
- 1AI撰稿革新文案创作,解锁高效智能写作新时代
- 2两万字大章带你使用 Vue3、Vite、TypeScript、Less、Pinia、Naive-ui 开发 Chrome 浏览器 Manifest V3 版本插件_vite chrome插件开发
- 3【吐血整理】强烈推荐 GitHub 上值得学习的开源实战项目(持续更新中,万字长文建议收藏)_github上面免费的java开源项目
- 4Ubuntu关闭防火墙、关闭selinux、关闭swap
- 5fast-lio运行步骤(使用velodyne数据)_fastlio安装和启动
- 6github下载的常用操作_github下载代码
- 7AndroidStudio Gradle下载速度慢甚至出现超时timeout报错解决方法_download gradle-6.3-all timeout
- 8做ROS小车实物的第一天_用ros做一个实物出来要多久
- 9【SpringCloud-7】常见问题解析_ribbon 缓存
- 10FPGA秋招-笔记整理(3)
ChatGPT3.5 和 4.0真的使用差别很大嘛?有必要去升级Plus嘛?_chatgpt有必要4.0吗
赞
踩
在本文介绍的所有测试中,ChatGPT都明显弱于GPT-4。(如果想快速一键升级Chatgpt4.0直接拉到文章末端)
1. 微软的测试结果
这部分测试结果来自于微软针对GPT-4的研究论文《Sparks of Artificial General Intelligence: Early experiments with GPT-4 》。这篇论文测的是GPT-4的一个早期版本,它在训练阶段仍只用了文本数据,没有图像。所以从训练数据的类型来看,它和ChatGPT是一致的。
1.1 视觉能力
GPT-4的一个强大能力是它从纯文本中产生了视觉概念,但ChatGPT没有这种能力。
