
- 1基于tensorflow的校园绿植识别_基于tensorflow的植物识别
- 2简单总结一下计算机科学(CS)的课程体系_cs 学科体系
- 3Android 进程与进程之间的通信--Messager 详细教程,两个app实现_android messager
- 4Postgresql总结几种HA的部署方式_postgresql ha
- 5宋江是怎么当上老大的
- 6【unity】动画状态机中Transition的settings两段动画如何设置?
- 7阿尔法python练习(4-7答案)_阿尔法平台考试
- 8Linux下SVN的三种备份方式_linux svn 备份
- 9Elasticsearch:在 Elastic Stack 8.0 中引入近似最近邻搜索_elasticsearch ann
- 10ATF源码篇(一):起始_atf代码
生成式人工智能(generative AI)对公共部门的影响_generative artificial intelligence
赞
踩
在过去的几个月里,我们看到了对生成式人工智能 (generative artificial intelligence - GAI) 的极大兴趣。 人们正在试用 ChatGPT 等 GAI 应用程序,企业正在思考它对客户体验、会计、营销等方面的影响。 鉴于技术发展的速度有多快,现在很难判断什么是推测性的,什么是实际可实施的和有价值的。
我们现在正处于政府领导人应该认真考虑如何准备内部数据以从 GAI 中获得最大价值的地步,以及如何使用 GAI 来促进更好的公民和员工体验。
GAI 本身的好坏取决于它所训练的数据
在目前的状态下,GAI 可以产生令人印象深刻的内容、对话、图像等。 但这些结果仅与该工具接受过训练的数据一样相关。 当训练数据集 —— 提供大型语言模型 (LLM) 中知识的表象 —— 基于互联网上公开可用的数据时,它们生成的答案范围有限。 基于公共数据的 GAI 往往容易产生幻觉 —— 将不正确的信息当作准确的信息来呈现。
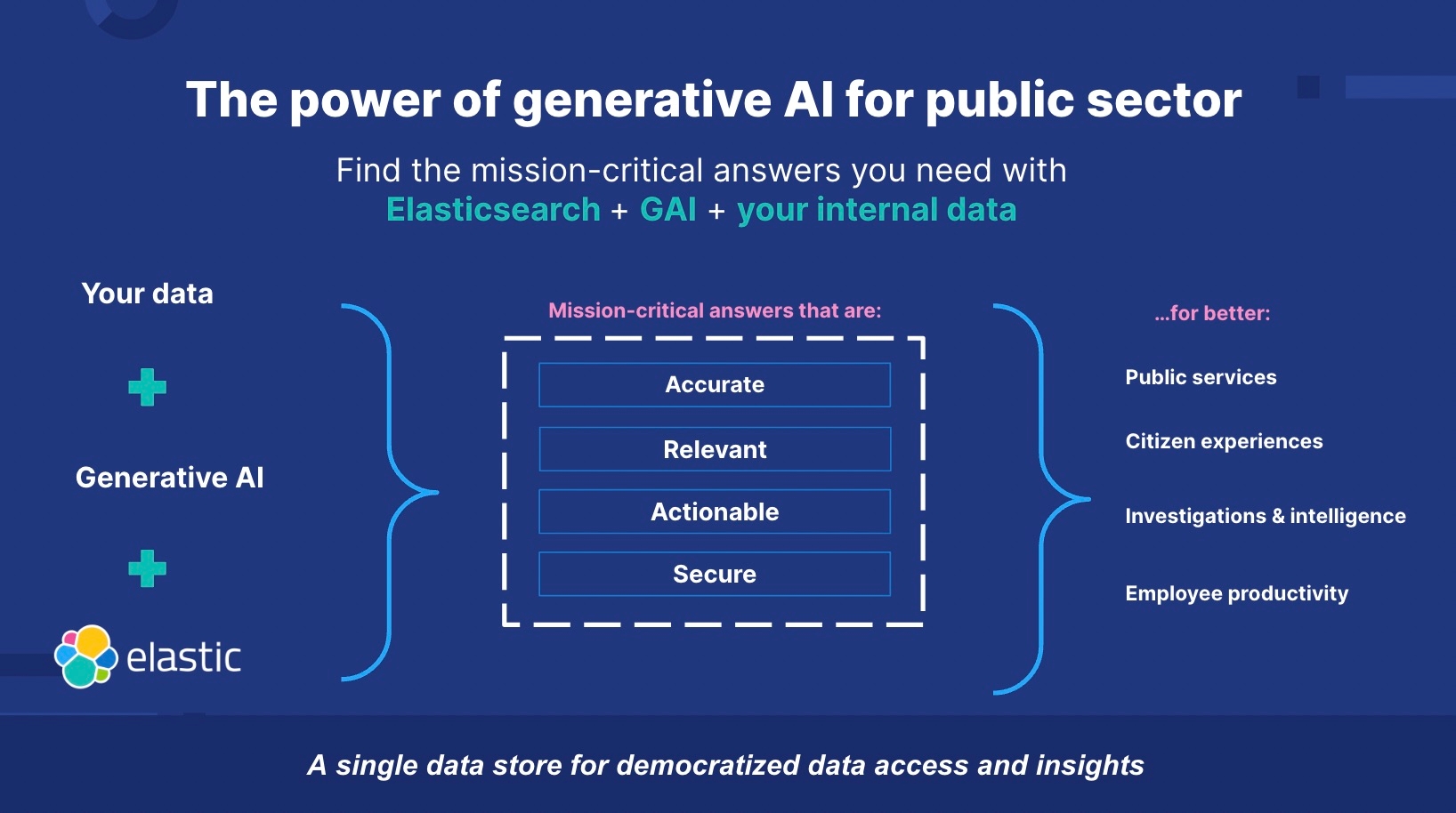
另一方面,当 GAI 与机构的内部数据一起使用时,它可以显着加快任务成果,改善公民服务,并在正确的时间更好地将分析师和网络安全专业人员等政府知识工作者与正确的数据联系起来。 为什么? 因为该机构数据增加了必要的背景。
GAI 与私人机构数据的结合具有力量倍增效应。 天真的解决方案是将私有数据烘焙到模型本身; 然而,训练或微调 AI 模型的复杂性和成本 —— 乘以政府领域和交互点的数量 —— 变得难以维持。 相反,向 LLM 提出的相同问题可以首先用于 Elastic 的 AI 支持的搜索功能,在那里可以找到基于你的内部数据的最相关的基于事实的答案。
你的数据为 GAI 带来的这种特定于领域的上下文可以使输出更准确、相关且更适合你的任务。 “自带数据” 的前提是你的数据存储在一个统一的数据平台上,可以在一个地方访问和查找。
隐私和安全呢?
