
Hadoop集群安装配置教程
链接: https://pan.baidu.com/s/1rDyTLQKA5MvfVWc8CtoL_g
提取码:8v19
--来自百度网盘超级会员V6的分享
1、环境
| 名称 | 物理IP | 说明 | 版本 | 操作系统 |
|---|---|---|---|---|
| hadoop-master | 192.168.200.34 | 名称节点 | 3.1.3 | ubuntu20.04 |
| hadoop-slave | 192.168.200.35 | 数据节点 | 3.1.3 | ubuntu20.04 |
- #添加主机名映射(两节点同步进行)
- root@hadoop-master:~# vim /etc/hosts
- root@hadoop-master:~# tail -2 /etc/hosts
- 192.168.200.34 hadoop-master
- 192.168.200.35 hadoop-slave
2、创建hadoop用户(两节点同步进行)
- #创建hadoop用户
- root@hadoop-master:~# useradd -m hadoop -s /bin/bash
-
- #设置hadoop密码
- root@hadoop-master:~# passwd hadoop
-
- #为新建的hadoop增加管理员权限
- root@hadoop-master:~# adduser hadoop sudo
3、安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
- #安装openssh-server
- hadoop@hadoop-master:~$ sudo apt-get -y install openssh-server
- #生成密匙
- hadoop@hadoop-master:~$ ssh-keygen -t rsa
-
- #加入授权,为了让Master节点能够无密码SSH登录本机
- hadoop@hadoop-master:~$ cd .ssh/
- hadoop@hadoop-master:~/.ssh$ cat id_rsa.pub > authorized_keys
- #将hadoop-master节点上的公匙传输到hadoop-slave节点
- hadoop@hadoop-master:~/.ssh$ scp ~/.ssh/id_rsa.pub hadoop@hadoop-slave:/home/hadoop/
-
- #接着在hadoop-slave节点上,将SSH公匙加入授权:
- hadoop@hadoop-slave:~$ mkdir .ssh
- hadoop@hadoop-slave:~$ cat id_rsa.pub > ./.ssh/authorized_keys
4、安装Java环境(两节点同步进行)
- #创建JDK存放目录
- hadoop@hadoop-master:~$ sudo mkdir -p /usr/lib/jvm
-
- #把JDK文件解压到/usr/lib/jvm目录下
- hadoop@hadoop-master:~$ sudo tar xf jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm/
- #添加环境变量
- hadoop@hadoop-master:~$ vim ~/.bashrc
- hadoop@hadoop-master:~$ tail -4 ~/.bashrc
- export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
- export JRE_HOME=${JAVA_HOME}/jre
- export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
- export PATH=${JAVA_HOME}/bin:$PATH
-
- #使环境变量立即生效
- hadoop@hadoop-master:~$ source ~/.bashrc
- #检查java是否安装成功
- hadoop@hadoop-master:~$ java -version
- java version "1.8.0_162"
- Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
- Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
5、安装Hadoop3.1.3(两节点同步进行)
- #安装hadoop
- hadoop@hadoop-master:~$ sudo tar xf hadoop-3.1.3.tar.gz -C /usr/local/
- hadoop@hadoop-master:~$ cd /usr/local/
- hadoop@hadoop-master:/usr/local$ sudo mv hadoop-3.1.3 hadoop
- hadoop@hadoop-master:/usr/local$ sudo chown -R hadoop:hadoop hadoop
- #验证Hadoop是否可用
- hadoop@hadoop-master:/usr/local$ cd hadoop/
- hadoop@hadoop-master:/usr/local/hadoop$ ./bin/hadoop version
- Hadoop 3.1.3
- Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
- Compiled by ztang on 2019-09-12T02:47Z
- Compiled with protoc 2.5.0
- From source with checksum ec785077c385118ac91aadde5ec9799
- This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar
6、配置PATH变量(两节点同步进行)
- #添加环境变量
- hadoop@hadoop-master:~$ vim ~/.bashrc
- hadoop@hadoop-master:~$ tail -1 ~/.bashrc
- export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
-
- #使环境变量立即生效
- hadoop@hadoop-master:~$ source ~/.bashrc
7、配置集群/分布式环境(两节点同步进行)
在配置集群/分布式模式时,需要修改/usr/local/hadoop/etc/hadoop目录下的配置文件,这里仅设置正常启动所必须的设置项,包括workers 、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml共5个文件,更多设置项可查看官方说明。
1、修改文件workers
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),所以,在伪分布式配置时,就采用了这种默认的配置,使得节点既作为名称节点也作为数据节点。在进行分布式配置时,可以保留localhost,让Master节点同时充当名称节点和数据节点,或者也可以删掉localhost这行,让Master节点仅作为名称节点使用。
本教程让Master节点仅作为名称节点使用,因此将workers文件中原来的localhost删除,只添加如下一行内容:
- hadoop@hadoop-master:~$ cd /usr/local/hadoop/etc/hadoop/
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ vim workers
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ cat workers
- hadoop-slave
2、修改文件core-site.xml
请把core-site.xml文件修改为如下内容:
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ nano core-site.xml
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ cat core-site.xml
- ......
