编辑这个页面须要登录或更高权限!
- 您刚才的请求只有这个用户组的用户才能使用:自动确认用户
- 如果您还没有登录请登录后重试。编程那点事是一个开放式网站,修改本站大部分内容仅须要花10秒钟时间创建一个账户。 如果您已经登录,本页面可能是受保护的内容。如果您认为有修改的必要,请联系本站管理人员。
- 该页面已被锁定以防止编辑。
R 数据类型
数据类型指的是用于声明不同类型的变量或函数的一个广泛的系统。
变量的类型决定了变量存储占用的空间,以及如何解释存储的位模式。
R 语言中的最基本数据类型主要有三种:
数字
逻辑
文本
数字常量主要有两种:
| 一般型 | 123 -0.125 |
|---|---|
| 科学计数法 | 1.23e2 -1.25E-1 |
逻辑类型在许多其他编程语言中常称为布尔型(Boolean),常量值只有 TRUE 和 FALSE。
注意:R 语言区分大小写,true 或 True 不能代表 TRUE。
最直观的数据类型就是文本类型。文本就是其它语言中常出现的字符串(String),常量用双引号包含。在 R 语言中,文本常量既可以用单引号包含,也可以用双引号包含,例如:
> 'nhooo' == "nhooo" [1] TRUE
有关于 R 语言的变量定义,并不像一些强类型语言中的语法规则,需要专门为变量设置名称和数据类型,每当在 R 中使用赋值运算符时,实际上就是定义了一个新的变量:
a = 1 b <- TRUE b = "abc"
按对象类型来分是以下 6 种(后面会详细介绍这几种类型):
向量
向量(Vector)在 Java、Rust、C# 这些专门编程的的语言的标准库里往往会提供,这是因为向量在数学运算中是不可或缺的工具——我们最常见的向量是二维向量,这种向量在平面坐标系中必然会用到。
向量从数据结构上看就是一个线性表,可以看成一个数组。
R 语言中向量作为一种类型存在可以让向量的操作变得更加容易:
> a = c(3, 4) > b = c(5, 0) > a + b [1] 8 4 >
c() 是一个创造向量的函数。
这里把两个二维向量相加,得到一个新的二维向量 (8, 4)。如果将一个二维向量和三维向量做运算,将失去数学意义,虽然不会停止运行,但会被警告。
我建议大家从习惯上杜绝这种情况的出现。
向量中的每一个元素可以通过下标单独取出:
> a = c(10, 20, 30, 40, 50) > a[2] [1] 20
注意:R 语言中的"下标"不代表偏移量,而代表第几个,也就是说是从 1 开始的!
R 也可以方便的取出向量的一部分:
> a[1:4] # 取出第 1 到 4 项,包含第 1 和第 4 项 [1] 10 20 30 40 > a[c(1, 3, 5)] # 取出第 1, 3, 5 项 [1] 10 30 50 > a[c(-1, -5)] # 去掉第 1 和第 5 项 [1] 20 30 40
这三种部分取出方法是最常用的。
向量支持标量计算:
> c(1.1, 1.2, 1.3) - 0.5 [1] 0.6 0.7 0.8 > a = c(1,2) > a ^ 2 [1] 1 4
之前讲述的常用的数学运算函数,如 sqrt 、exp 等,同样可以用于对向量作标量运算。
"向量"作为线性表结构,应该具备一些常用的线性表处理函数,R 确实具备这些函数:
向量排序:
> a = c(1, 3, 5, 2, 4, 6) > sort(a) [1] 1 2 3 4 5 6 > rev(a) [1] 6 4 2 5 3 1 > order(a) [1] 1 4 2 5 3 6 > a[order(a)] [1] 1 2 3 4 5 6
order() 函数返回的是一个向量排序之后的下标向量。
向量统计
R 中有十分完整的统计学函数:
| 函数名 | 含义 |
|---|---|
| sum | 求和 |
| mean | 求平均值 |
| var | 方差 |
| sd | 标准差 |
| min | 最小值 |
| max | 最大值 |
| range | 取值范围(二维向量,最大值和最小值) |
向量统计示例:
> sum(1:5) [1] 15 > sd(1:5) [1] 1.581139 > range(1:5) [1] 1 5
向量生成
向量的生成可以用 c() 函数生成,也可以用 min:max 运算符生成连续的序列。
如果想生成有间隙的等差数列,可以用 seq 函数:
> seq(1, 9, 2) [1] 1 3 5 7 9
seq 还可以生成从 m 到 n 的等差数列,只需要指定 m, n 以及数列的长度:
> seq(0, 1, length.out=3) [1] 0.0 0.5 1.0
rep 是 repeat(重复)的意思,可以用于产生重复出现的数字序列:
> rep(0, 5) [1] 0 0 0 0 0
向量中常会用到 NA 和 NULL ,这里介绍一下这两个词语与区别:
NA 代表的是"缺失",NULL 代表的是"不存在"。
NA 缺失就像占位符,代表这里没有一个值,但位置存在。
NULL 代表的就是数据不存在。
示例说明:
> length(c(NA, NA, NULL)) [1] 2 > c(NA, NA, NULL, NA) [1] NA NA NA
很显然, NULL 在向量中没有任何意义。
逻辑型
逻辑向量主要用于向量的逻辑运算,例如:
> c(1, 2, 3) > 2 [1] FALSE FALSE TRUE
