
- 1Learn the basics of Python 3-Chapter 4:Loops
- 2python Web框架要点---Django流程详解_python django
- 3备战蓝桥杯---数据结构与STL应用(入门1)
- 4pip install 之subprocess-exited-with-error_pip install subprocess
- 5Kubernetes创始人发声!K8s 变得太复杂了
- 6【WPF】消息蒙版弹窗UI以及await实现等待反馈(popup)_wpf popup
- 7C#毕业设计——基于C#+asp.net+SQL server的教学网站及网上考试系统设计与实现(毕业论文+程序源码)——教学网站及网上考试系统
- 8使用蒙特卡罗方法计算圆周率(Python版)_蒙特卡罗法计算圆周率python
- 9【pip安装包错误】subprocess-exited-with-error | No matching distribution found for setuptool>=40.8.0_no matching distribution found for setuptools>=40.
- 10Dung beetle optimizer|(DBO)智能算法之蜣螂优化算法(DBO)|含matlab代码
随机森林算法java代码_数据挖掘实践(27):算法基础(五)Random Forest(随机森林)算法(集成学习)(一)...
赞
踩
0 简介
0.1 主题

0.2 目标

1. Bootstraping与Bagging策略
1.1 Bootstraping/自助算法


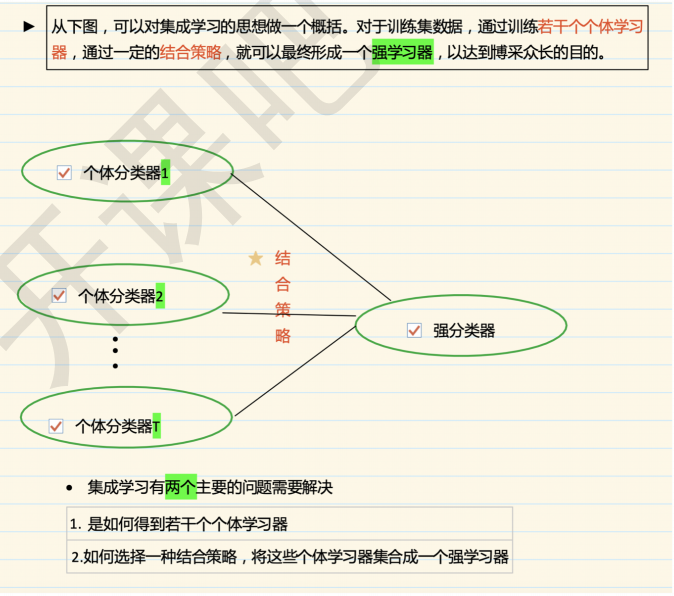


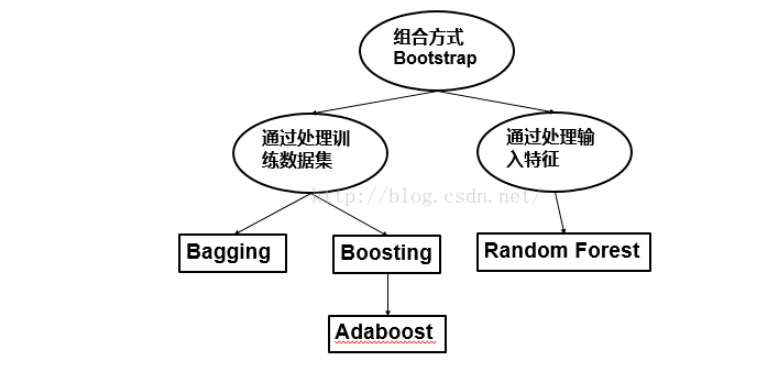
1.2 分类
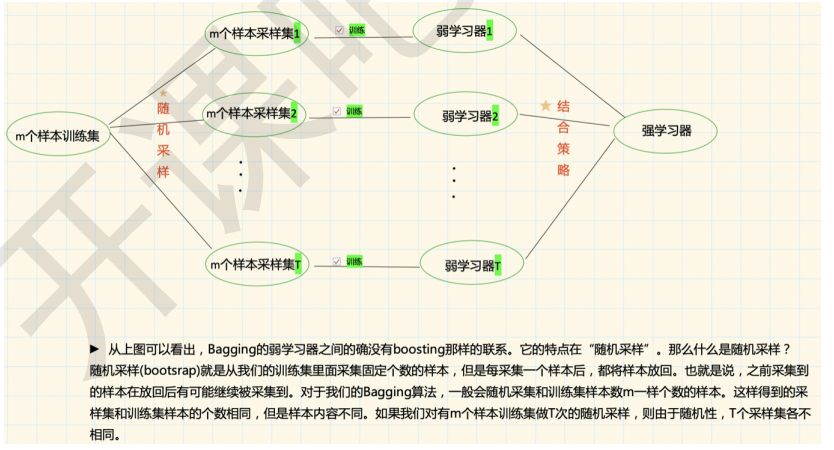
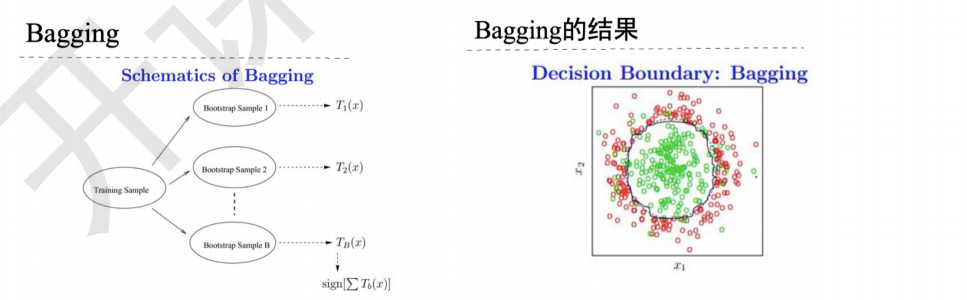
1.3 Bagging/套袋法

