
- 1ESP32 开发笔记(三)源码示例 7_WS2812_RMT 使用ESP32的RMT实现彩虹变色效果_mic 朋友w2812 esp32
- 2mysql大量查询导致锁表_mysql数据库大规模数据读写并行时导致的锁表问题
- 3Boostrap(五)组件_pootstrap组件
- 4库卡机器人编程语言di_清华打造首支中国风机器人乐队,最早的人形机器人在哪?机器编程...
- 55分钟读懂什么是虚拟数字人_数字人 ue
- 6kafka sasl_ssl配置
- 7iOS 常用第三方开源框架介绍_mgboxprovider
- 8C++-vector:判断vector中是否存在特定元素【std::find(v.begin(), v.end(), key)】_std::vector 查找元素
- 9bert-实体抽取
- 10硬件安全模块 (HSM)、硬件安全引擎 (HSE) 和安全硬件扩展 (SHE)的区别_se芯片与hsm模块的区别
论文解读《TimeSeAD: Benchmarking Deep Multivariate Time-Series Anomaly Detection》
赞
踩
文章摘要
背景:开发新的时间序列异常检测方法是非常重要的,但是新方法的效益难以评估,原因:
- 公共基准是有缺陷的(eg: 存在潜在的错误异常标签)
- 目前并没有一个被广泛接受的标准评估度量
- 评估协议大多不一致
工作:
- 批判性地分析了几个最广泛使用的多变量数据集,并选择了best candidate
- 引入了一种新的时间序列异常检测指标(advantage:召回率一致性 and 考虑了时间相关性)
- 分析了现有的现有的评估协议,并提供了目前为止深度多元时间序列异常检测方法的最大benchmark(专注于基于深度学习的方法和多源数据)
- 提供了TimeSeAD1(在一个新的时间序列异常检测综合库中提供了所有的实现和分析工具)
Introduction
- AD: anomaly detection异常检测
- AD的目的:自动识别对规范的重大偏差
- AD的两种方法:异常检测器逐点分配分数或者为全局分配分数
本文选择AD方法:逐点-可以容易地通过聚合本地标签来适应全局环境。同时有助于实施预测和异常定位。 - contribution:
- 对多变量时间序列AD最广泛使用的数据集、指标和评估协议进行了全面分析,揭示了存在的问题
- 创建了一个库,实现了28个基于深度学习的多变量时间序列AD方法
- 提出了一个评估指标。是可证明的召回一致性,从经验上提供了评测方法的合理排序
- 提出了非常大的多元时间序列AD综合基准,比较了21个数据集上的28种深度学习方法
伪进步
许多AD的评估是不可靠的
数据集的重大缺陷
- Anomaly density:异常在测试集中所占的比例
时间序列数据包含强烈的时间依赖性,类似于图像中的空间依赖性。
一个好的基准数据集:包含相似数量的样本,以方便深度模型的训练。应该包含足够的特征,以允许复杂的特征间依赖关系
问题
-
除了wadi之外,所有考虑的数据集都包含超过10%的异常,这可能已经太高,不能被认为是罕见的偏离标准
-
存在疑问?就是这种数据集为什么不行,认为挺接近现实的呀
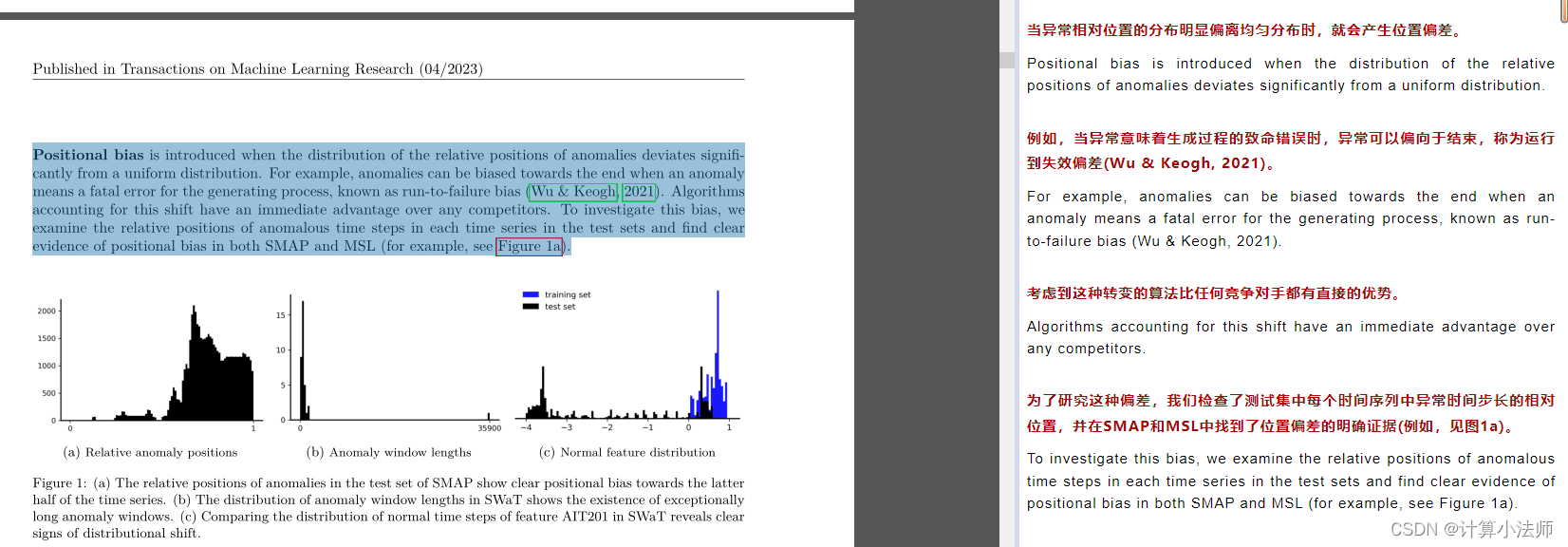
