
- 1ARM第五章平时作业
- 2vue中初步使用store缓存获取当前登录用户id_vue3 缓存获取当前用户信息
- 3RC522 NFC IC卡简介_rc522上传数据是什么数据
- 4NISP二级--操作系统安全_操作系统的审计记录应包含如下信息: 事件的源地点
- 5Jmeter 01 -概述&线程组
- 6QueryRunner的使用_queryrunner runner = new queryrunner(jdbcutils.get
- 7python——开发2022年过年烟花小程序_龙年春节python
- 8Task1.2 A.I. 发展史_希腊的金色机器人
- 9“一带一路”国际国际方案CCG报告-万祥军 |国家(中国)智库
- 10Qt动画框架详解_qt ui动画
深度学习04—反向传播算法(用于参数更新、troch实现)_反向传播实例及代码
赞
踩
目录
2.2 二次模型y=w1x²+w2x+b,损失函数loss=(ŷ-y)²
好文推荐:
PyTorch 深度学习实践 第4讲_错错莫的博客-CSDN博客
PyTorch学习(三)--反向传播_陈同学爱吃方便面的博客-CSDN博客_pytorch 反向传播
学习地址(B站刘老师) :
04.反向传播_哔哩哔哩_bilibili
1.基本原理
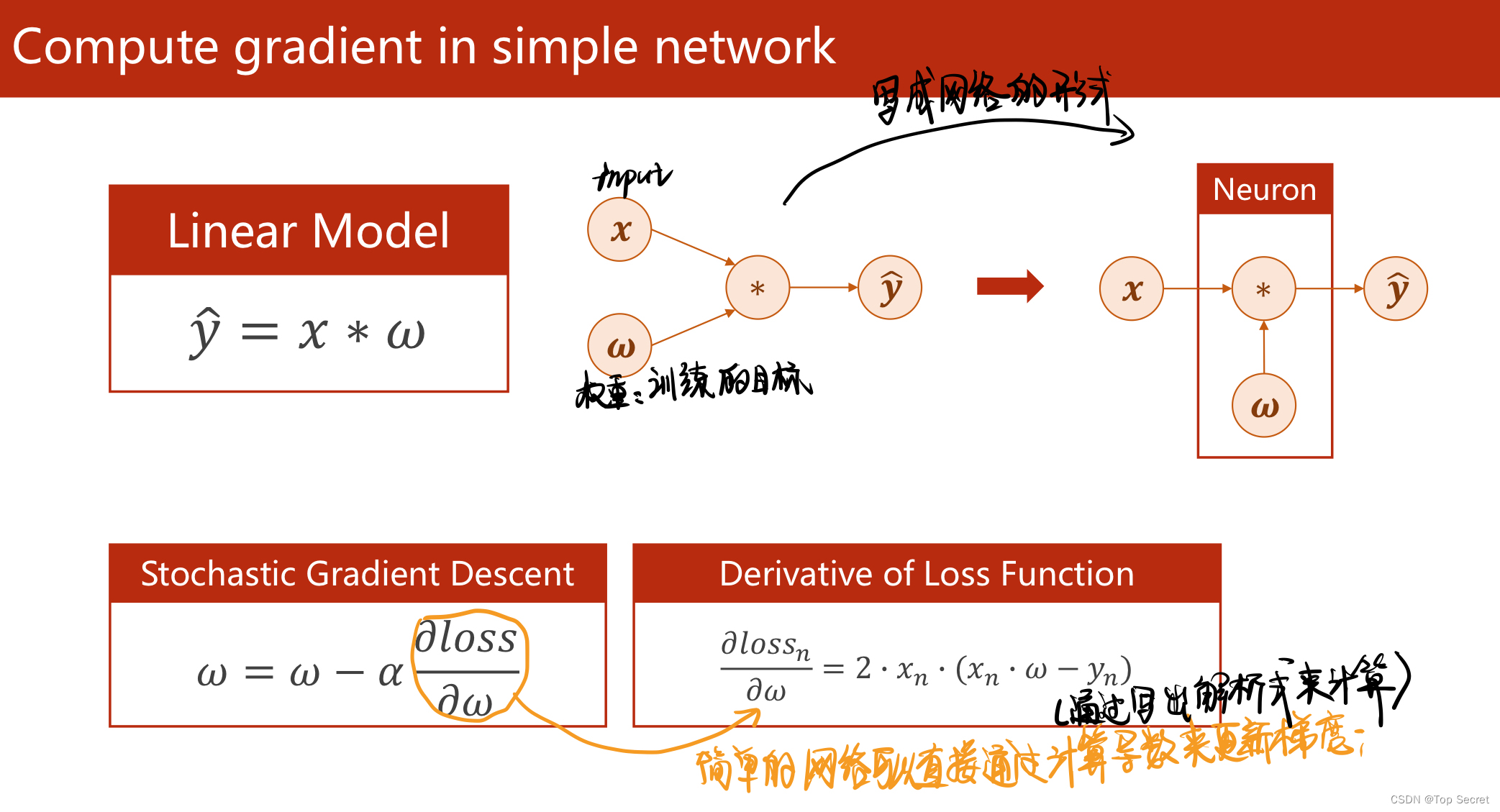