第一个测试方法是让模型用SVG(一种简易的图像格式)生成“汽车”、“卡车”、“猫”和“狗”。GPT-4和ChatGPT生成的图像如图1和图2所示。
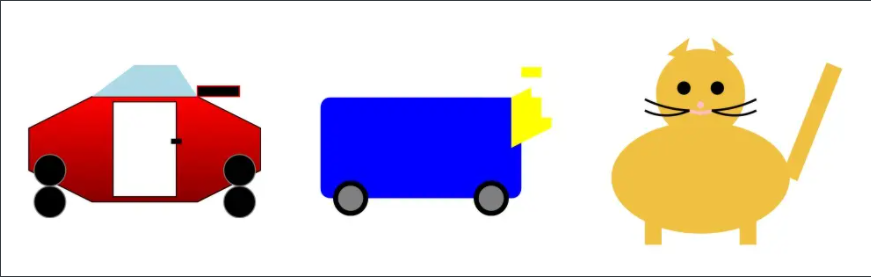
GPT-4生成的汽车、卡车、猫和狗
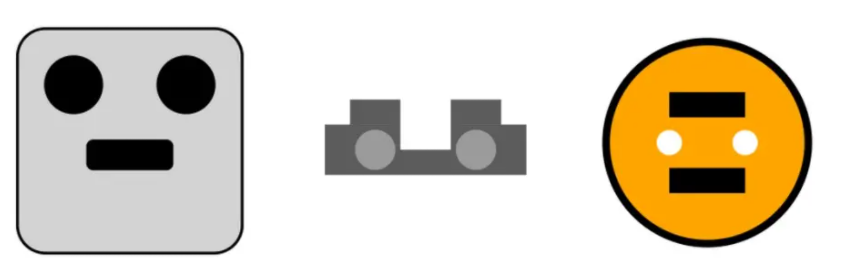
ChatGPT生成的汽车、卡车、猫和狗
要注意,GPT-4和ChatGPT在训练中都没有使用图像。但GPT-4能够较为准确地理解了一些基础图像的概念,而ChatGPT完全不行。
第二个测试方法是让模型用英文字母来画火柴人:用字母O作为头,用Y作为身体和手臂,用H作为腿。
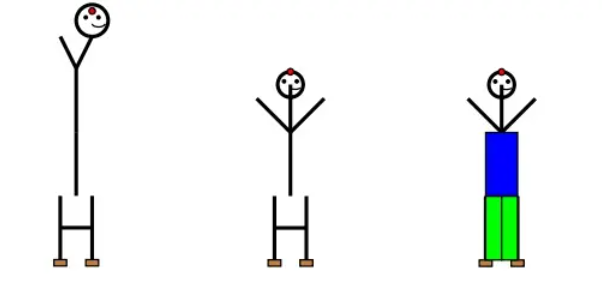
图中 GPT-4用字母画火柴人。左图:让GPT-4用字母O作为头,用Y作为身体和手臂,用H作为腿画出的火柴人;中图:告诉GPT-4身子太长了,头太歪了后,GPT-4做出的调整;右图:让GPT-4画上衣服和裤子。
GPT-4画出来的火柴人如图3中最左侧图所示。当告诉GPT-4身子太长了后,GPT-4对火柴人进行调整后的图如图4中图所示。这个新的火柴人基本正确。最后让GPT-4对火柴人加上衣服和裤子,如图4中右图所示。
而ChatGPT画出来的火柴人是这样:
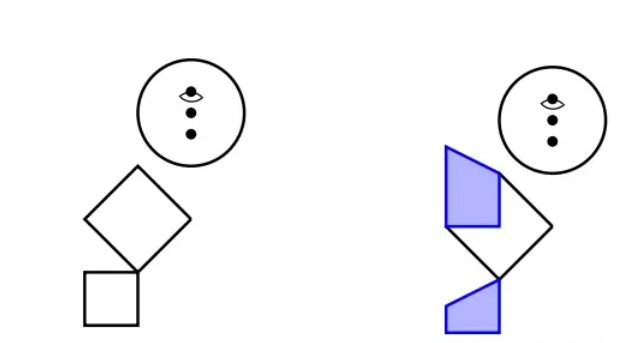
图中 ChatGPT用字母画火柴人。左图:让ChatGPT用字母O作为头,用Y作为身体和手臂,用H作为腿画出的火柴人;右图:让ChatGPT画上衣服和裤子
显而易见,ChatGPT对图像基本没有概念。
1.2 代码能力
论文中有很多复杂的例子,比如让GPT-4按照文字描述写一个PyTorch的优化器;让GPT-4对一段代码进行单步运行;让GPT-4对一段伪代码进行单步运行并分析等等。在所有这些测试中,GPT-4都明显优于ChatGPT。这里挑一个简单一点的示例,代码也比较短,如下图所示。