1.4 集成学习之结合策略





1.5 代码实验
importnumpy as npimportos%matplotlib inlineimportmatplotlibimportmatplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14plt.rcParams['xtick.labelsize'] = 12plt.rcParams['ytick.labelsize'] = 12
importwarnings
warnings.filterwarnings('ignore')
np.random.seed(42)
from sklearn.model_selection import train_test_split #分割数据集
from sklearn.datasets import make_moons #生成数据
"""主要参数作用如下:
n_numbers:生成样本数量
noise:默认是false,数据集是否加入高斯噪声
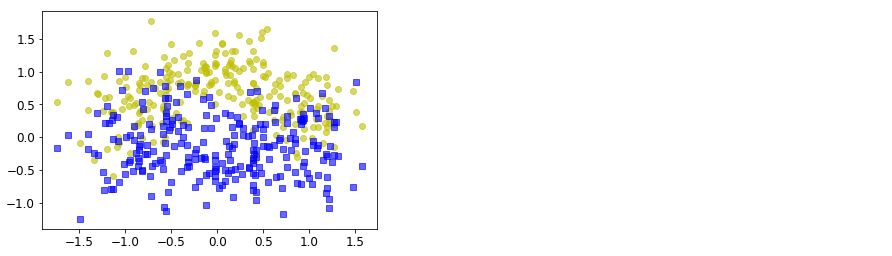
random_state:生成随机种子,给定一个int型数据,能够保证每次生成数据相同。"""X,y= make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test= train_test_split(X, y, random_state=42)
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha = 0.6) #黄色的圆
plt.plot(X[:,0][y==0],X[:,1][y==1],'bs',alpha = 0.6) #蓝色的矩形
[]

from sklearn.tree importDecisionTreeClassifierfrom sklearn.ensemble import VotingClassifier #投票分类器
from sklearn.linear_model importLogisticRegressionfrom sklearn.svm importSVC
log_clf= LogisticRegression(random_state=42)
rnd_clf= DecisionTreeClassifier(random_state=42)
svm_clf= SVC(random_state=42)#投票 参数估计
voting_clf = VotingClassifier(estimators =[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf)],voting='hard')#voting_clf = VotingClassifier(estimators =[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf)],voting='soft')
voting_clf.fit(X_train,y_train)
VotingClassifier(estimators=[('lr',
LogisticRegression(C=1.0, class_weight=None,
dual=False, fit_intercept=True,
intercept_scaling=1,
l1_ratio=None, max_iter=100,
multi_class='warn',
n_jobs=None, penalty='l2',
random_state=42, solver='warn',
tol=0.0001, verbose=0,
warm_start=False)),
('rf',
DecisionTreeClassifier(class_weight=None,
criterion='gini',
max_depth=None,
ma...
min_weight_fraction_leaf=0.0,
presort=False,
random_state=42,
splitter='best')),
('svc',
SVC(C=1.0, cache_size=200, class_weight=None,
coef0=0.0, decision_function_shape='ovr',
degree=3, gamma='auto_deprecated',
kernel='rbf', max_iter=-1, probability=False,
random_state=42, shrinking=True, tol=0.001,
verbose=False))],
flatten_transform=True, n_jobs=None, voting='hard',
weights=None)
from sklearn.metrics import accuracy_score #导入准确率
for clf in(log_clf,rnd_clf,svm_clf,voting_clf):
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)print (clf.__class__.__name__,accuracy_score(y_test,y_pred))
LogisticRegression 0.864
DecisionTreeClassifier 0.856
SVC 0.888
VotingClassifier 0.896

