- 1Windows server2016进行配置DHCP服务_虚拟机windows sever2016安装dhcp服务,结果画面截图
- 22021年保研推免面试经验_湖南大学计算机预推免
- 3王道考研 计算机网络12 点对点链路 广播式链路 介质访问控制MAC 动态分配信道 ALOHA协议 CSMA CSMA/CD CSMA/CA协议
- 42022中国智慧医疗领域最具商业合作价值企业盘点
- 5【论文笔记】Digital Twin in Industry: State-of-the-Art——Tao Fei
- 6GitHub的注册-登录-克隆仓库至本地-同步仓库-分享项目链接_克隆chatgpt存储库时,github网站的用户名和密码
- 7通用图形处理单元GPGPU计算管线(General Purpose computation on Graphics Processing Units)介绍
- 8Windows运行代码管理工具(gitee)指南_gitee windows工具
- 9matlab程序中ode45,关于matlab中ode45的问题
- 10轻松上手MYSQL:MYSQL事务隔离级别的奇幻之旅_mysql设置隔离级别
python晋江文学城数据分析——简单的可视化(pyecharts)
赞
踩
本节用pyecharts对一些非数值的数据进行初步的较为简单的可视化。

1饼图
1.1代码
- #以性向为例
- group1 = data.groupby(['性向']).count().sort_values('作品',ascending=False)
- c = (
- Pie(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
