
- 1python123基本数据类型_Python-基本数据类型
- 22024年最全Android Studio 修改常用设置(2),2024年最新2024非科班生的Android面试之路_android studio 2024 界面改变
- 3美团笔试题目(Java后端5题2小时)_美团java笔试题
- 4verilog实现仲裁器设计_verilog仲裁器
- 5什么是FineBI?如何为FineBI配置数据源?
- 6怎样使用js技术实现Chrome投屏功能?_前端如何实现投屏功能
- 7代码随想录Day66(图论Part03)
- 8Kafka生产者详解_kafka producerrecord
- 9SM3加密算法
- 10maven打包/跳过某个modules_maven跳过某个模块编译
图片识别,从图片中提取文字,OCR_图片识别文字开源
赞
踩
1. 方案对比
| 方案 | 环境准备 | 优势 | 劣势 | 结论 | |
|---|---|---|---|---|---|
| 1 | tesseract | 新增环境变量 下载语言包 cmd命令:tesseract 输入图片的文件名 输出文件名 [-l lang][-psm pagesegmode][configfile…] | 使用简单 | 同下 | 不推荐 |
| 2 | pytesseract | 需要先下载1的tesseract pip install pillow pip install pytesseract import pytesseract text = pytesseract.image_to_string(image, lang=‘chi_sim’) | 平均解析时间: 6.94s | 1. 使用Levenshtein距离来评估识别准确度 2. 准确度值不稳定,高的能有95.40%,低的有过20.23% | 不推荐 |
| 3 | Umi-OCR | 直接拖入图片自动识别 | 1.平均置信度96.4% 2.平均解析时间:5.82s 3.并发测试(iterations = 100):11.31s | 1. 仅支持Windows 2. 高CPU占用,并发测试时CPU占用百分之五六十左右 | 推荐 |
| 4 | 百度飞桨 | pip install paddlepaddle pip install paddleocr 需下载模型 | 平均置信度95.7% | 1. 配置复杂 2. 解析时间太长了,平均一张图要141.26s 3. 运行的时候内存占用高,电脑多次出现卡死情况 4. 跑单张图片还行,批量的话不太行啊… | 不推荐 |
| 5 | GPT-4 Vision Preview | 1.平均解析时间:54.30s 2. 会自行增添、删减、修改、提炼、总结、优化 3. prompt详见 2.5.3 4.中文识别效果太拉了 | 不推荐 | ||
| 6 | Kimi(moonshot-v1-8k) | 平均解析时间:24.51s | 推荐 |
2. 详细介绍
2.1 Google开源ocr:tesseract
源码链接:tesseract-ocr
2.1.1 简介
2.1.2 使用
2.1.3 效果
同2.2
2.2 Python自带库pytesseract
2.2.1 简介
其实是对tesseract做的一层Python API封装,是Google的Tesseract-OCR引擎包装器,它的核心是tesseract。
2.2.2 使用
import pytesseract
在使用之前,需要先安装tesseract
默认支持英文,中文需要下载语言包
pytesseract.image_to_string()
2.2.3 测试代码
# -*- coding:utf-8 -*- import pytesseract from PIL import Image import re import time def demo(): tot_time = [] with open('output1.txt', 'w', encoding='utf-8') as file: while True: pic_name = input("输入图片文件名(输入#结束):") if pic_name == '#': break start_time = time.time() image = Image.open(pic_name + '.png') gray_image = image.convert('L') text = pytesseract.image_to_string(gray_image, lang='chi_sim') # 图片转字符串 print(text) end_time = time.time() print(f'time = {end_time - start_time}') tot_time.append(end_time - start_time) file.write(text + '\n') file.write('-' * 50 + '\n') avg_time = sum(tot_time) / len(tot_time) print(f'平均解析时间: {avg_time}') with open('output1.txt', 'r', encoding='utf-8') as file: text = file.read() text = re.sub(r' +', ' ', text) # 空格处理 with open('output1.txt', 'w', encoding='utf-8') as file: file.write(text) if __name__ == '__main__': demo()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
2.2.4 效果
