
- 1全面梳理chatGPT常用提示词,看我这一篇就够了!(同样适用于国内大语言模型)_chat gpt提示词全部汇总
- 2Github为开发者打造的AI代码编写建议插件_github ai code插件
- 3用大数据“喂养”出来的AI模型ChatGPT 爆火是大数据、大算力、强算法的支撑,中国缺乏的什么?_数据喂养名词解释
- 4Resnet概述及代码_resunet代码
- 52024年人工智能顶级会议投稿信息汇总(数据挖掘领域)_sigmod.org
- 6Google BERT 中文应用之《红楼梦》中对话人物提取_bert 对话集
- 7成本2元开发游戏,最快3分钟完成!全程都是AI智能体“打工”,大模型加持的那种
- 8Linux 网络: 网卡速度异常案例(1)
- 9FastGPT:大模型应用的新里程碑_fastgpt 模型
- 10如何用python做一个小工具:文字转语音_python文字转语音界面版exe
解锁深度表格学习(Deep Tabular Learning)的关键:算术特征交互_表格数据的深度学习模型
赞
踩
近日,阿里云人工智能平台PAI与浙江大学吴健、应豪超老师团队合作论文《Arithmetic Feature Interaction is Necessary for Deep Tabular Learning》正式在国际人工智能顶会AAAI-2024上发表。本项工作聚焦于深度表格学习中的一个核心问题:在处理结构化表格数据(tabular data)时,深度模型是否拥有有效的归纳偏差(inductive bias)。我们提出算术特征交互(arithmetic feature interaction)对深度表格学习是至关重要的假设,并通过创建合成数据集以及设计实现一种支持上述交互的AMFormer架构(一种修改的Transformer架构)来验证这一假设。实验结果表明,AMFormer在合成数据集表现出显著更优的细粒度表格数据建模、训练样本效率和泛化能力,并在真实数据的对比上超过一众基准方法,成为深度表格学习新的SOTA(state-of-the-art)模型。
背景

图1:结构化表格数据示例,引用自[Borisov et al.]
结构化表格数据——这些数据往往以表(Table)的形式存储于数据库或数仓中——作为一种在金融、市场营销、医学科学和推荐系统等多个领域广泛使用的重要数据格式,其分析一直是机器学习研究的热点。表格数据(图1)通常同时包含数值型(numerical)特征和类目型(categorical)特征,并往往伴随有特征缺失、噪声、类别不平衡(class imblanance)等数据质量问题,且缺少时序性、局部性等有效的先验归纳偏差,极大地带来了分析上的挑战。传统的树集成模型(如,XGBoost、LightGBM、CatBoost)因在处理数据质量问题上的鲁棒性,依然是工业界实际建模的主流选择,但其效果很大程度依赖于特征工程产出的原始特征质量。
随着深度学习的流行,研究者试图引入深度学习端到端建模,从而减少在处理表格数据时对特征工程的依赖。相关的研究工作至少可以可以分成四大类:(1)在传统建模方法中叠加深度学习模块(通常是多层感知机MLP),如Wide&Deep、DeepFMs;(2)形状函数(shape function)采用深度学习建模的广义加性模型(generalized additive model),如 NAM、NBM、SIAN;(3)树结构启发的深度模型,如NODE、Net-DNF;(4)基于Transformer架构的模型,如AutoInt、DCAP、FT-Transformer。尽管如此,深度学习在表格数据上相比树模型的提升并不显著且持续,其有效性仍然存在疑问,表格数据因此被视为深度学习尚未征服的最后堡垒。
算术特征交互在深度表格学习的“必要性”
我们认为现有的深度表格学习方法效果不尽如人意的关键症结在于没有找到有效的建模归纳偏差,并进一步提出算术特征交互对深度表格学习是至关重要的假设。本节介绍我们通过创建一个合成数据集,并对比引入算数特征交互前后的模型效果,来验证该假设。
合成数据集的构造方法如下:我们设计了一个包含八个特征( )的合成数据集。
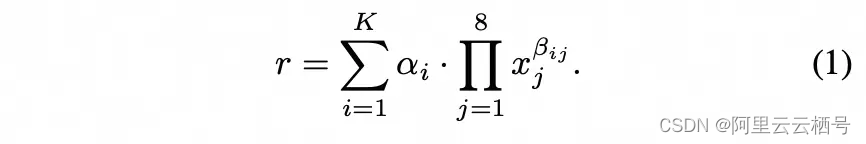