- .add("", [list(z) for z in zip(group1.index.tolist(), group1['作品'].tolist())],radius=130) # zip函数两个部分组合在一起list(zip(x,y))-----> [(x,y)]
- .set_global_opts(title_opts=opts.TitleOpts(title="Pie-性向")) # 标题
- .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}({d}%)")) # 数据标签设置
- )
- c.render_notebook()
1.2结果
1.2.1性向
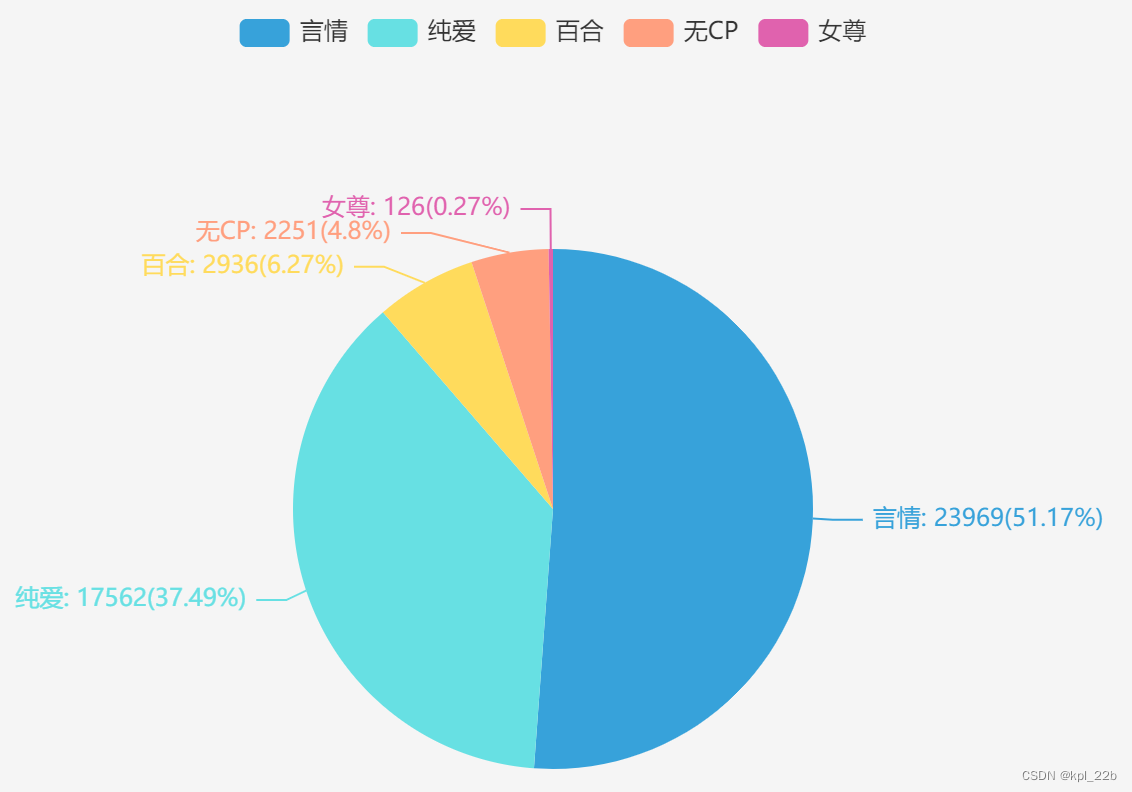
言情占半数,纯爱占近4成,百合和无CP共占一成,百合比无CP略高,女尊几乎可忽略不计。目前看来,作为所谓小众题材的纯爱作品数虽然不及言情,但声量也不小,而百合、无CP、女尊在晋江较为小众。
由于女尊数量过少,分析不具有普遍性,接下来展开分析主要针对其他四个性向。
1.2.2原创性
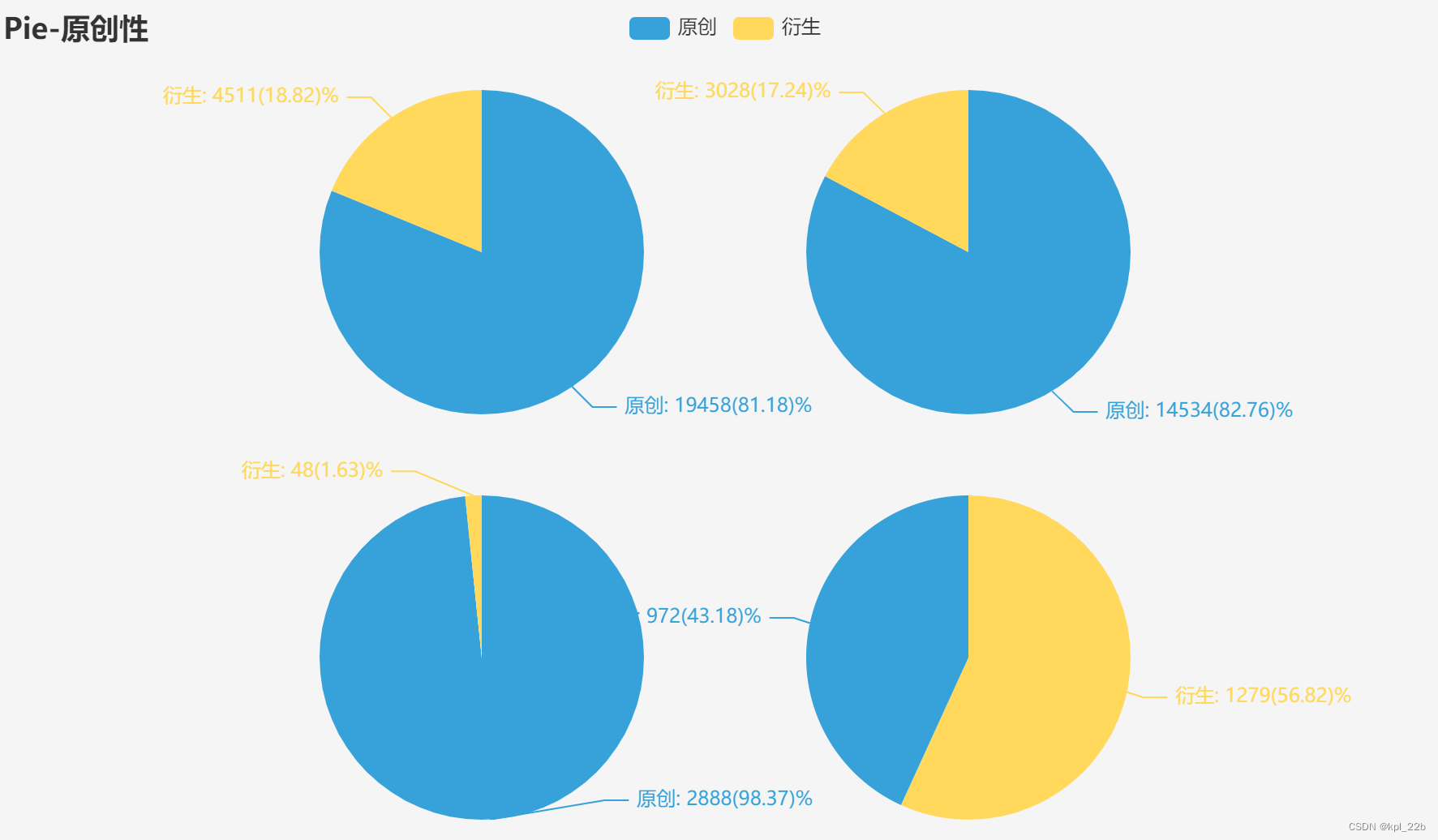
从左到右,从上往下依次是言情、纯爱、百合、无CP。
可以看到,言情和纯爱的原创衍生比基本在8:2,而百合的原创达到98.37%,基本都是原创。而无CP则与前三者相反,衍生文学反而是大头,占比56.82%。后续可借助其他数据对无CP的衍生较多的原因进行一个分析。
1.2.3时代
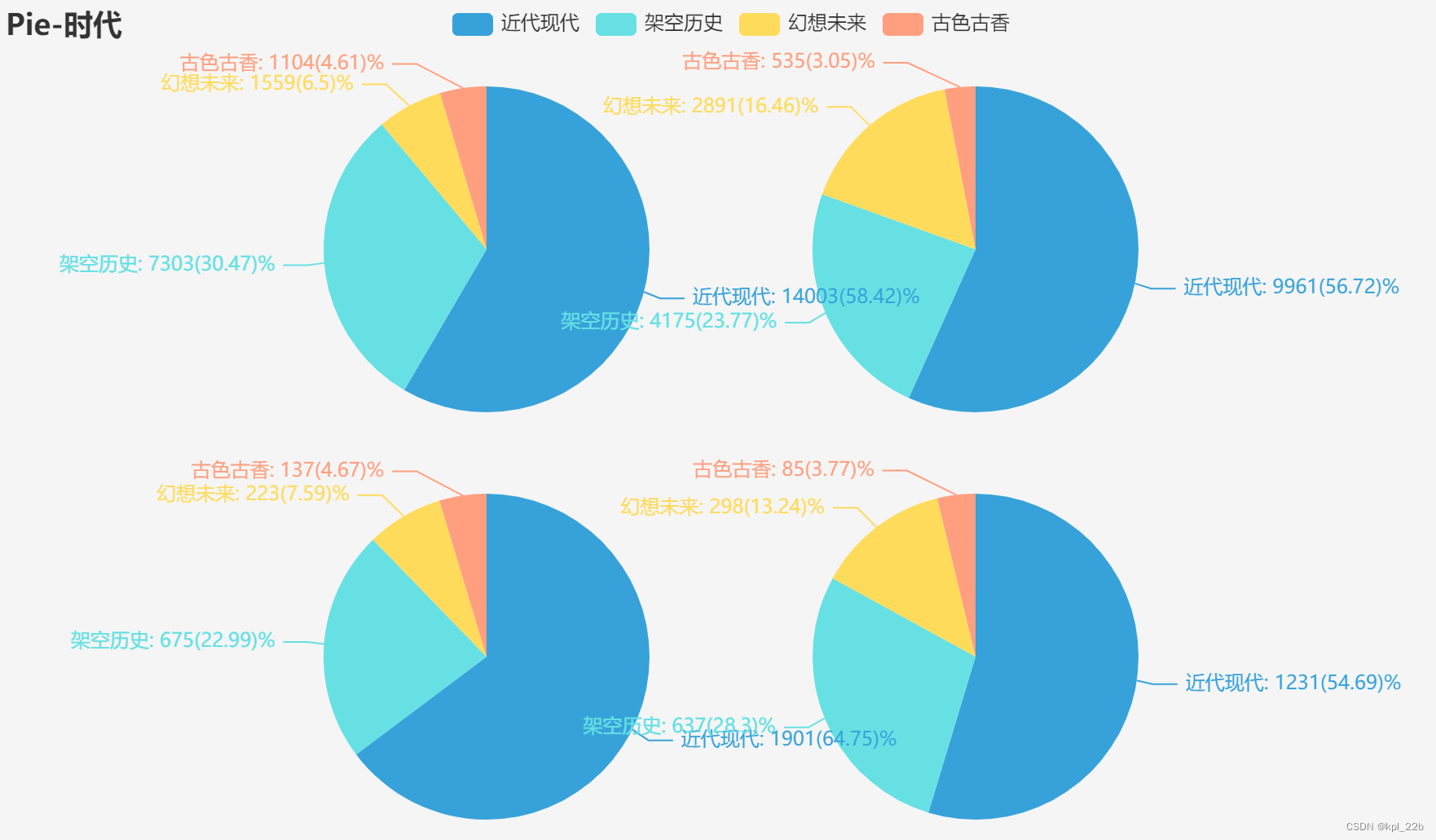
