
- 1为什么很多人用不好GPT_gpt并不好用
- 2使用git连接一个新的gitlab项目_gitlab工程里链接其他工程
- 3sort与sorted的区别及实例
- 4学习日志【Gitee/Github账户创建与开源仓库的使用】_github desktop 登陆gitee账号
- 5python-opencv学习(二)之图像的读取、显示与保存_cv2读取jpg
- 6贝塞尔曲线-曲线拟合_贝塞尔曲线拟合
- 7<数据集>煤矸石识别数据集<目标检测>
- 8前端面试题记录_2024前端面试题
- 9互联网行业采购堡垒机的四个必要性看这里!
- 10【实验】使用docker-compose编排lnmp(dockerfile) 完成Wordpress 部署
美团二面:聊聊线程池设计与原理,由表及里趣味解析,2024年最新java技术经理面试题目及答案_面试 java技术经理 面试题
赞
踩
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
-
一个框架:即线程池的整体设计存在一个框架,而不是杂乱无章的组成。所以,在学习线程池时,首先要能从立体上感知到这个框架的存在,而不要陷于凌乱的细节中;
-
两大核心:在线程池的整个框架中,围绕任务执行这件事,存在两大核心:任务的管理和任务的执行,对应的也就是任务队列和用于执行任务的工作线程。任务队列和工作线程是框架得以有效运转的关键部件;
-
三大过程:前面说过,线程池的整体设计都是围绕任务展开,所以框架内可以分为任务提交、任务管理和任务执行三大过程。
从类比的角度讲,你可以把框架看作是一个生产车间。在这个车间里,有一条流水线,任务队列和工作线程是这条流水线的两大关键组成。而在流水线运作的过程中,就会涉及任务提交、任务管理和任务执行等不同的过程。
下面这幅图,将帮助你立体地感知线程池的整体设计,建议你收藏。在这幅图中,清楚地展示了线程池整个框架的工作流程和核心部件,接下来的文章也将围绕这幅图展开。
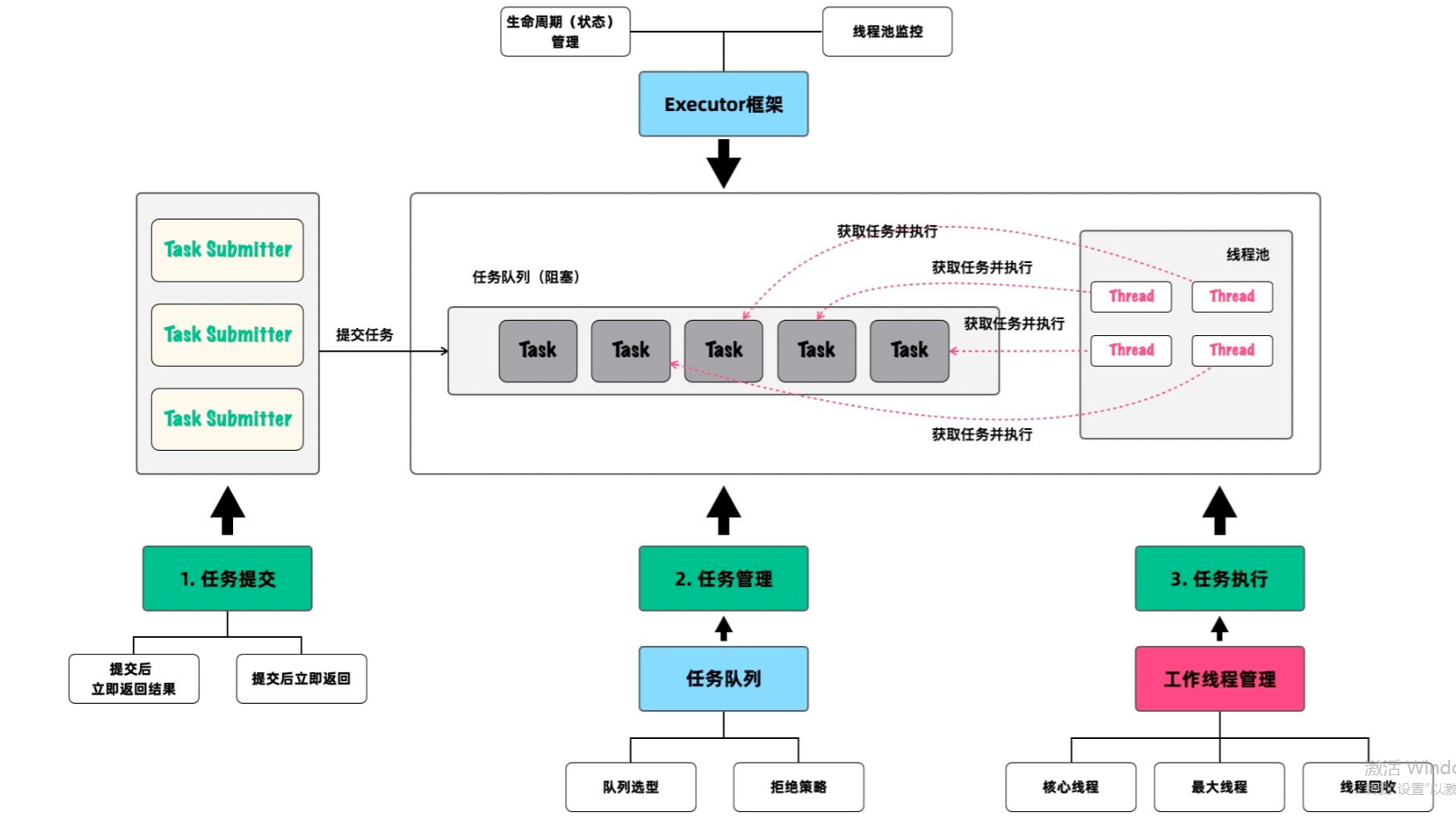
1. 线程池框架设计概览
=============
从源码层面看,理解Java中的线程池,要从下面这四兄弟的概念和关系入手,这四个概念务必了然于心。