特别是对于公共部门,你不希望将高度敏感的数据与可公开访问的 GAI 或你无法控制自己数据的任何系统混合在一起。 发送到公开可用的 GAI 产品(例如 ChatGPT)的任何搜索查询都会被模型使用,这意味着你的内部数据不再是内部数据。 即使你的组织没有正式使用 GAI 作为技术堆栈的一部分,但可以肯定的是,你的员工无论如何都会使用它。
通过以 IT 团队可以控制和洞察的方式将 GAI 与你的专有数据战略性集成,帮助确保你的内部数据掌握在正确的人手中。 否则,你可能会让员工无意中将你的敏感数据放入 ChatGPT 等公共 GAI 服务中,而你无法确保其安全性。 理想情况下,你可以将你的专有数据集成到一个旨在处理敏感信息的平台中,你可以在其中保留对自己数据的完全控制并启用基于角色的访问控制 (RBAC)。 更多内容请见下文。
使用 GAI 加速任务影响
数据是当今公共部门组织拥有的最具战略意义的资产之一。 当你的数据统一并存储在一个平台上时 —— 它可以在其中利用 GAI 和搜索技术——现实世界的影响可能是深远的,提供的好处包括:
个性化访问公共服务
想象一下,一位公民正在寻求申请公共住房服务。 申请过程涉及几个步骤和表格,这些步骤和表格因需求和位置而异。 简单地在网页上列出一般信息会很复杂,而且可能无法解决公民的独特情况。 另一方面,当机构将自己的数据带到 GAI 时,公民可以找到适合他们个人情况的信息和说明。 这种高度相关的信息有可能降低通常阻碍人们获得基本服务的复杂性。
简化公民体验
或者,再举一个例子:你被传唤担任陪审员,需要知道接下来会发生什么。 你需要去哪里? 它需要多长时间? 你被选为陪审员了吗? 你们的法官允许在法庭上使用手机吗? 利用你的数据,GAI 可以简化和个性化这些复杂的信息,从而有可能改善公民体验并建立与政府服务和领导者的信任。
准确的调查和情报
对于执法部门和情报界而言,实时民主化访问正确数据至关重要。 当多个组织在一个项目上进行协作时尤其如此 —— 使用不同格式的不同信息数据库。 能够通过单个 GAI 查询找到跨数据类型和来源的答案,有可能提高结果的速度和准确性,减少手动和耗时的工作,并确保每个需要的人都能以同样准确的方式工作 数据集。
提高员工生产力
当你将 GAI 与特定领域的上下文集成时,你可以帮助你的内部团队快速找到他们需要的信息来帮助他们完成工作。 跨多个数据集和格式的快速查询可以实时提供高度相关的信息 —— 避免需要费力(和头脑麻木)梳理文档或孤立的数据库。 在大多数情况下,你的团队正在寻找的信息不会在公共互联网或 AI 模型训练集中找到,因此提供一个 GAI 支持的工具来快速查找专有信息非常重要,这样你的员工就不会转向 到可能危及你的数据安全的公共工具。
当员工花费更少的时间在无结果的搜索和手动数据关联上时,你就可以消除他们一天中的更多摩擦源,为更好的工作满意度和敬业度铺平道路,尤其是当你一开始就资源紧张时。
GAI + Elasticsearch + 你的内部数据
当你考虑如何将你机构的数据与 GAI 集成时,Elasticsearch 平台可以成为一个强大的工具。 它允许你摄取所有类型的数据,经济地存储它,在任何地方访问它,并将它与 GAI transformer 模型集成。