从左到右,从上往下依次是言情、纯爱、百合、无CP。
四种性向都是近代现代占比高,百合占比更是高达64.75%,剩下三者也均在54%-58%之间。其他也是以架空历史、幻想未来、古色古香依次递减。稍有所不同的是,相较其他二者,言情和无CP的架空历史占比较高,都在30%左右,纯爱和无CP的幻想未来占比较高,在15%左右。
1.2.4类型
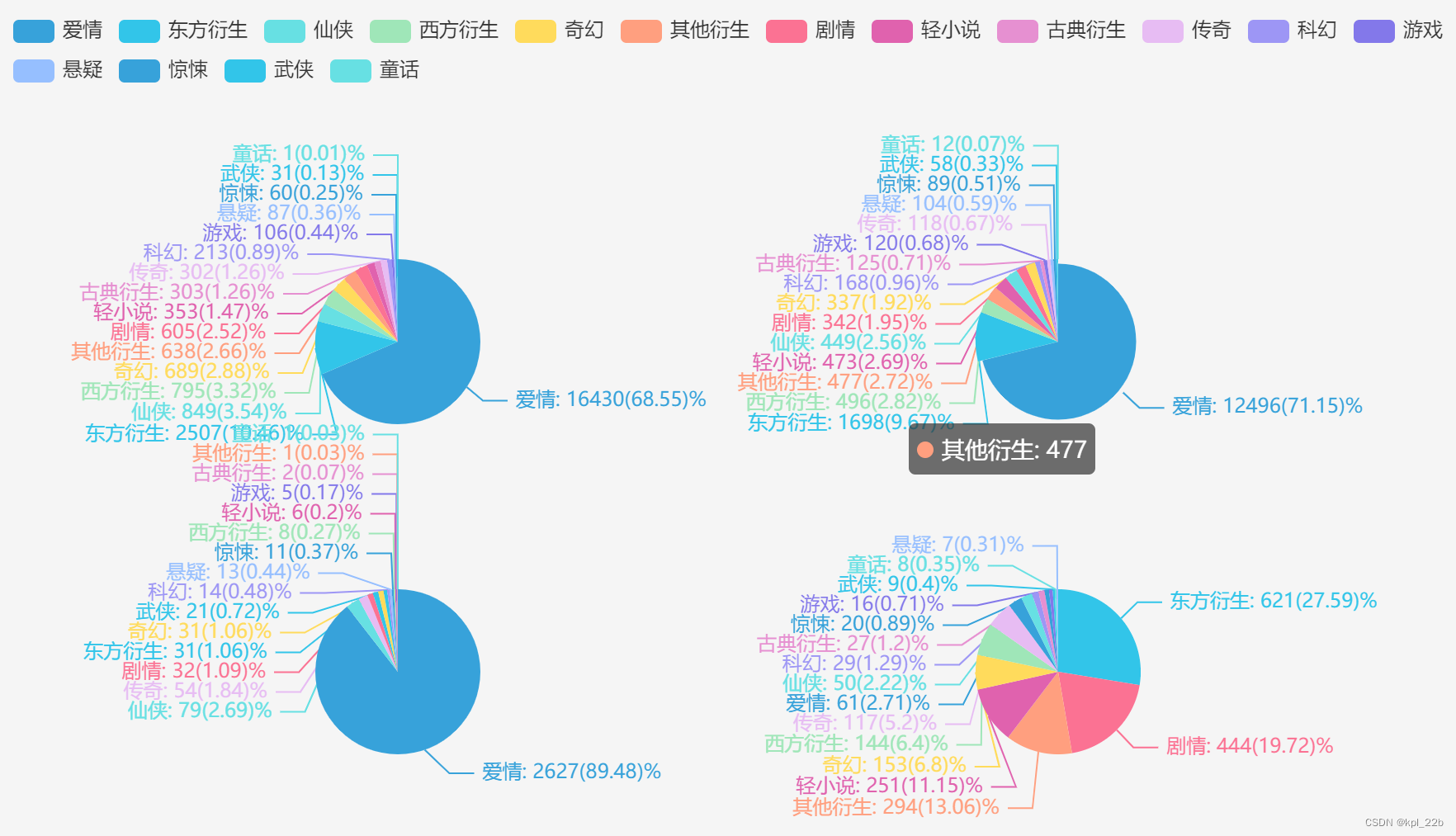
从左到右,从上往下依次是言情、纯爱、百合、无CP。
除了无CP外,其他三个性向均是爱情占比最大,百合占比更是将近90%,言情和纯爱在70%上下,有点奇怪的是无CP里爱情也能占比到2.71%。
无CP相较于其他性向,明显类型更加杂乱,东方衍生占比最大(27.59%),剧情(19.72%),其他衍生(13.06%),轻小说(11.15%),奇幻(6.8%),西方衍生(6.4%),传奇(5.2%)
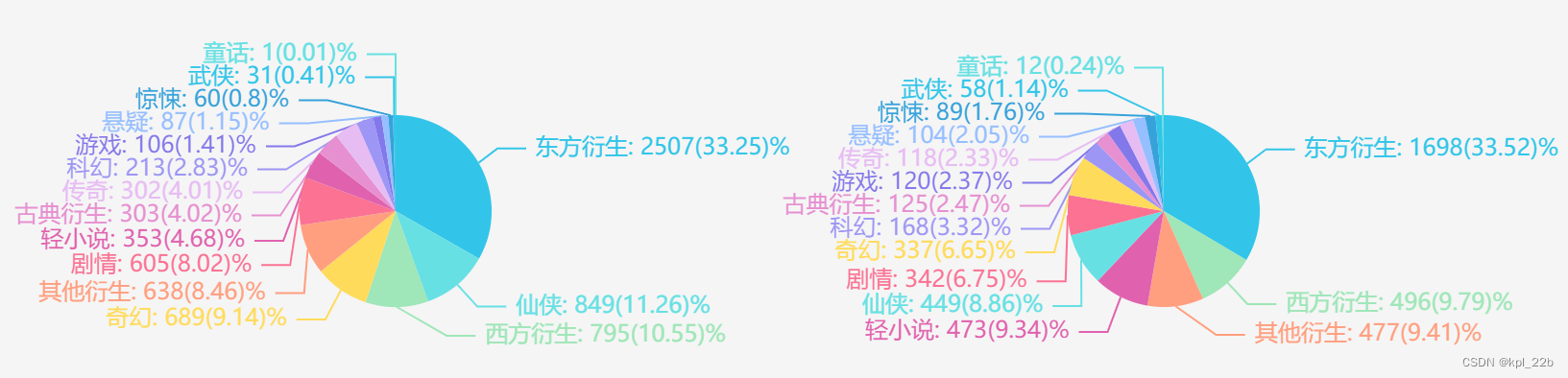
对言情、纯爱去掉爱情后的图进行分析,言情和纯爱中东方衍生都达到了33%,占比最大,
言情中占比较大的是东方衍生(33.25%),仙侠(11.26%),西方衍生(10.55%),奇幻(9.14%),其他衍生(8.46%),剧情(8.02%)。
纯爱中占比较大的是东方衍生(33.52%),西方衍生(9.79%),其他衍生(9.41%),轻小说(9.34%),仙侠(8.86%)
1.2.5风格

从左到右,从上往下依次是言情、纯爱、百合、无CP。
四种性向下都是轻松为主要风格,占60%-70%,正剧位居第二,在30%左右,而报销、暗黑、悲剧甚至不超2%。
1.2.6进度
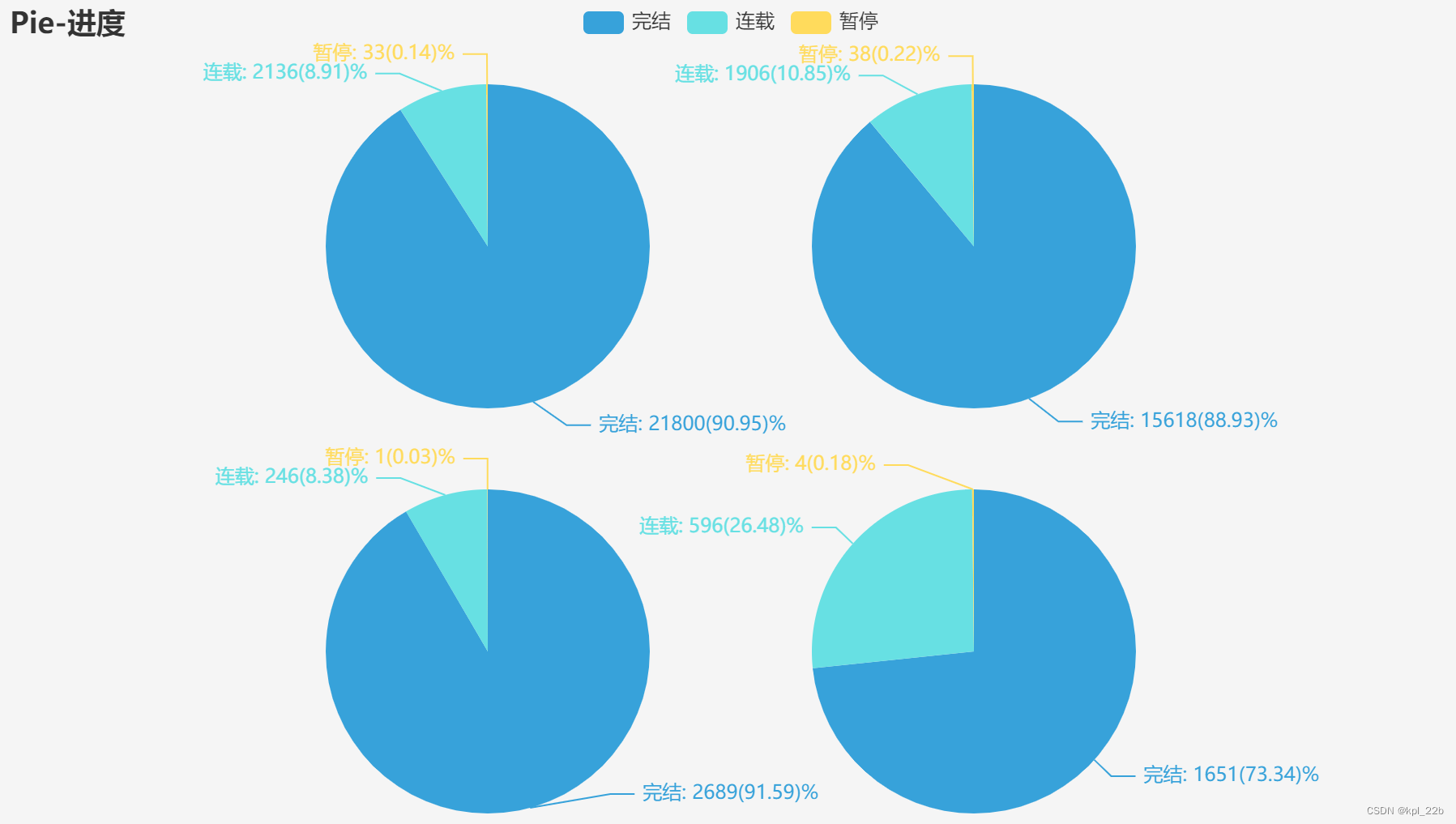