-
Executor:作为线程池的最顶层接口,Executor的接口在设计上,实现了任务提交与任务执行之间的解耦,这是它存在的意义。在Executor中,只定义了一个方法void execute(Runnable command),用于执行提交的可运行的任务。注意,你看它这个方法的参数干脆就叫command,也就是“命令”,意在表明所提交的不是一个静止的对象,而是可运行的命令。并且,这个命令将在未来的某一时刻执行,具体由哪个线程来执行也是不确定的;
-
ExecutorService:继承了Executor的接口,并在此基础上提供可以管理服务和执行结果(Futrue) 的能力。ExecutorService所提供的submit方法可以返回任务的执行结果,而shutdown方法则可以用于关闭服务。相比起来,Executor只具备单一的执行能力,而ExecutorService则不仅具有执行能力,还提供了简单的服务管理能力;
-
AbstractExecutorService:作为ExecutorService的简单实现,该类通过RunnableFuture和newTaskFor实现了submit、invokeAny和invokeAll等方法;
-
ThreadPoolExecutor:该类是线程池的最终实现类,实现了Executor和ExecutorService中定义的能力,并丰富了AbstractExecutorService中的实现。在ThreadPoolExecutor中,定义了任务管理策略和线程池管理能力,相关能力的实现细节将是我们下文所要讲解的核心所在。
如果你觉得还是不太能直观地感受四兄弟的差异,那么你可以放大查看下面这幅高清图示。看的时候,要格外注意它们各自方法的不同,方法的不同意味着它们的能力不同。
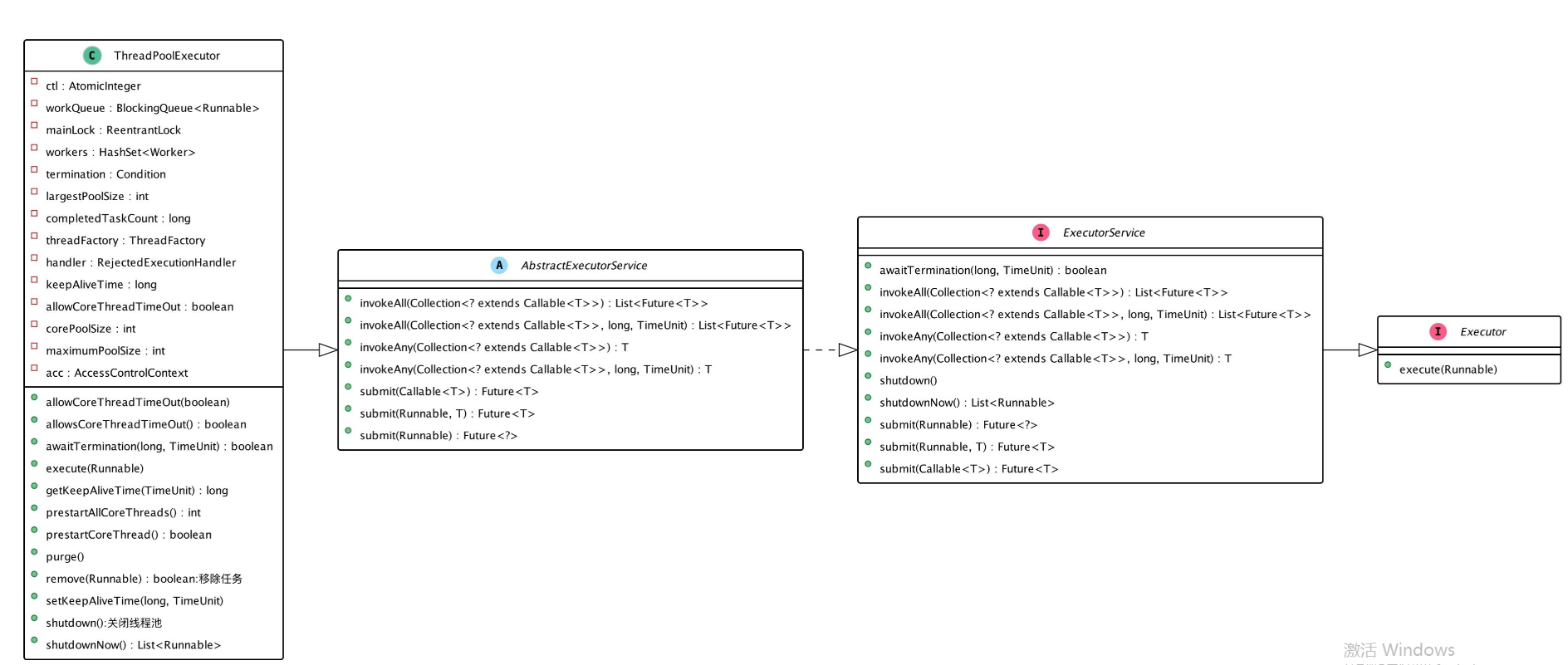
而对于线程池总体的执行过程,下面这幅图也建议你收藏。这幅图虽然简明,但完整展示了从任务提交到任务执行的整个过程。这个执行过程往往也是面试中的高频面试题,务必掌握。