1.1 直接用求导的解析式来更新参数
简单的网络可通过解析式表示参数更新的过程。
对于复杂网络,利用“反向传播算法”来计算梯度;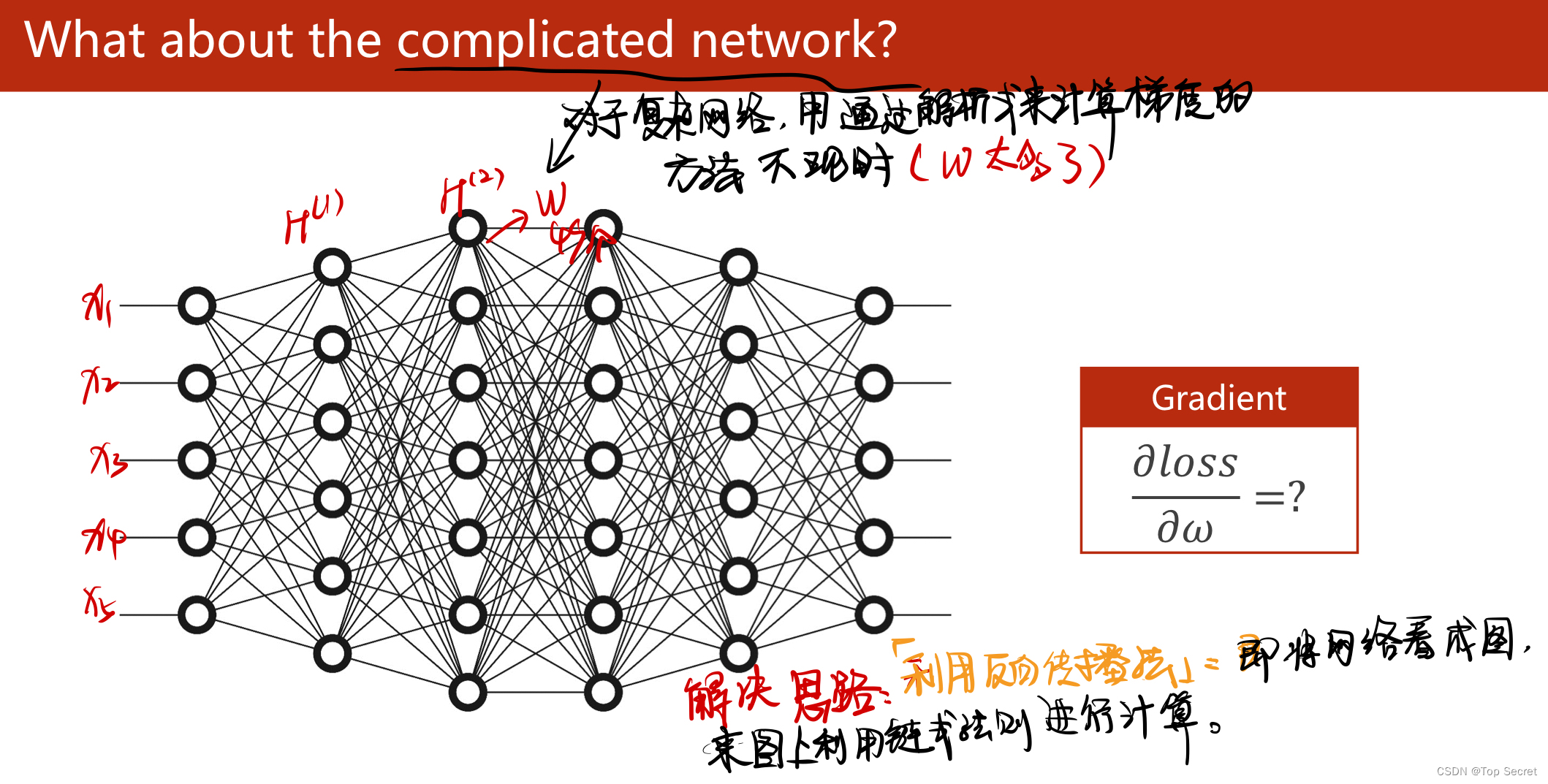
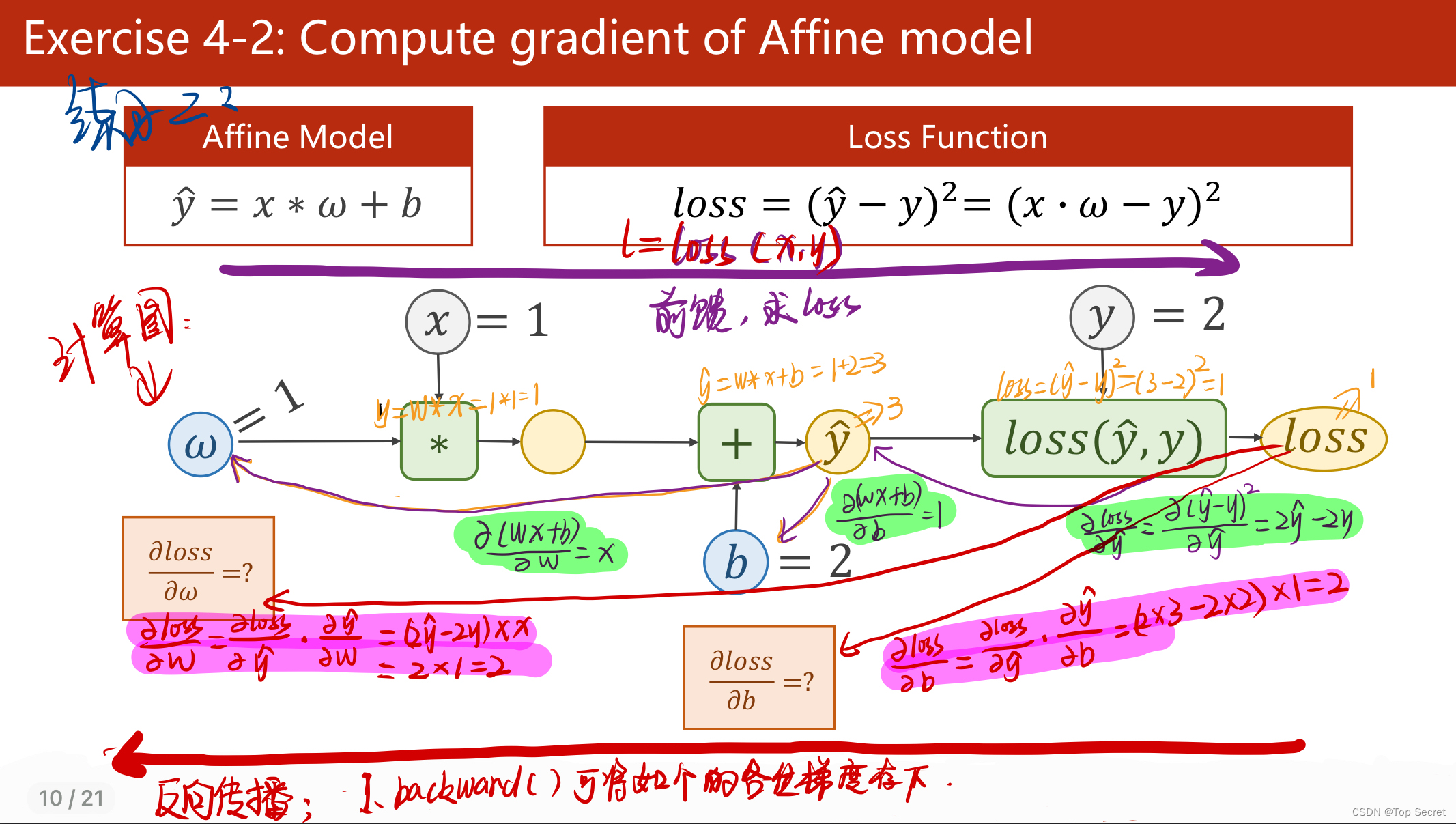
1.2 反向传播的原理
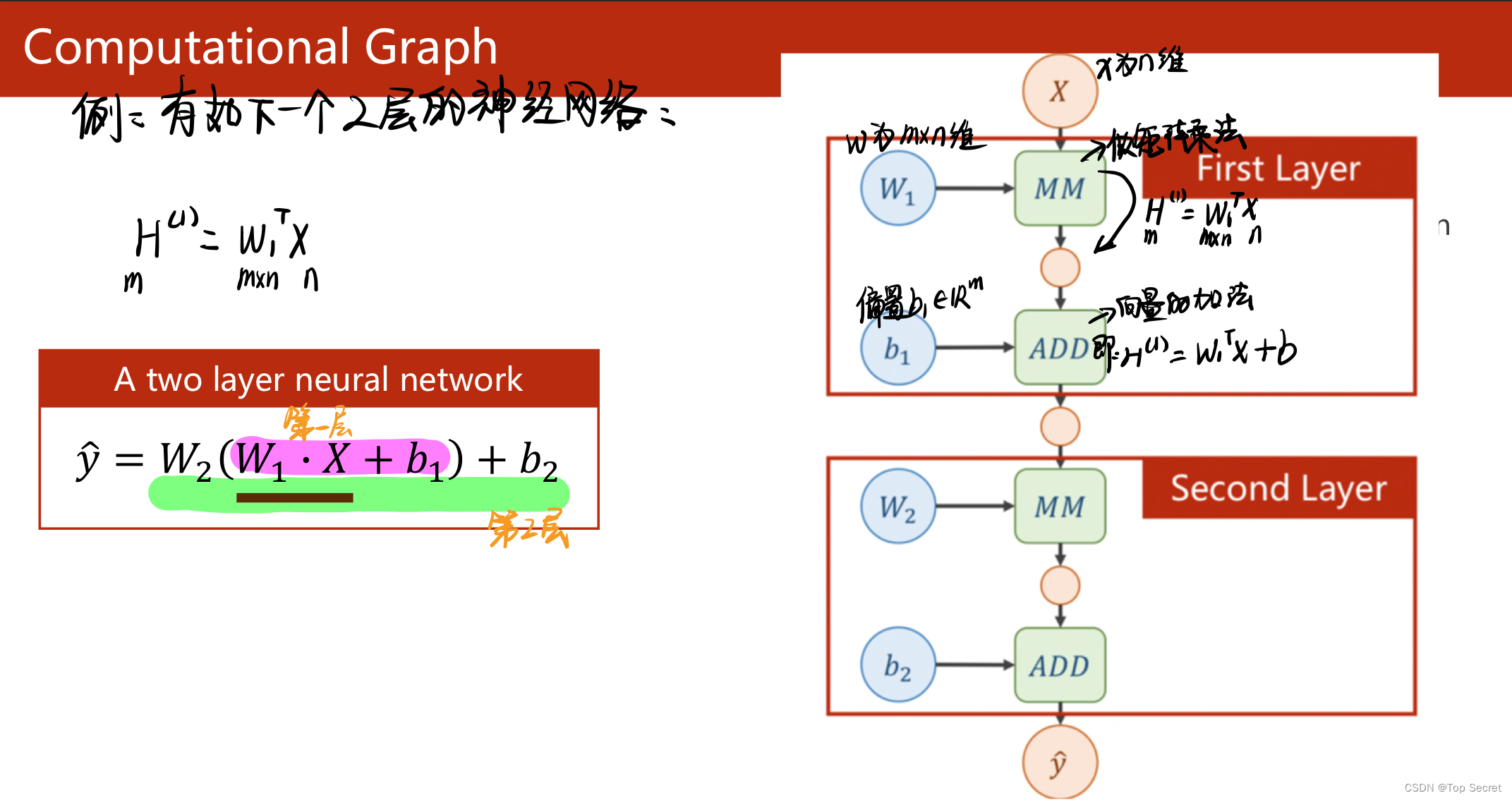
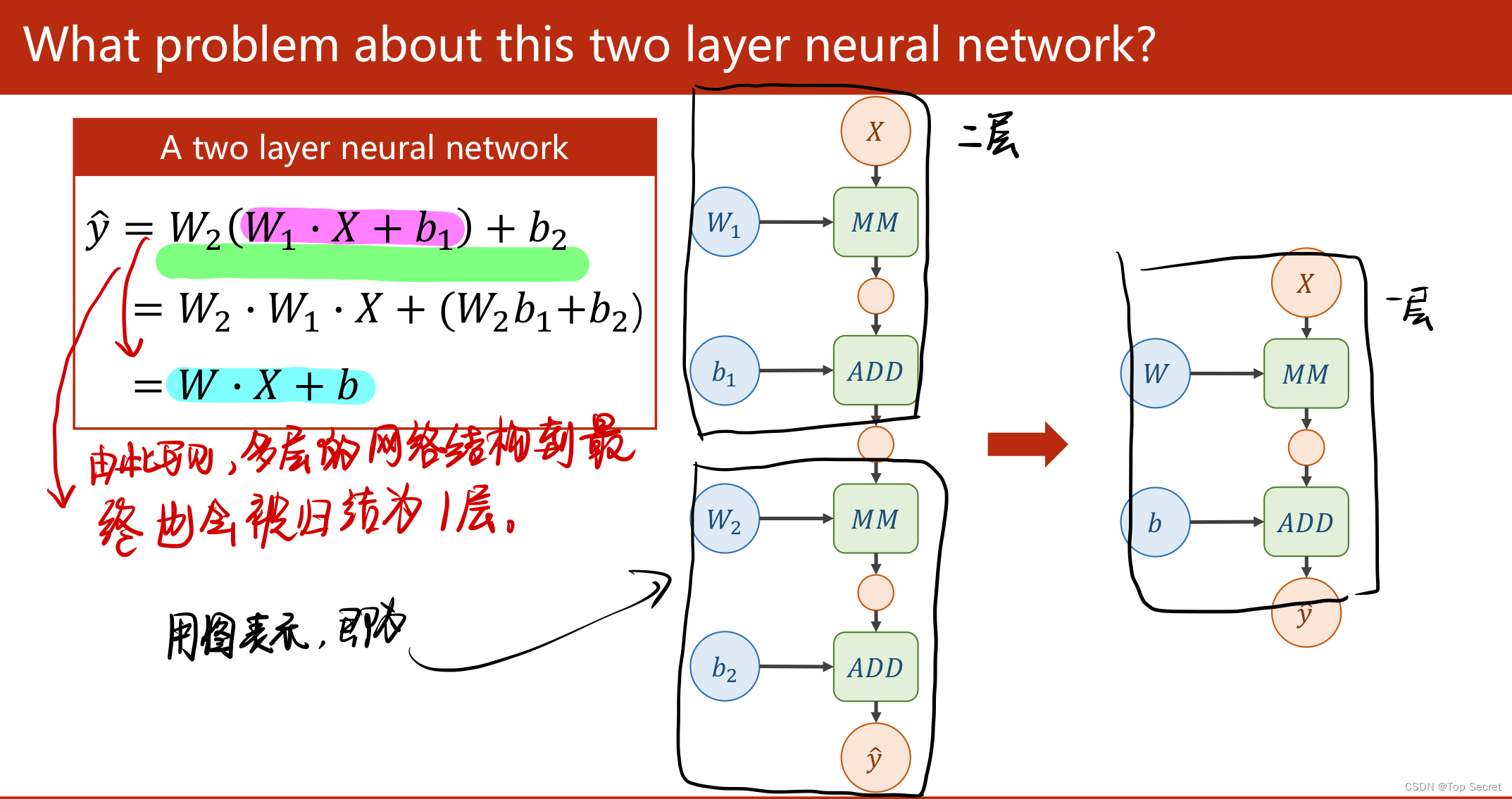
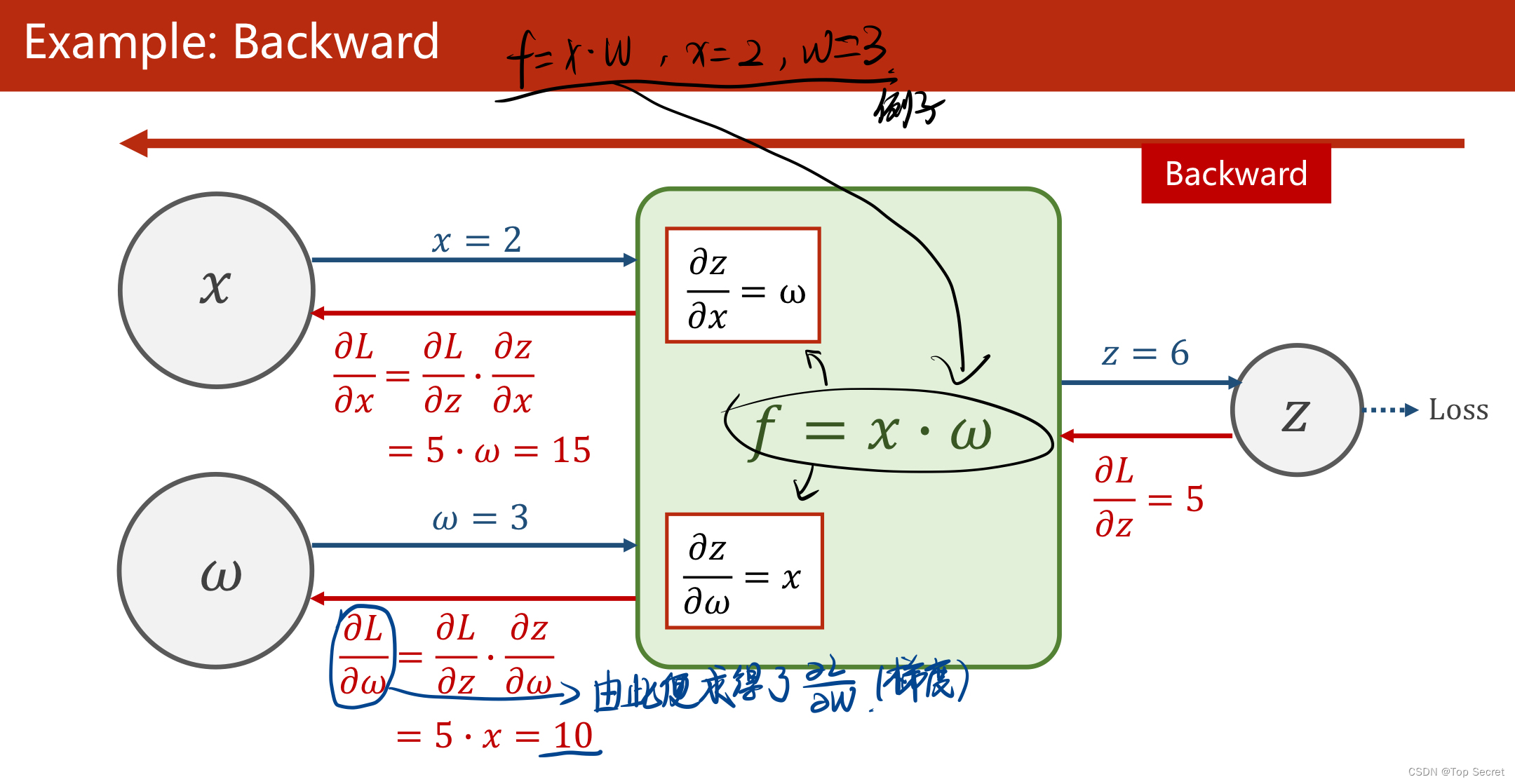
