
- 1决策树 随机森林_随机森林决策树数量的选择
- 22021-02-22_waylandsink
- 3Fonts字体简介_font中ttf都代表的是什么字体
- 4http:/222.212.79/app/zscd.html,emscripten/src/shell.html at 1.29.12 · emscripten-core/emscripten · G...
- 5linux重装后文件会不会丢失,重做日志文件丢失的恢复(二)
- 6状态压缩dp
- 7SQL语句使用大全,最常用的sql语句_sql语句大全及用法
- 8python3和Python2的区别
- 9详解K8s Pod对象的生命周期_container lifecycle prestop
- 10Project Summary
pytorch自动求导机制
赞
踩
Torch.autograd
在训练神经网络时,我们最常用的算法就是反向传播(BP)。
参数的更新依靠的就是loss function针对给定参数的梯度。为了计算梯度,pytorch提供了内置的求导机制 torch.autograd,它支持对任意计算图的自动梯度计算。
- 计算图是由节点和边组成的,其中的一些节点是数据,一些是数据之间的运算
- 计算图实际上就是变量之间的关系
- tensor 和 function 互相连接生成的一个有向无环图
Tensors,Function,计算图
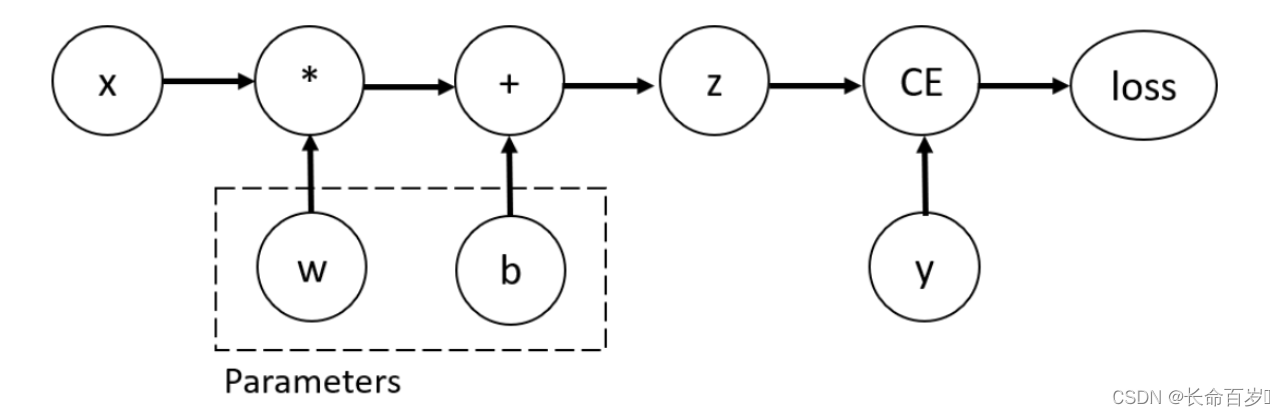
考虑最简单的例子,一个一层的神经网络
-
input:x
-
parameters:w,b
import torch x = torch.ones(5) # input tensor y = torch.zeros(3) # expected output w = torch.randn(5, 3, requires_grad=True) b = torch.randn(3, requires_grad=True) z = torch.matmul(x, w)+b #x 和 w 矩阵相乘,再加上 bias b loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其计算图如下所示
- 我们可以在创建tensor时设置 requires_grad = True 来支持梯度计算
- 也可以后续使用 x.requires_grad_(True) 来设置
我们对 tensor 应用的来构建计算图的函数,实际上是 Function 类的一个对象。
-
该对象知道如何在前向传播中实施函数
-
也知道如何在反向传播中计算梯度
-
对反向传播函数的引用存储在tensor的 grad_fn 属性中
print('Gradient function for z =', z.grad_fn) print('Gradient function for loss =', loss.grad_fn) >>Gradient function for z = <AddBackward0 object at 0x000002A040C867F0> >>Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward object at 0x000002A040C867F0>- 1
- 2
- 3
- 4
计算梯度
为了更新参数,我们需要计算 loss function 关于参数的梯度。
-
我们使用 loss.backward() 来计算梯度
-
使用 w.grad,b.grad 来检索梯度值
loss.backward() print(w.grad) print(b.grad) >>tensor([[0.2832, 0.0843, 0.3005], [0.2832, 0.0843, 0.3005], [0.2832, 0.0843, 0.3005], [0.2832, 0.0843, 0.3005], [0.2832, 0.0843, 0.3005]]) >>tensor([0.2832, 0.0843, 0.3005])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
note:
-
我们仅能获得计算图叶子节点的 grad 属性,并且需要这些节点设置 requires_grad = True。对于图中的其他节点,梯度是不可获取的
-
由于性能原因,在给定的计算图中,我们仅能使用 backward() 计算梯度一次(每次backward之后,计算图会被释放,但叶子节点的梯度不会被释放。叶子节点就是参数,不包括一些运算产生的中间变量。比如 x,w是叶子节点,但是 h = wx,h就不是叶子节点)。如果需要多次计算,我们需要设置 backward 的 retain_graph = True,这样的话求得的最终梯度是几次梯度之和
