
热门标签
热门文章
- 1布隆过滤器(一)——布隆过滤器的原理和理解_java实现布隆过滤器,并且如何减少哈希碰撞的概率
- 2IDEA连接MySql数据库_java 链接 mysql 3307 的端口
- 3[算法前沿]--026-如何实现一个BERT_bert模型代码 jupyter
- 4gogs组织中的仓库提交代码没用_如何在Github上提交第二个PR?
- 5【Linux】1w详解如何实现一个简单的shell
- 6微阵列数据分析(Microarray Data Analysis)
- 7异常检测之IF孤立森林实战_python 基于树的异常点检测
- 8【Python】解决Python报错:KeyError: ‘xxx‘_keyerror怎么处理
- 9IDEA 超全优化设置,效率杠杠的!_idea tab设置
- 10如何从小米手机传输文件到电脑? [5个简单的方法]_小米文件传输电脑
当前位置: article > 正文
使用Python selenium爬虫领英数据,并进行AI岗位数据挖掘_requests领英爬虫
作者:你好赵伟 | 2024-07-22 15:05:14
赞
踩
requests领英爬虫
随着OpenAI大火,从事AI开发的人趋之若鹜,这次使用Python selenium抓取了领英上几万条岗位薪资数据,并使用Pandas、matplotlib、seaborn等库进行可视化探索分析。
但领英设置了一些反爬措施,对IP进行限制封禁,因此会用到IP代理,用不同的IP进行访问,我这里用的是亮数据的IP代理。
亮数据是一家提供网络数据采集解决方案的网站,它拥有全球最大的代理IP网络,覆盖超过195个国家和地区,拥有超过7200万个不重复的真人IP地址。
这些IP地址可以用于匿名浏览网页、绕过IP封锁、抓取网页数据等。
亮数据官网地址:
https://get.brightdata.com/weijun
另外,亮数据提供各种数据采集工具,帮助企业轻松采集网页数据。这些工具包括Web Scraper IDE、亮数据浏览器、SERP API等等。
下面是关于Python爬取领英的步骤和代码。
- 1、爬虫采集AI岗位数据-selenium&亮数据
- 2、处理和清洗数据-pandas
- 3、可视化数据探索-matplotlib seaborn
1、爬虫采集AI岗位数据-selenium&亮数据
# 导入相关库 import random from selenium import webdriver from selenium.webdriver.common.by import By import time import requests import pandas as pd from scripts.helpers import strip_val, get_value_by_path # 选择Edge浏览器 BROWSER = 'edge' # 创建网络会话,登录Linkedin # create_session函数用于创建一个自动化的浏览器会话,并使用提供的电子邮件和密码登录LinkedIn。 # 它首先根据BROWSER变量选择相应的浏览器驱动程序(Chrome或Edge),然后导航到LinkedIn的登录页面,自动填写登录表单,并提交。 # 登录成功后,它会获取当前会话的cookies,并创建一个requests.Session对象来保存这些cookies,以便后续的HTTP请求可以保持登录状态。最后,它返回这个会话对象。 def create_session(email, password): if BROWSER == 'chrome': driver = webdriver.Chrome() elif BROWSER == 'edge': driver = webdriver.Edge() # 登录信息 driver.get('https://www.linkedin.com/checkpoint/rm/sign-in-another-account') time.sleep(1) driver.find_element(By.ID, 'username').send_keys(email) driver.find_element(By.ID, 'password').send_keys(password) driver.find_element(By.XPATH, '//*[@id="organic-div"]/form/div[3]/button').click() time.sleep(1) input('Press ENTER after a successful login for "{}": '.format(email)) driver.get('https://www.linkedin.com/jobs/search/?') time.sleep(1) cookies = driver.get_cookies() driver.quit() session = requests.Session() for cookie in cookies: session.cookies.set(cookie['name'], cookie['value']) return session # 获取登录账号和密码 def get_logins(method): logins = pd.read_csv('logins.csv') logins = logins[logins['method'] == method] emails = logins['emails'].tolist() passwords = logins['passwords'].tolist() return emails, passwords # JobSearchRetriever类用于检索LinkedIn上的职位信息。 # 它初始化时设置了一个职位搜索链接,并获取登录凭证来创建多个会话。 # 它还定义了一个get_jobs方法,该方法通过会话发送HTTP GET请求到LinkedIn的职位搜索API,获取职位信息,并解析响应以提取职位ID和标题。 # 如果职位被标记为赞助(即广告),它也会记录下来。 class JobSearchRetriever: def __init__(self): self.job_search_link = 'https://www.linkedin.com/voyager/api/voyagerJobsDashJobCards?decorationId=com.linkedin.voyager.dash.deco.jobs.search.JobSearchCardsCollection-187&count=100&q=jobSearch&query=(origin:JOB_SEARCH_PAGE_OTHER_ENTRY,selectedFilters:(sortBy:List(DD)),spellCorrectionEnabled:true)&start=0' emails, passwords = get_logins('search') self.sessions = [create_session(email, password) for email, password in zip(emails, passwords)] self.session_index = 0 self.headers = [{ 'Authority': 'www.linkedin.com', 'Method': 'GET', 'Path': 'voyager/api/voyagerJobsDashJobCards?decorationId=com.linkedin.voyager.dash.deco.jobs.search.JobSearchCardsCollection-187&count=25&q=jobSearch&query=(origin:JOB_SEARCH_PAGE_OTHER_ENTRY,selectedFilters:(sortBy:List(DD)),spellCorrectionEnabled:true)&start=0', 'Scheme': 'https', 'Accept': 'application/vnd.linkedin.normalized+json+2.1', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'en-US,en;q=0.9', 'Cookie': "; ".join([f"{key}={value}" for key, value in session.cookies.items()]), 'Csrf-Token': session.cookies.get('JSESSIONID').strip('"'), # 'TE': 'Trailers', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36', # 'X-Li-Track': '{"clientVersion":"1.12.7990","mpVersion":"1.12.7990","osName":"web","timezoneOffset":-7,"timezone":"America/Los_Angeles","deviceFormFactor":"DESKTOP","mpName":"voyager-web","displayDensity":1,"displayWidth":1920,"displayHeight":1080}' 'X-Li-Track': '{"clientVersion":"1.13.5589","mpVersion":"1.13.5589","osName":"web","timezoneOffset":-7,"timezone":"America/Los_Angeles","deviceFormFactor":"DESKTOP","mpName":"voyager-web","displayDensity":1,"displayWidth":360,"displayHeight":800}' } for session in self.sessions] # self.proxies = [{'http': f'http://{proxy}', 'https': f'http://{proxy}'} for proxy in []] # 添加亮数据代理IP # get_jobs函数用于发送HTTP请求到LinkedIn的职位搜索API,获取职位信息 # 它使用当前会话索引来选择一个会话,并发送带有相应请求头的GET请求。