图2:合成数据集上的结果对比。图中+x%表示AMFormer相比Transformer的相对提升。
在上述数据中,我们将引入了算数特征交互的AMFormer架构与经典的XGBoost和Transformer架构对比。实验结果显示:

以上结果共同证实了算术特征交互在深度表格学习中的显著意义。
算法架构

图3:AMFormer架构,其中L表示模型层数。
本节介绍AMFormer架构(图3),并重点介绍算数特征交互的引入。AMFormer架构借鉴了经典的Transformer框架,并引入了Arithmetic Block来增强模型的算术特征交互能力。在AMFormer中,我们首先将原始特征转换为具有代表性的嵌入向量,对于数值特征,我们使用一个1输入d输出的线性层;对于类别特征,则使用一个d维的嵌入查询表。之后,这些初始嵌入通过L个顺序层进行处理,这些层增强了嵌入向量中的上下文和交互元素。每一层中的算术模块采用了并行的加法和乘法注意力机制,以刻意促进算术特征之间的交互。为了促进梯度流动和增强特征表示,我们保留了残差连接和前馈网络。最终,依据这些丰富的嵌入向量,AMFormer使用分类或回归头部生成最终输出。
算术模块的关键组件包括并行注意力机制和提示标记。为了补偿需要算术特征交互的特征,我们在AMFormer中配置了并行注意力机制,这些机制负责提取有意义的加法和乘法交互候选者。这些交互候选随着会沿着候选维度被串联(concatenate)起来,并通过一个下采样的线性层进行融合,使得AMFormer的每一层都能有效捕捉算术特征交互,即特征上的四则算法运算。为了防止由特征冗余引起的过拟合并提升模型在超大规模特征数据集上的伸缩,我们放弃了原始Transformer架构中平方复杂度的自注意力机制,而是使用两组提示向量(prompt token vectors)作为加法和乘法查询。这种方法为AMFormer提供了有限的特征交互自由度,并且作为一个附带效果,优化了内存占用和训练效率。
以上是AMFormer在架构层引入的主要创新,关于模型更详细的实现细节可以参考原文以及我们的开源实现。
进一步实验结果

表1:真实数据集统计以及评估指标。
为了进一步展示AMFormer的效果,我们挑选了四个真实数据集进行实验。被挑选数据集覆盖了二分类、多分类以及回归任务,数据集统计如表1所示。

表2:AMFormer以及基准方法的性能对比,其中括号内的数字表示该方法在当前数据集上表现的排名,最优以及次优的结果分别以加粗以及下划线突出。
我们一共测试了包含传统树模型(XGBoost)、树架构深度学习方法(NODE)、高阶特征交互(DCN-V2、DCAP)以及Transformer派生架构(AutoInt、FT-Trans)在内的六个基准算法以及两个AMFormer实现(分别选择AutoInt、FT-Trans做基础架构,即AMF-A和AMF-F),结果汇总在表2中。
在一系列对比实验中,AMFormer表现更突出。结果显示,基于MLP的深度学习方法如DCN-V2在表格数据上的性能不尽如人意,而基于Transformer架构的模型显示出更大的潜力,但未能始终超过树模型XGBoost。我们的AMFormer在四个不同的数据集上,与所有六个基准模型相比,表现一致更优:在分类任务中,它将AutoInt和FT-transformer的准确率或AUC提升至少0.5%,最高达到1.23%(EP)和4.96%(CO);在回归任务中,它也显著减少了平均平方误差。相比其它深度表格学习方法,AMFormer具有更好的鲁棒和稳定性,这使得在性能排序中AMFormer断层式优于其它基准算法,这些实验结果充分证明了AMFormer在深度表格学习中的必要性和优越性。
结论
本工作研究了深度模型在表格数据上的有效归纳偏置。我们提出,算术特征交互对于表格深度学习是必要的,并将这一理念融入Transformer架构中,创建了AMFormer。我们在合成数据和真实世界数据上验证了AMFormer的有效性。合成数据的结果展示了其在精细表格数据建模、训练数据效率以及泛化方面的优越能力。此外,对真实世界数据的广泛实验进一步确认了其一致的有效性。因此,我们相信AMFormer为深度表格学习设定了强有力的归纳偏置。
进一步阅读
● 论文标题:
Arithmetic Feature Interaction is Necessary for Deep Tabular Learning
● 论文作者:
程奕、胡仁君、应豪超、施兴、吴健、林伟
● 论文PDF链接:https://arxiv.org/abs/2402.02334
● 代码链接:https://github.com/aigc-apps/AMFormer
本文为阿里云原创内容,未经允许不得转载。

