
热门标签
热门文章
- 1【Java基础】Java中不能被实例化的类 -- p267_不能实例化类型怎么解决
- 2在Unity3D中控制动画播放_u3d的多个animation动画
- 3前端常用的快捷键:_前端开发快捷键!
- 4[附源码]JAVA+ssm计算机毕业设计航空订票系统(程序+Lw)_航空订单系统毕业设计
- 5大模型混战,阿里百度华为谁将成就AI时代的“新地基”?_stable、diffusion模型、文心大模型、混元大模型、通义 大
- 6瑞芯微1808模型转换(onnx到rknn)环境配置过程
- 7工作中的adb 常用命令_adb shell free
- 8apache-tomcat-10.0.18配置_tomcat-10.1.18对应java的版本
- 9使用python实现简单的猜数字小游戏_python猜数字游戏编程
- 10frida学习及使用
当前位置: article > 正文
PPYOLOE目标检测训练框架使用说明_pp-yoloe源代码
作者:stabc | 2024-01-31 20:38:11
赞
踩
pp-yoloe源代码
数据集准备
-
数据集标注参考博客【使用labelimg制作数据集】:使用labelimg制作数据集-CSDN博客
-
标注数据注意事项,图片名称为纯数字,例如1289.jpg ;不要出现其他字符,否则下面代码转换会报错。
-
标注好的数据集格式为VOC格式,AI Studio 中PPYOLOE用到的数据格式为coco数据格式,需要将标注好的数据进行格式转换。执行python voc2coco.py 即可!转换代码如下:
voc2coco.py
-
- import os
- import random
- import shutil
- import sys
- import json
- import glob
- import xml.etree.ElementTree as ET
-
-
- """
- 代码来源:https://github.com/Stephenfang51/VOC_to_COCO
- You only need to set the following three parts
- 1.val_files_num : num of validation samples from your all samples
- 2.test_files_num = num of test samples from your all samples
- 3.voc_annotations : path to your VOC dataset Annotations(最好写成绝对路径)
-
- """
- val_files_num = 0
- test_files_num = 0
- voc_annotations = r'C:/Users/liq/Desktop/VOC/Annotations/' #remember to modify the path
-
- split = voc_annotations.split('/')
- coco_name = split[-3]
- del split[-3]
- del split[-2]
- del split[-1]
- del split[0]
- # print(split)
- main_path = ''
- for i in split:
- main_path += '/' + i
-
- main_path = main_path + '/'
-
- # print(main_path)
-
- coco_path = os.path.join(main_path, coco_name+'_COCO/')
- coco_images = os.path.join(main_path, coco_name+'_COCO/images')
- coco_json_annotations = os.path.join(main_path, coco_name+'_COCO/annotations/')
- xml_val = os.path.join(main_path, 'xml', 'xml_val/')
- xml_test = os.path.join(main_path, 'xml/', 'xml_test/')
- xml_train = os.path.join(main_path, 'xml/', 'xml_train/')
-
- voc_images = os.path.join(main_path, coco_name, 'JPEGImages/')
-
-
-
-
- #from https://www.php.cn/python-tutorials-424348.html
- def mkdir(path):
- path=path.strip()
- path=path.rstrip("\\")
- isExists=os.path.exists(path)
- if not isExists:
- os.makedirs(path)
- print(path+' ----- folder created')
- return True
- else:
- print(path+' ----- folder existed')
- return False
- #foler to make, please enter full path
-
-
-
-
- mkdir(coco_path)
- mkdir(coco_images)
- mkdir(coco_json_annotations)
- mkdir(xml_val)
- mkdir(xml_test)
- mkdir(xml_train)
-
-
- #voc images copy to coco images
- for i in os.listdir(voc_images):
- img_path = os.path.join(voc_images + i)
- shutil.copy(img_path, coco_images)
-
- # voc images copy to coco images
- for i in os.listdir(voc_annotations):
- img_path = os.path.join(voc_annotations + i)
- shutil.copy(img_path, xml_train)
-
- print("\n\n %s files copied to %s" % (val_files_num, xml_val))
-
- for i in range(val_files_num):
- if len(os.listdir(xml_train)) > 0:
-
- random_file = random.choice(os.listdir(xml_train))
- # print("%d) %s"%(i+1,random_file))
- source_file = "%s/%s" % (xml_train, random_file)
-
- if random_file not in os.listdir(xml_val):
- shutil.move(source_file, xml_val)
- else:
- random_file = random.choice(os.listdir(xml_train))
- source_file = "%s/%s" % (xml_train, random_file)
- shutil.move(source_file, xml_val)
- else:
- print('The folders are empty, please make sure there are enough %d file to move' % (val_files_num))