如果响应状态码是200(表示请求成功) # 它将解析JSON响应,提取职位ID、标题和赞助状态,并将这些信息存储在一个字典中。 def get_jobs(self): results = self.sessions[self.session_index].get(self.job_search_link, headers=self.headers[self.session_index]) #, proxies=self.proxies[self.session_index], timeout=5) self.session_index = (self.session_index + 1) % len(self.sessions) if results.status_code != 200: raise Exception('Status code {} for search\nText: {}'.format(results.status_code, results.text)) results = results.json() job_ids = {} for r in results['included']: if r['$type'] == 'com.linkedin.voyager.dash.jobs.JobPostingCard' and 'referenceId' in r: job_id = int(strip_val(r['jobPostingUrn'], 1)) job_ids[job_id] = {'sponsored': False} job_ids[job_id]['title'] = r.get('jobPostingTitle') for x in r['footerItems']: if x.get('type') == 'PROMOTED': job_ids[job_id]['sponsored'] = True break return job_ids

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
2、处理和清洗数据-pandas
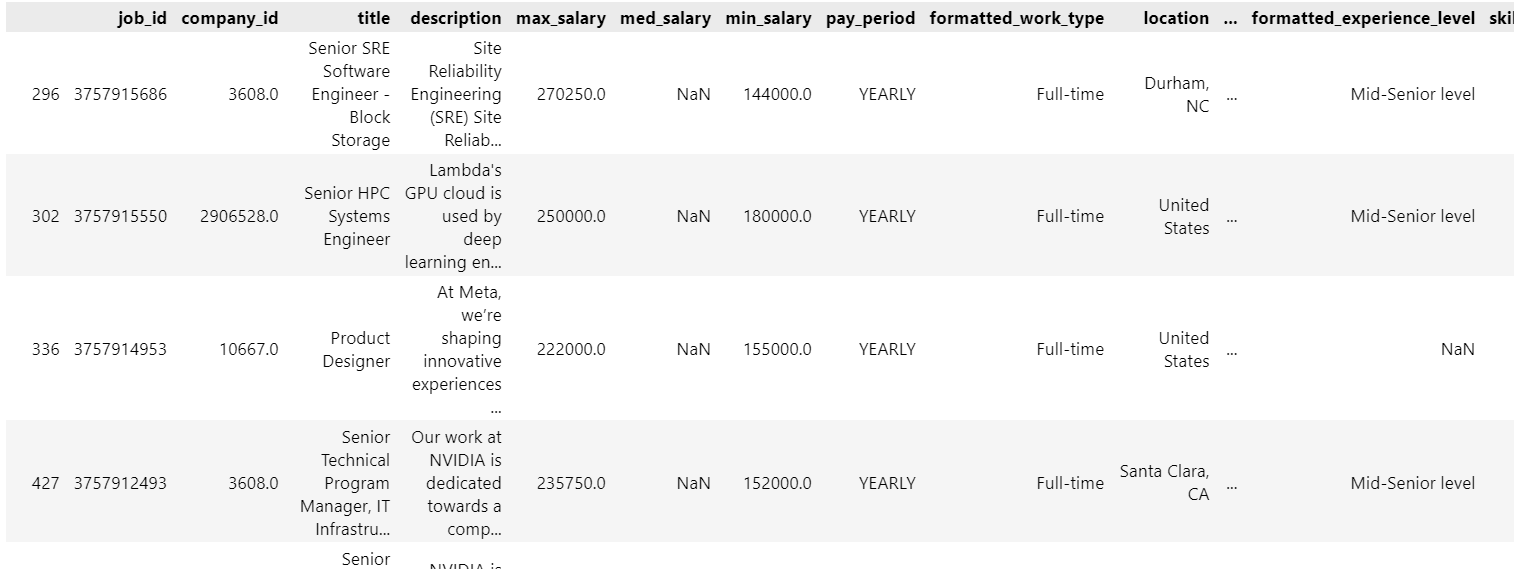
# 导入相关库 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from wordcloud import WordCloud # 导入职位数据 job_postings = pd.read_csv('./archive/job_postings.csv') job_postings # 根据AI岗位关键词筛选AI相关岗位 keywords = ['data scientist', 'machine learning', 'data science', 'data analyst', 'ml engineer',' data engineer','ai engineer','ai/ml','ai/nlp','ai reasearcher','ai consultant','artificial intelligence','computer vision','deep learning'] # 新增一列,标注职位是否包含关键字 def check_keywords(description): for keyword in keywords: if keyword in str(description).lower(): return 'AI岗位' return '非AI岗位' job_postings['is_programmer'] = job_postings['description'].apply(check_keywords) # 保存AI岗位新表 job_ai = job_postings[(job_postings['is_programmer']=='AI岗位') & (job_postings['pay_period']=='YEARLY') & (job_postings['max_salary']>10000) ] job_others = job_postings[(job_postings['is_programmer']=='非AI岗位') & (job_postings['pay_period']=='YEARLY') & (job_postings['max_salary']>10000) & (job_postings['max_salary']<200000) ] job_ai
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