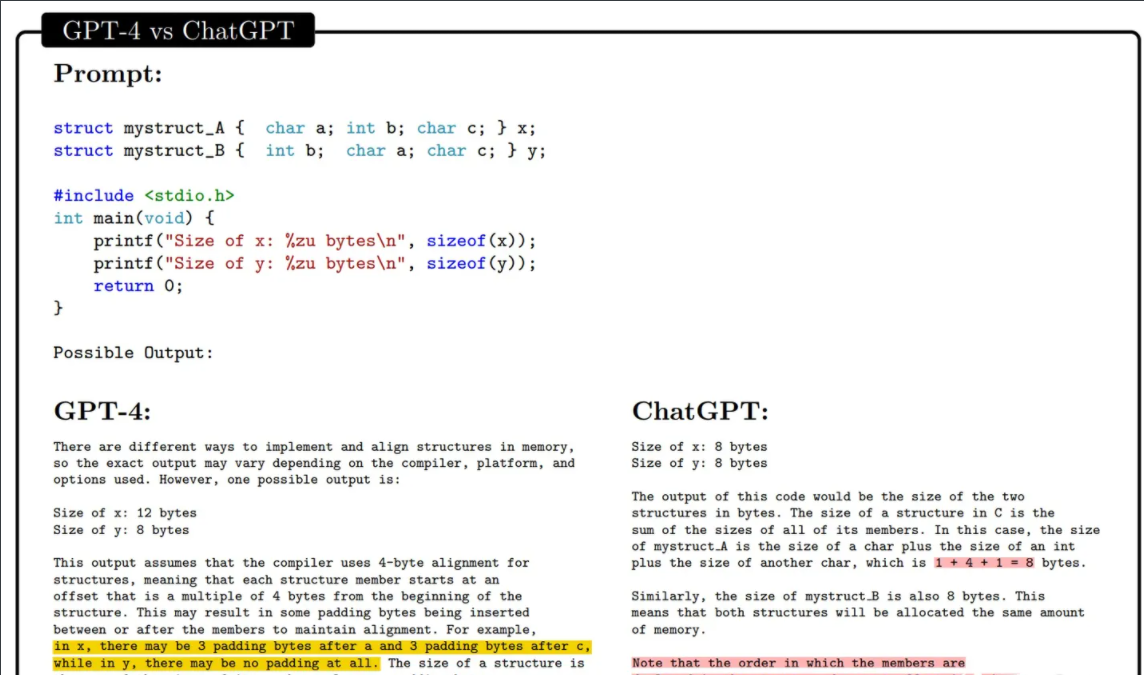
图中 给定两个结构体,让GPT-4和ChatGPT分析它们的内存占用量。图中黄色区域为非常深刻的分析;红色区域为错误分析。
结构体x和结构体y的成员变量相同,但它们的顺序不同。GPT-4准确地知道结构体占用内存量与对齐规则有关,并给出了一个具体地示例。该示例假设以4-byte进行对齐。那么对于结构体x,它的第一个char a虽然只占1-byte,但因为int b需要对齐地址,所以char a实际占用了4-byte。同理,虽然char c也只占用1-byte,但因结构体的大小必须为4的倍数,所以char c也要占4-byte。
对于结构体y,int b占4-byte,char a占1-byte(因为char a的开销为1-byte,小于对齐的4-byte,所以按1-byte对齐即可),char b占1-byte,总共6-byte。但因结构体大小必须为4的倍数,所以总开销为8-byte。
而ChatGPT显然在胡说八道。
1.3 数学计算能力
先看一道应用题,原文如下:

题目大致如下。有一群兔子,在每年年初时,它们的数量为变为原来的a倍。在每年年底时,这群兔子中有b只兔子会被抓走。假设最开始有x只兔子,三年后兔子总数时27x - 26,求a和b。
GPT-4和ChatGPT的解答分别如下:


GPT-4和ChatGPT对“兔子问题”的解答
很容易看到,GPT-4答的非常好。而ChatGPT基本没理解到题目的意思。
1.4 工具使用能力
不论是GPT-4还是ChatGPT,它们的缺陷都非常明显:
-
无法获取及时信息;
-
数值计算容易出错;
-
一些简单且偏常识类的任务容易出错。
论文作者们通过一个例子来说明了GPT-4和ChatGPT存在的上述2个明显问题,如下图所示。

图9 GPT-4和ChatGPT均出错的2个简单示例
第一个问题关于及时信息:美国现在总统是谁?