- break
-
- for i in range(test_files_num):
- if len(os.listdir(xml_train)) > 0:
-
- random_file = random.choice(os.listdir(xml_train))
- # print("%d) %s"%(i+1,random_file))
- source_file = "%s/%s" % (xml_train, random_file)
-
- if random_file not in os.listdir(xml_test):
- shutil.move(source_file, xml_test)
- else:
- random_file = random.choice(os.listdir(xml_train))
- source_file = "%s/%s" % (xml_train, random_file)
- shutil.move(source_file, xml_test)
- else:
- print('The folders are empty, please make sure there are enough %d file to move' % (val_files_num))
- break
-
- print("\n\n" + "*" * 27 + "[ Done ! Go check your file ]" + "*" * 28)
-
- # !/usr/bin/python
-
- # pip install lxml
-
-
- START_BOUNDING_BOX_ID = 1
- PRE_DEFINE_CATEGORIES = None
-
-
- # If necessary, pre-define category and its id
- # PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
- # "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
- # "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
- # "motorbike": 14, "person": 15, "pottedplant": 16,
- # "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}
-
- """
- main code below are from
- https://github.com/Tony607/voc2coco
- """
-
-
- def get(root, name):
- vars = root.findall(name)
- return vars
-
-
- def get_and_check(root, name, length):
- vars = root.findall(name)
- if len(vars) == 0:
- raise ValueError("Can not find %s in %s." % (name, root.tag))
- if length > 0 and len(vars) != length:
- raise ValueError(
- "The size of %s is supposed to be %d, but is %d."
- % (name, length, len(vars))
- )
- if length == 1:
- vars = vars[0]
- return vars
-
-
- def get_filename_as_int(filename):
- try:
- filename = filename.replace("\\", "/")
- filename = os.path.splitext(os.path.basename(filename))[0]
- return int(filename)
- except:
- raise ValueError("Filename %s is supposed to be an integer." % (filename))
-
-
- def get_categories(xml_files):
- """Generate category name to id mapping from a list of xml files.
- Arguments:
- xml_files {list} -- A list of xml file paths.
- Returns:
- dict -- category name to id mapping.
- """
- classes_names = []
- for xml_file in xml_files:
- tree = ET.parse(xml_file)
- root = tree.getroot()
- for member in root.findall("object"):
- classes_names.append(member[0].text)
- classes_names = list(set(classes_names))
- classes_names.sort()
- return {name: i for i, name in enumerate(classes_names)}
-
-
- def convert(xml_files, json_file):
- json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
- if PRE_DEFINE_CATEGORIES is not None:
- categories = PRE_DEFINE_CATEGORIES
- else:
- categories = get_categories(xml_files)
- bnd_id = START_BOUNDING_BOX_ID
- for xml_file in xml_files:
- tree = ET.parse(xml_file)
- root = tree.getroot()
- path = get(root, "path")
- if len(path) == 1:
- filename = os.path.basename(path[0].text)
- elif len(path) == 0:
- filename = get_and_check(root, "filename", 1).text
- else:
- raise ValueError("%d paths found in %s" % (len(path), xml_file))
- ## The filename must be a number
- image_id = get_filename_as_int(filename)
- size = get_and_check(root, "size", 1)
- width = int(get_and_check(size, "width", 1).text)
- height = int(get_and_check(size, "height", 1).text)
- image = {
- "file_name": filename,
- "height": height,
- "width": width,
- "id": image_id,
- }
- json_dict["images"].append(image)
- ## Currently we do not support segmentation.