2.3 Umi-OCR
源码链接:Umi-OCR
2.3.1 简介
封装好的PaddleOCR(PaddleOCR见2.4)(但是据作者说,有优化),UI界面;
软件发布包下载为 .7z 压缩包或 .7z.exe 自解压包。自解压包可在没有安装压缩软件的电脑上,解压文件;
本软件无需安装。解压后,点击 Umi-OCR.exe 即可启动程序;
暂无Linux版本。
软件:软件下载链接
2.3.2 使用
本人下载的是Rapid 引擎插件版(速度稍慢,内存占用低,适合低配机器,兼容性好)
2.3.3 效果
2.4 百度飞桨
源码链接:PaddleOCR
2.4.1 简介
2.4.2 使用
其中模型下载直接在后面链接下载,需要下载三个,并且有三个可选模型,本人选用第一个模型(下载的时候选推理模型):模型下载链接
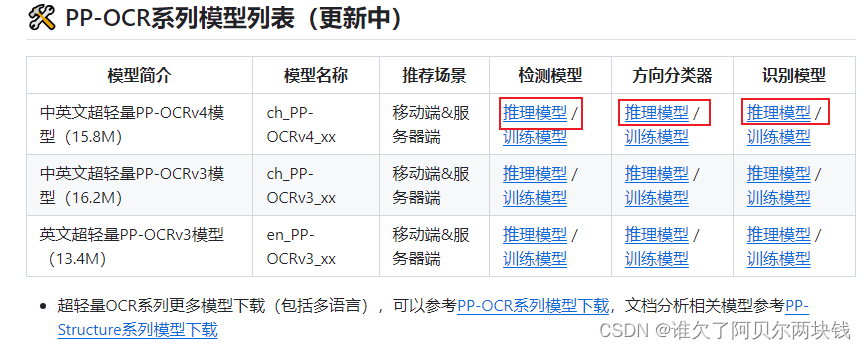
【注意】:
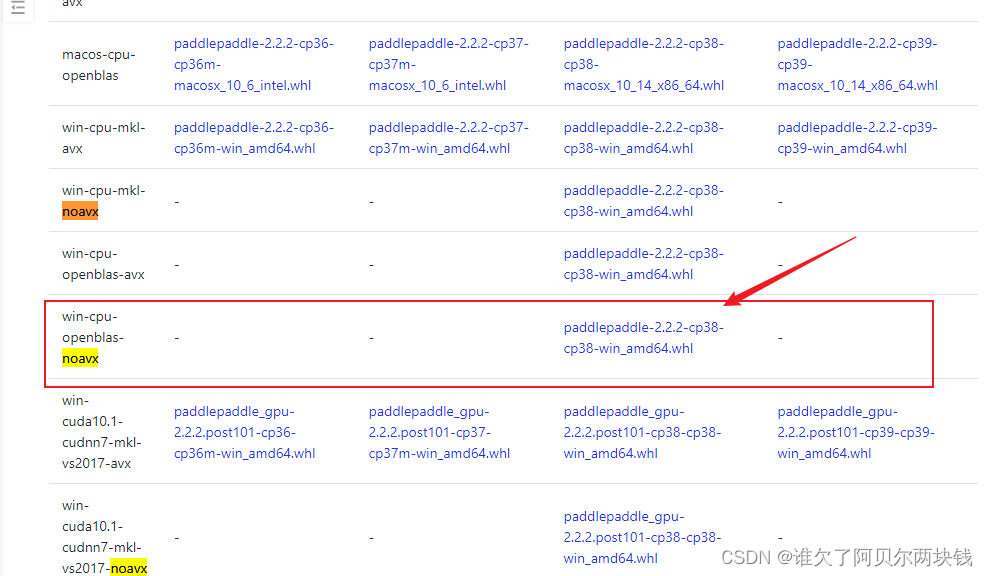
- 建议使用 python 3.8.5
- 若报noavx错,需在这里找到指定版本的wheel下载,而后直接pip install下载好的wheel,链接(本人下的CPU版):wheel下载
2.4.3 测试代码
from paddleocr import PaddleOCR, draw_ocr from PIL import Image import time # load model ocr = PaddleOCR(lang="ch", use_gpu=False, det_model_dir="inference_model/ch_PP-OCRv4_det_infer", cls_model_dir="inference_model/ch_ppocr_mobile_v2.0_cls_infer", rec_model_dir="inference_model/ch_PP-OCRv4_rec_infer") # load dataset tot_time = [] tot_acc = [] while True: img_name = input('输入图片文件名(输入#结束):') if img_name == '#': break start_time = time.time() img_path = img_name + '.png' result = ocr.ocr(img_path) acc = [] for line in result: # 只打印文本和识别置信度 text, confidence = line[1] acc.append(confidence) print(f'文本: {text}, 置信度: {confidence:.4f}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.4.4 效果
2.5 GPT-4 vision preview
2.5.1 简介
2.5.2 使用
- 使用postman向API发请求
{ "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": [{"type": "text", "text": "你现在是一个名为'ProcessFlowBot'的AI助手。你的任务是识别图片中的操作步骤和流程,而不是识别图片中的所有文字。请提供详细的、准确的步骤和流程描述,确保不包含任何其他不相关信息。你应该专注于在回复中提供流程和步骤的详细描述,以便用户获得清晰的操作指导。"}, { "type": "image_url", "image_url": { "url": "如果做的是图像OCR,这里支持base64编码。(python自带库就可以实现图片转base64编码,import base64)。或者不用base64,之间用网上的图片,放url就行。"} } ] } ], "model": "gpt4", "temperature": 0.6, "max_tokens": 2000, // "top_p": 0.8, "frequency_penalty": 0, "presence_penalty": 0.2 // "stream": true }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- Python代码(本地图片转base64,然后请求gpt)
# -*- coding: utf-8 -*- import base64 import requests import time # OpenAI API Key api_key = "你的api key" # Function to encode the image def encode_image(image_path): with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode('utf-8') # Path to your image image_path = "测试图片/2.png" start_time = time.time() # Getting the base64 string base64_image = encode_image(image_path) # print(base64_image) headers = { "Content-Type": "application/json", # "Authorization": f"Bearer {api_key}" "api-key": f"{api_key}" } payload = { "model": "gpt-4-vision-preview", "messages": [ { "role": "user", "content": [ { "type": "text", "text": "你是一个OCR(光学字符识别)专家助手。