-
Long anomalies长异常会在评估中引入问题(有些方法根据窗口中的正常上下文来预测随后的异常),与适应的求值协议相互作用。
-
Constant features恒定特征出现在所有考虑的数据集中(一些数据集包含的特征在训练集和测试集之间保持不变)
-
Distributional shift分布转移:当生成正常训练和测试数据的底层过程不相同时,就会发生分布转移
(和师兄讨论:(A)这个图你一眼看到就感觉莫名其妙,他标签不标在出现下降的地方,标在一个水平线上换成谁来也看不出这里为啥是异常)
exist question :仅在标记异常之后才在传感器中显示的效果(例如,参见图2a)对于任何异常检测器来说都是不可能的问题。
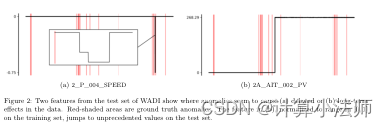
针对于数据集的分析:
- SWAT and WADI: 都存在明显的 long-anomalies。同时在测试集的后半段都发生了明显的变化
- SMAP and MSL: 数据内容:(one feature representing a sensor measurement, while the rest represent binary encoded commands)命令的特征通常是constant,特别是在发生异常的部分。
评估指标的缺陷(特别是f1分及其适用性)
异常检测器对时间序列中的每个时间步产生一个异常分数。在时刻t的分数越高,探测器就越有信心认为此时的点是异常点。然后通过这些分数的阈值来预测异常。给定预测和标签,评估度量根据它们的一致性产生一个分数。然后,不同的算法可以根据其预测产生的分数进行比较。
逐点度量的缺点,以及在评估度量中明确包含时间依赖性的现有尝试:
- Predictive patterns: 描述异常检测器的预测模式预测模式对于分离早期和晚期的预测,或者一致和分散的预测很重要,它们的差异应该反映在用于比较它们的度量中~
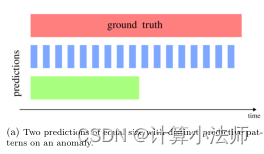
逐点度量的缺陷:很多度量忽略了predictive patterns的重要。只是用F1和recall作为度量
机器学习 召回率:true recognition / all true example
- Recall consistency:召回一致性是指逐点召回随着阈值的增加而单调降低。派生的metric 应该保持recall 以避免意外和unintuitive行为
- Implicit bias:隐形偏见是定义理想行为的任何评估指标的核心。因此每个指标都需要仔细设计,以避免意外地鼓励不必要的行为或引入相互冲突的目标。但是隐形偏见与基数递减函数的选择相冲突,后者鼓励相反的结果。
- Compensating flaws:补偿缺陷通常会在评估中引入进一步的、通常是微妙的偏见。在一个标记良好的数据集中,每个异常窗口都应该表明哪里是预期和可接受的警报。因此,这些问题不应该在度量中解决,而应该在数据集中解决。
目前存在的评价指标的问题:
- Soft-boundary metrics:软边界指标 eg: distance-based precision and recall and range-based volume under surface metrics。前者对异常窗口中心的正确预测引入了隐性偏见,并且对异常之前或之后的预测没有明确的区分,后者继承了对逐点方法的预测模式的缺陷。
- Early prediction metrics:早期预测指标~~~只考虑异常窗口中的第一次异常预测,通过忽略剩余的预测,这些指标不能区分预测模式,从而区分方法之间的细微差异。
- Time-series precision and recall:时间序列精度和召回率~~~解决了大多数逐点指标的问题,并提供了一组直观的可调参数。However, they suffer from recall inconsistency and conflicting implicit bias(读到这里感觉说了很多tspar的好处,这篇paper应该是基于rspar改进的metric)
评估协议的问题
evaluation protocol :包括如何进行实验的规范,包括数据集的预处理、特征消除和参数选择启发式。(结合之前的讨论,感觉师兄的paper将这部分做了一个规范,形成了一个范式)
- Point adjustment:点调整~~~任何具有至少一个正确预测时间步长的异常窗口都被认为是正确预测的。缺点:即使是随机方法也有很好的机会在较大的异常窗口中预测至少一个点,在那里它们可以很容易地达到大多数复杂方法的性能,甚至优于它们。
即使这个evaluation protocol非常的不合理,但是也被很多paper所采用。 - 很多论文并没有公开详细的信息来复现,一些作品没有足够详细地指定它们的求值协议、超参数和体系结构来重现它们的结果,也没有发布包含它们的任何源代码。
- 有的paper报告了由来自不同分布的样本组成的数据集上的汇总指标,或在多个数据集上进行汇总,但是如果没有对如何计算汇总值的明确定义或其他分析,这些评估通常缺乏清晰度、可比性和可再现性。
TimeSeAD: Benchmarking Deep Multivariate Time-Series AD(为了解决以上的问题,本文做的工作)
新的数据集
新的metric(果然,改进的time-series precision and recall)

- 为T Rec和T P Rec的一个变体提出了新的默认参数来解决它们的缺陷.
令α = 0
原因:第一项计算至少有一个点被正确预测的异常窗口的数量。相比之下,第二项完全与每个异常窗口内的预测结构有关。由于第一项完全忽略了异常的大小,因此两个项的范围在不同的任务之间可能会有很大的差异,并且需要为每个任务单独平衡这两个项。此外,第二项已经含蓄地承认在它们的重叠中存在异常现象

- 使用常数偏差(可调)作为偏置函数
原因:当偏置为常数时,基数函数具有闭型解

3. 在TPrec中使用 代替相等的权值|P|-1
代替相等的权值|P|-1
原因:可以通过消除对总精度的全局影响来惩罚碎片化的预测
例如,LSTM-P产生的分数在异常窗口内波动,并在异常窗口的末尾甚至外部出现尖峰,可能导致碎片化的预测,而TCN-AE产生的分数在异常窗口的持续时间内平稳地增加和减少,导致连续的预测,并在终端故障时出现尖峰
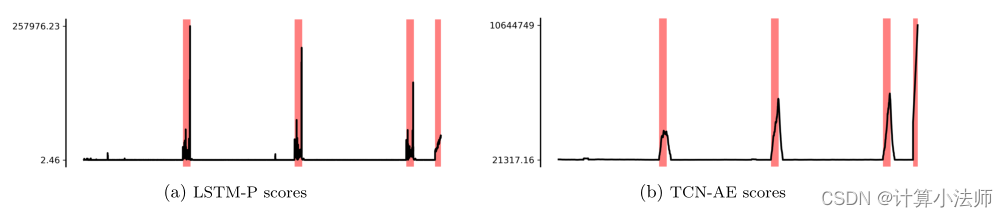

使用新的加权,而不是等权值

