
- 1【爬虫实战】Python爬取知网文献信息_python爬虫知网
- 2人工智能:重塑语言翻译的未来
- 3代码随想录算法训练营day46 | 完全背包、518. 零钱兑换 II、377. 组合总和 Ⅳ
- 4爬虫实战系列!淘宝店铺各品牌手机售卖信息爬取及可视化!_爬取商品售量进行可视化分析
- 5YOLO的作者们_yolo系列作者是同一个团队吗
- 6CI-03T语音控制MP3模块音乐播报
- 7JDBC---Java连接数据库_javajdbc连接数据库
- 8python手机版破解wifi脚本,python手机版安装教程_termux查看wifi密码
- 9vs2017+openni2+opencv343 人脸活体检测_openni 人脸检测
- 10北师大蔡苏教授:教育领域VR/AR的三个重点研究方向
机器学习之特征选择_机器学习的类型是根据算法还是特征选择器
赞
踩
转自:https://www.cnblogs.com/nolonely/p/6435083.html
特征选择方法初识:
1、为什么要做特征选择
在有限的样本数目下,用大量的特征来设计分类器计算开销太大而且分类性能差。
2、特征选择的确切含义
将高维空间的样本通过映射或者是变换的方式转换到低维空间,达到降维的目的,然后通过特征选取删选掉冗余和不相关的特征来进一步降维。
3、特征选取的原则
获取尽可能小的特征子集,不显著降低分类精度、不影响类分布以及特征子集应具有稳定适应性强等特点
主要有三种方法:
1、Filter方法
其主要思想是:对每一维的特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该维特征的重要性,然后依据权重排序。
主要的方法有:
-
- Chi-squared test(卡方检验)
- information gain(信息增益),详细可见“简单易学的机器学习算法——决策树之ID3算法”
- correlation coefficient scores(相关系数)
2、Wrapper方法
其主要思想是:将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个是一个优化问题,这里有很多的优化算法可以解决,尤其是一些启发式的优化算法,如GA,PSO,DE,ABC等,详见“优化算法——人工蜂群算法(ABC)”,“优化算法——粒子群算法(PSO)”。
主要方法有: (递归特征消除算法)
3、Embedded方法
其主要思想是:在模型既定的情况下学习出对提高模型准确性最好的属性。这句话并不是很好理解,其实是讲在确定模型的过程中,挑选出那些对模型的训练有重要意义的属性。
简单易学的机器学习算法——岭回归(Ridge Regression)”,岭回归就是在基本线性回归的过程中加入了正则项。
总结以及注意点
这篇文章中最后提到了一点就是用特征选择的一点Trap。个人的理解是这样的,特征选择不同于特征提取,特征和模型是分不开,选择不同的特征训练出的模型是不同的。在机器学习=模型+策略+算法的框架下,特征选择就是模型选择的一部分,是分不开的。这样文章最后提到的特征选择和交叉验证就好理解了,是先进行分组还是先进行特征选择。
答案是当然是先进行分组,因为交叉验证的目的是做模型选择,既然特征选择是模型选择的一部分,那么理所应当是先进行分组。如果先进行特征选择,即在整个数据集中挑选择机,这样挑选的子集就具有随机性。
我们可以拿正则化来举例,正则化是对权重约束,这样的约束参数是在模型训练的过程中确定的,而不是事先定好然后再进行交叉验证的。
特征选择方法具体分细节总结:
1 去掉取值变化小的特征 Removing features with low variance
该方法一般用在特征选择前作为一个预处理的工作,即先去掉取值变化小的特征,然后再使用其他的特征选择方法选择特征。
2 单变量特征选择 Univariate feature selection
单变量特征选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。对于回归和分类问题可以采用卡方检验等方式对特征进行测试。
2.1 Pearson相关系数 Pearson Correlation
皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关。
2.2 互信息和最大信息系数 Mutual information and maximal information coefficient (MIC)
以上就是经典的互信息公式了。想把互信息直接用于特征选择其实不是太方便:1、它不属于度量方式,也没有办法归一化,在不同数据及上的结果无法做比较;2、对于连续变量的计算不是很方便(X和Y都是集合,x,y都是离散的取值),通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
2.3 距离相关系数 (Distance correlation)
距离相关系数是为了克服Pearson相关系数的弱点而生的。Pearson相关系数是0,我们也不能断定这两个变量是独立的(有可能是非线性相关);但如果距离相关系数是0,那么我们就可以说这两个变量是独立的。
2.4 基于学习模型的特征排序 (Model based ranking)
这种方法的思路是直接使用你要用的机器学习算法,针对每个单独的特征和响应变量建立预测模型。其实Pearson相关系数等价于线性回归里的标准化回归系数。假如某个特征和响应变量之间的关系是非线性的,可以用基于树的方法(决策树、随机森林)、或者扩展的线性模型等。基于树的方法比较易于使用,因为他们对非线性关系的建模比较好,并且不需要太多的调试。但要注意过拟合问题,因此树的深度最好不要太大,再就是运用交叉验证。
3 线性模型和正则化
单变量特征选择方法独立的衡量每个特征与响应变量之间的关系,另一种主流的特征选择方法是基于机器学习模型的方法。有些机器学习方法本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,例如回归模型,SVM,决策树,随机森林等等。
3.1 正则化模型
正则化就是把额外的约束或者惩罚项加到已有模型(损失函数)上,以防止过拟合并提高泛化能力。损失函数由原来的E(X,Y)变为E(X,Y)+alpha||w||,w是模型系数组成的向量(有些地方也叫参数parameter,coefficients),||·||一般是L1或者L2范数,alpha是一个可调的参数,控制着正则化的强度。当用在线性模型上时,L1正则化和L2正则化也称为Lasso和Ridge。
3.2 L1正则化/Lasso
L1正则化将系数w的l1范数作为惩罚项加到损失函数上,由于正则项非零,这就迫使那些弱的特征所对应的系数变成0。因此L1正则化往往会使学到的模型很稀疏(系数w经常为0),这个特性使得L1正则化成为一种很好的特征选择方法。
3.3 L2正则化/Ridge regression
L2正则化将系数向量的L2范数添加到了损失函数中。由于L2惩罚项中系数是二次方的,这使得L2和L1有着诸多差异,最明显的一点就是,L2正则化会让系数的取值变得平均。对于关联特征,这意味着他们能够获得更相近的对应系数。还是以Y=X1+X2为例,假设X1和X2具有很强的关联,如果用L1正则化,不论学到的模型是Y=X1+X2还是Y=2X1,惩罚都是一样的,都是2alpha。但是对于L2来说,第一个模型的惩罚项是2alpha,但第二个模型的是4*alpha。可以看出,系数之和为常数时,各系数相等时惩罚是最小的,所以才有了L2会让各个系数趋于相同的特点。
可以看出,L2正则化对于特征选择来说一种稳定的模型,不像L1正则化那样,系数会因为细微的数据变化而波动。所以L2正则化和L1正则化提供的价值是不同的,L2正则化对于特征理解来说更加有用:表示能力强的特征对应的系数是非零
4 随机森林
随机森林具有准确率高、鲁棒性好、易于使用等优点,这使得它成为了目前最流行的机器学习算法之一。随机森林提供了两种特征选择的方法:mean decrease impurity和mean decrease accuracy。
4.1 平均不纯度减少 mean decrease impurity
随机森林由多个决策树构成。决策树中的每一个节点都是关于某个特征的条件,为的是将数据集按照不同的响应变量一分为二。利用不纯度可以确定节点(最优条件),对于分类问题,通常采用基尼不纯度或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
4.2 平均精确率减少 Mean decrease accuracy
另一种常用的特征选择方法就是直接度量每个特征对模型精确率的影响。主要思路是打乱每个特征的特征值顺序,并且度量顺序变动对模型的精确率的影响。很明显,对于不重要的变量来说,打乱顺序对模型的精确率影响不会太大,但是对于重要的变量来说,打乱顺序就会降低模型的精确率。
5 两种顶层特征选择算法
之所以叫做顶层,是因为他们都是建立在基于模型的特征选择方法基础之上的,例如回归和SVM,在不同的子集上建立模型,然后汇总最终确定特征得分。
5.1 稳定性选择 Stability selection
稳定性选择是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回归、SVM或其他类似的方法。它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果,比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。理想情况下,重要特征的得分会接近100%。稍微弱一点的特征得分会是非0的数,而最无用的特征得分将会接近于0。
5.2 递归特征消除 Recursive feature elimination (RFE)
递归特征消除的主要思想是反复的构建模型(如SVM或者回归模型)然后选出最好的(或者最差的)的特征(可以根据系数来选),把选出来的特征放到一遍,然后在剩余的特征上重复这个过程,直到所有特征都遍历了。这个过程中特征被消除的次序就是特征的排序。因此,这是一种寻找最优特征子集的贪心算法。
RFE的稳定性很大程度上取决于在迭代的时候底层用哪种模型。例如,假如RFE采用的普通的回归,没有经过正则化的回归是不稳定的,那么RFE就是不稳定的;假如采用的是Ridge,而用Ridge正则化的回归是稳定的,那么RFE就是稳定的。
7、特征获取方法的选取原则
a、处理的数据类型
b、处理的问题规模
c、问题需要分类的数量
d、对噪声的容忍能力
e、无噪声环境下,产生稳定性好、最优特征子集的能力。
互信息Mutual Informantion
yj对xi的互信息定义为后验概率与先验概率比值的对数。
互信息越大,表明yj对于确定xi的取值的贡献度越大。
实际上,互信息衡量的是xi与y的独立性,如果他俩独立,则互信息发值为零,则xi与y不相关,则可以剔除xi,反之,如果互信息发值越大则他们的相关性越大
基于期望交叉熵的特征项选择