从左到右,从上往下依次是言情、纯爱、百合、无CP。
四种性向下暂停都是占据极少数,不到0.3%,言情、纯爱、百合完结连载比大概在9:1,而无CP则大概在3:1,晋江这两年无CP有渐起之势,完结连载比可以印证这一点。
1.2.7视角
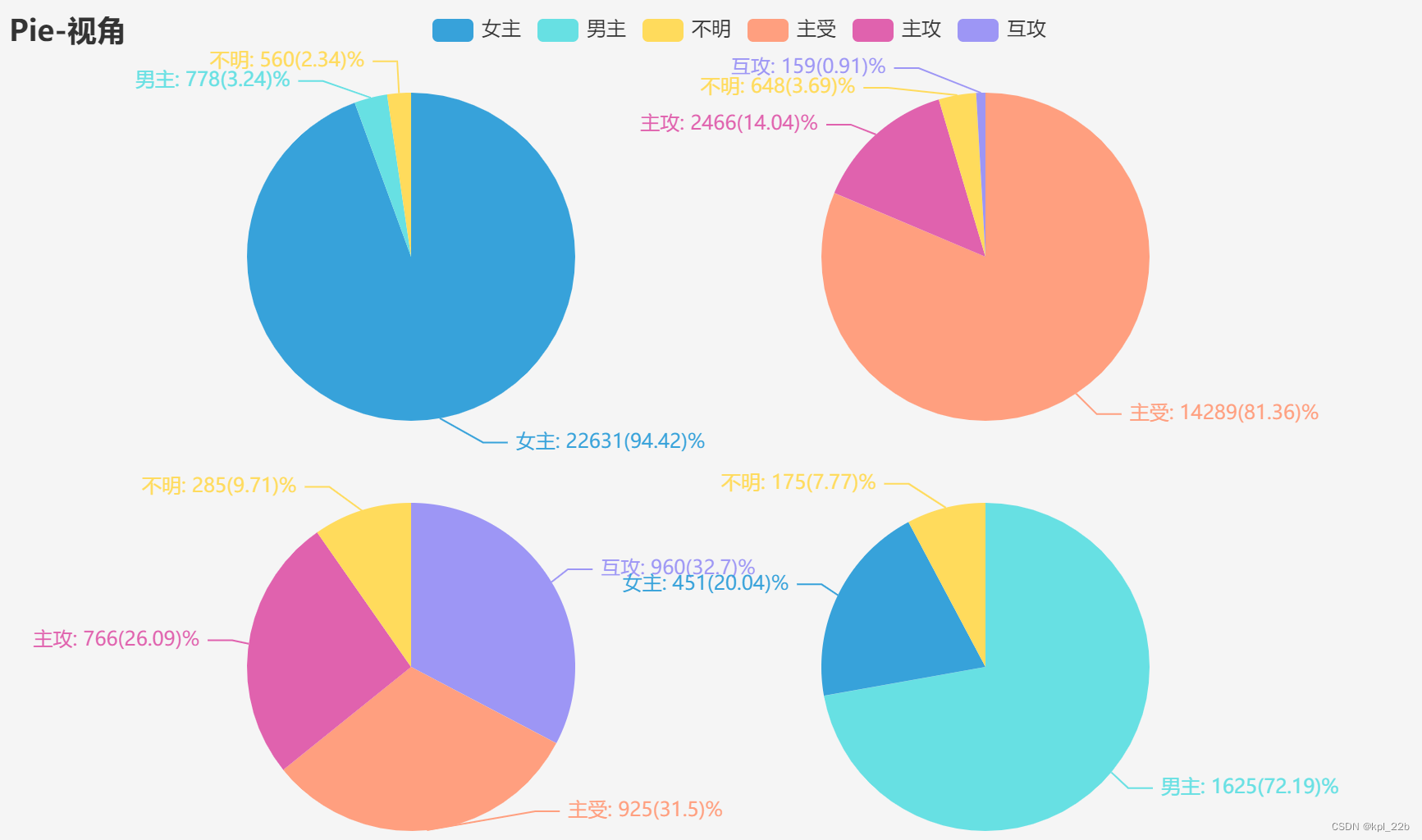
从左到右,从上往下依次是言情、纯爱、百合、无CP。
四种性向在视角方面呈现巨大的差异。言情女主视角为主(94.42%),纯爱视角主受为主(81.36%),主攻次之(14.04%),互攻只占不到1%,但在百合文中,互攻占(32.7%),主受次之(31.5%),主攻(26.09%),三种视角较为平均。而无CP中,男主占比最大(72.19%),女主次之(20.04%),男主视角为主,这在女频向的晋江实属一个奇怪的现象。推测可能是男频于此的替代,也有可能是纯爱近期势弱,部分作者转攻无CP的结果,需要进一步分析论证。
1.2.8出版状态
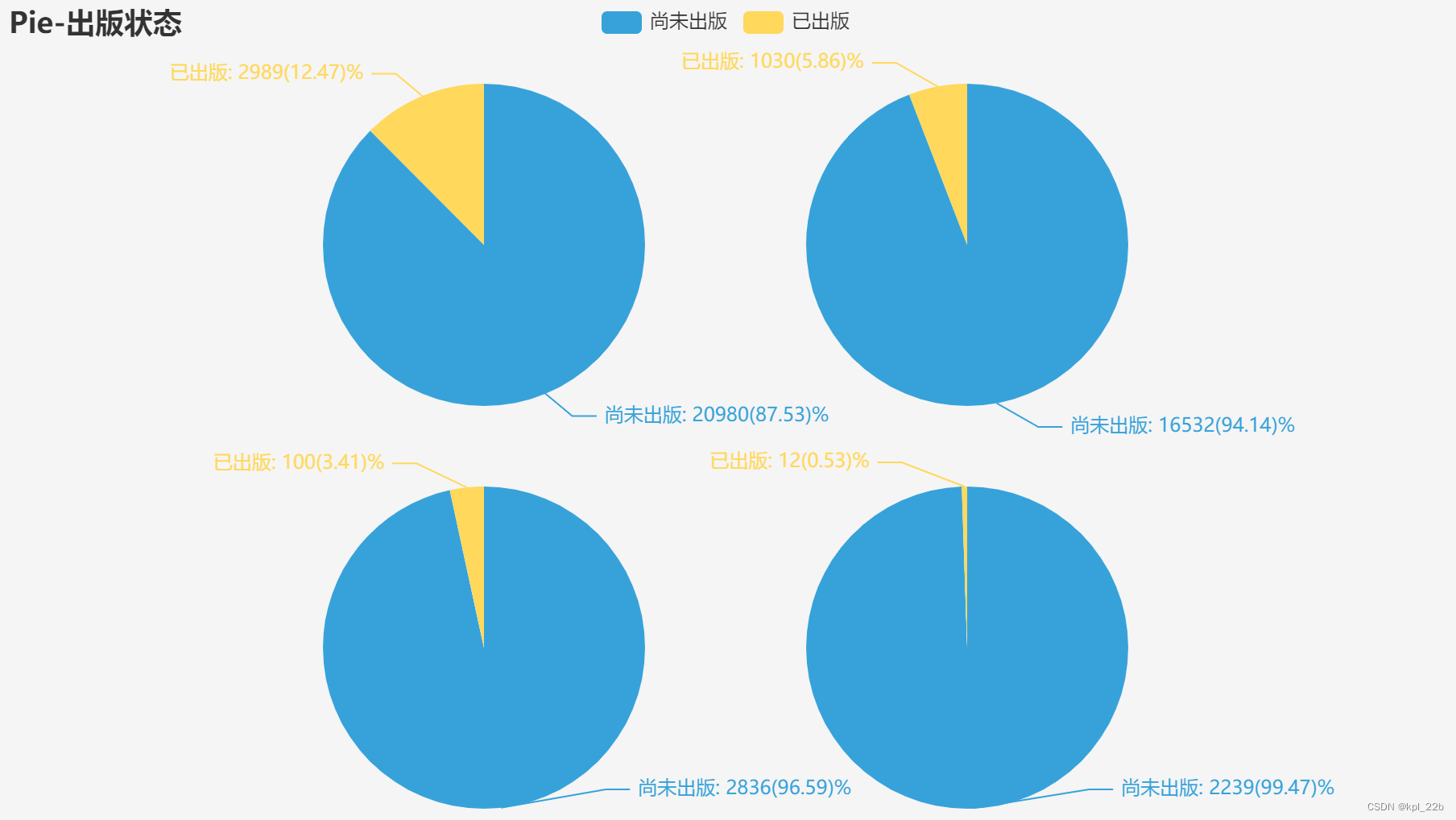
从左到右,从上往下依次是言情、纯爱、百合、无CP。
目前言情出版数和占比都是最高的(12.47%),纯爱次之(5.86%),百合(3.41%)和无CP(0.53%)较少。
1.2.9签约状态
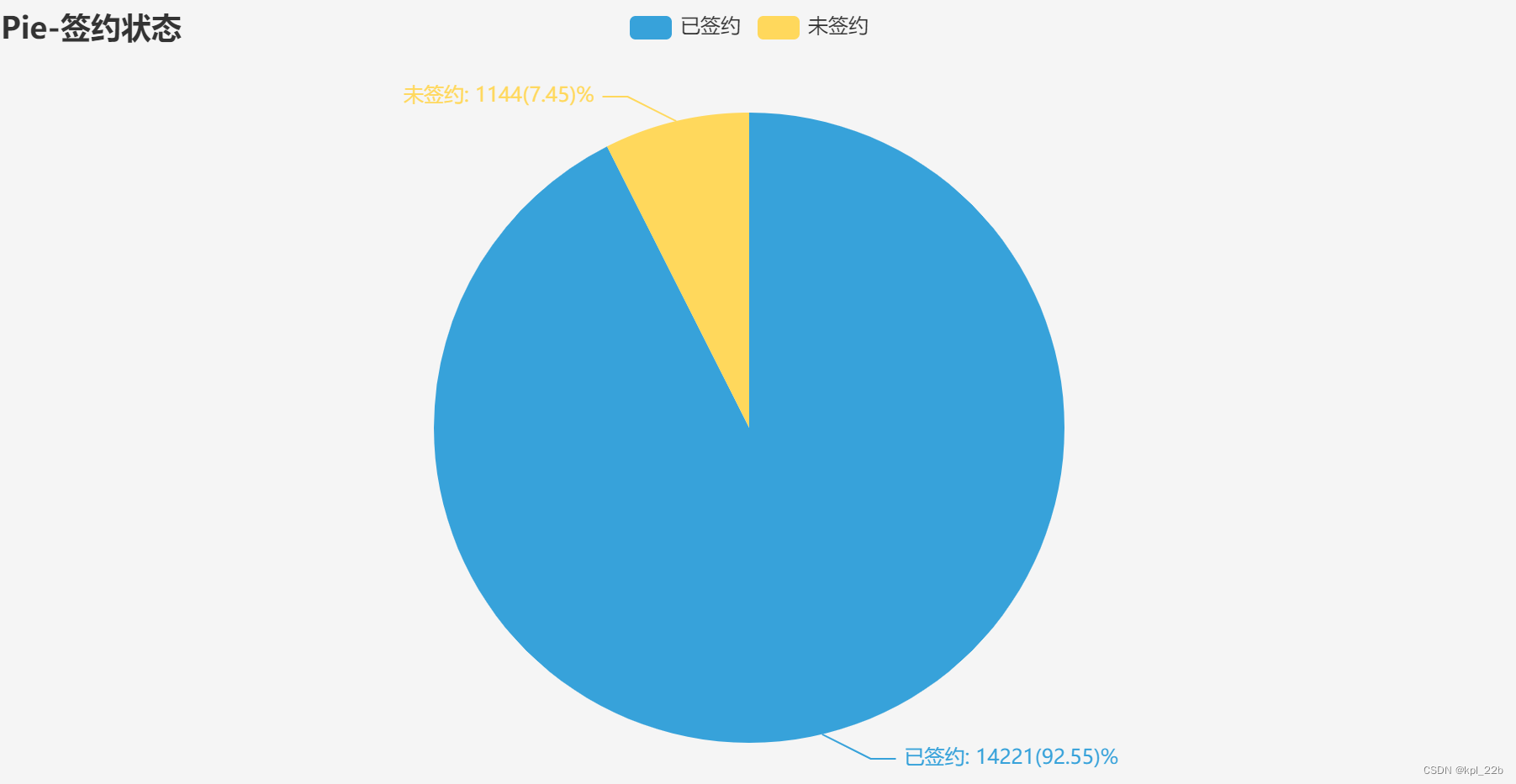
46844本小说是由15365名作者写的,其中92.55%的作者已签约。
2柱状图/折线图
2.1代码
- data1 = data.copy()
- data1['年份']=data1['发表日期'].dt.year