处理好的数据如下:
3、可视化数据探索-matplotlib seaborn
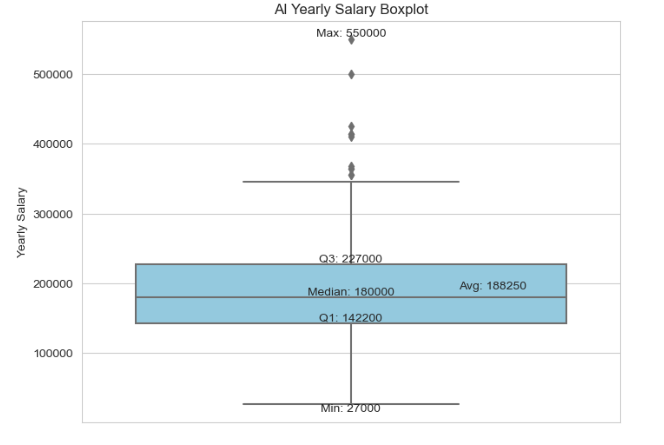
AI岗位中位数年薪18W美金,最高50w以上
# 设置Seaborn样式和调色板 sns.set_style("whitegrid") palette = ["skyblue"] # palette = ["#87CEEB"] # 使用颜色代码或者其他有效的颜色名称,这里使用天蓝色的颜色代码 # 箱线图 plt.figure(figsize=(8, 6)) sns.boxplot(y='max_salary', data=job_ai, palette=palette) plt.ylabel('Yearly Salary') plt.title('AI Yearly Salary Boxplot') # 添加分位数标注 quantiles = job_ai['max_salary'].quantile([0.25, 0.5, 0.75]) for q, label in zip(quantiles, ['Q1', 'Median', 'Q3']): plt.text(0, q, f'{label}: {int(q)}', horizontalalignment='center', verticalalignment='bottom', fontdict={'size': 10}) # 添加平均值、最大最小值标注 avg_value = job_ai['max_salary'].mean() max_value = job_ai['max_salary'].max() min_value = job_ai['max_salary'].min() plt.text(0.2, avg_value, f'Avg: {int(avg_value)}', ha='left', va='bottom', fontdict={'size': 10}) plt.text(0, max_value, f'Max: {int(max_value)}', ha='center', va='bottom', fontdict={'size': 10}) plt.text(0, min_value, f'Min: {int(min_value)}', ha='center', va='top', fontdict={'size': 10}) # 显示图形 plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
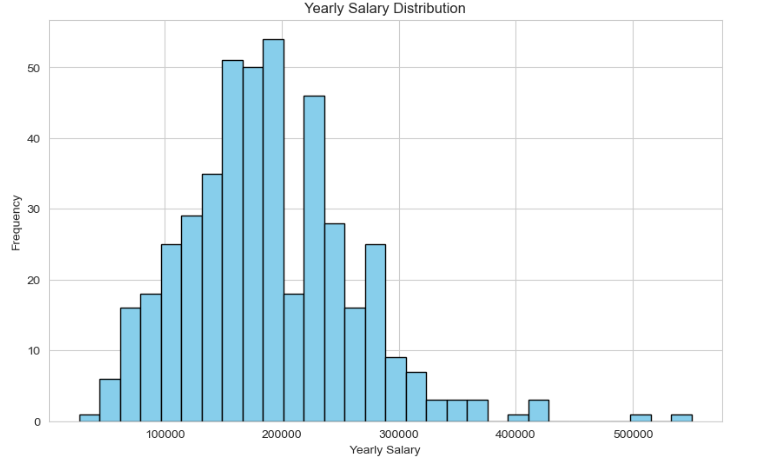
AI岗位年薪主要集中在15-30w美金
# 1. 直方图
plt.figure(figsize=(10, 6))
plt.hist(job_ai['max_salary'], bins=30, color='skyblue', edgecolor='black')
plt.xlabel('Yearly Salary')
plt.ylabel('Frequency')
plt.title('Yearly Salary Distribution')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
AI大多需要高级岗,对软件开发、机器学习、数据科学要求较多
# 词云
stopwords = set(["Manager"])
job_titles_text = ' '.join(job_ai['title'])
wordcloud = WordCloud(width=800, height=400, background_color='white',stopwords=stopwords).generate(job_titles_text)
# 显示词云
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.title('AI Job Title Word Cloud')
plt.axis('off')
plt.tight_layout()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

数据发现,AI岗位平均年薪竟高达18万美金,远超普通开发岗,而且AI岗位需求也在爆发性增长。
这次使用的是亮数据IP服务,质量还是蛮高的,大家可以试试。
亮数据官网地址:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/865723
推荐阅读
相关标签