通过分析神经网络的计算图来推演反向传播算法在参数更新中的应用。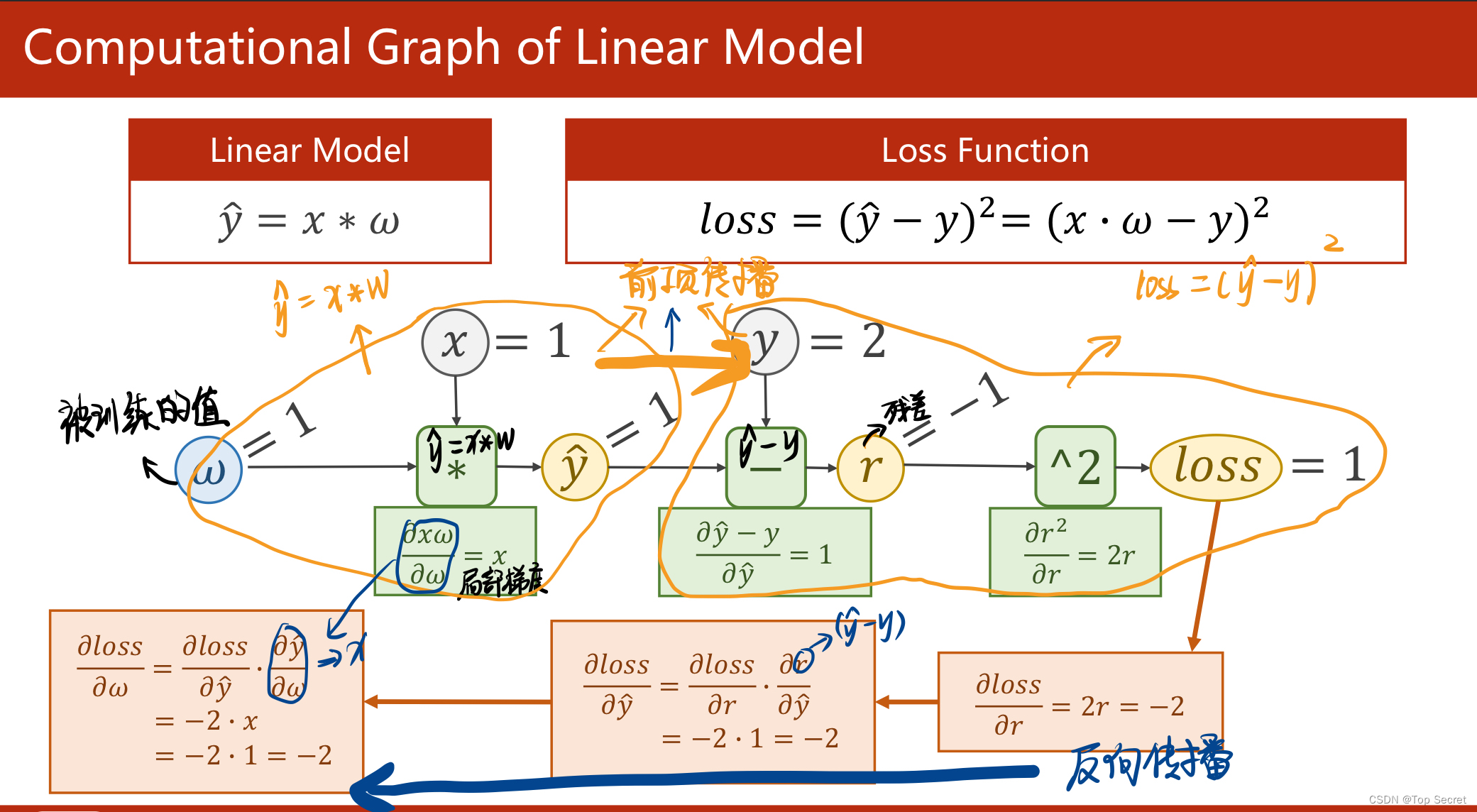
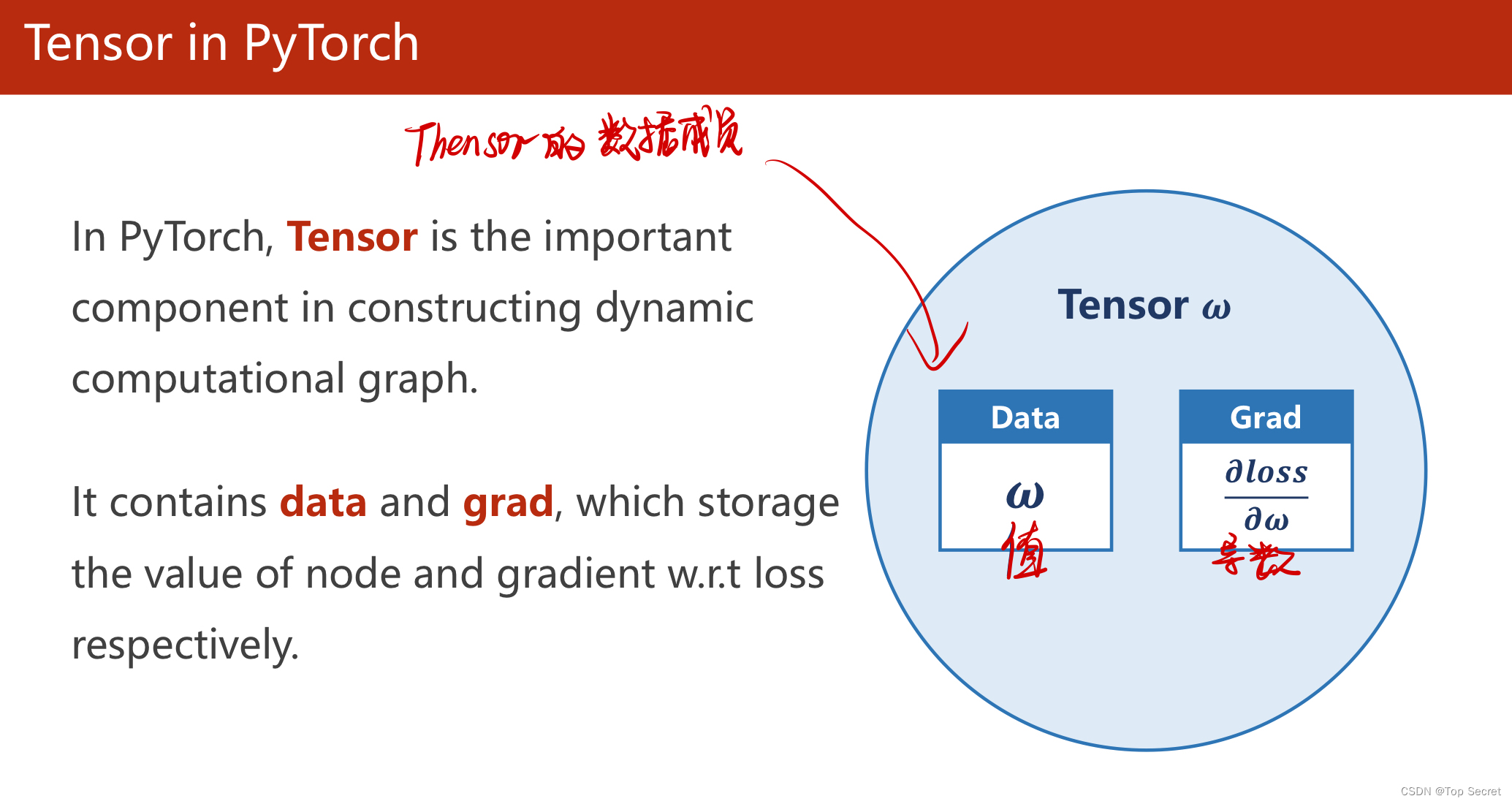
1.3 tensor的存储数据以及基本应用思想
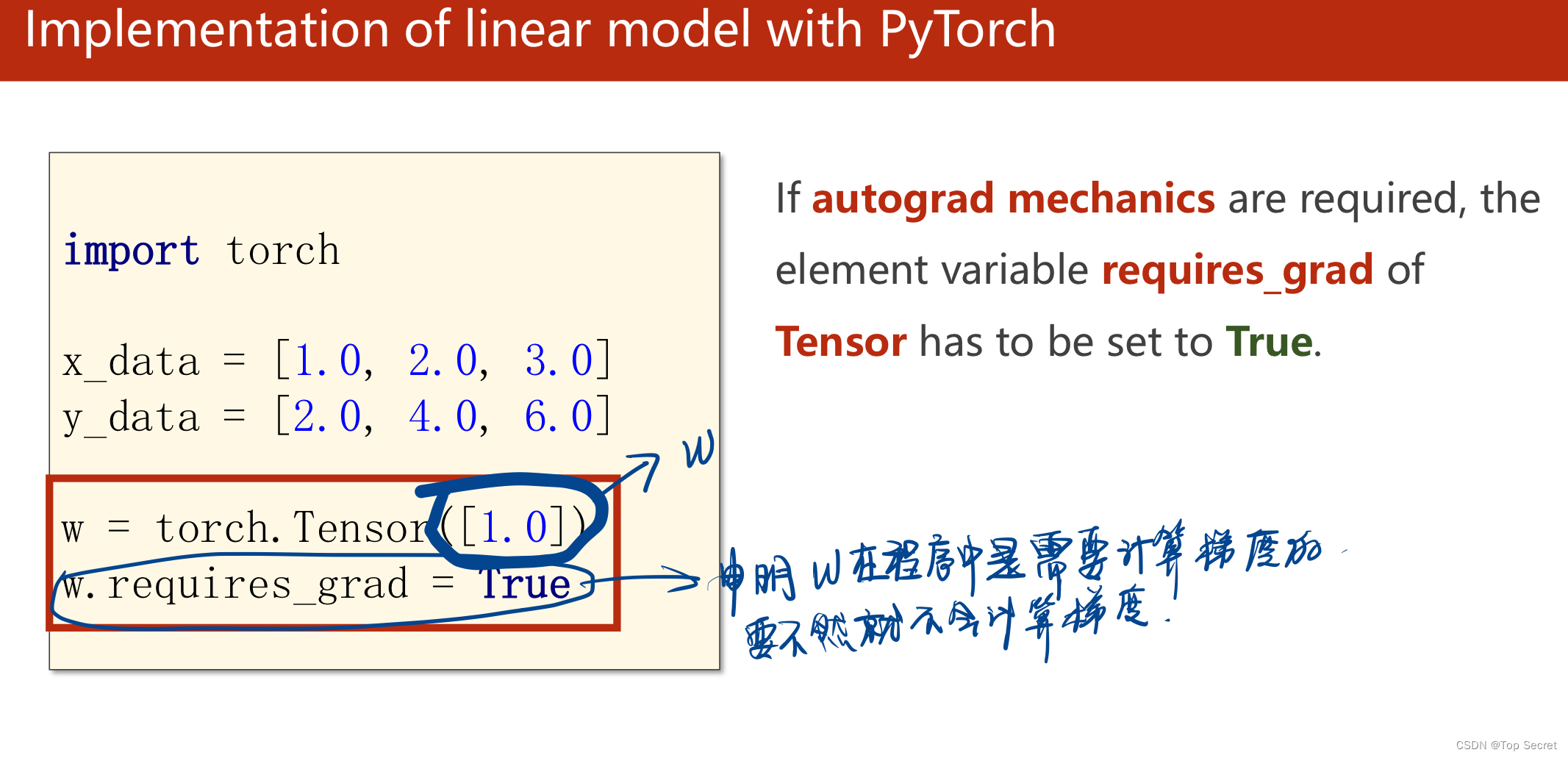





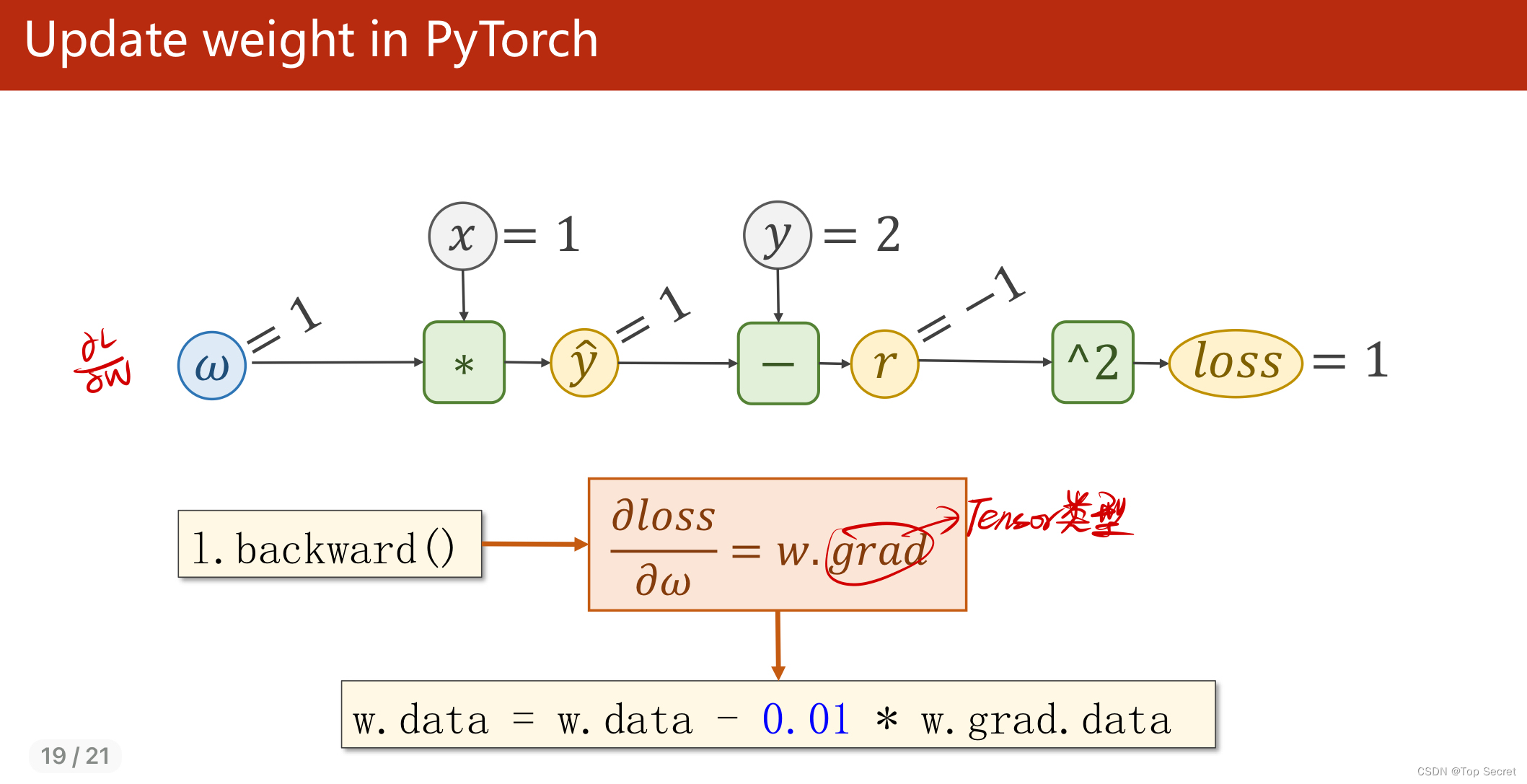
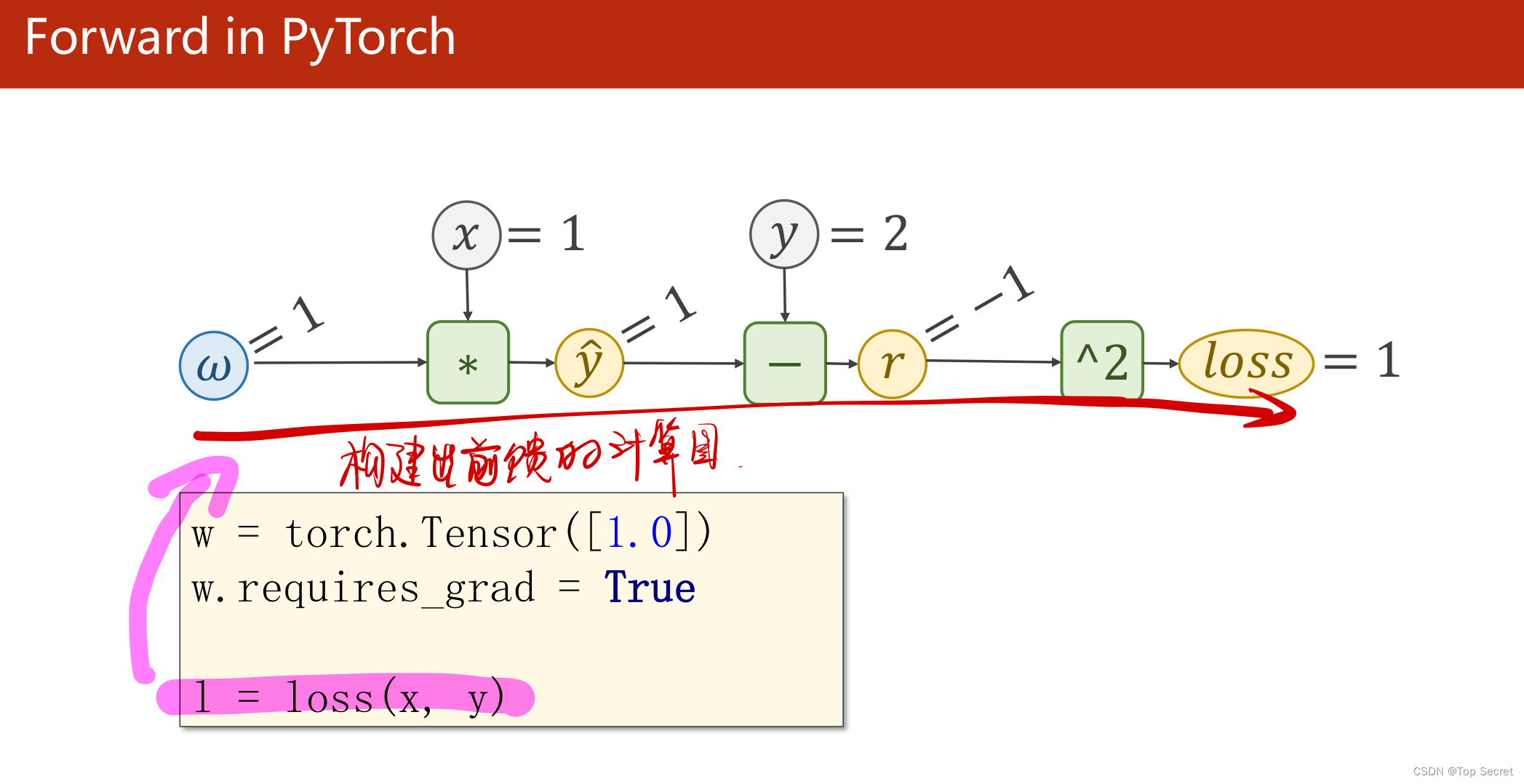

1.4 总结
(1)反向传播:该方法主要是应用链式法则的方法,求loss关于w和b的导数;
(2)关于如下步骤中,l.backward()会将前向的各部梯度存入,而红色的两个代码会形成“计算图”;
(3)其中:w是Tensor(张量类型),Tensor中包含data和grad,data和grad也是Tensor。grad初始为None,调用l.backward()方法后w.grad为Tensor,故更新w.data时需使用w.grad.data。如果w需要计算梯度,那构建的计算图中,跟w相关的tensor都默认需要计算梯度。

(4)w是Tensor, forward函数的返回值也是Tensor,loss函数的返回值也是Tensor.