(1)线程池的核心属性
===========
线程池中的一些核心属性选取如下,对于其中个别属性会做特别说明。
// 线程池控制相关的主要变量
// 这个变量很神奇,下文后专门陈述,请特别留意
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 待处理的任务队列
private final BlockingQueue < Runnable > workQueue;
// 工作线程集合
private final HashSet < Worker > workers = new HashSet < Worker > ();
// 创建线程所用到的线程工厂
private volatile ThreadFactory threadFactory;
// 拒绝策略
private volatile RejectedExecutionHandler handler;
// 核心线程数
private volatile int corePoolSize;
// 最大线程数
private volatile int maximumPoolSize;
// 空闲线程的保活时长
private volatile long keepAliveTime;
// 线程池变更的主要控制锁,在工作线程数、变更线程池状态等场景下都会用到
private final ReentrantLock mainLock = new ReentrantLock();
关于ctl字段的特别说明
在ThreadPoolExecutor的多个核心字段中,其他字段可能都比较好理解,但是ctl要单独拎出来做些解释。
顾名思义,ctl这个字段用于对线程池的控制。它的设计比较有趣,用一个字段却表示了两层含义,也就是这个字段实际是两个字段的合体:
-
runState:线程池的运行状态(高3位);
-
workerCount:工作线程数量(第29位)。
这两个字段的值相互独立,互不影响。那为何要用这种设计呢?这是因为,在线程池中这两个字段几乎总是如影相随,如果不用一个字段来表示的话,那么就需要通过锁的机制来控制两个字段的一致性。不得不说,这个字段设计上还是比较巧妙的。
在线程池中,也提供了一些方法可以方便地获取线程池的状态和工作线程数量,它们都是通过对ctl进行位运算得来。
/**
计算当前线程池的状态
*/
private static int runStateOf(int c) {
return c & ~CAPACITY;
}
/**
计算当前工作线程数
*/
private static int workerCountOf(int c) {
return c & CAPACITY;
}
/**
初始化ctl变量
*/
private static int ctlOf(int rs, int wc) {
return rs | wc;
}
关于位运算,这里补充一点说明,如果你对位运算有点迷糊的话可以看看,如果你对它比较熟悉则可以直接跳过。
假设A=15,二进制是1111;B=6,二进制是110.
运算符名称描述示例&按位与如果相对应位都是1,则结果为1,否则为0(A&B),得到6,即110~按位非按位取反运算符翻转操作数的每一位,即0变成1,1变成0。(〜A)得到-16,即
11111111111111111111111111110000|按位或如果相对应位都是 0,则结果为 0,否则为 1(A | B)得到15,即 1111
(2)线程池的核心构造器
============
ThreadPoolExecutor有四个构造器,其中一个是核心构造器。你可以根据需要,按需使用这些构造器。
- 核心构造器之一:相对较为常用的一个构造器,你可以指定核心线程数、最大线程数、线程保活时间和任务队列类型。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue < Runnable > workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
- 核心构造器之二:相比于第一个构造器,你可以在这个构造器中指定ThreadFactory. 通过ThreadFactory,你可以指定线程名称、分组等个性化信息。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue < Runnable > workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
- 核心构造器之三:这个构造器的要点在于,你可以指定拒绝策略。关于任务队列的拒绝策略,下文有详细介绍。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue < Runnable > workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
- 核心构造器之四:这个构造器是ThreadPoolExecutor的核心构造器,提供了较为全面的参数设置,上述的三个构造器都是基于它实现。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue < Runnable > workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