- group1 = data1.query("性向=='言情'").groupby(['年份']).count().sort_values('年份',ascending=False)
- group2 = data1.query("性向=='纯爱'").groupby(['年份']).count().sort_values('年份',ascending=False)
- group3 = data1.query("性向=='百合'").groupby(['年份']).count().sort_values('年份',ascending=False)
- group4 = data1.query("性向=='无CP'").groupby(['年份']).count().sort_values('年份',ascending=False)
- group5 = data1.query("性向=='女尊'").groupby(['年份']).count().sort_values('年份',ascending=False)
-
- c = (
- #Bar(init_opts=opts.InitOpts(theme='white')) #背景颜色
- Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
- .add_xaxis(group1.index.tolist())
- .add_yaxis("言情", group1['作品'].tolist())
- .add_yaxis("纯爱", group2['作品'].tolist())
- .add_yaxis("百合", group3['作品'].tolist())
- .add_yaxis("无CP", group4['作品'].tolist())
- .add_yaxis("女尊", group5['作品'].tolist())
- .set_global_opts(
- title_opts=opts.TitleOpts(title="柱状图",subtitle="slider-水平/圈选功能/切换折线、堆叠、柱状"),
- datazoom_opts=opts.DataZoomOpts(), #水平线
- brush_opts=opts.BrushOpts(), #允许圈选功能
- toolbox_opts=opts.ToolboxOpts(),#允许切换折线/堆叠/柱状
- legend_opts=opts.LegendOpts(is_show=True,#图例的类型 这个就是商家A 商家B那个显示与否
- type_ = 'plain', # 图例的类型。可选值;'plain':普通图例。缺省就是普通图例。'scroll':可滚动翻页的图例。当图例数量较多时可以使用。
- ),
- )
- )
- c.render_notebook()

2.2结果
主要针对发表时间、发表日期这两个数据展开分析。
2.2.1年份
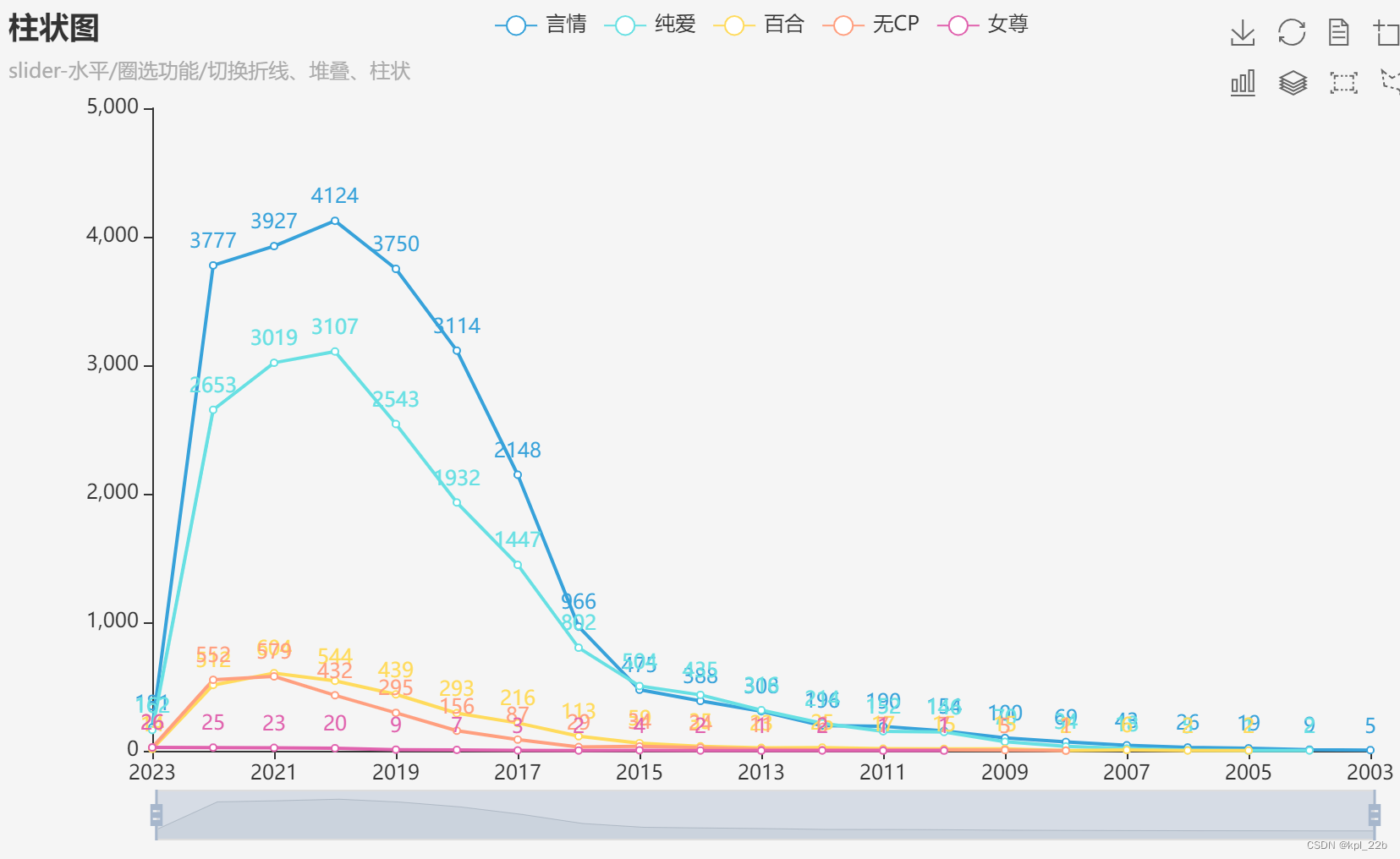
目前来说,晋江小说在逐年增长,大概在2015年前后,迅速增加,目前顶峰在2020年,推测2021和2022年逐年比2019年低的原因是时间积累还不够,也不排除晋江近两年流量变低或是小说质量不高的可能。
2.2.2月份

其实每个月发表作品都较为平均,2月,4月,9月会略微低,1月会略微高。
2.2.3时间
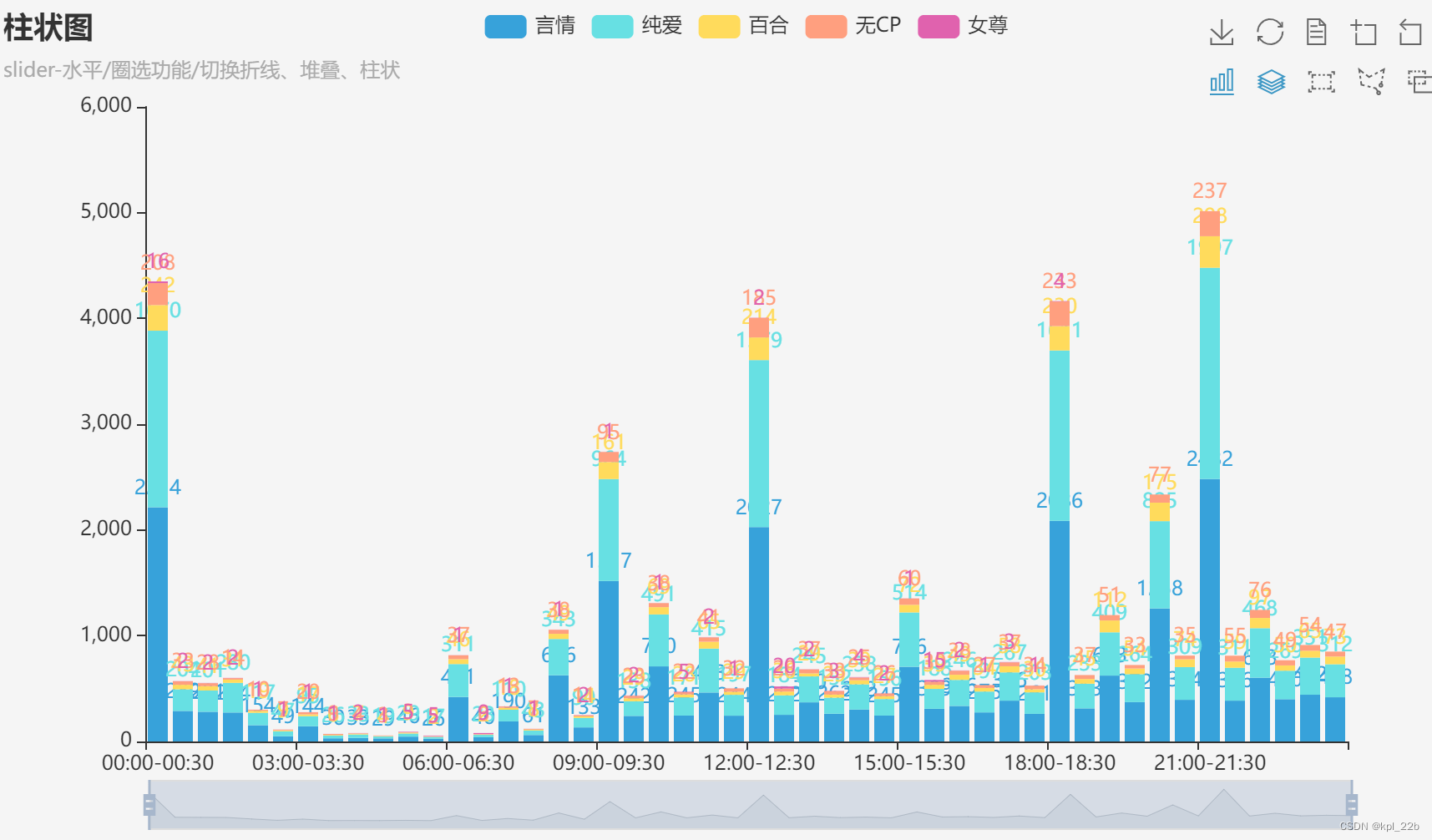