- # segmented = get_and_check(root, 'segmented', 1).text
- # assert segmented == '0'
- for obj in get(root, "object"):
- category = get_and_check(obj, "name", 1).text
- if category not in categories:
- new_id = len(categories)
- categories[category] = new_id
- category_id = categories[category]
- bndbox = get_and_check(obj, "bndbox", 1)
- xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1
- ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1
- xmax = int(get_and_check(bndbox, "xmax", 1).text)
- ymax = int(get_and_check(bndbox, "ymax", 1).text)
- assert xmax > xmin
- assert ymax > ymin
- o_width = abs(xmax - xmin)
- o_height = abs(ymax - ymin)
- ann = {
- "area": o_width * o_height,
- "iscrowd": 0,
- "image_id": image_id,
- "bbox": [xmin, ymin, o_width, o_height],
- "category_id": category_id,
- "id": bnd_id,
- "ignore": 0,
- "segmentation": [],
- }
- json_dict["annotations"].append(ann)
- bnd_id = bnd_id + 1
-
- for cate, cid in categories.items():
- cat = {"supercategory": "none", "id": cid, "name": cate}
- json_dict["categories"].append(cat)
-
- os.makedirs(os.path.dirname(json_file), exist_ok=True)
- json_fp = open(json_file, "w")
- json_str = json.dumps(json_dict)
- json_fp.write(json_str)
- json_fp.close()
-
-
- xml_val_files = glob.glob(os.path.join(xml_val, "*.xml"))
- xml_test_files = glob.glob(os.path.join(xml_test, "*.xml"))
- xml_train_files = glob.glob(os.path.join(xml_train, "*.xml"))
-
- convert(xml_val_files, coco_json_annotations + 'val2017.json')
- convert(xml_test_files, coco_json_annotations+'test2017.json')
- convert(xml_train_files, coco_json_annotations + 'train2017.json')

或者使用voc2coco2.py
- # !/usr/bin/python
- # -*- coding: utf-8 -*-
- '''
- @Project :always
- @File :voc2coco2.py
- @Author :Lis
- @Date :2023/7/28 18:23
- @Desc :
- '''
- import xml.etree.ElementTree as ET
- import os
- import json
-
- coco = dict()
- coco['images'] = []
- coco['type'] = 'instances'
- coco['annotations'] = []
- coco['categories'] = []
-
- category_set = dict()
- image_set = set()
-
- category_item_id = -1
- image_id = 20180000000
- annotation_id = 0
-
-
- def addCatItem(name):
- global category_item_id
- category_item = dict()
- category_item['supercategory'] = 'none'
- category_item_id += 1
- category_item['id'] = category_item_id
- category_item['name'] = name
- coco['categories'].append(category_item)
- category_set[name] = category_item_id
- return category_item_id
-
-
- def addImgItem(file_name, size):
- global image_id
- if file_name is None:
- raise Exception('Could not find filename tag in xml file.')
- if size['width'] is None:
- raise Exception('Could not find width tag in xml file.')
- if size['height'] is None:
- raise Exception('Could not find height tag in xml file.')
- image_id += 1
- image_item = dict()
- image_item['id'] = image_id
- image_item['file_name'] = file_name
- image_item['width'] = size['width']
- image_item['height'] = size['height']
- coco['images'].append(image_item)
- image_set.add(file_name)
- return image_id
-
-
- def addAnnoItem(object_name, image_id, category_id, bbox):
- global annotation_id
- annotation_item = dict()
- annotation_item['segmentation'] = []
- seg = []
- # bbox[] is x,y,w,h
- # left_top
- seg.append(bbox[0])
- seg.append(bbox[1])
- # left_bottom
- seg.append(bbox[0])
- seg.append(bbox[1] + bbox[3])
- # right_bottom
- seg.append(bbox[0] + bbox[2])
- seg.append(bbox[1] + bbox[3])
- # right_top
- seg.append(bbox[0] + bbox[2])
- seg.append(bbox[1])
-
- annotation_item['segmentation'].append(seg)
-
- annotation_item['area'] = bbox[2] * bbox[3]
- annotation_item['iscrowd'] = 0
- annotation_item['ignore'] = 0
- annotation_item['image_id'] = image_id
- annotation_item['bbox'] = bbox
- annotation_item['category_id'] = category_id
- annotation_id += 1
- annotation_item['id'] = annotation_id
- coco['annotations'].append(annotation_item)
-
-
- def parseXmlFiles(xml_path):
- for f in os.listdir(xml_path):
- if not f.endswith('.xml'):
- continue
-
- bndbox = dict()
- size = dict()
- current_image_id = None
- current_category_id = None
- file_name = None
- size['width'] = None
- size['height'] = None
- size['depth'] = None
-
- xml_file = os.path.join(xml_path, f)
- print(xml_file)
-
- tree = ET.parse(xml_file)
- root = tree.getroot()
- if root.tag != 'annotation':
- raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
-
- # elem is <folder>, <filename>, <size>, <object>
- for elem in root:
- current_parent = elem.tag
- current_sub = None
- object_name = None
-
- if elem.tag == 'folder':
- continue
-
- if elem.tag == 'filename':
- file_name = elem.text
- if file_name in category_set:
- raise Exception('file_name duplicated')
-
- # add img item only after parse <size> tag
- elif current_image_id is None and file_name is not None and size['width'] is not None:
- if file_name not in image_set:
- current_image_id = addImgItem(file_name, size)
- print('add image with {} and {}'.format(file_name, size))
- else:
- raise Exception('duplicated image: {}'.format(file_name))
- # subelem is <width>, <height>, <depth>, <name>, <bndbox>
- for subelem in elem:
- bndbox['xmin'] = None
- bndbox['xmax'] = None
- bndbox['ymin'] = None
- bndbox['ymax'] = None
-
- current_sub = subelem.tag
- if current_parent == 'object' and subelem.tag == 'name':
- object_name = subelem.text
- if object_name not in category_set:
- current_category_id = addCatItem(object_name)
- else:
- current_category_id = category_set[object_name]
-
- elif current_parent == 'size':
- if size[subelem.tag] is not None:
- raise Exception('xml structure broken at size tag.')