x = torch.ones((1, 4), dtype=torch.float32, requires_grad=True) y = x ** 2 z = y * 4 loss1 = z.mean() loss2 = z.sum() loss1.backward(retain_graph=True) loss2.backward() #如果上面没有设置 retain_graph = True,这里会报错 print(x.grad)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
禁用梯度跟踪
有时,我们只想对数据应用模型(forward过程),而不考虑模型的更新,这时我们可以不使用梯度跟踪
-
将计算代码包围在 torch.no_grad() 块中
z = torch.matmul(x, w)+b print(z.requires_grad) >>True with torch.no_grad(): z = torch.matmul(x, w)+b print(z.requires_grad) >>False- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
另一种方式是使用 detach()
z = torch.matmul(x, w)+b z_det = z.detach() print(z_det.requires_grad) >>False- 1
- 2
- 3
- 4
禁用梯度跟踪的一些原因
- fine-tune一个预训练的模型时,我们需要冻结模型的一些参数
- 当进行前向传播时,加速计算。对不追踪梯度的tensor进行计算会更高效
计算图的扩展
从概念上讲,autograd在由Function对象组成的有向无环图(DAG)中保存数据(张量)和所有执行的操作(以及产生的新张量)的记录。在DAG中,叶子是 input tensors,根是 output tensors,通过从根到叶跟踪这个图,可以使用链式法则自动计算梯度
在前向传播中,autograd同时做两件事
- 运行请求的操作来计算结果张量
- 在DAG中保持操作的梯度函数
反向传播过程开始,当 .backward() 在 DAG 根上被使用时
- 从每个 .grad_fn 中计算梯度
- 将它们累加到各个 tensor 的 .grad 属性中
- 利用链式法则,一直传播到叶子 tensor
DAGs 在 pytorch 中是动态的。值得注意的是,图是从头创建的。在每次.backward()调用之后autograd开始填充一个新的图。这正是允许我们在模型中使用控制流语句的原因,如果需要的话,我们可以在每次迭代中改变 shape(tensor的属性),size(tensor的方法) 和 operations(加减乘除等运算过程)
Tensor梯度和雅克比乘法
在很多情况下,我们loss function的结果是一个标量,我们以此来计算参数的梯度。但是,有些时候,我们的 loss 是 tensor。在这种情况下,pytorch 允许我们计算所谓的雅克比乘法,而不是梯度
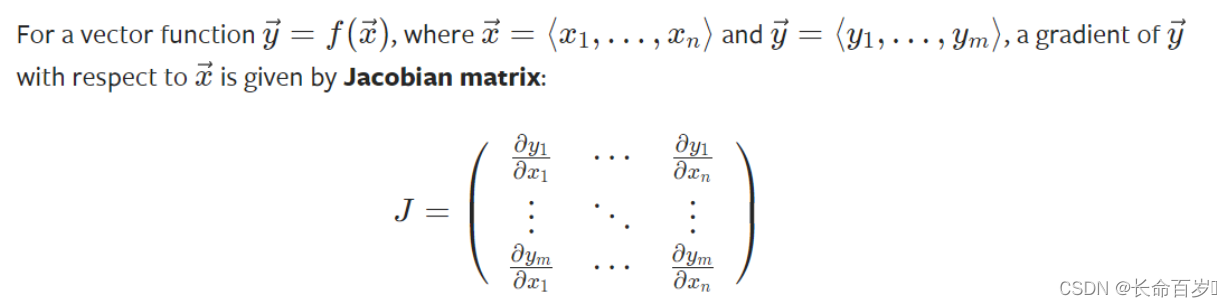
-
如果是标量对向量求导(scalar对tensor求导),那么就可以保证上面的计算图的根节点只有一个,此时不用引入grad_tensors参数,直接调用backward函数即可
-
如果是(向量)矩阵对(向量)矩阵求导(tensor对tensor求导),实际上是先求出Jacobian矩阵中每一个元素的梯度值(每一个元素的梯度值的求解过程对应上面的计算图的求解方法),然后将这个Jacobian矩阵与grad_tensors参数对应的矩阵相乘,得到最终的结果。v中的每个值代表该位置对应输出产生的梯度的权重。因此 v 的大小与输出 y 相同
-
当y 和 x 都是向量时,雅克比点乘 v T ⋅ J v^T \cdot J vT⋅J 是矩阵乘法, v = ( v 1 , … , v m ) v = (v_1,\dots,v_m) v=(v1,…,vm) , v v v 是 backward函数的参数,与 y 的大小一致。 v v v 中的每个量代表该位置对应 y 元素产生梯度的权重
x1 = torch.tensor(1, requires_grad=True, dtype = torch.float) x2 = torch.tensor(2, requires_grad=True, dtype = torch.float) x3 = torch.tensor(3, requires_grad=True, dtype = torch.float) y = torch.randn(3) y[0] = x1 ** 2 + 2 * x2 + x3 y[1] = x1 + x2 ** 3 + x3 ** 2 y[2] = 2 * x1 + x2 ** 2 + x3 ** 3 v = torch.tensor([3, 2, 1], dtype=torch.float) y.backward(v) print(x1.grad) >>tensor(10.) print(x2.grad) >>tensor(34.) print(x3.grad) >>tensor(42.)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-