作者发表作品多集中于每天0点、9点、12点、18点、21点。
3日历图
3.1代码
- data1 = data.copy()
- data1['年份']=data1['发表日期'].dt.year
- group1 = data1.query("年份==2020").groupby(['发表日期']).count().sort_values('作品',ascending=False)
- # 把数据框转变成列表,以便下面绘图时直接调用
- df1 = [[str(x)[:10], round(y,1)] for (x, y) in zip(group1.index.tolist(), group1['作品'].tolist())]
- c = (
- Calendar(init_opts=opts.InitOpts(theme=ThemeType.INFOGRAPHIC))
- .add("", df1, calendar_opts=opts.CalendarOpts(range_="2020"))
- .set_global_opts(
- title_opts=opts.TitleOpts(title="日历图-2020年作品发表情况"),
- visualmap_opts=opts.VisualMapOpts(
- max_=72,
- min_=1,
- orient="horizontal",
- is_piecewise=True,
- pos_top="230px",
- pos_left="100px",
- ),
- )
- )
- c.render_notebook()
3.2结果
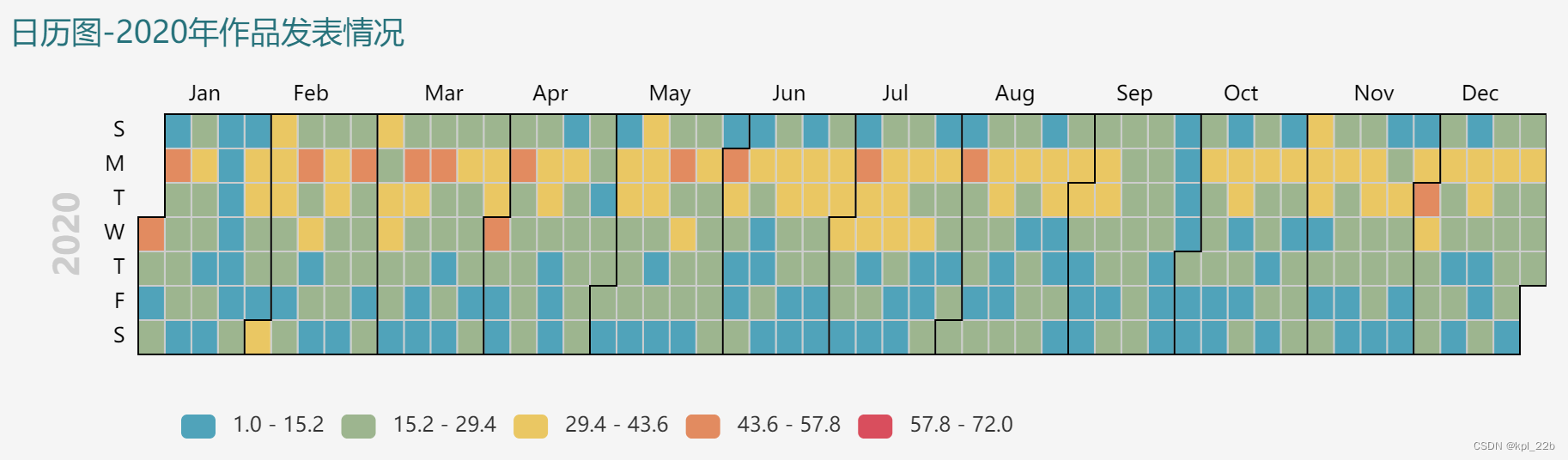