- size[subelem.tag] = int(subelem.text)
-
- # option is <xmin>, <ymin>, <xmax>, <ymax>, when subelem is <bndbox>
- for option in subelem:
- if current_sub == 'bndbox':
- if bndbox[option.tag] is not None:
- raise Exception('xml structure corrupted at bndbox tag.')
- bndbox[option.tag] = int(option.text)
-
- # only after parse the <object> tag
- if bndbox['xmin'] is not None:
- if object_name is None:
- raise Exception('xml structure broken at bndbox tag')
- if current_image_id is None:
- raise Exception('xml structure broken at bndbox tag')
- if current_category_id is None:
- raise Exception('xml structure broken at bndbox tag')
- bbox = []
- # x
- bbox.append(bndbox['xmin'])
- # y
- bbox.append(bndbox['ymin'])
- # w
- bbox.append(bndbox['xmax'] - bndbox['xmin'])
- # h
- bbox.append(bndbox['ymax'] - bndbox['ymin'])
- print('add annotation with {},{},{},{}'.format(object_name, current_image_id, current_category_id,
- bbox))
- addAnnoItem(object_name, current_image_id, current_category_id, bbox)
-
-
- if __name__ == '__main__':
- # 只需要改动这两个参数就行了
- xml_path = r'C:\Users\Administrator\Desktop\皮革数据检测格式数据集\anno' # 这是xml文件所在的地址
- json_file = r'C:\Users\Administrator\Desktop\皮革数据检测格式数据集\annotations.json' # 这是你要生成的json文件
- parseXmlFiles(xml_path)
- json.dump(coco, open(json_file, 'w'))
Fork PPYOLOE项目并启动运行
PPYOLOE目标检测训练框架
PPYOLOE目标检测训练框架 - 飞桨AI Studio星河社区
按照main.ipynb流程依次执行即可!
-
导入所需要的第三方库
-
安装paddlex
-
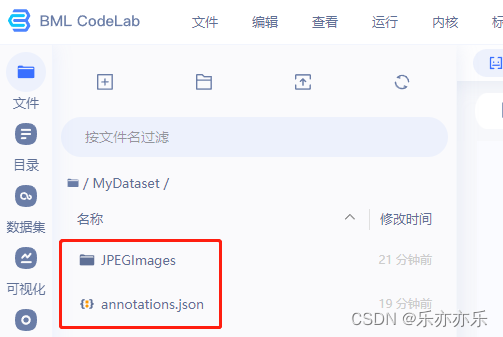
创建数据集目录 将标注的图像数据上传到 MyDataset/JPEGImages 目录下;将coco格式数据标签annotations.json放到MyDataset目录下。