p(ci|w)表示在出现词条w时文档属于类别ci的概率。
交叉熵反应了文本类别的概率分布与在出现了某个词条的情况下文本类别的概率分布之间的距离。词条的交叉熵越大,对文本类别分布影响也就越大。
如果使用具有对称性的交叉熵,那公式就变成了

特征选择->前向搜索,后向搜索

1初始化特征集F为空
2扫描i从1到n,
如果第i个特征不再F中,那么将特征i和F放到一起Fi在只使用Fi中特征的情况下,利用交叉验证来得到Fi的错误率。
3从上步中得到的n个Fi中选择出错误率最小的Fi,更新F为Fi
如果F中的特征数达到n或者预设定的阈值(如果有),那么输出整个搜索过程中最好的F,没达到转到2
这里指不断地使用不同的特征集来测试学习算法,即每次增量地从剩余未选中的特征选出一个加入特征集中,待达到阈值或者n时,从所有的F中选出错误率最小的。
开始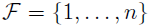

向前和向后搜索的时间复杂度都比较高,时间复杂度为O(n2)
特征选择算法实现:http://blog.csdn.net/fighting_one_piece/article/details/37912051
更多详细信息参见: http://www.tuicool.com/articles/ieUvaq
参考自:http://blog.csdn.net/google19890102/article/details/40019271