接下来我会给你发送一张或多张包含文字内容的图像。请你仔细分析识别出图像中的所有文本,并将识别出的文本内容原封不动地输出。识别时请注意以下几点: 1. 请将图像中的所有文本全部识别出来,不要遗漏任何文字,包括背景中的文字、印章等。背景中的水印不需要输出。 2. 识别结果要尽可能准确无误,请尽量避免出现错别字、漏字或多识别的情况。如有无法确定的字符,可用[]标注。 3. 输出识别结果时,要完全保持原有的格式、标点符号、换行、空格、缩进等,确保与原图中的文本格式完全一致。 4. 如果一张图像中同时包含了横向和竖向排列的文字,请先输出横向文字,然后再输出竖向文字,并在两部分内容之间用2个换行分隔。 5. 如果图像中有多种不同字体/字号/颜色的文字,输出时统一使用固定格式即可,不需要特别标注。 6. 对于表格、图表等特殊格式,也请尽量按照原有格式输出文本内容。如果实在无法完美还原格式,输出纯文本也可以。最后输出的内容无需加引号或其他任何标识,识别出的文字直接原样输出即可。如果给你的图像中没有识别到任何文字,请回复’未识别到任何文字内容‘。" }, { "type": "image_url", "image_url": { "url": f"data:image/jpeg;base64,{base64_image}" } } ] } ], "max_tokens": 2000, "temperature": 0.6 } response = requests.post("api网址", headers=headers, json=payload) end_time = time.time() print(response.json()) print(f'time = {end_time - start_time}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
【优化方向】:
- prompt enginering:
- 用了这个优化prompt:promptperfect
微软官方:微软官方prompt优化 - 别的一些参数,比如temperature
- 对图像使用视觉增强:
GPT-4 Turbo with Vision 提供对 Azure AI 服务定制增强功能的独占访问权限。 与 Azure AI 视觉结合使用时,它可以为聊天模型提供有关图像中可见文本和对象位置的更详细信息,从而增强聊天体验。“光学字符识别 (OCR)”集成使模型能够针对密集文本、转换后的图像和数字较多的财务文档生成更高质量的响应。【GPT-4 Turbo with Vision 的 Azure AI 增强功能将与核心功能分开计费。 GPT-4 Turbo with Vision 的每个特定 Azure AI 增强功能都有其独特的费用。】
2.5.3 效果
主要做的是prompt enginering
prompt示例1:
你是一个OCR(光学字符识别)专家助手,接下来我会给你发送一张或多张包含文字内容的图像。请你仔细分析识别出图像中的所有文本,并将识别出的文本内容原封不动地输出。识别时请注意以下几点: 1. 请将图像中的所有文本全部识别出来,不要遗漏任何文字。 2. 识别结果要尽可能准确无误,确保每个字都能识别正确,不要有错别字或漏字。3. 输出识别结果时,要保持原有的格式、标点符号、换行等,确保与原图中的文本格式完全一致。4. 如果图像中同时包含了横向和竖向排列的文字,请按照在图中的排列顺序依次输出。5. 如果图像中有多种不同字体/字号/颜色的文字,输出时不需要特别标注,保持原样输出即可。
【使用感受】:
- 若图片中文字格式比较规范(如一段纯文本等),识别准确度较高。但也存在gpt自动纠正 / 猜测的现象,缺字漏字现象;
- 若图片格式不统一,布局杂乱,识别准确度低。存在大量gpt自动纠正 / 猜测的现象,缺字漏字现象;
- 若图片中有icon,gpt会将其识别转化为文字(如点赞数、收藏数等)。
2.6 Kimi
2.6.1 简介
本人使用的是moonshot-v1-8k,中文OCR效果很好了(但是英文似乎gpt4更优)
API使用文档:API
官方文档的定价如下
| 模型 | 计费单位 | 价格 |
|---|---|---|
| moonshot-v1-8k | 1M tokens | ¥12.00 |
| moonshot-v1-32k | 1M tokens | ¥24.00 |
| moonshot-v1-128k | 1M tokens | ¥60.00 |
此处 1M = 1,000,000。以上模型的区别在于它们的最大上下文长度,这个长度包括了输入消息和生成的输出,在效果上并没有什么区别。
充值与限速
| 用户等级 | 累计充值金额 | 并发 (同一时间内我们最多处理的来自您的请求数) | RPM (request per minute 指一分钟内您最多向我们发起的请求数) | TPM (token per minute 指一分钟内您最多和我们交互的token数) | TPD (token per day 指一天内您最多和我们交互的token数) |
|---|---|---|---|---|---|
| Free | ¥ 0 | 1 | 3 | 32,000 | 1,500,000 |
| Tier1 | ¥ 50 | 50 | 200 | 128,000 | 10,000,000 |
| Tier2 | ¥ 100 | 100 | 500 | 128,000 | 20,000,000 |
| Tier3 | ¥ 500 | 200 | 5,000 | 384,000 | Unlimited |
| Tier4 | ¥ 5,000 | 400 | 5,000 | 768,000 | Unlimited |
| Tier5 | ¥ 20,000 | 1,000 | 10,000 | 2,000,000 | Unlimited |
2.6.2 使用
Python代码
# -*- coding: utf-8 -*- from pathlib import Path from openai import OpenAI import time client = OpenAI( api_key="你的api key", base_url="https://api.moonshot.cn/v1", ) tot_time = [] while True: file_name = input('请输入文件名(以#结尾):') if file_name == '#': break file_path = './测试图片/' + file_name + '.png' # file_path = file_name + '.png' # file_object = client.files.create(file=Path(file_path), purpose="file-extract") file_object = client.files.create(file=Path(file_path), purpose="file-extract") # 获取结果 # file_content = client.files.retrieve_content(file_id=file_object.id) # 注意,之前 retrieve_content api 在最新版本标记了 warning, 可以用下面这行代替 # 如果是旧版本,可以用 retrieve_content file_content = client.files.content(file_id=file_object.id).text start_time = time.time() # 把它放进请求中 messages = [ { "role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。", }, { "role": "system", "content": file_content, }, {"role": "user", "content": "你现在是一名需求分析专家。你的任务是识别图片中的逻辑、操作或流程,而不是识别图片中的所有文字。我会给你提供一些图片,图片照片那个会用红色方框、红色箭头标注出需要修改或者操作的位置," "可能也会有一些说明性的红色文字。请你注意这些标记,提供详细、准确的操作,并确保不要包含其他不相关信息。"}, # "content": "你现在是一个名为'ProcessFlowBot'的AI助手。你的任务是识别图片中的操作步骤和流程,而不是识别图片中的所有文字。" # "请提供详细的、准确的步骤,流程描述和操作,确保不包含任何其他不相关信息。你应该专注于在回复中提供流程和步骤的详细描述,以便用户获得清晰的操作指导。"}, # "content": "你是一个OCR(光学字符识别)专家助手。接下来我会给你发送一张或多张包含文字内容的图像。请你仔细分析识别出图像中的所有文本,并将识别出的文本内容原封不动地输出。识别时请注意以下几点: 1. 请将图像中的所有文本全部识别出来,不要遗漏任何文字,包括背景中的文字、水印、印章等。2. 识别结果要尽可能准确无误,请尽量避免出现错别字、漏字或多识别的情况。如有无法确定的字符,可用[]标注。3. 输出识别结果时,要完全保持原有的格式、标点符号、换行、空格、缩进等,确保与原图中的文本格式完全一致。4. 如果一张图像中同时包含了横向和竖向排列的文字,请先输出横向文字,然后再输出竖向文字,并在两部分内容之间用2个换行分隔。5. 如果图像中有多种不同字体/字号/颜色的文字,输出时统一使用固定格式即可,不需要特别标注。6. 对于表格、图表等特殊格式,也请尽量按照原有格式输出文本内容。如果实在无法完美还原格式,输出纯文本也可以。最后输出的内容无需加引号或其他任何标识,识别出的文字直接原样输出即可。"}, ] # 然后调用 chat-completion, 获取 kimi 的回答 completion = client.chat.completions.create( model="moonshot-v1-8k", messages=messages, temperature=0.3, ) end_time = time.time() print(completion.choices[0].message) each_time = end_time - start_time print(f'time = {each_time}') tot_time.append(each_time) print(sum(tot_time) / len(tot_time))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66