GPT-4的回答明显错误(特朗普),而ChatGPT表现地更合理,直接回答说它的知识只到2021年。
第二个问题关于数值计算:34324 * 2432的平方根。
正确答案是9136.51。GPT-4和ChatGPT都错的离谱。
2. OpenAI的测试结果
这一部分结果来自OpenAI的GPT-4论文。
第一个测试是人类参与的专业考试,测试结果如下图所示。
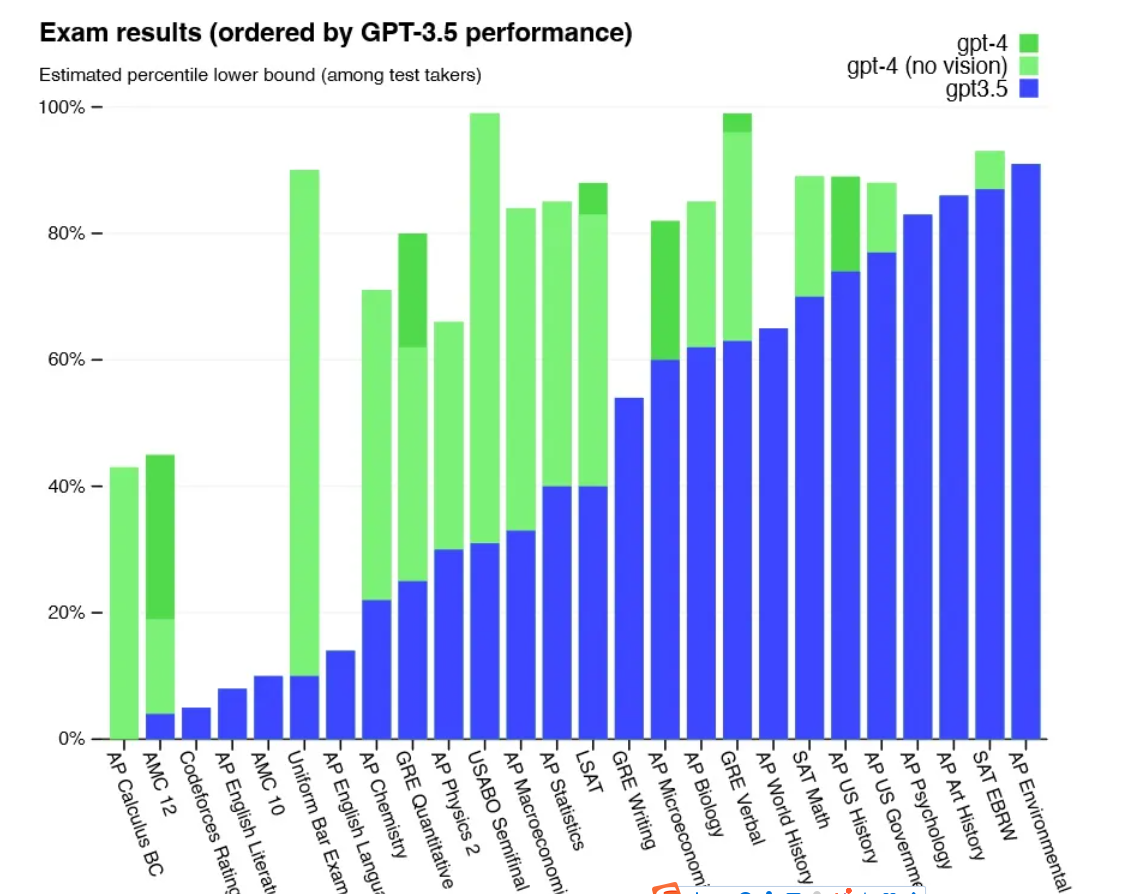
人类专业考试测试
图中的柱状表示百分位数。比如,第六列的Uniform Bar Exam(律师资格考试),ChatGPT(GPT3.5)大概是垫底的10%(蓝色柱子),而GPT-4是最高的10%(绿色柱子)。图中浅绿色表示没有视觉能力的GPT-4(没有用图像数据训练),深绿色表示有视觉能力的GPT-4。
第二个测试结果是传统的“刷榜”:在一些标准的数据集上测试GPT-4的能力。结果如下。
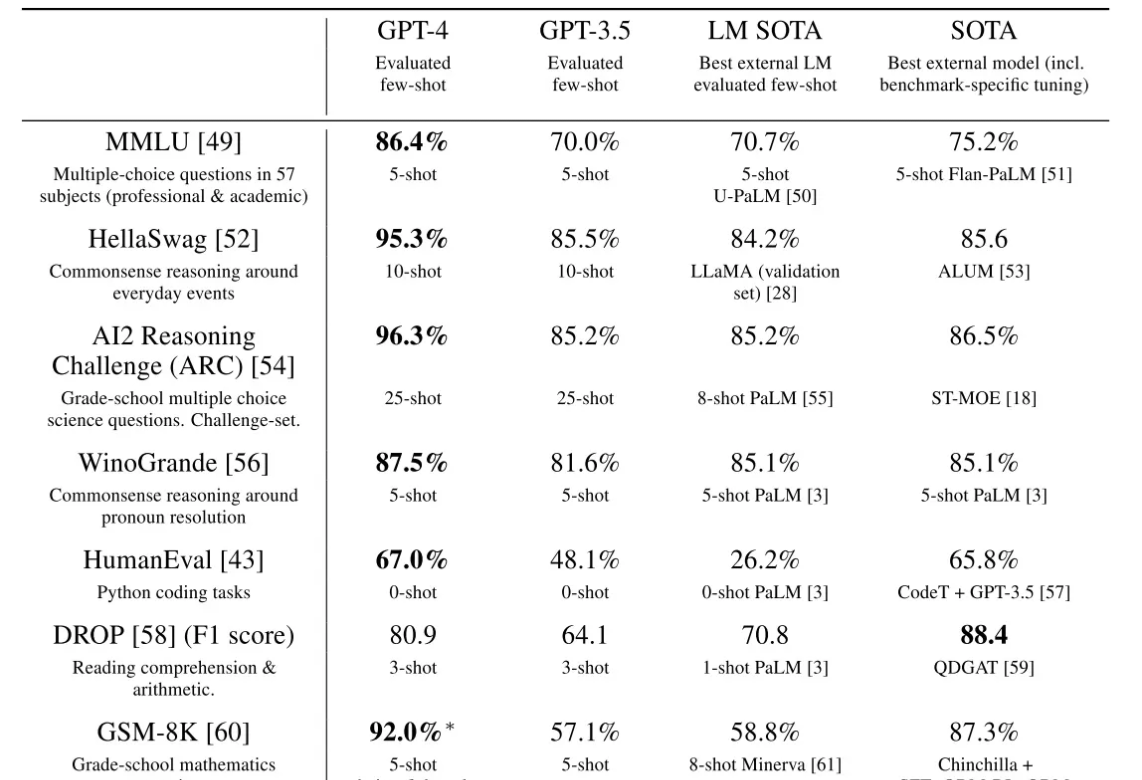
图14 GPT-4和ChatGPT的刷榜表现
最左侧是数据集和任务的描述。结果的第一列和第二列分别是GPT-4和ChatGPT(GPT3.5)的结果。非常明显,GPT-4的能力强太多。
3. 测试用例
这部分列举两个自己写的测试用例,这些用例涉及的场景GPT可能会比现有方法更优。