(5)本算法中反向传播主要体现在,l.backward()。调用该方法后w.grad由None更新为Tensor类型,且w.grad.data的值用于后续w.data的更新。l.backward()会把计算图中所有需要梯度(grad)的地方都会求出来,然后把梯度都存在对应的待求的参数中,最终计算图被释放。取tensor中的data是不会构建计算图的。
2. pytorch反向传播实例
前置:由torch.tensor()创建tensor类型数据;
- import torch
- a = torch.Tensor([1.0])
- a.requires_grad = True # 或者 a.requires_grad_()
- print(a)
- print(a.data)
- print(a.type()) # a的类型是tensor
- print(a.data.type()) # a.data的类型是tensor
- print(a.grad)
- print(type(a.grad))
-
- """
- C:\Users\ZARD\anaconda3\envs\PyTorch\python.exe C:/Users/ZARD/PycharmProjects/pythonProject/机器学习库/PyTorch实战课程内容/backward.py
- tensor([1.], requires_grad=True)
- tensor([1.])
- torch.FloatTensor
- torch.FloatTensor
- None
- <class 'NoneType'>
- Process finished with exit code 0
- """
2.1 完整代码
- import torch
-
- x_data = [1.0, 2.0, 3.0]
- y_data = [2.0, 4.0, 6.0]
-
- w = torch.tensor([1.0]) # w的初值为1.0,是一个tensor
- w.requires_grad = True # 指明参数w需要计算梯度
-
- # 定义一个线性模型:y=x*w
- def forward(x):
- return x * w # w是一个Tensor
-
- #计算损失函数,算出的loss的数据类型为tensor
- def loss(x, y):
- y_pred = forward(x)
- return (y_pred - y) ** 2
-
- print("predict (before training)", 4, forward(4).item()) #打印初始值
-
- #训练数据100次
- for epoch in range(100):
- for x, y in zip(x_data, y_data):
- l = loss(x, y) # l是一个张量,tensor主要是在建立计算图 forward, compute the loss
- l.backward() # backward,compute grad for Tensor whose requires_grad set to True
- print('\tgrad:', x, y, w.grad.item())
- w.data = w.data - 0.01 * w.grad.data # 权重更新时,注意grad也是一个tensor
- #每一次数据的参数更新完成后,都需要对计算图中的梯度记录做一次清理,要不然在下一组数据的更新中将这次的参数与下一次叠加在一起
- w.grad.data.zero_() # after update, remember set the grad to zero
-
- print('progress:', epoch, l.item()) # 取出loss使用l.item,不要直接使用l(l是tensor会构建计算图)
-
- print("predict (after training)", 4, forward(4).item())
运行结果: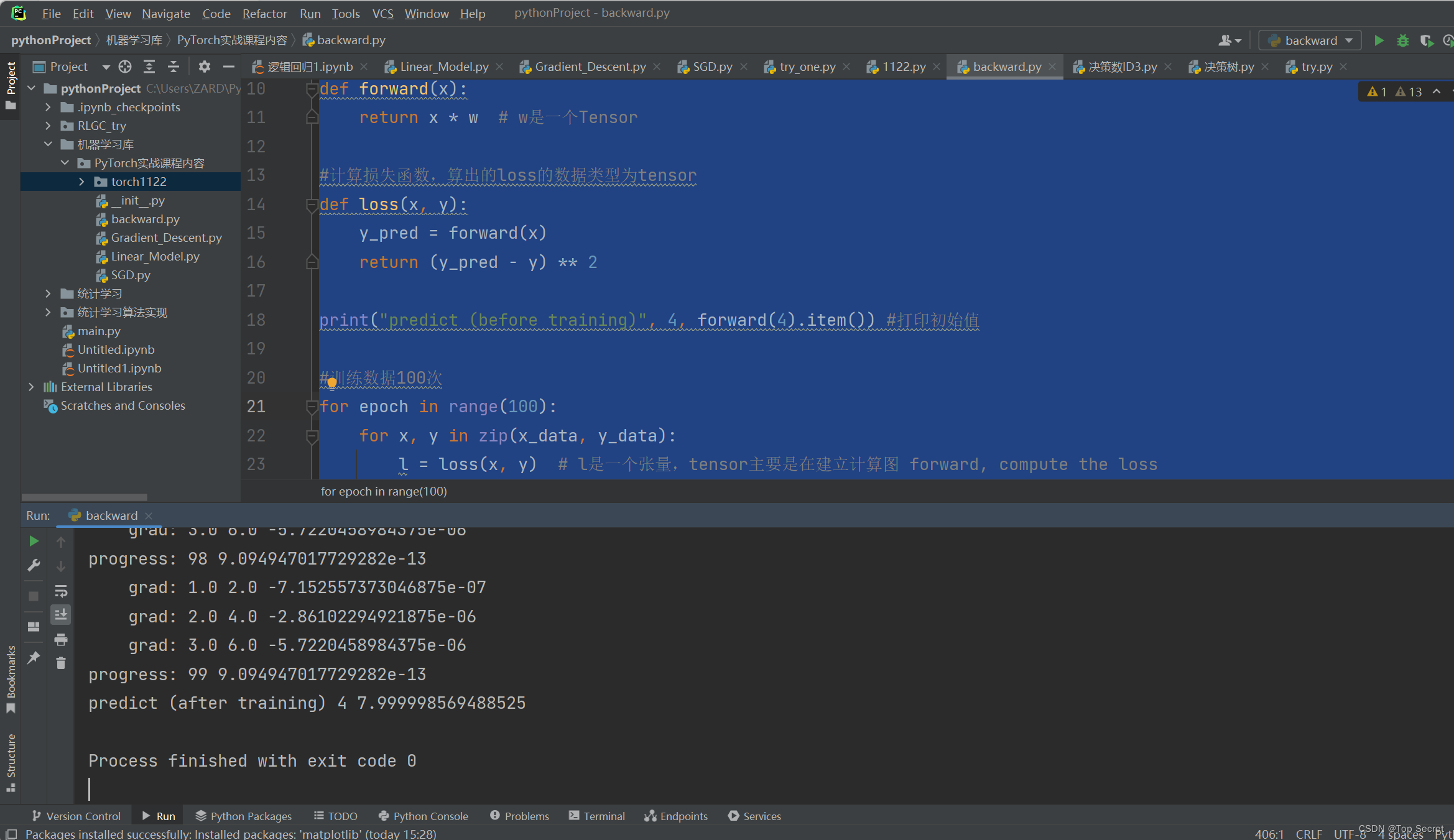
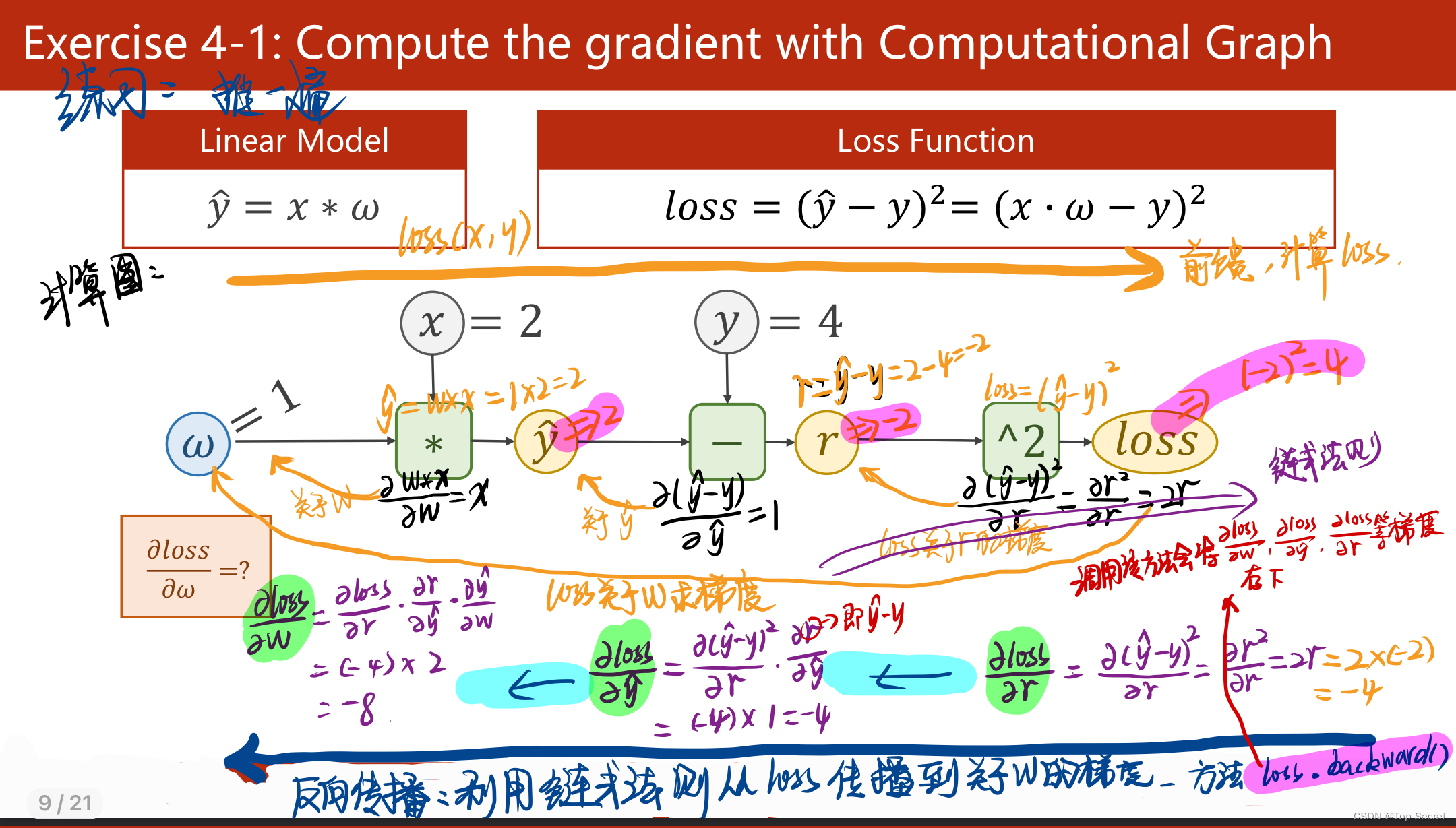
2.2 二次模型y=w1x²+w2x+b,损失函数loss=(ŷ-y)²
画出该模型的计算图:
参考文章,侵删:https://blog.csdn.net/weixin_44841652/article/details/105046519

2.2.1 定义参数w1,w2,b都需要计算梯度
- #模型:y = w1 * x**2 + w2 * x + b
- #如下定义参数w1,w2,b都需要计算梯度
- w1 = torch.Tensor([1.0])#初始权值