from sklearn.ensemble importBaggingClassifierfrom sklearn.tree importDecisionTreeClassifier"""n_estimators:int, optional (default=10),要集成的基估计器的个数
max_samples: int or float, optional (default=1.0)。
决定从x_train抽取去训练基估计器的样本数量。int 代表抽取数量,float代表抽取比例
bootstrap : boolean, optional (default=True) 决定样本子集的抽样方式(有放回和不放回)
n_jobs : int, optional (default=1)
random_state:如果int,random_state是随机数生成器使用的种子"""
#用集成BaggingClassifier分类器
bag_clf =BaggingClassifier(DecisionTreeClassifier(),
n_estimators= 500,
max_samples= 100,
bootstrap=True,
n_jobs= -1,
random_state= 42)
bag_clf.fit(X_train,y_train)
y_pred= bag_clf.predict(X_test)
accuracy_score(y_test,y_pred)
0.904
#用随机森林分类器
tree_clf = DecisionTreeClassifier(random_state = 42)
tree_clf.fit(X_train,y_train)
y_pred_tree=tree_clf.predict(X_test)
accuracy_score(y_test,y_pred_tree)
0.856
2 随机森林



3 扩展点
3.1 使用场景:数据维度相对低(几十维),同时对准确性有较高要求时
3.2 随机森林在现实分析中被大量使用,它相对于决策树,在准确性上有了很大的提升
4.总结
4.1 随机森林的生成步骤