3.1 推荐
GPT对场景、上下文的理解非常深刻,因此想到的第一个场景就是让它代替推荐算法来做推荐。当然推荐本身的范畴非常大,这里以商品为例,测一下GPT对场景的理解能力。
用例设计:小明购买了新房,所以他在过去一段时间里购买了很多居家用品。测试GPT能否推测出小明当前的生活状态(即将入住新家或准备搬家)。
ChatGPT的结果如下:

ChatGPT4.0的结果如下:

GPT-4显然对场景的理解更加深刻。但它仍然过于强调了3月8日这一天的鲜花(更可能是妇女节送花)。
虽然还不完美,但GPT-4一定会使现有的推荐算法、模式(电商、短视频等等)发生巨大变化。
3.2 实体抽取
实体抽取指从文本中抽取人名、地址、机构名等等使用者感兴趣的内容。实体抽取是NLP领域一项非常基础且重要的任务,具有广泛的实际用途。
下面是从今日头条上随便贴了一段新闻(侵删):
大家都知道,美国之所以能肆意收割世界财富,最主要的原因就是其拥有美元、军事和科技三大霸权。这些霸权让美国在全球范围内拥有巨大的影响力,也让其成为了国际舞台上的主角。不可否认,手握三大霸权的美国确实会让很多国家和地区甘愿臣服。但同时也会有个别国家会做出反抗,就比如俄罗斯和中国。尤其是中国,在经历了改革开放的大浪淘沙之后,近几年来我国在科技领域迎来了新一轮的爆发。