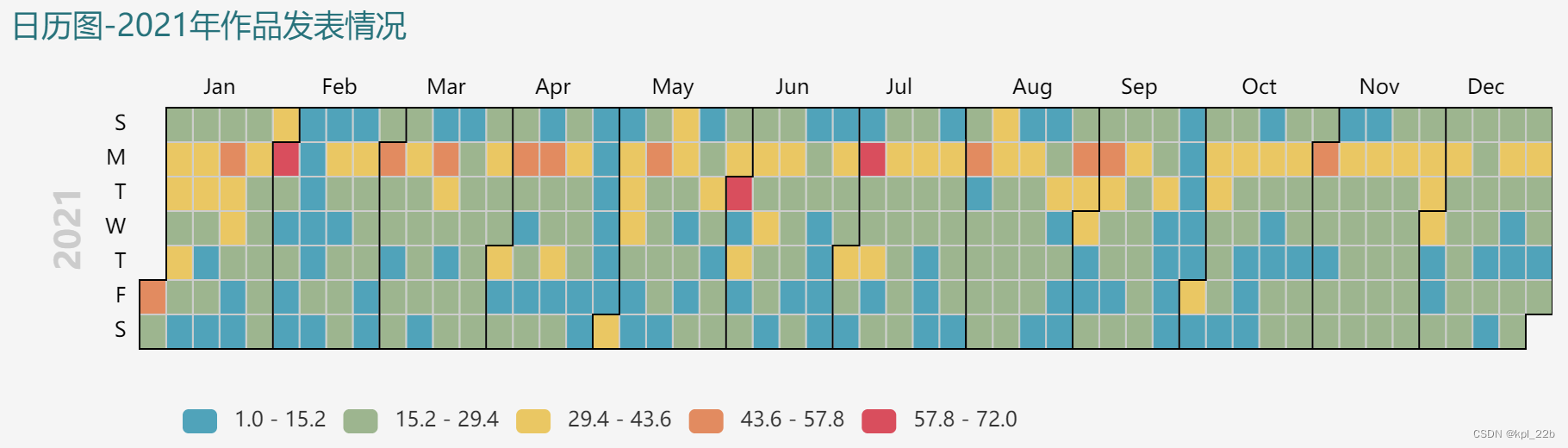
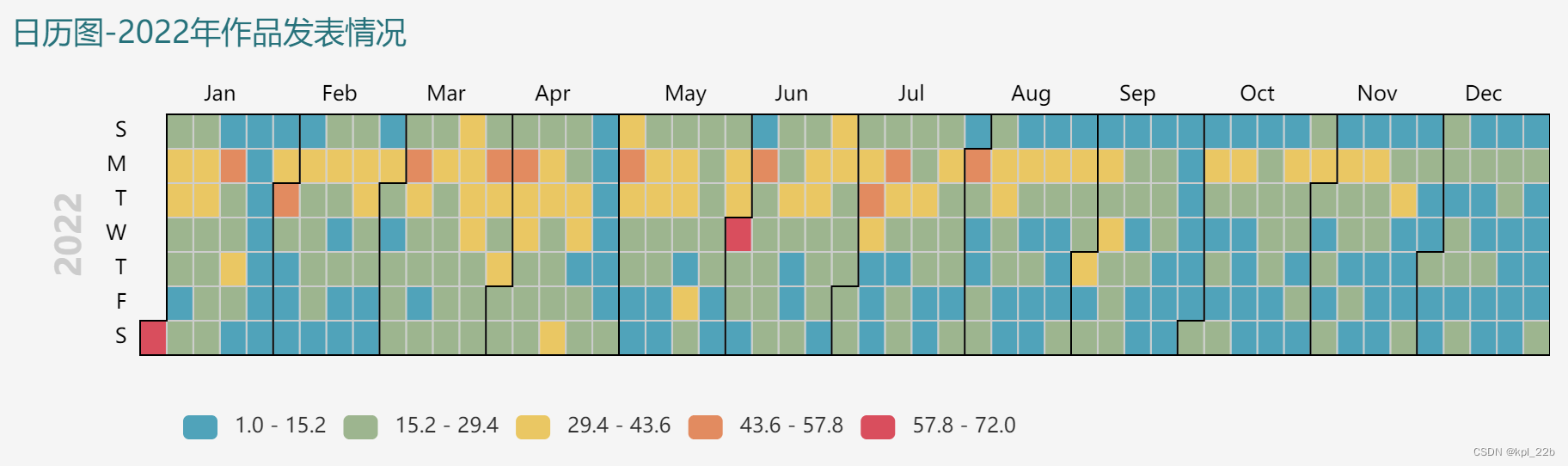
选取了发表作品较多的近三年进行可视化。可以看到,每周周一发表作品明显比其他天更多,可能是作者想用以冲击周榜,每月1号,作品发表也较多,可能是作者想用以冲击月榜。
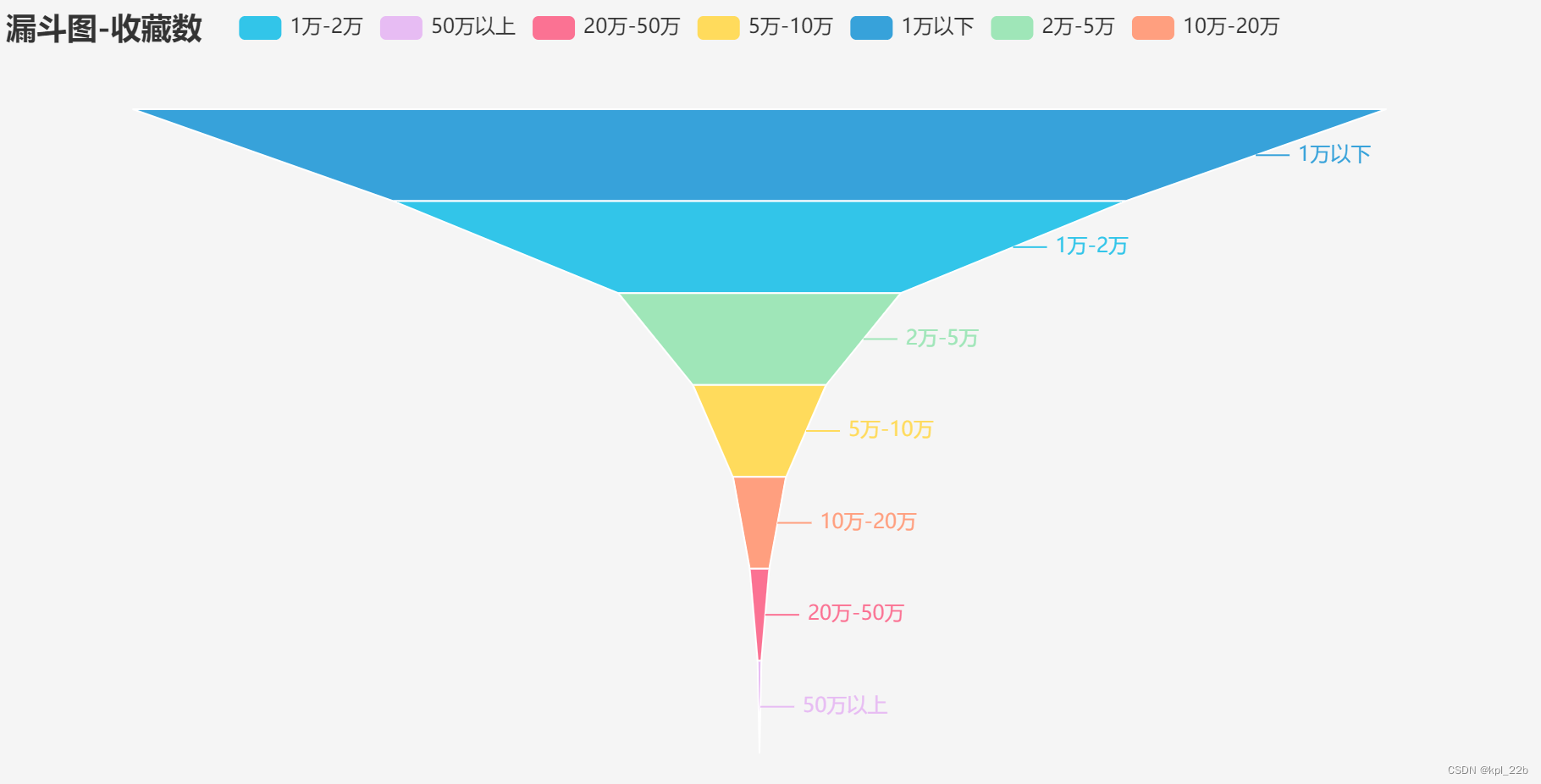
4漏斗图
4.1代码
- # 设置数据分组的位置
- bins_words = [0, 10000, 25000, 50000, 100000, 200000, 500000, 2000000]
-
- words_distribution1 = pd.value_counts(pd.cut(data["当前被收藏数"], bins=bins_words), sort=False)
- s=['1万以下', '1万-2万', '2万-5万', '5万-10万', '10万-20万', '20万-50万', '50万以上']
- from pyecharts.charts import Funnel
- c = (
- Funnel(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
- .add("类目", [list(z) for z in zip(s, words_distribution1.values.tolist())])
- .set_global_opts(title_opts=opts.TitleOpts(title="漏斗图-收藏数"))
- )
- c.render_notebook()
4.2结果