v
∘
J
=
[
3
∗
2
x
1
+
2
∗
1
+
1
∗
2
,
3
∗
2
+
2
∗
3
x
2
2
+
1
∗
2
x
2
,
3
∗
1
+
2
∗
2
x
3
+
1
∗
3
x
3
2
]
=
[
10
,
34
,
42
]
v \circ J=\left[3 * 2 x_{1}+2 * 1+1 * 2,3 * 2+2 * 3 x_{2}^{2}+1 * 2 x_{2}, 3 * 1+2 * 2 x_{3}+1 * 3 x_{3}^{2}\right]=[10,34,42]
v∘J=[3∗2x1+2∗1+1∗2,3∗2+2∗3x22+1∗2x2,3∗1+2∗2x3+1∗3x32]=[10,34,42]
可以理解为
$v \circ J = 3 * [2x_1\,2\,1] + 2 * [1\,3x_2^2\,2x_3] + 1 * [2\,2x_2\,3x_3^2]$
- 第一项是 $y_1$ 产生的梯度,系数为 3
- 第二项是 $y_2$ 产生的梯度,系数为 2
- 第三项是 $y_3$ 产生的梯度,系数为 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
矩阵对矩阵,对应位置相乘(点乘,也是加权求和)v的大小与输出相同,每个值代表对应位置产生梯度的权重,然后相加
- 输出是 3 * 3 的,一共 9 个输出
- 每个输出对参数都有一个梯度矩阵,总的梯度是九个矩阵的加权
inp = torch.tensor([[1., 0, 0], [0, 1, 0], [0, 0, 1], [1, 1, 1], [1, 1, 1]]) w = torch.ones(3, 5, requires_grad=True) out = torch.matmul(w, inp) print(out) >>tensor([[3., 3., 3.], [3., 3., 3.], [3., 3., 3.]], grad_fn=<MmBackward>) x = torch.tensor([[1, 0, 0], [0, 0, 0], [0, 0, 0]]) #只考虑第一个输出产生的梯度,该梯度是一个矩阵 out.backward(x, retain_graph=True) print("First call\n", w.grad) >> tensor([[1., 0., 0., 1., 1.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.]]) w.grad.zero_() x = torch.ones(3, 3) out.backward(x) # 所有输出产生的梯度权重都是 1,总的梯度为 9 个矩阵之和 print("First call\n", w.grad) >> tensor([[1., 1., 1., 3., 3.], [1., 1., 1., 3., 3.], [1., 1., 1., 3., 3.]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
-
输出是标量的时候,v 相当于 tensor(1.0) ,可以省略
- 这篇博客手把手教你搭建Pytoch-Gpu环境!可谓是良心制作!一步一步,自己感觉很详细,质量也很高,算是对配置Pytorch深度学习环境的一个总结!大部分人想学编程都被配置环境劝退,这个过程难免会遇到各种各样的坑,但也正是这些坑让我们不断... [详细]
赞
踩
- ResNet代码复现(PyTorch),每一行都有超详细注释,新手小白都能看懂,亲测可运行_resnet实验复现resnet实验复现关于ResNet的原理和具体细节,可参见上篇解读:经典神经网络论文超详细解读(五)——ResNet(残差网络... [详细]
赞
踩
- 大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型13-pytorch搭建RBM(受限玻尔兹曼机)模型,调通模型的训练与测试。RBM(受限玻尔兹曼机)可以在没有人工标注的情况下对数据进行学习。其原理类似于我们人类学习... [详细]
赞
踩
- 本文在原论文的基础上进行了代码补充,并提供了整个流程的代码运行方法以完成图像超分辨率工作。_超分辨率图像重建超分辨率图像重建本文代码 ... [详细]
赞
踩
- 本文从BERT的基本概念和架构开始,详细讲解了其预训练和微调机制,并通过Python和PyTorch代码示例展示了如何在实际应用中使用这一模型。我们探讨了BERT的核心特点,包括其强大的注意力机制和与其他Transformer架构的差异。_... [详细]
赞
踩
- article
成功解决RuntimeError: [enforce fail at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c
成功解决RuntimeError:[enforcefailatC:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.c... [详细]赞
踩
- roberta文本分类 ... [详细]
赞
踩
- 本文使用PyTorch构建一个简单而有效的泰坦尼克号生存预测模型。通过这个项目,你会学到如何使用PyTorch框架创建神经网络、进行数据预处理和训练模型。我们将探讨如何处理泰坦尼克号数据集,设计并训练一个神经网络,以预测乘客是否在灾难中幸存... [详细]
赞
踩
- 人/B们/E常/S说/S生/B活/E是/S一/S部/S教/B科/M书/E”图中是双向的三层RNNs,堆叠多层的RNN网络,可以增加模型的参数,提高模型的拟合。理网格化数据(例如图像数据)的神经网络,RNN是专门用来处理序列数据的神经网络。双... [详细]
赞
踩
- 本文深入探索了PyTorch框架中的torch.nn模块,这是构建和实现高效深度学习模型的核心组件。我们详细介绍了torch.nn的关键类别和功能,包括ParameterModuleSequentialModuleListModuleDic... [详细]
赞
踩
- 本篇博客深入探讨了PyTorch的torch.nn子模块中与Transformer相关的核心组件。我们详细介绍了及其构成部分——编码器()和解码器(),以及它们的基础层——和。每个部分的功能、作用、参数配置和实际应用示例都被全面解析。这些组... [详细]
赞
踩
- PyTorch是由Facebook的AI研究团队开发的一个开源机器学习库,最初发布于2016年。它的前身是Torch,这是一个使用Lua语言编写的科学计算框架。PyTorch的出现标志着Torch的核心功能被转移到了Python这一更加流行... [详细]
赞
踩
- 本文详细介绍了PyTorch框架中的多个填充类,用于在深度学习模型中处理不同维度的数据。这些填充方法对于保持卷积神经网络中数据的空间维度至关重要,尤其在图像处理、音频信号处理等领域中有广泛应用。每种填充方法都有其特定的应用场景和注意事项,如... [详细]
赞
踩
- article
PyTorch 简单易懂的实现 CosineSimilarity 和 PairwiseDistance - 距离度量的操作_nn.cosinesimilarity(dim=1)返回的一定是标量吗
和。模块专注于计算两个高维数据集之间的余弦相似度,适用于评估文档、用户偏好等在特征空间中的相似性。而模块提供了一种计算两组数据点之间成对欧几里得距离的有效方式,这在聚类、近邻搜索或预测与实际值之间距离度量的场景中非常有用。这两个模块共同构成... [详细]赞
踩
- torch.cosine_similarity可以对两个向量或者张量计算相似度>>>input1=torch.randn(100,128)>>>input2=torch.randn(100,128)>>>output=torch.cosin... [详细]
赞
踩
- 本文提供几个pytorch中常用的向量相似度评估方法,并给出其源码实现,供大家参考。分别为以下六个。(其中第一个pytoch自带有库函数)_l2正则化和余弦相似度计算pytorxhl2正则化和余弦相似度计算pytorxh原文链接:https... [详细]
赞
踩
- 余弦相似度\color{red}{余弦相似度}余弦相似度在NLP的任务里,会对生成两个词向量进行相似度的计算,常常采用余弦相似度公式计算。余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接... [详细]
赞
踩
- 两个张量之间的欧氏距离即m*e和n*e张量之间的欧式距离理论分析算法实现importtorchdefeuclidean_dist(x,y):"""Args:x:pytorchVariable,withshape[m,d]y:pytorchV... [详细]
赞
踩
- importtorch.nn.functionalasFF.cosin_similarity(a,b,dim=1)沿着dim维度对a,b两个tensor计算余弦相似度。由于dim属性的存在,使得a,b两个tensor可以为任意维。_pyto... [详细]
赞
踩
- importtorchfromtorchimportTensordefcos_similar(p:Tensor,q:Tensor):sim_matrix=p.matmul(q.transpose(-2,-1))a=torch.norm(p,... [详细]
赞
踩

