
- 1【深度学习理论】持续更新
- 2ubuntu mysql 编译_Ubuntu下mysql编译安装
- 3二层接口和三层接口的区别_计算机网络中二层环路与三层环路的区别
- 4python -- PyQt5(designer)中文详细教程(五)对话框_qtdesigner 显示dialog对话框的方法
- 5解决git clone与git push出现的若干问题:Failed to connect to github.com port 443: Timed out
- 6Eclipse连接SqlServer_使用eclipse链接sqlserver语句
- 72022年最新前端面试题(大前端时代来临卷起来吧小伙子们..持续维护走到哪记到哪)_打字机效果 当滚动条在页面最下方时 滚动条保持在底部
- 8使用node.js实现接口步骤_node接口
- 9Codeforce -990A【模拟】_codeforces - 990a
- 10数据结构——排序算法总结(八个)_数据结构排序
Java调试终端乱码问题_java远程调试显示错乱怎么解决
赞
踩
1.调试终端乱码问题
VScode官网中终端网站: https://code.visualstudio.com/docs/editor/integrated-terminal
1.1 命令控制行cmd中文乱码
WIN+R,输入cmd,输入chcp查看编码方式

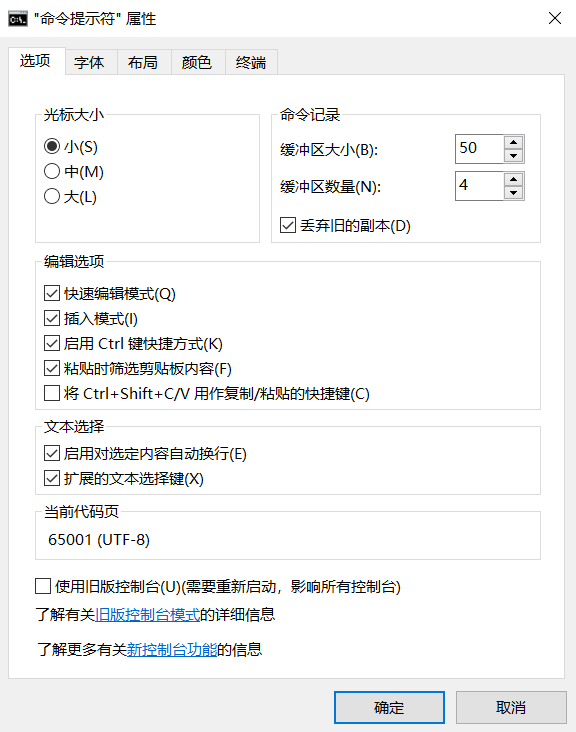
说明cmd默认使用GBK编码,需要输入:chcp 65001,修改为utf-8编码
右键选择属性,勾选丢弃旧的副本,实现永久更改
1.2 VScode调试终端乱码问题
解决方法:
File–>Preference–>Settings
在搜索框中输入terminal.integrated.shellArgs.windows
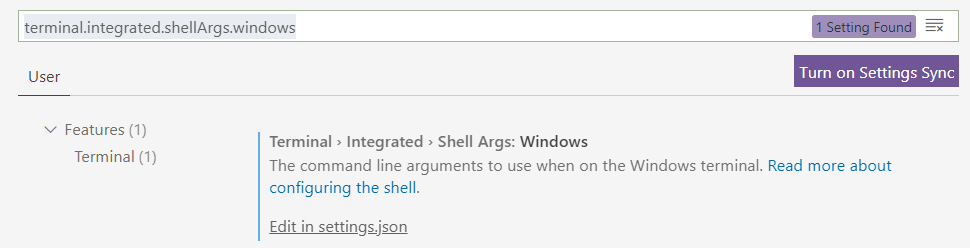
点击下面的Edit in settings.json
加入下面代码
"terminal.integrated.shellArgs.windows": ["-NoExit", "/c", "chcp 65001"]
- 1
1.3乱码原因
字符串是系统把内存中的编码信息读取显示出来,当保存文件时系统就会把这个文件以我们所设置的编码方式编码,再放入内存中。
ASCII码
ASCII码使用7位2进制数表示一个字符,7位2进制数可以表示出2的7次方个字符,共128个字符,编码范围是0x00-0x7F。32 ~ 126(共95个)是字符(32sp是空格),其中48 ~ 57为0到9十个阿拉伯数字,65 ~ 90为26个大写英文字母,97~122为26个小写字母,其余为一些标点符号、运算符号等。
GBK编码
GBK编码是国家制定的一个专门用于编码汉字的一套编码方式。字符有一字节和双字节编码,00–7F范围内是一位,和ASCII保持一致,此范围内严格上说有96个字符和32个控制符号。之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。
Unicode编码
如果有一种编码,将世界上所有的符号都纳入其中,无论是英文、日文、还是中文等,大家都使用这个编码表,就不会出现编码不匹配现象。每个符号对应一个唯一的编码,乱码问题就不存在了。这就是Unicode编码。Unicode固然统一了编码方式,但是它的效率不高,比如UCS-4(Unicode的标准之一)规定用4个字节存储一个符号,那么每个英文字母前都必然有三个字节是0,这对存储和传输来说都很耗资源。
UTF-8编码
UTF-8是一种针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符。
由此可见,使用GBK编码的字符只占用两个字节,使用UTF-8编码要占用三个字节,因此会出现乱码
参考资料:
彻底理解字符编码 http://www.cnblogs.com/leesf456/p/5317574.html
字符编码笔记 http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
计算机字符编码详解——从理论到实践 https://blog.csdn.net/xuejianhui/article/details/52650825
- 桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。分别用JavaScript,Java,PHP,C++实现桶排序的算法(附带源码)... [详细]
赞
踩
- 一、下载二、安装1、双击下载的程序包,出现如图所示2、点击下一步3、继续下一步,会出现弹框,点击确定4、点击确定,会出现安装jre的提示,点击下一步即可5、等待安装完成6、之后窗口左侧会有一个弹框,把它拉出来即可7、点击关闭三、接下来进行环... [详细]
赞
踩
- Java开发环境配置_在本地运行一个java项目在本地运行一个java项目在本章节中我们将为大家介绍如何搭建Java开发环境。Windows上安装开发环境Linux上安装开发环境安装Eclipse运行Javawindow系统安装java下载... [详细]
赞
踩