which 函数是十分常见的逻辑型向量处理函数,可以用于筛选我们需要的数据的下标:
> a = c(1, 2, 3) > b = a > 2 > print(b) [1] FALSE FALSE TRUE > which(b) [1] 3
例如我们需要从一个线性表中筛选大于等于 60 且小于 70 的数据:
> vector = c(10, 40, 78, 64, 53, 62, 69, 70) > print(vector[which(vector >= 60 & vector < 70)]) [1] 64 62 69
类似的函数还有 all 和 any:
> all(c(TRUE, TRUE, TRUE)) [1] TRUE > all(c(TRUE, TRUE, FALSE)) [1] FALSE > any(c(TRUE, FALSE, FALSE)) [1] TRUE > any(c(FALSE, FALSE, FALSE)) [1] FALSE
all() 用于检查逻辑向量是否全部为 TRUE,any() 用于检查逻辑向量是否含有 TRUE。
字符串
字符串数据类型本身并不复杂,这里注重介绍字符串的操作函数:
> toupper("Nhooo") # 转换为大写
[1] "nhooo"
> tolower("Nhooo") # 转换为小写
[1] "nhooo"
> nchar("中文", type="bytes") # 统计字节长度
[1] 4
> nchar("中文", type="char") # 总计字符数量
[1] 2
> substr("123456789", 1, 5) # 截取字符串,从 1 到 5
[1] "12345"
> substring("1234567890", 5) # 截取字符串,从 5 到结束
[1] "567890"
> as.numeric("12") # 将字符串转换为数字
[1] 12
> as.character(12.34) # 将数字转换为字符串
[1] "12.34"
> strsplit("2019;10;1", ";") # 分隔符拆分字符串
[[1]]
[1] "2019" "10" "1"
> gsub("/", "-", "2019/10/1") # 替换字符串
[1] "2019-10-1"在 Windows 计算机上实现,使用的是 GBK 编码标准,所以一个中文字符是两个字节,如果在 UTF-8 编码的计算机上运行,单个中文字符的字节长度应该是 3。
R 支持 perl 语言格式的正则表达式:
> gsub("[[:alpha:]]+", "$", "Two words")
[1] "$ $"更多字符串内容参考:R 语言字符串介绍。
矩阵
R 语言为线性代数的研究提供了矩阵类型,这种数据结构很类似于其它语言中的二维数组,但 R 提供了语言级的矩阵运算支持。
首先看看矩阵的生成:
> vector=c(1, 2, 3, 4, 5, 6) > matrix(vector, 2, 3) [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6
矩阵初始化内容是由一个向量来传递的,其次要表达一个矩阵有几行、有几列。
向量中的值会一列一列的填充到矩阵中。如果想按行填充,需要指定 byrow 属性:
> matrix(vector, 2, 3, byrow=TRUE) [,1] [,2] [,3] [1,] 1 2 3 [2,] 4 5 6
矩阵中的每一个值都可以被直接访问:
> m1 = matrix(vector, 2, 3, byrow=TRUE) > m1[1,1] # 第 1 行 第 1 列 [1] 1 > m1[1,3] # 第 1 行 第 3 列 [1] 3
R 中的矩阵的每一个列和每一行都可以设定名称,这个过程通过字符串向量批量完成:
> colnames(m1) = c("x", "y", "z")
> rownames(m1) = c("a", "b")
> m1
x y z
a 1 2 3
b 4 5 6
> m1["a", ]
x y z
1 2 3矩阵的四则运算与向量基本一致,既可以与标量做运算,也可以与同规模的矩阵做对应位置的运算。
矩阵乘法运算:
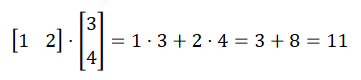
> m1 = matrix(c(1, 2), 1, 2) > m2 = matrix(c(3, 4), 2, 1) > m1 %*% m2 [,1] [1,] 11
逆矩阵:
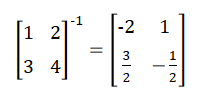
> A = matrix(c(1, 3, 2, 4), 2, 2) > solve(A) [,1] [,2] [1,] -2.0 1.0 [2,] 1.5 -0.5
apply() 函数可以将矩阵的每一行或每一列当作向量来进行操作:
> (A = matrix(c(1, 3, 2, 4), 2, 2)) [,1] [,2] [1,] 1 2 [2,] 3 4 > apply(A, 1, sum) # 第二个参数为 1 按行操作,用 sum() 函数 [1] 3 7 > apply(A, 2, sum) # 第二个参数为 2 按列操作 [1] 4 6
更多矩阵内容参考:R 矩阵。
- Copyright © 2003-2013 菜鸟教程。
- 版权与免责声明