(3)线程池中的核心方法
============
/**
- 提交Runnable类型的任务并执行,但不返回结果
*/
public void execute(Runnable command){…}
/**
- 提交Runnable类型的任务,并返回结果
*/
public Future<?> submit(Runnable task){…}
/**
- 提交Runnable类型的任务,并返回结果,支持指定默认结果
*/
public Future submit(Runnable task, T result){…}
/**
- 提交Callable类型的任务并执行
*/
public Future submit(Callable task) {…}
/**
- 关闭线程池,继续执行队列中未完成的任务,但不会接收新的任务
*/
public void shutdown() {…}
/**
- 立即关闭线程池,同时放弃未执行的任务,并不再接收新的任务
*/
public List shutdownNow(){…}
(4)线程池的状态与生命周期管理
================
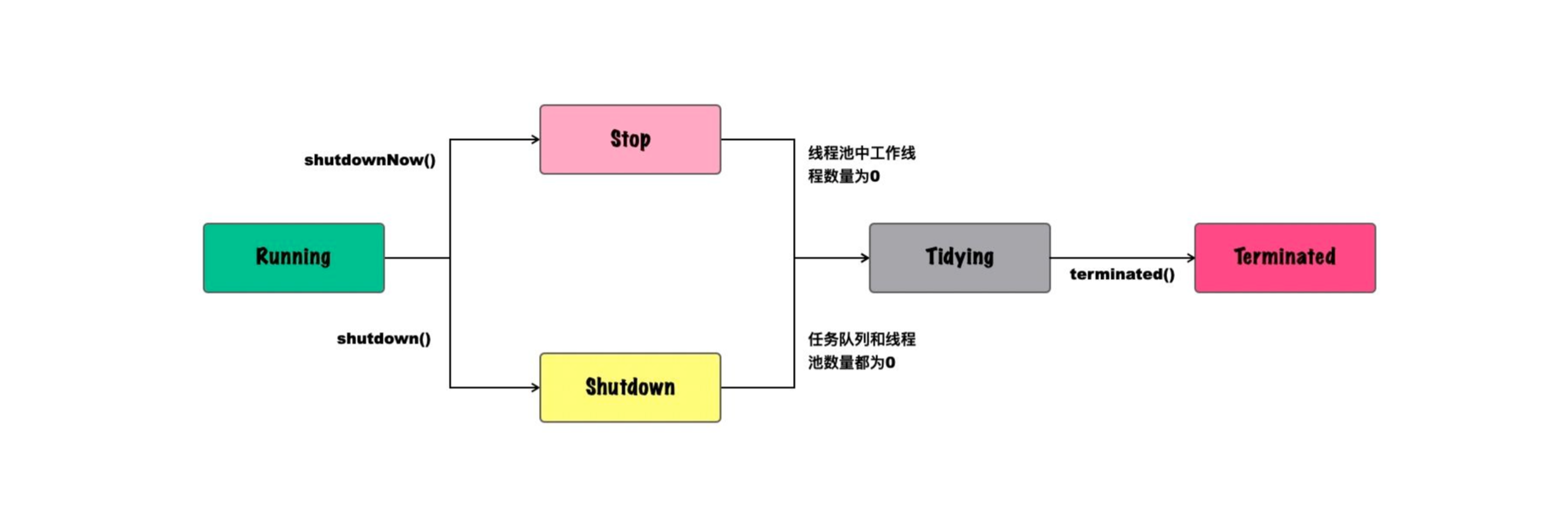
前文说过,线程池恰似一个生产车间,而从生产车间的角度看,生产车间有运行、停产等不同状态,所以线程池也是有一定的状态和使用周期的。
-
Running:运行中,该状态下可以继续向线程池中增加任务,并正常处理队列中的任务;
-
Shutdown:关闭中,该状态下线程池不会立即停止,但不能继续向线程池中增加任务,直到任务执行结束;
-
Stop:停止,该状态下将不再接收新的任务,同时不再处理队列中的任务,并中断工作中的线程;
-
Tidying:相对短暂的中间状态,所有任务都已经结束,并且所有的工作线程都不再存在(workerCount==0),并运行terminated()钩子方法;
-
Terminated:terminated()运行结束。
2. 如何向线程池中提交任务
===============
向线程池提交任务有两种比较常见的方式,一种是需要返回执行结果的,一种则是不需要返回结果的。
(1)不关注任务执行结果:execute
====================
通过execute()提交任务到线程池后,任务将在未来某个时刻执行,执行的任务的线程可能是当前线程池中的线程,也可能是新创建的线程。当然,如果此时线程池应关闭,或者任务队列已满,那么该任务将交由RejectedExecutionHandler处理。
(2)关注任务执行结果:submit
==================
通过submit()提交任务到线程池后,运行机制和execute类似,其核心不同在于,由submit()提交任务时将等待任务执行结束并返回结果。
3. 如何管理提交的任务
=============
(1)任务队列选型策略
===========
-
SynchronousQueue:无缝传递(Direct handoffs)。当新的任务到达时,将直接交由线程处理,而不是放入缓存队列。因此,如果任务达到时却没有可用线程,那么将会创建新的线程。所以,为了避免任务丢失,在使用SynchronousQueue时,将会需要创建无数的线程,在使用时需要谨慎评估。
-
LinkedBlockingQueue:无界队列,新提交的任务都会缓存到该队列中。使用无界队列时,只有corePoolSize中的线程来处理队列中的任务,这时候和maximumPoolSize是没有关系的,它不会创建新的线程。当然,你需要注意的是,如果任务的处理速度远低于任务的产生速度,那么LinkedBlockingQueue的无限增长可能会导致内存容量等问题。
-
ArrayBlockingQueue:有界队列,可能会触发创建新的工作线程,maximumPoolSize参数设置在有界队列中将发挥作用。在使用有界队列时,要特别注意任务队列大小和工作线程数量之间的权衡。如果任务队列大但是线程数量少,那么结果会是系统资源(主要是CPU)占用率较低,但同时系统的吞吐量也会降低。反之,如果缩小任务队列并扩大工作线程数量,那么结果则是系统吞吐量增大,但同时系统资源占用也会增加。所以,使用有界队列时,要考虑到平衡的艺术,并配置相应的拒绝策略。
(2)如何选择合适的拒绝策略
==============
在使用线程池时,拒绝策略是必须要确认的地方,因为它可能会造成任务丢失。
当线程池已经关闭或任务队列已满且无法再创建新的工作线程时,那么新提交的任务将会被拒绝,拒绝时将调用RejectedExecutionHandler中的rejectedExecution(Runnable r, ThreadPoolExecutor executor)来执行具体的拒绝动作。
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