-
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoop-master:9000</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/usr/local/hadoop/tmp</value>
- <description>Abase for other temporary directories.</description>
- </property>
- </configuration>
各个配置项的含义可以参考前面伪分布式模式时的介绍,这里不再赘述。
3、修改文件hdfs-site.xml
对于Hadoop的分布式文件系统HDFS而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。但是,本教程只有一个Slave节点作为数据节点,即集群中只有一个数据节点,数据只能保存一份,所以 ,dfs.replication的值还是设置为 1。hdfs-site.xml具体内容如下:
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ nano hdfs-site.xml
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ cat hdfs-site.xml
- ......
-
- <configuration>
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>hadoop-master:50090</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/usr/local/hadoop/tmp/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/usr/local/hadoop/tmp/dfs/data</value>
- </property>
- </configuration>

4、修改文件mapred-site.xml
把mapred-site.xml文件配置成如下内容:
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ nano mapred-site.xml
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ cat mapred-site.xml ......
-
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>hadoop-master:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>hadoop-master:19888</value>
- </property>
- <property>
- <name>yarn.app.mapreduce.am.env</name>
- <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
- </property>
- <property>
- <name>mapreduce.map.env</name>
- <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
- </property>
- <property>
- <name>mapreduce.reduce.env</name>
- <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
- </property>
- </configuration>
5、修改文件 yarn-site.xml
请把yarn-site.xml文件配置成如下内容:
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ nano yarn-site.xml
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ cat yarn-site.xml
- ......
-
- <configuration>
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>hadoop-master</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>
6、配置hadoop JAVA环境变量
- hadoop@hadoop-master:/usr/local/hadoop$ vim ./etc/hadoop/hadoop-env.sh
- hadoop@hadoop-master:/usr/local/hadoop$ sed -n "54p" ./etc/hadoop/hadoop-env.sh
- export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
7、首次启动Hadoop集群时,需要先在Master节点执行名称节点的格式化(只需要执行这一次,后面再启动Hadoop时,不要再次格式化名称节点),命令如下:
- hadoop@hadoop-master:/usr/local/hadoop/etc/hadoop$ cd /usr/local/hadoop/
- hadoop@hadoop-master:/usr/local/hadoop$ ./bin/hdfs namenode -format
8、现在就可以启动Hadoop了,启动需要在Master节点上进行,执行如下命令:
- hadoop@hadoop-master:/usr/local/hadoop$ ./sbin/start-dfs.sh
- hadoop@hadoop-master:/usr/local/hadoop$ ./sbin/start-yarn.sh
