
热门标签
热门文章
- 1二开ChatGPT微信小程序源码 AI聊天微信小程序源码 适配H5和WEB端 支持AI聊天次数限制_ai对话h5 源码 免费开源
- 2win10 vmware没有vmnet0(桥接后无法上网)解决办法_vmnet0不见了
- 3Java基于HbuilderX开发通用生活记账app(源码+mysql+文档)_hbuilder开发安卓app源码
- 4安装requests模块及其他依赖库的完美解决办法_requests whl
- 5Flutter滚动型容器组件 - ListView篇_下面哪些容器组件是可以滚动的
- 6【HarmonyOS NEXT】Web组件中调用HSP中的rawfile资源,无法获取
- 7ssh 报错:no matching host key type found. 解决方法_unable to negotiate with 10.100. port 2222: no mat
- 8Android4.4 Activity启动流程分析_ensuring correct configuration: activityrecord
- 9Cesium label相关_cesiumlabel
- 10【Uniapp开发】APP的真机调试指南,从开发到上架全过程_uniapp开发app怎么运行到手机调试
当前位置: article > 正文
报错解决:RuntimeError: CUDA out of memory.
作者:凡人多烦事01 | 2024-03-11 21:10:04
赞
踩
runtimeerror: cuda out of memory.
问题
在进行深度学习的模型训练时,经常会遇到显存溢出的报错:
RuntimeError: CUDA out of memory.
输出如下图所示:

分析
打开一个终端,输入以下命令查看GPU使用情况:
nvidia-smi
- 1
输出如下图所示:
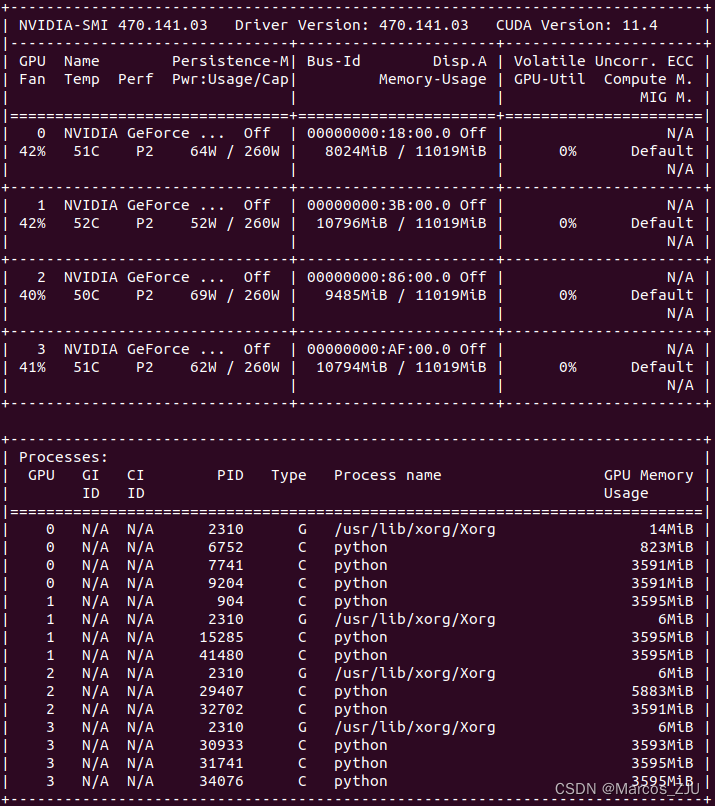
使用nvidia-htop可以进一步查看更为详细的内容。
nvidia-htop:A tool for enriching the output of nvidia-smi.
可以通过下列代码进行安装:
pip3 install nvidia-htop
- 1
打开一个终端,运行如下代码:
nvidia-htop.py
# nvidia-htop.py --color # 可以附带颜色,更加炫酷
- 1
- 2
输出如下图所示:
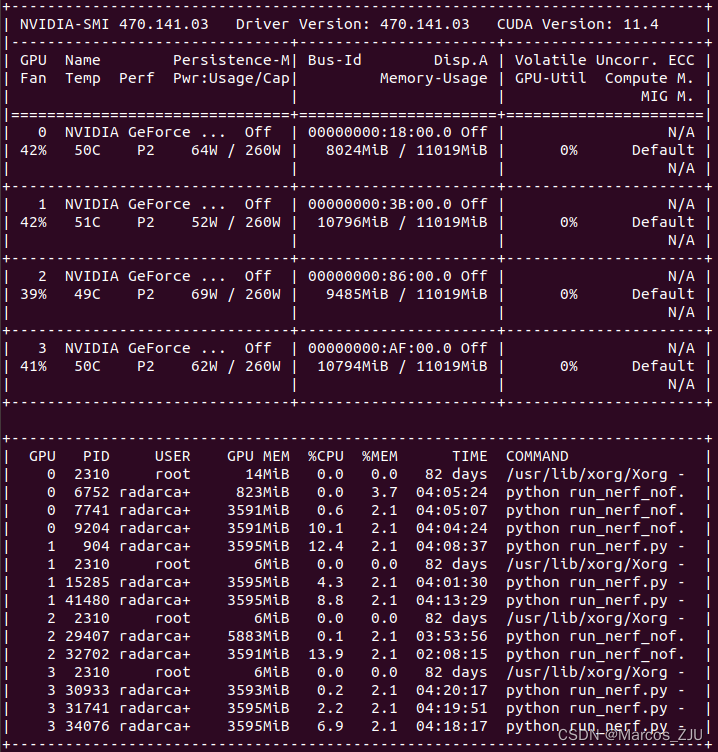
从图中可以看出编号为0,1,2,3的GPU利用率均为0,但四张显卡均有进程占用了GPU的显存,从而导致显存不足的问题。
解决
解决上述问题,只需将占用显存的进程杀死即可:
- 正常杀死进程:
kill -15 pid号 - 强制杀死进程:
kill -9 pid号
其他报错原因
若kill后仍报错RuntimeError: CUDA out of memory.,尝试以下方法:
1、降低batch size大小,或采用梯度累积的方法从而提高实际batch size的大小;
2、把网络模型改小;
3、把中间变量的大小(尺寸)改小;
4、换用显存更大的显卡。
5、在报错处、代码关键节点(一个epoch跑完…)插入以下代码(目的是定时清内存):
import torch, gc
gc.collect()
torch.cuda.empty_cache()
- 1
- 2
- 3
- 4
参考文献
pytorch: 四种方法解决RuntimeError: CUDA out of memory. Tried to allocate … MiB
深度学习中GPU和显存分析
浅谈深度学习:如何计算模型以及中间变量的显存占用大小
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/220618
推荐阅读
相关标签