以execute方法为例,当线程池状态异常或无法新增工作线程时,将会执行任务拒绝策略。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf© < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning© && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
ThreadPoolExecutor的默认拒绝策略是AbortPolicy,这一点在属性定义中已经确定。在大部分场景中,直接拒绝任务都是不合适的。
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
-
AbortPolicy:默认策略,直接抛出RejectedExecutionException异常;
-
CallerRunsPolicy:交由当前线程自己来执行。这种策略这提供了一个简单的反馈控制机制,可以减慢提交新任务的速度;
-
DiscardPolicy:直接丢弃任务,不会抛出异常;
-
DiscardOldestPolicy:如果此时线程池没有关闭,将从队列的头部取出第一个任务并丢弃,并再次尝试执行。如果执行失败,那么将重复这个过程。
如果上述四种策略均不满足,你也可以通过RejectedExecutionHandler接口定制个性化的拒绝策略。事实上,为了兼顾任务不丢失和系统负载,建议你自己实现拒绝策略。
(3)队列维护
=======
对于任务队列的维护,线程池也提供了一些方法。
- 获取当前任务队列
public BlockingQueue getQueue() {
return workQueue;
}
- 从队列中移除任务
public boolean remove(Runnable task) {
boolean removed = workQueue.remove(task);
tryTerminate(); // In case SHUTDOWN and now empty
return removed;
}
4. 如何管理执行任务的工作线程
=================
(1)核心工作线程
=========
核心线程(corePoolSize)是指最小数量的工作线程,此类线程不允许超时回收。当然,如果你设置了allowCoreThreadTimeOut,那么核心线程也是会超时的,这可能会导致核心线程数为零。核心线程的数量可以通过线程池的构造参数指定。
(2)最大工作线程
=========
最大工作线程指的是线程池为了处理现有任务,所能创建的最大工作线程数量。
最大工作线程可以通过构造函数的maximumPoolSize变量设定。当然,如果你所使用的任务队列是无界队列,那么这个参数将形同虚设。
(3)如何创建新的工作线程
=============
在线程池中,新线程的创建是通过ThreadFactory完成。你可以通过线程池的构造函数指定特定的ThreadFactory,如未指定将使用默认的Executors.defaultThreadFactory(),该工厂所创建的线程具有相同的ThreadGroup和优先级(NORM_PRIORITY),并且都不是守护( Non-Daemon)线程。
通过设定ThreadFactory,你可以自定义线程的名字、线程组以及守护状态等。
在Java的线程池ThreadPoolExecutor中,addWorker方法负责新线程的具体创建工作。
private boolean addWorker(Runnable firstTask, boolean core) {…}
(4)保活时间
=======
保活时间指的是非核心线程在空闲时所能存活的时间。
如果线程池中的线程数量超过了corePoolSize中的设定,那么空闲线程的空闲时间在超过keepAliveTime中设定的时间后,线程将被回收终止。在线程被回收后,如果需要新的线程时,将继续创建新的线程。
需要注意的是,keepAliveTime仅对非核心线程有效,如果需要设置核心线程的保活时间,需要使用allowCoreThreadTimeOut参数。
(5)钩子方法
=======
- 设定任务执行前动作:beforeExecute
如果你希望提交的任务在执行前执行特定的动作,比如写入日志或设定ThreadLocal等。那么,你可以通过重写beforeExecute来实现这一目的。
protected void beforeExecute(Thread t, Runnable r) { }
- 设定任务执行后动作:beforeExecute
如果你希望提交的任务在执行后执行特定的动作,比如写入日志或捕获异常等。那么,你可以通过重写afterExecute来实现这一目的。
protected void afterExecute(Runnable r, Throwable t) { }
- 设定线程池终止动作:terminated
protected void terminated() { }
(6)线程池的预热
=========
默认情况下,在设置核心线程数之后,也不会立即创建相关线程,而是任务到达后再创建。
如果你需要预先就启动核心线程,那么你可以通过调用prestartCoreThread或prestartAllCoreThreads来提前启动,以达到线程池预热目的,并且可以通过ensurePrestart方法来验证效果。