- hadoop@hadoop-master:/usr/local/hadoop$ ./sbin/mr-jobhistory-daemon.sh start historyserver
通过命令jps可以查看各个节点所启动的进程。如果已经正确启动,则在Master节点上可以看到NameNode、ResourceManager、SecondrryNameNode和JobHistoryServer进程,如下所示。
- hadoop@hadoop-master:/usr/local/hadoop$ jps
- 17728 JobHistoryServer
- 16992 NameNode
- 17399 ResourceManager
- 17213 SecondaryNameNode
- 17805 Jps
在Slave节点可以看到DataNode和NodeManager进程,如下所示。
- hadoop@hadoop-slave:/usr/local/hadoop$ jps
- 13738 NodeManager
- 13581 DataNode
- 13871 Jps
缺少任一进程都表示出错。另外还需要在Master节点上通过命令hdfs dfsadmin -report查看数据节点是否正常启动,如果屏幕信息中的“Live datanodes”不为 0 ,则说明集群启动成功。由于本教程只有1个Slave节点充当数据节点,因此,数据节点启动成功以后,会显示如下图所示信息。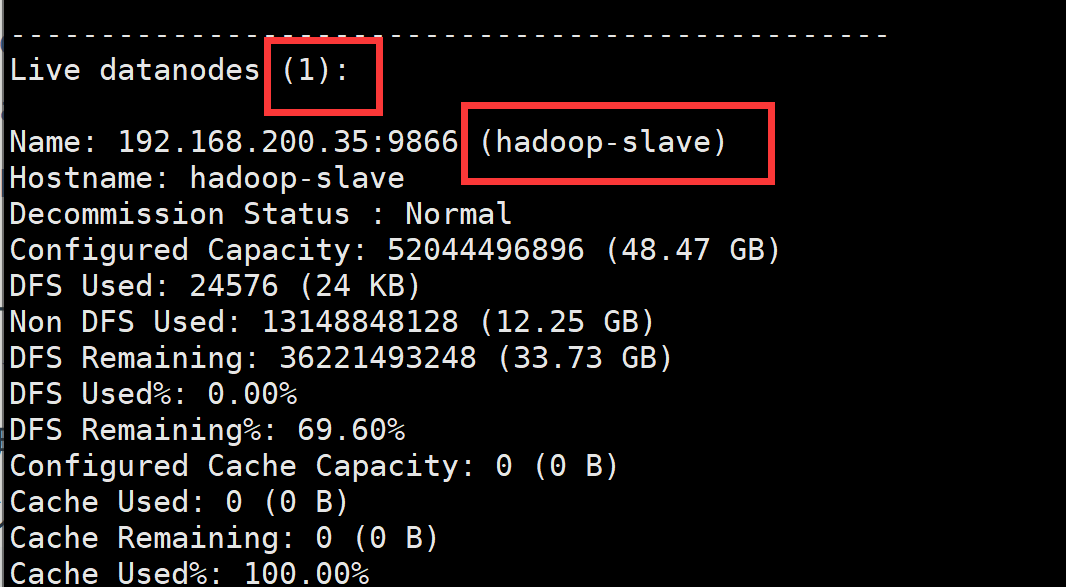
也可以在Linux系统的浏览器中输入地址“http://hadoop-master:9870/”,通过 Web 页面看到查看名称节点和数据节点的状态。如果不成功,可以通过启动日志排查原因。
这里再次强调,伪分布式模式和分布式模式切换时需要注意以下事项:
- 从分布式切换到伪分布式时,不要忘记修改slaves配置文件;
- 在两者之间切换时,若遇到无法正常启动的情况,可以删除所涉及节点的临时文件夹,这样虽然之前的数据会被删掉,但能保证集群正确启动。所以,如果集群以前能启动,但后来启动不了,特别是数据节点无法启动,不妨试着删除所有节点(包括Slave节点)上的
/usr/local/hadoop/tmp文件夹,再重新执行一次hdfs namenode -format,再次启动即可。
8、执行分布式实例
执行分布式实例过程与伪分布式模式一样,首先创建HDFS上的用户目录,命令如下:
hadoop@hadoop-master:/usr/local/hadoop$ hdfs dfs -mkdir -p /user/hadoop然后,在HDFS中创建一个input目录,并把/usr/local/hadoop/etc/hadoop目录中的配置文件作为输入文件复制到input目录中,命令如下:
- hadoop@hadoop-master:/usr/local/hadoop$ hdfs dfs -mkdir input
- hadoop@hadoop-master:/usr/local/hadoop$ hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
接着就可以运行 MapReduce 作业了,命令如下:
hadoop@hadoop-master:/usr/local/hadoop$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'运行时的输出信息与伪分布式类似,会显示MapReduce作业的进度,如下所示。
- ......
- 2022-04-14 19:38:09,651 INFO mapreduce.Job: Running job: job_1649936194163_0002
- 2022-04-14 19:38:19,778 INFO mapreduce.Job: Job job_1649936194163_0002 running in uber mode : false
- 2022-04-14 19:38:19,778 INFO mapreduce.Job: map 0% reduce 0%
- 2022-04-14 19:38:23,815 INFO mapreduce.Job: map 100% reduce 0%
- 2022-04-14 19:38:27,858 INFO mapreduce.Job: map 100% reduce 100%
- 2022-04-14 19:38:27,877 INFO mapreduce.Job: Job job_1649936194163_0002 completed successfully
- ......
执行过程可能会有点慢,但是,如果迟迟没有进度,比如5分钟都没看到进度变化,那么不妨重启Hadoop再次测试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改YARN的内存配置来解决。
在执行过程中,可以在Linux系统中打开浏览器,在地址栏输入“http://hadoop-master:8088/cluster”,通过Web界面查看任务进度,在Web界面点击 “Tracking UI” 这一列的History连接,可以看到任务的运行信息,如下图所示。
执行完毕后的输出结果如下所示。
- hadoop@hadoop-master:/usr/local/hadoop$ hdfs dfs -cat output/*
- 1 dfsadmin
- 1 dfs.replication
- 1 dfs.namenode.secondary.http
- 1 dfs.namenode.name.dir
- 1 dfs.datanode.data.dir
最后,关闭Hadoop集群,需要在Master节点执行如下命令:
- stop-yarn.sh
- stop-dfs.sh
- mr-jobhistory-daemon.sh stop historyserver
至此,就顺利完成了Hadoop集群搭建。