4.2 RF与传统bagging的区别

4.3 RF的优点

- 互联网的每一个角落,无论是大型电商平台的秒杀活动,社交平台的实时消息推送,还是在线视频平台的流量洪峰,背后都离不开多线程技术的支持。在数字化转型的过程中,高并发、高性能是衡量系统性能的核心指标,越来越多的公司对从业人员的多线程编程能力提出了... [详细]
赞
踩
- 在本文中,我们将探索如何利用Java编程与AmazonS3(即简单存储服务)存储系统进行互动。需要牢记,S3的结构异常简单:每个存储桶能够容纳大量的对象,这些对象可以通过SOAP接口或REST风格的API进行访问。接下来,我们将使用适用于J... [详细]
赞
踩
- 1.0移除链表元素、2.0反转链表、3.0链表中倒数第k个节点、4.0合并两个有序链表、5.0链表的回文结构、6.0环形链表、7.0相加链表JavaLeetCode篇-深入了解关于单链表的经典解法 ... [详细]
赞
踩
- 因为项目不方便直接发上来,所以大家需要源码的话就私我叭~_java和sqlserver2012课程设计‘java和sqlserver2012课程设计‘本科参与项目文档合集:点击跳转~学生管理系统StudentManagementSystem... [详细]
赞
踩
- 在本博文中,我们将探讨如何使用Java检查指定的秘钥是否存在于亚马逊S3存储桶中。AmazonS3是一个非常流行的云存储服务,为存储和检索数据提供了可伸缩、安全和高可用的平台。就个人而言,后续很多的公有云平台或者一些SaaS服务,都或多或少... [详细]
赞
踩
- 进来!只花五分钟学懂!采用分布式架构时,一次请求报错难以定位,分布式链路追踪技术来解决。【JAVA】分布式链路追踪技术概论目录1.概述2.基于日志的实现2.1.实现思想2.2.sleuth2.2.可视化3.基于agent的实现4.联系作者1... [详细]
赞
踩
- web3j是一个轻量级、高度模块化、响应式、类型安全的Java和Android类库提供丰富API,用于处理以太坊智能合约及与以太坊网络上的客户端(节点)进行集成。可以通过它进行以太坊区块链的开发,而无需为你的应用平台编写集成代码。web3j... [详细]
赞
踩
- 在本文中,我们将探索如何利用Java编程与AmazonS3(即简单存储服务)存储系统进行互动。需要牢记,S3的结构异常简单:每个存储桶能够容纳大量的对象,这些对象可以通过SOAP接口或REST风格的API进行访问。接下来,我们将使用适用于J... [详细]
赞
踩
- article
java.net.NoRouteToHostException No route to host的排查与解决思路分享_caused by: java.net.noroutetohostexception: no rou
 那问题肯定就出在这个datanode22中了,经过简单的测试发现,在HiveSQL的执行过程中,hadoop的心跳时间经常很大,整个hadoop集群的心跳超时时间设置为600S(这个值设置的非常大,其实是有点不合理的),在web页面上能看见... [详细]
那问题肯定就出在这个datanode22中了,经过简单的测试发现,在HiveSQL的执行过程中,hadoop的心跳时间经常很大,整个hadoop集群的心跳超时时间设置为600S(这个值设置的非常大,其实是有点不合理的),在web页面上能看见... [详细]赞
踩
- article
解决思路:java.lang.IllegalArgumentException: Invalid character found in method name. HTTP method names
然后,我们设置了请求方法为POST,并设置了请求头部信息,包括Content-Type和Accept。通过检查代码中的方法名、使用合适的HTTP请求方法常量、使用第三方HTTP库、检查请求URL以及使用调试和日志工具,我们可以解决这个异常并... [详细]赞
踩
- Java中虽然已经内置了丰富的异常类,但是并不能完全表示实际开发中所遇到的一些异常,此时就需要维护符合我们实际情况的异常结构.if(!thrownewuserNameException("用户名错误");if(!thrownewpassWo... [详细]
赞
踩
- 假设第一个元素已经排序好了的,在已经排好的元素的后一个元素记录为low,这个low索引对应的元素需要用临时变量来接受,只要找到比这个索引对应的元素小的值,就可以插入到比它小的值的后一个索引位置了,当然,每一次对比之后,都需要往后移一个位置,... [详细]
赞
踩
- 在文件的最上方加上一个package语句指定该代码在哪个包中.包名需要尽量指定成唯一的名字,通常会用公司的域名的颠倒形式例如包名要和代码路径相匹配.例如创建的包,那么会存在一个对应的路径来存储代码.如果一个类没有package语句,则该类被... [详细]
赞
踩
- Set接口继承自Collection接口,并添加了一些针对无序集合的操作。它不允许重复的元素,并提供了添加、删除和检查元素是否存在的方法。在Java中,Set接口有几个常见的实现类,每个实现类都具有不同的性能和用途。HashSet:基于哈希... [详细]
赞
踩
- 本人使用idea创建web工程后,运行tomcat服务器时出现报错:Error:CouldnotcreatetheJavaVirtualMachine.EDDisconnectedfromserverError:Afatalexceptio... [详细]
赞
踩
- article
Failed to obtain JDBC Connection; nested exception is java.sql.SQLException_failed to obtain jdbc connection; nested exception
FailedtoobtainJDBCConnection;nestedexceptionisjava.sql.SQLException_failedtoobtainjdbcconnection;nestedexceptionisjava.s... [详细]赞
踩
 该博客教程旨在帮助初学者了解如何在Java前端和MySQL数据库之间建立连接。通过简单易懂的指导,教程覆盖了从前端到后端的完整流程。首先,它介绍了Java编程语言的基础知识,为初学者提供了必要的背景。接着,教程引导读者学习如何使用Java中... [详细]
该博客教程旨在帮助初学者了解如何在Java前端和MySQL数据库之间建立连接。通过简单易懂的指导,教程覆盖了从前端到后端的完整流程。首先,它介绍了Java编程语言的基础知识,为初学者提供了必要的背景。接着,教程引导读者学习如何使用Java中... [详细]赞
踩
- 开发工具:Eclipse/IDEAJDK版本:jdk1.8Mysql版本:5.7Java+Swing+Mysql主要功能包括1.管理学生信息,其中包括添加,删除,修改等操作。2.管理课程信息,其中包括添加,删除,修改等操作。3.管理选课信息... [详细]
赞
踩
- 要出栈时,如果栈二不为空,就出栈二中的元素,如果栈二为空,将栈一中的所有元素一次性的全部push到栈二中,此时就将入栈的元素全部倒转过来了,(例如入栈时在栈中的入栈顺序依次排序为182535,栈二中此时的元素入栈顺序是352518,出栈时就... [详细]
赞
踩
 Java19的未来:新特性、性能优化和更多Java19的未来:新特性、性能优化和更多目录 前言 新特性的引入1.模式匹配的扩展 2.增强的模式匹配异常处理 3.基于记录的反射 4.引入静态方... [详细]
Java19的未来:新特性、性能优化和更多Java19的未来:新特性、性能优化和更多目录 前言 新特性的引入1.模式匹配的扩展 2.增强的模式匹配异常处理 3.基于记录的反射 4.引入静态方... [详细]赞
踩