十多年来,Elastic 一直致力于使搜索大众化,并且我们在其中的大部分时间里一直在投资人工智能和机器学习 (ML)。 因此,我们刚刚推出了 Elasticsearch Relevance Engine (ESRE),以帮助我们的客户通过 Elasticsearch 平台上的 AI 和 ML 找到问题的相关答案。
什么是 Elasticsearch 相关性引擎 (ESRE)?
ESRE 将 AI 的精华与 Elastic 的文本搜索相结合,提供了与大型语言模型 (LLM) 集成的能力。 它可以通过 Elastic 社区已经信任的简单、统一的 API 访问,因此开发人员可以立即开始使用它来提升搜索相关性。
换句话说,你现在可以将自己的 GAI 模型或第三方 GAI 模型直接连接到你存储在 Elasticsearch 平台中的数据。 这使你可以利用 GAI 的强大功能和特定领域的数据来生成准确、相关、可操作且安全的答案。
要了解有关 ESRE 的更多信息,请阅读发布博客。
为什么选择 Elasticsearch 用于 GAI 和私有数据?
1)数据统一存储,访问民主化。 你可以经济实惠地将所有数据存储在 Elasticsearch 平台中,以实现民主化访问、可查找性和洞察力。 一旦你的数据进入平台,你就可以将其用于其他用例,例如威胁搜寻和基础设施监控。
2)找到关键任务答案的能力:
- 准确:你将从 GAI 获得的答案和你自己的数据基于与任务相关的事实 —— 而非幻觉。
- 相关性:通过在 Elasticsearch 中使用专有数据,你可以避免在内部数据上重复重新培训 LLM,从而节省你的时间和培训成本,并确保你的信息始终是最新的。
- 可操作性:Elasticsearch 平台使数据和见解的访问民主化,使你的团队能够随时随地协作并实时做出决策。
- 安全:并非每个员工都应该能够访问每个文档,并且出于数据主权的目的,某些数据需要驻留在特定位置。 Elasticsearch 允许你限制组织内某些角色的数据访问,同时仍然保留在整个数据存储中进行搜索的能力。
3)具有成本效益的实施。 由于在信息检索方面进行了数十年的优化,Elasticsearch 以一种比从经过训练或微调的大型语言模型中提取相同知识的 CPU 效率高出几个数量级的方式向 GAI 交互呈现知识。 一些估计表明,语义检索的效率是仅使用 ChatGPT 3.5 的五倍或 GPT-4 CPU 成本的 250 倍。
GAI 能为你的组织创造多少价值取决于你的数据及其是否统一和可访问。 如果你的数据分布在多个工具和团队中,你可能缺乏使 GAI 与你的任务目标高度相关所需的上下文和内容。 Elasticsearch 平台作为你机构所有数据的单一数据存储,以及协作、人工智能洞察和自动化的集中起点。
下一步
- 了解有关 Elasticsearch 和 GAI 的更多信息。
- 从技术角度了解如何为隐私优先用例实施 Elasticsearch 和 AI。
- 联系 Elasticsearch 公共部门专家,讨论 AI 如何为你机构的使命带来价值。