- 本小节我们将介绍如何在Windows平台安装Java。由于微软已正式终止对Win7操作系统的支持,作为新时代的程序员,我们使用Win10操作系统来进行安装演示。如果你想在其他平台安装Java,请查看对应平台的安装教程:1.下载安装包我们首先... [详细]
赞
踩
- 一、下载进入官网(https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)下载所需版本安装包二、安装1、双击打开程序包2、点击... [详细]
赞
踩
- 一类是JDK其是Java的开发环境,不过在JDK的发布包中包含了一个独立的JRE,另外需要注意JDK本身就内置有JRE。Windows8,10的Path变量配置要友好一些,直接配置一条记录即可,如果是Windows7的话,需要在Path变量... [详细]
赞
踩
- 2023年最新教程:简要介绍Java编程语言并手把手教你搭建Java的开发环境,超级详细哦!_java开发环境java开发环境图片来源于互联网目录|CONTENTJava简介一、什么是Java二、认识Java版本三、选择哪个版本比较好搭建J... [详细]
赞
踩
- 如何搭建java环境,安装ide软件,配置maven仓库整套详情步骤流程_java开发环境的搭建步骤java开发环境的搭建步骤文章目录前提准备搭建环境流程安装ide软件导入到ide项目包加载慢,搭建maven环境打开ide配置maven前提... [详细]
赞
踩
- java环境配置,网上教程很多,那我为什么还要写?首先为了完善我的知识体系今后一些软件的安装教程也可能会用到想写一个更加详细的,因为这并不仅仅是写给IT行业的,其它行业可能也需要配置java环境提示:以下是本篇文章正文内容,下面案例可供参考... [详细]
赞
踩
- 简单实践javaspringboot自动配置模拟简单实践javaspringboot自动配置模拟1.概要1.1需求,自己写一个redis-spring-boot-starter模拟自动配置自动配置就是在引入*-starter坐标后,可以已经... [详细]
赞
踩
- 快递管理系统包含的快递区域模块、快递货架模块、快递类型模块和快递档案模块,还包含系统自带的用户管理、部门管理、角色管理、菜单管理、日志管理、数据字典管理、文件管理、图表展示等基础模块,快递管理系统基于角色的访问控制,给快递管理员和快递工作人... [详细]
赞
踩
- Autowired//Mybatisplus查询student表中的数据返回List类型//相当于:SELECTstu_id,stu_name,stu_sex,date,room,acadimyFROMstudentListlist=stu... [详细]
赞
踩
- SpringBoot是当下最流行的JavaWeb开发框架之一,它有着极高的可扩展性和灵活性,同时还可以极大提高开发效率。在本文中,我们将会深入探究SpringBoot的各个方面,包括SpringBoot基础、SpringBoot数据库操作、... [详细]
赞
踩
- 1.什么是SpringBootSpringBoot是Spring社区较新的一个项目。该项目的目的是帮助开发者更容易的创建基于Spring的应用程序和服务,让更多人的人更快的对Spring进行入门体验,为Spring生态系统提供了一种固定的、... [详细]
赞
踩
- 网上很多写的都比较复杂,然后这里有一个很简单的Dockerfile就可以很容器的构建出镜像,而且读起来和很容易Dockerfile#指定基础镜像FROMjava:8-alpineCOPY./docker-demo.jar/tmp/app.j... [详细]
赞
踩
- 小简选择的是最后一个,第一个也还行吧,但是Google那个不需要本地有Docker环境,第一个我还是开着魔法(梯子)打包的,最后一个挺好的。看情况选择的,很久没更新啦!越来越懒了,嘿嘿,下篇再见。_springboot打包镜像springb... [详细]
赞
踩
- 有许多应用程序和网站只有在安装java后才能正常工作,而且这样的应用程序和网站日益增多。java快速、安全、可靠。从笔记本电脑到数据中心,从游戏控制台到科学超级计算机,从手机到互联网,java无处不在什么是JavaAutoUpdate?自动... [详细]
赞
踩
- 今日内容1计算机基础知识1.1键盘功能键和快捷键A:键盘功能键a:Tabb:Shiftc:Ctrld:Alte:空格 f:Enterg:Windowh:上下左右键B:键盘快捷键a:Ctrl+A 全选b:Ctrl+C 复制c:Ctrl+V 粘... [详细]
赞
踩
- JDK64位,适用于WIN64位系统JDK,全名是JavaSEDevelopmentKit,Java的研发环境,使用最广泛的JavaSDK,JDK是研发与编译JAVA程序,必不可少的环境,64位的JDK解压出来就是jdk-7u51-wind... [详细]
赞
踩
- 1、下载安装jdk7.0forlinux我下载的版本为:jdk-7u2-linux-i586.rpm下载地址为:http://www.oracle.com/technetwork/java/javase/downloads/jdk-7u2-... [详细]
赞
踩