无论是在航空航天方面,还是在5G通讯、人工智能等方面,我国都处于领先地位。与此同时,我国还涌现出了一大批高科技企业,比如华为、大疆、龙芯中科、长江存储等。其中华为在5G通讯领域的强势崛起,动摇了美“科技霸权”的根基。为了继续收割世界财富,美国对华为等中企进行了毫无底线的制裁,可结果却得不偿失,我们的企业非但没有倒下,反而越战越勇,打赢了一场又一场漂亮的“攻坚战”。反观美国半导体市场可谓是一片狼藉,可以说到处都是“断壁残垣”。高通、苹果、AMD等美科技企业不是面临市值腰斩,就是面临利润和营收双双下滑,甚至还开启了上万规模的裁员浪潮。
我的输入是这样:

实体识别能力测试
ChatGPT的输出:
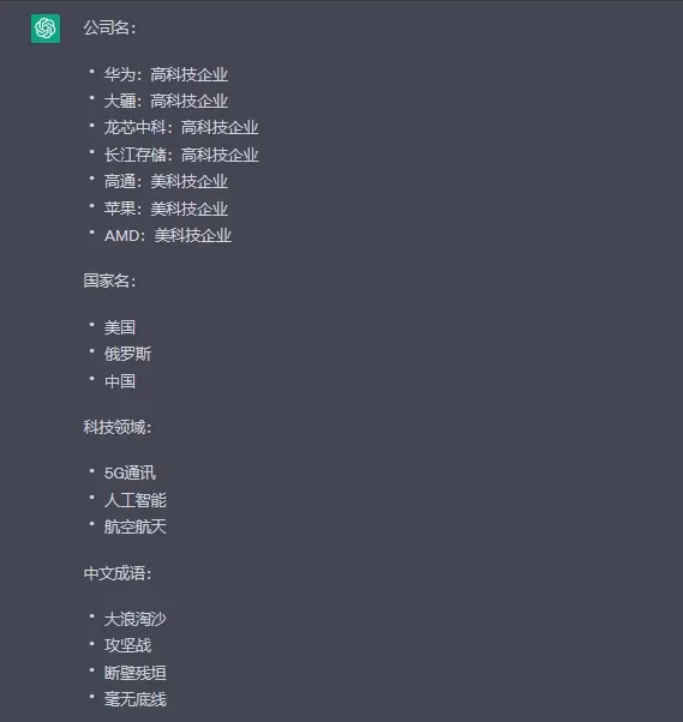
ChatGP没有理解到我希望的输出格式。并且成语这一部分不太理想。
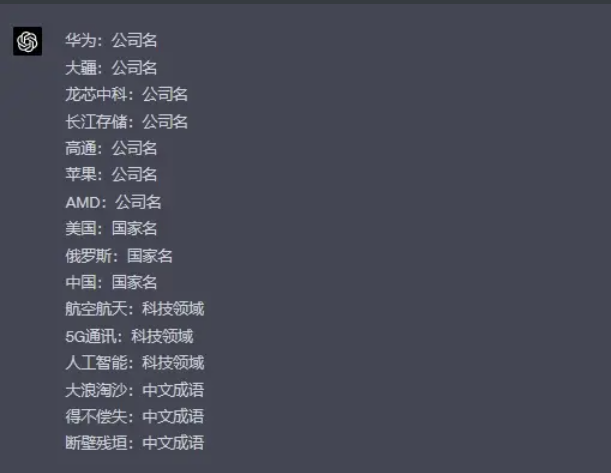
实体识别GPT-4的输出
GPT-4完全理解输出格式,并且回答的比较好。(注:如果在输入中把“包括国外公司”去掉,GPT-4会漏掉高通、苹果和AMD,但ChatGPT没有这个问题)
最后
光是在推荐和实体抽取这两类任务上的优异表现,就可以设计出很多GPT-4可用的场景。好了,如果大家想自己试下ChatGPT4.0的效果可以看下这篇文章:
相关文章:

