
- 1大厂架构师面试题top20_架构师面试名词术语解释
- 2Windows 11 - 打开操作安全中心提示 “需要使用新应用以打开此 Windowsdefender 链接“ 解决方案(电脑更新了 Win11 系统版本后,想关闭病毒防护盾牌的时候提示打不开)_需要使用新应用以打开此windowsdefender链接
- 3hadoop的平台搭建和运行_搭建完成hdfs平台,并可运行
- 4喰星云·数字化餐饮服务系统 多处 SQL注入漏洞复现
- 5解决由于方法异步导致数据丢失问题_异步复位丢失数据
- 6python小程序之正五角星_python五角星编程代码
- 7Blender里的三种绑定 (三)骨骼_blender骨骼
- 8Android 串口通信之间的发送数据与接收数据(详解)_安卓串口通信
- 9[大数据]Hive(4)_hive 4
- 101024_2017年左右1024网站,一位程序员结婚十年后,老婆出差,其实是跟主人在景区玩自
让图片开口说话的模型Hallo: 基于音频驱动的肖像图像动画,精准唇形同步,支持多种语言和风格_hallo: hierarchical audio-driven visual synthesis
赞
踩
前言
让静态的图片“开口说话”,一直是人们对人工智能的期待。近年来,随着深度学习技术的发展,音频驱动的肖像图像动画技术取得了长足的进步。各种模型涌现,但如何实现精准的唇形同步、保持视频的真实感和流畅性,以及支持多种语言和风格,仍然是研究人员面临的挑战。
来自复旦大学、百度、苏黎世联邦理工学院和南京大学的研究团队,共同开发了一个新的音频驱动肖像图像动画模型 Hallo,该模型在多个方面实现了突破,为打造更逼真的动画形象提供了新的可能性。
-
Huggingface模型下载:https://huggingface.co/fudan-generative-ai/hallo
-
AI快站模型免费加速下载:https://aifasthub.com/models/fudan-generative-ai
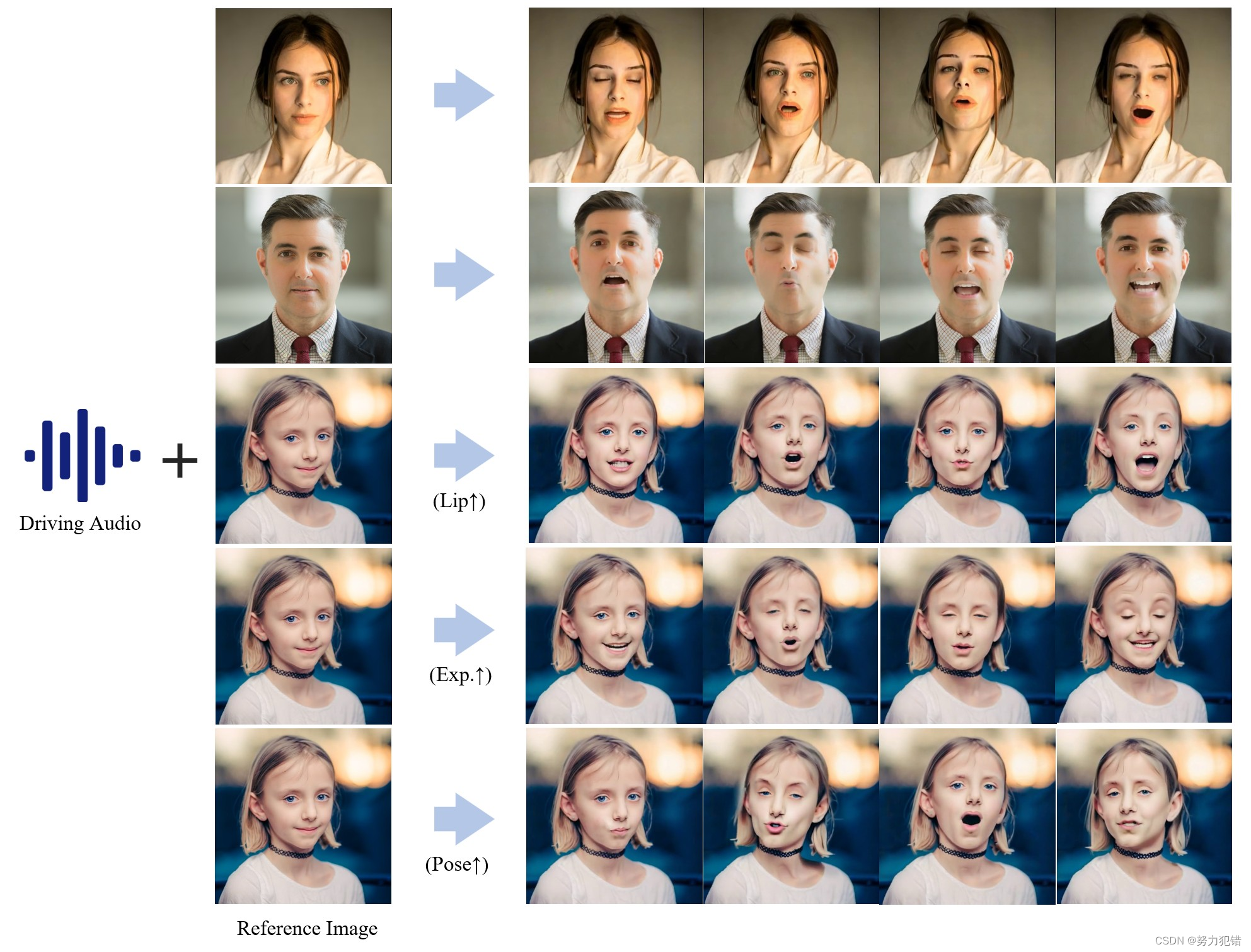
技术特点
Hallo 的核心技术在于其创新性的 分层音频驱动视觉合成模块 (Hierarchical Audio-Driven Visual Synthesis),该模块通过交叉注意力机制,建立了音频与视觉特征之间精准的对应关系,进而实现对唇形、表情和姿态的精准控制。
-
精准的唇形同步: Hallo 通过音频驱动模型的训练,能够根据音频信号,精准地生成与声音内容一致的唇形变化,让动画形象的嘴巴更自然地“动起来”。
-
多样化的表情和姿态: Hallo 能够根据音频内容,生成多种表情和姿态,使动画形象更生动、更自然。同时,它还支持用户调整表情和姿态的控制力度,实现个性化定制。
-
支持多种语言和风格: Hallo 能够根据不同的音频语言进行训练,并支持不同的视觉风格,例如素描、油画、卡通等。这使得 Hallo 能够生成更具多样性和个性化的动画形象。
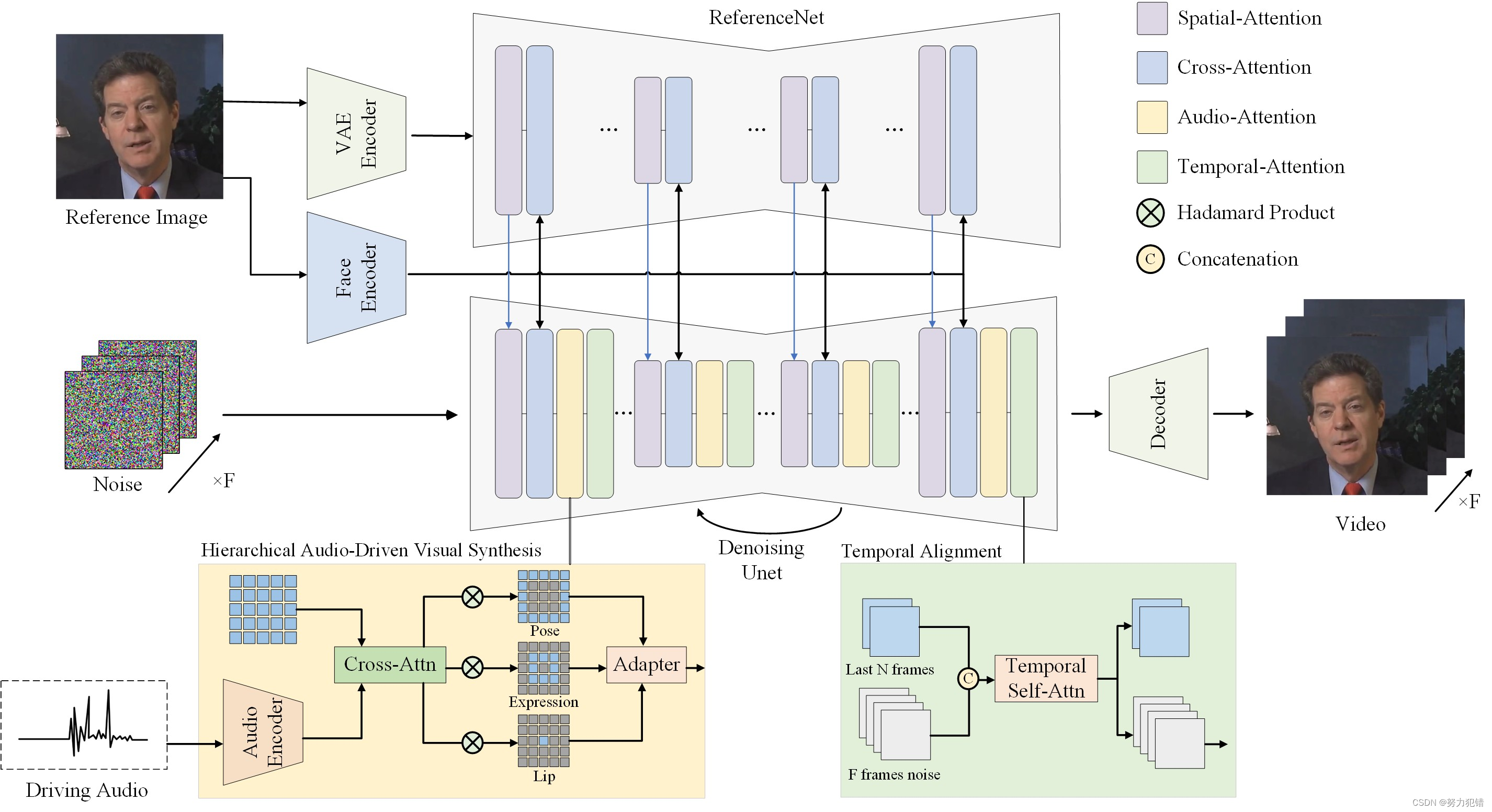
Hallo 的整体架构包含以下几个关键部分:
-
ReferenceNet: 使用参考图像来指导视觉生成,增强动画的视觉纹理信息。
-
Face Encoder: 提取人脸图像的身份特征,确保动画形象保持原有面部特征。
-
Audio Encoder: 将音频信号编码成运动信息,驱动动画的唇形、表情和姿态变化。
-
UNet Denoiser: 使用 U-Net 网络进行噪声去除,提高动画的质量和清晰度。
-
Temporal Alignment: 对视频帧进行时间对齐,确保动画的流畅性和连贯性。
性能表现
Hallo 在多个指标上都展现出显著的优势,超越了现有的其他模型:
-
图像和视频质量: Hallo 在 FID 和 FVD 指标上表现突出,表明其生成的高质量图像和视频更加逼真,更加接近真实世界的人物。
-
唇形同步精度: Hallo 在唇形同步方面表现优异,在 Sync-C 指标上取得了接近真实视频的成绩,表明其能够更精准地将音频信息转化为唇形运动。
-
运动多样性: Hallo 能够灵活地控制表情和姿态,生成具有多种表情和姿态的动画形象,提升了动画的丰富度和自然度。
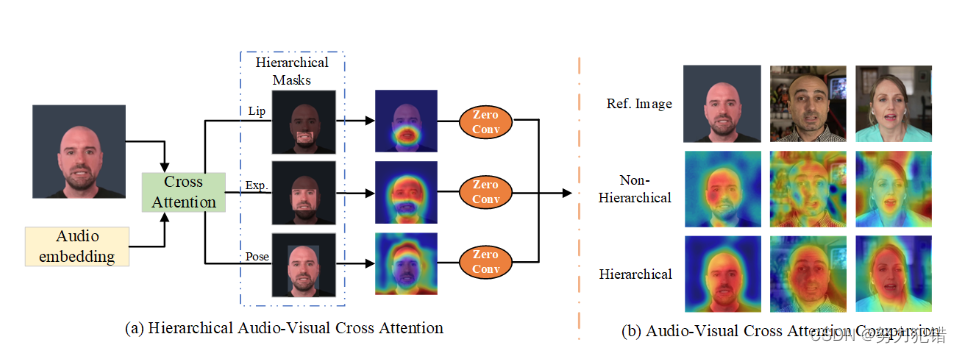
应用场景
Hallo 在多个领域都拥有广泛的应用前景:
-
虚拟偶像: 为虚拟偶像制作更生动、更真实的动画形象,提升用户体验。
-
影视制作: 创建逼真的数字角色,简化影视制作流程,降低制作成本。
-
游戏开发: 为游戏角色提供更丰富、更自然的动画,提升游戏体验。
-
教育和培训: 制作更生动的教学视频,提升学习效率。
-
人机交互: 创建更逼真的虚拟助手,为用户提供更自然、更友好的交互体验。
总结
Hallo 的出现,标志着音频驱动的肖像图像动画技术迈入了新的发展阶段。它不仅为开发者提供了强大的工具,也为未来各种应用场景下的动画形象创作带来了新的可能性。相信随着技术的不断发展,Hallo 将会为我们带来更多惊喜,让我们可以更加便捷地制作出更逼真、更自然的动画形象。
模型下载
Huggingface模型下载
https://huggingface.co/fudan-generative-ai/hallo
AI快站模型免费加速下载
https://aifasthub.com/models/fudan-generative-ai