- w1.requires_grad = True#计算梯度,默认是不计算的
- w2 = torch.Tensor([1.0])
- w2.requires_grad = True
- b = torch.Tensor([1.0])
- b.requires_grad = True
2.2.2 定义训练模型并构建计算图
- # 定义模型:y = w1 * x**2 + w2 * x + b
- def forward(x):
- return w1 * x**2 + w2 * x + b
-
- def loss(x,y):#构建计算图,计算loss
- y_pred = forward(x)
- return (y_pred-y) **2
2.2.3 训练数据
- #训练数据100次
- for epoch in range(100):
- l = loss(1, 2)#为了在for循环之前定义l,以便之后的输出,无实际意义
- for x,y in zip(x_data,y_data):
- #step1: 计算loss,l.backward()构建计算图;
- l = loss(x, y)
- l.backward()
- print('\tgrad:',x,y,w1.grad.item(),w2.grad.item(),b.grad.item())
-
- #step2: 参数更新,并释放各参数对应的梯度
- w1.data = w1.data - 0.01*w1.grad.data #注意这里的grad是一个tensor,所以要取他的data
- w2.data = w2.data - 0.01 * w2.grad.data
- b.data = b.data - 0.01 * b.grad.data
- # 释放之前计算的梯度(如下可见,释放的梯度是相对与每一个需要被计算梯度的tensor数据相对应的)
- #因此,简记为: w1.requires_grad = True 与 w1.grad.data.zero_() 成对出现
- w1.grad.data.zero_()
- w2.grad.data.zero_()
- b.grad.data.zero_()
-
- #step3:输出每次训练的损失
- print('Epoch:',epoch,l.item()) #读取每一次训练得到的loss值,用l.item()
该过程可以简单总结为3部分:
(1)计算loss,l.backward()构建计算图;
(2)参数更新,并释放各参数对应的梯度;
(3)输出每次训练的损失;
输出:
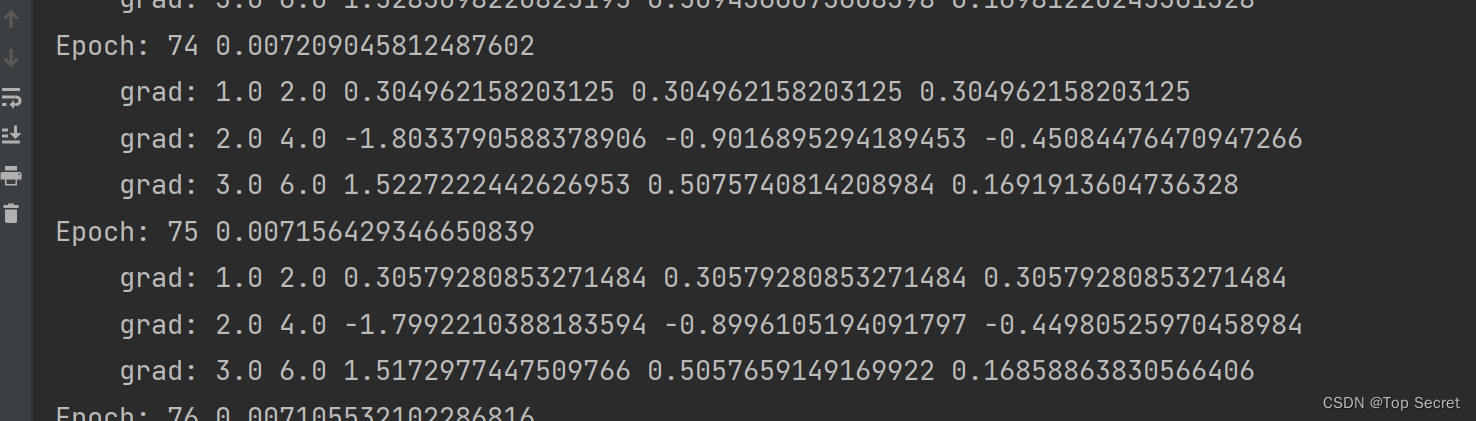
复盘总结:
理论的Tips:
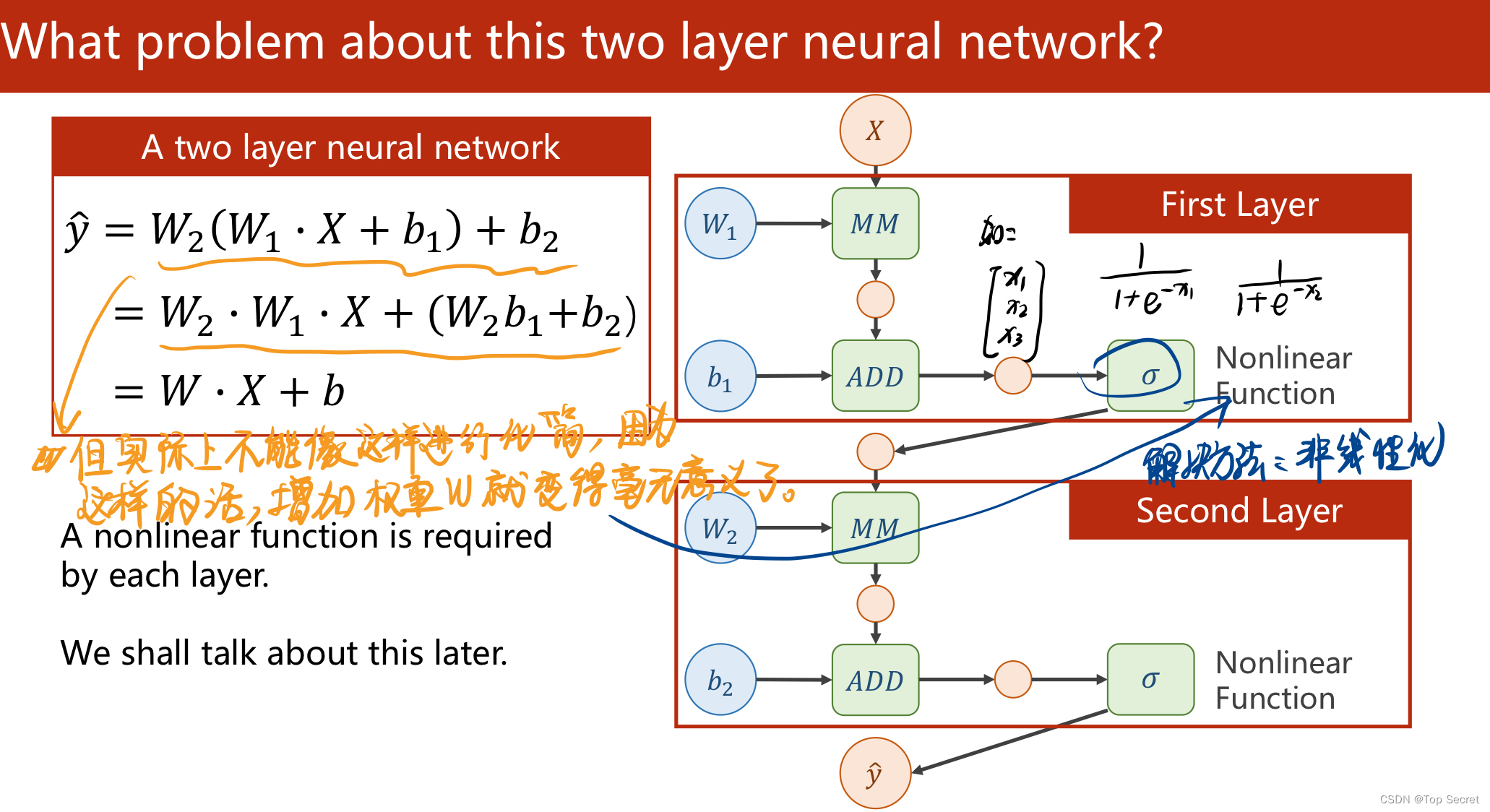
(1)对于简单的网络,可通过解析式表示参数更新的过程;
(2)对于复杂网络,利用“反向传播算法”来计算梯度;
(3)通过分析神经网络的计算图来推演反向传播算法在参数更新中的应用。 (先分析前馈过程,再分析反向传播的过程)
编程的Tips:
(1) 对于某个需要计算导数的张量,比如权重w,在定义好w后,要声明需对其计算梯度,语法是:w.requires_grad = True
- 1.Android长按home键呼出应用列表和切换应用,然后右滑则终止应用;2.多分辨率测试,Android端20多种,ios较少;3.手机操作系统,Android较多,ios较少且不能降级,只能单向升级;新的ios系统中的资源库不能完全兼... [详细]
赞
踩
- 题目描述:输入一个整数,将这个整数以字符串的形式逆序输出程序不考虑负数的情况,若数字含有0,则逆序形式也含有0,如输入为100,则输出为001方式一:#include
usingnamespacestd;intmain()... [详细] 赞
踩
- 在日常的生活中有时候循环的次数通常不会在刚开始就知道,而是满足条件之后就停止循环,如有一路公交车不是固定时间间隔发车,而是在人数满足多少个之后就发车,一直到晚上的11点准时收工,那么没有到11点的话就会一直重复,直到条件不满足时才结束的循环... [详细]
赞
踩
- 进度条最终效果如下,上面是一个进度条进度,进度通过线条颜色来控制:蓝色表示已达到该进度,黑色表示未达到;下方是两个按钮来控制整体进度条的进度:点击Prev按钮减少进度,Next来增加进度;首先创建一个index.html,补充页面中的标签元... [详细]
赞
踩
- 其实完成这一段,即使提示无法定位软件包dkms,也可以打开realsense-viewer了,如果打不开再进行后续的步骤。完成后即可启动realsense-viewer。首先从源码处下载对应压缩包并解压。_ubuntu20.04realse... [详细]
赞