(7)线程回收机制
=========
当线程池中的工作线程数量大于corePoolSize设置的数量时,并且存在空闲线程,并且这个空闲线程的空闲时长超过了keepAliveTime所设置的时长,那么这样的空闲线程将会被回收,以降低不必要的资源浪费。
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
…
} finally {
processWorkerExit(w, completedAbruptly); // 主动回收自己
}
}
(8)线程数调整策略
==========
线程池的工作线程的设置是否合理,关系到系统负载和任务处理速度之间的平衡。这里要明确的是,如何设置核心线程并没有放之四海而皆准的公式。每个业务场景都有着它独特的地方,CPU密集型和IO密集型任务存在较大差异。因此,在使用线程池的时候,要具体问题具体分析,但是你可以运行结果持续调整来优化线程池。
5. 线程池使用示例
===========
我们仍以手工制作线程池部分的场景为例,通过ThreadPoolExecutor实现来展示线程池的使用示例。从代码中看,ThreadPoolExecutor的使用和王者线程池TheKingThreadPool的用法基本一致。
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(3, 20, 1000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue < > (10));
String[] wildMonsters = {“棕熊”, “野鸡”, “灰狼”, “野兔”, “狐狸”, “小鹿”, “小花豹”, “野猪”};
for (String wildMonsterName: wildMonsters) {
threadPoolExecutor.execute(new RunnableTask() {
public String getTaskDesc() {
return wildMonsterName;
}
public void run() {
System.out.println(Thread.currentThread().getName() + “:” + wildMonsterName + “已经烤好”);
}
});
}
threadPoolExecutor.shutdown();
}
6. Executors类
==============
Executors是JUC中一个针对ThreadPoolExecutor和ThreadFactory等设计的一个工具类。通过Executors,可以方便地创建不同类型的线程池。当然,其内部主要是通过给ThreadPoolExecutor的构造传递特定的参数实现,并无玄机可言。常用的几个工具如下所示:
- 创建固定线程数的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
- 创建只有1个线程的线程池
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory));
}
- 创建缓存线程池:这种线程池不设定核心线程数,根据任务的数据动态创建线程。当任务执行结束后,线程会被逐步回收,也就是所有的线程都是临时的。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
7. 线程池监控
=========
作为一个运行框架,ThreadPoolExecutor既简单也复杂。因此,对其内部的监控和管理是十分必要的。ThreadPoolExecutor也提供了一些方法,通过这些方法,我们可以获取到线程池的一些重要状态和数据。
- 获取线程池大小
public int getPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Remove rare and surprising possibility of
// isTerminated() && getPoolSize() > 0
return runStateAtLeast(ctl.get(), TIDYING) ? 0 :
workers.size();
} finally {
mainLock.unlock();
}
}
- 获取活跃工作线程数量
public int getActiveCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int n = 0;
for (Worker w: workers)
if (w.isLocked())
++n;
return n;
} finally {
mainLock.unlock();
}
}
- 获取最大线程池
public int getLargestPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
return largestPoolSize;
} finally {
mainLock.unlock();
}
}
- 获取线程池中的任务总数
Docker步步实践
目录文档:


①Docker简介
②基本概念
③安装Docker

④使用镜像:

⑤操作容器:

⑥访问仓库:

⑦数据管理:

⑧使用网络:

⑨高级网络配置:

⑩安全:

⑪底层实现:

⑫其他项目:

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
inLock;
mainLock.lock();
try {
return largestPoolSize;
} finally {
mainLock.unlock();
}
}
- 获取线程池中的任务总数
Docker步步实践
目录文档:
[外链图片转存中…(img-3FThfuFD-1713355741867)]
[外链图片转存中…(img-2k8GRi9f-1713355741867)]
①Docker简介
②基本概念
③安装Docker
[外链图片转存中…(img-lD28mwlm-1713355741868)]
④使用镜像:
[外链图片转存中…(img-Zqa4T2hC-1713355741868)]
⑤操作容器:
[外链图片转存中…(img-zyTWBX0n-1713355741868)]
⑥访问仓库:
[外链图片转存中…(img-Qo8BDO2L-1713355741869)]
⑦数据管理:
[外链图片转存中…(img-Pt403Iuc-1713355741869)]
⑧使用网络:
[外链图片转存中…(img-rY041WAf-1713355741869)]
⑨高级网络配置:
[外链图片转存中…(img-TVVZZmL8-1713355741870)]
⑩安全:
[外链图片转存中…(img-UlbLRuHs-1713355741870)]
⑪底层实现:
[外链图片转存中…(img-FE0vdyWZ-1713355741871)]
⑫其他项目:
[外链图片转存中…(img-SKnDytHz-1713355741871)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-AjoQ8BMJ-1713355741871)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

