入研究如何使用Python的Tkinter库来打开和关... [详细]赞
踩
- 我国地域辽阔,自然条件复杂,因此灾害性天气种类繁多,地区差异大。其中,雷雨大风、冰雹、龙卷、短时强降水等强对流天气是造成经济损失、危害生命安全最严重的一类灾害性天气[1]。以2022年为例,我国强对流天气引发风雹灾害造成的死亡失踪人数和直接... [详细]
赞
踩
- 优秀的中文分词库——jieba库_jiebajiebaHello,World!从去年开始学习Python,在长久的学习过程中,发现了许多有趣的知识,不断充实自己。今天我所写的内容也是极具趣味性,关于优秀的中文分词库——jieba库。... [详细]
赞
踩
- 类型:字典。_python绩点计算python绩点计算绩点计算类型:字典描述平均绩点计算方法:(课程学分1绩点+课程学分2绩点+…+课程学分n*绩点)/(课程学分1+课程学分2+…+课程学分n)用户循环输入五分制成绩和课程学分,题目测试数据... [详细]
赞
踩
- 用tkinter做前端,通过qrcode模块,做出了一个根据网页生成二维码的小程序【Python】生成二维码创建了一个使用python创建二维码的程序。下面是生成的程序的图像。功能描述输入网址(URL)。输入二维码的名称。当单击QR码生成按... [详细]
赞
踩
- VScode中Python代码不高亮显示怎么办?_vscode的python语法不高亮vscode的python语法不高亮最近在用VScode写代码的时候,发现Python代码不高亮显示:这样用起来体验感不好,网上查询资料,可能存在的原因为... [详细]
赞
踩
- 本项目包括四个核心部分:数据爬取、数据存储、数据分析和数据可视化。首先,利用Python编写的网络爬虫从专业的历史天气网站上爬取大连市从2011年至2023年的天气数据,包括日期、最高气温、最低气温和天气状况等信息。爬取过程中应用了requ... [详细]
赞
踩
- 探索Python函数的核心概念,从基础的函数定义和调用到高阶函数和装饰器。为初学者提供了详尽的指导和实用示例,让你更深入地理解Python的强大功能。【Python零基础入门】函数【Python零基础入门】第五课函数【Python零基础入门... [详细]
赞
踩
- sort()可以对列表进行「排序」_pythonsort函数pythonsort函数「作者主页」:士别三日wyx「作者简介」:CSDNtop100、阿里云博客专家、华为云享专家、网络安全领域优质创作者「推荐专栏」:小白零基础《Python入... [详细]
赞
踩
- 开门,意味着门的两个门板没有连通,对于外界是敞开的,对应“开”;而闭门,意味着门的两个门板连通到了一起,对于外界是关闭的状态,对应“闭”。_开运算开运算目录概要:正文部分:概念介绍: 何谓“开”与“闭”:如何实现开运算与闭运算:应... [详细]
赞
踩
- DES(DataEncryptionStandard)是一种对称加密算法。本文详细解释DES的算法原理,以及不安全的原因。附Python的实现源码。_des原理des原理文章目录1、什么是DES2、DES的基本概念3、DES的加密流程4、D... [详细]
赞
踩
- 因为课程需要,第一次这么彻底地接触numpy。虽闻名已久,但是真正使用numpy才感受到它的强大,发现它尤其适合数据分析与处理。这里根据自己的使用经验简单总结一下numpy在矩阵运算中的应用,之后也会根据自己的实践经历不断更新。_pytho... [详细]
赞
踩
相关标签