踩
- 2023最新自动化测试自学教程新手小白26天入门最详细教程,目前已有300多人通过学习这套教程入职大厂!!_哔哩哔哩_bilibili2023最新合集Python自动化测试开发框架【全栈/实战/教程】合集精华,学完年薪40W+_哔哩哔哩_b... [详细]
赞
踩
- 我们在开发中,应用程序会保存少量数据,例如一些字符串、一些标记或者一些配置文件,这时候如果去使用SQLite保存这些数据的话,难免会显得大材小用,用起来也不方便,对于这种信息,保存在SharedPreferences中在合适不过了。一、... [详细]
赞
踩
- 一、踩了一天在树莓派3搭建tensorflow并进行物体识别验证成功步骤:1、 更新国内源2、 安装tensorflow直接用下载的whl文件3、 利用手头现成的classify.py文件和inception.gz,注意用sudomkdir... [详细]
赞
踩
- 部门高德打车体验最好的一次面试,面试官会慢慢引导很有耐心,答错了也会挨个指导自我介绍,然后面试官也开始介绍面试流程,按css,js,浏览器,最后框架和手写代码。双非硕女,电子科学与技术专业,西安人,目前宝鸡某国企子公司和北京某航天私企,北京... [详细]
赞
踩
- 本来感觉这个title看起来有点离谱,结果没想到仔细一看,这份资料竟然真的有点东西。内容收纳的很全,而且融合了很多今年的新玩意。据我所知有人靠它拿下了45k+的offer…_软件测试offer收割机养成指南软件测试offer收割机养成指南前... [详细]
赞
踩
- 本文介绍了安装RHEL9的步骤,包括选择虚拟机类型、安装系统和关闭屏保等步骤。rhce9要安装RHEL9,可以在虚拟机中安装RHEL9系统,先要根据习惯选择虚拟机的类型,可以选择vmwareworkstation,也可以选择VirtualB... [详细]
赞
踩
- 确保你的系统中已经安装了Python,并且系统的环境变量中包含了Python的安装路径。可以使用一个批处理文件(.bat)来实现这个目标。以下是一个简单的例子,假设你的脚本文件名为。这个脚本首先将当前工作目录切换到批处理文件所在的目录,然后... [详细]
赞
踩
- 文章目录CPU1.动态批处理2.静态批处理3.共享材质4.应用场景GPU一、减少需要处理的顶点数目优化几何体LOD技术遮挡剔除技术二、减少需要处理的片元数目控制绘制顺序当心半透明物体减少实时光照和阴影三、节省带宽减少纹理大小利用分辨率缩放四... [详细]
赞
踩
- 论文地址:《2016PAMIHyperFace:ADeepMulti-taskLearningFrameworkforFaceDetection,LandmarkLocalization,PoseEstimation,andGenderRe... [详细]
赞
踩
- 1、确认期望薪资薪资问题如何回答,首先得确认自己的底牌;你的期望薪资是多少?职业的价值通常与工作经验,专业能力,所在城市,行业情况,学历背景等因素有关系,简单来说:随行就市。1.评估自身与应聘职位的匹配度;2.了解业内行情(招聘求职网站或者... [详细]
赞
踩
- http://blog.chinaunix.net/u1/38994/article_56618.htmlhttp://sources-redhat.mirrors.airband.net/ecos/releases/ecos-3.0/ht... [详细]
赞
踩
- 回归预测|Matlab基于OOA-LSSVM鱼鹰算法优化最小二乘支持向量机的数据多输入单输出回归预测回归预测|Matlab基于OOA-LSSVM鱼鹰算法优化最小二乘支持向量机的数据多输入单输出回归预测回归预测|Matlab基于OOA-LSS... [详细]
赞
踩
- 另一方面,在服务器不需要先前信息时它的应答就较快。自动化测试与软件开发本质上是一样的,利用自动化测试工具,经过测试需求分析,设计出自动化测试用例,从而搭建自动化测试的框架,设计与编写自动化脚本,验证测试脚本的正确性,最终完成自动化测试测试脚... [详细]
赞
踩
- 软考中级学习笔记【软件设计师笔记】程序语言设计考点... [详细]
赞
踩
- article
C语言反转一个整数(不使用数组) 给定一个整数,请将该数各个位上数字反转得到一个新数。新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零。_定义函数将一个整数以个位为轴对折,生成一个新的整数 例如输入123,生成12321
输入格式一个整数N输出格式一个整数,表示反转后的新数。输入输出样例:输入样例1:123;输出样例1:321;输入样例2:-380;输出样例2:-83;#includeintmain(){intN,a,b,c,d,e,f,w... [详细] 赞
踩