-
按比例切分数据集
-
git PaddleDetection代码
-
进入PaddleDetection目录
-
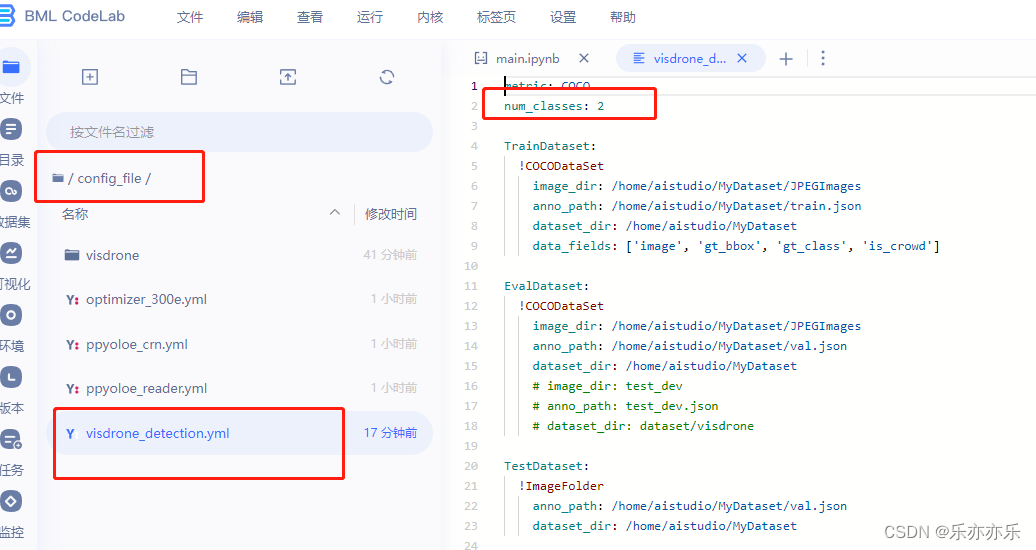
根据需求修改配置文件,比如检测的目标类别数 进入/home/aistudio/config_file/目录下,修改visdrone_detection.yml中num_classes参数
-
开始训练
-
训练完成后评估模型
-
挑一张验证集的图片展示预测效果(可以到生成的目录下,打开查看)
-
导出模型,即可使用FastDeploy进行快速推理
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/blog/article/detail/52114
推荐阅读
- 该项目着眼于基于视觉深度学习的自动驾驶场景,旨在对车载摄像头采集的视频数据进行道路场景解析,为自动驾驶提供一种解决思路。利用YOLO系列模型PP_YOLOE+完成车辆检测实现一种高效高精度的道路场景解析方式,从而实现真正意义上的自动驾驶,减... [详细]
赞
踩
- 解读百度目标检测论文PP-YOLOE及开源项目PaddleDetection应用_pp-yoloe-rpaddleocrpp-yoloe-rpaddleocr最新发布PP-YOLOE+,最高精度提升2.4%mAP,达到54.9%mAP,模型... [详细]
赞
踩
- 关注公众号,发现CV技术之美精度54.7mAP,相较YOLOv7提升1.9%L版本端到端推理速度42.2FPS训练速度提升3.75倍COCO数据集仅需20epoch即可达到50.0mAP下游任务泛化性最高提升8%10+即开即用多端部署Dem... [详细]
赞
踩
- 全国大学生智能汽车竞赛是以智能汽车为研究对象的创意性科技竞赛,是面向全国大学生的一种具有探索性工程的实践活动,是教育部倡导的大学生A类科技竞赛之一。竞赛以立足培养,重在参与,鼓励探索,追求卓越为指导思想,培养大学生的创意性科技竞赛能力。本次... [详细]
赞
踩
- 保姆级教程烟头检测,基于SOTA模型PPYOLOE+_X,好用且易懂,快来看看吧,还能部署到安卓端_pp-yoloe+pp-yoloe+★★★本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容>>>1.模型... [详细]
赞
踩
- 论文地址:https://arxiv.org/pdf/2203.16250.pdf发表时间:2022PP-YOLOE基于PP-YOLOv2改进实现,其中PP-YOLOv2的整体架构包含了具有可变形卷积的ResNet50-vd的主干,使用带有... [详细]
赞
踩
- 基于PP-YOLOE-SOD实现遥感场景下的小目标检测,完善了从训练到部署的全流程实践,达到了不错的准确率。_怎么使用训练好的ppyoloe推理图像可视化怎么使用训练好的ppyoloe推理图像可视化★★★本文源自AlStudio社区精品项目... [详细]
赞
踩
- 本文对PPYOLOv2进行了一些更新,包括可扩展的backbone-neck架构、高效的任务对齐head、高级标签分配策略和精确的目标损失函数,这一切的改进形成了PP-YOLOE。同时,提出了s/m/l/x模型,这些模型可以涵盖实际中的不同... [详细]
赞
踩
相关标签

