
- 1Kotlin withIndex
- 2FPGA硬件平台上基于Verilog实现的4路视频拼接技术_fpga 4路hdmi矩阵
- 33种python查看安装的所有库,然后将他们组合成一个pip命令_查看已安装的python库
- 4Flink HistoryServer配置(简单三步完成)_flink history server配置
- 5STC89C52RC数码管秒表程序编写_stc89c52rc数码管程序
- 6Android NotificationManager详解
- 7LLM记录-常见问题部分_llm为什么会出现复读机问题
- 8中国石油大学《客户关系管理》第三次在线作业_中国石油大学客户关系管理第一次在线作业
- 9尝鲜!最新 VitePress 1 版本 + Github action,自动部署个人静态站点 SSG_github action vits
- 10鸿蒙HarmonyOS实战-Stage模型(应用上下文Context)_鸿蒙 page 里获取 context(2)_鸿蒙 page里获取上下文
【强化学习】Q-Learning算法求解迷宫寻路问题 + Java代码实现_基于qlearning迷宫寻路问题解决方案
赞
踩
前言
相信大多数小伙伴应该和我一样,之前在学习强化学习的时候,一直用的是Python,但奈何只会用java写后端,对Python的一些后端框架还不太熟悉,(以后要集成到网站上就惨了),于是就想用Java实现一下强化学习中的Q-Learning算法,来搜索求解人工智能领域较热门的问题—迷宫寻路问题。(避免以后要用的时候来不及写)。
一、Q-Learning算法简介
下面仅对Q-Learning算法对简单介绍
Q学习是一种异策略(off-policy)算法。
异策略在学习的过程中,有两种不同的策略:目标策略(target policy)和行为策略(behavior policy)。
目标策略就是我们需要去学习的策略,相当于后方指挥的军师,它不需要直接与环境进行交互
行为策略是探索环境的策略,负责与环境交互,然后将采集的轨迹数据送给目标策略进行学习,而且为送给目标策略的数据中不需要 a t + 1 a_{t+1} at+1,而Sarsa是要有 a t + 1 a_{t+1} at+1的。
Q学习不会管我们下一步去往哪里探索,它只选取奖励最大的策略
1.1 更新公式
Q-Learning的更新公式
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + 1 + γ max a Q ( s t + 1 , a ) − Q ( s t , a t ) ] Q\left(s_t, a_t\right) \leftarrow Q\left(s_t, a_t\right)+\alpha\left[r_{t+1}+\gamma \max _a Q\left(s_{t+1}, a\right)-Q\left(s_t, a_t\right)\right] Q(st,at)←Q(st,at)+α[rt+1+γamaxQ(st+1,a)−Q(st,at)]
1.2 预测策略
Q-Learning算法采用 ε \varepsilon ε-贪心搜索的策略(和Sarsa算法一样)
1.3 详细资料
关于更加详细的Q-Learning算法的介绍,请看我之前发的博客:【EasyRL学习笔记】第三章 表格型方法(Q-Table、Sarsa、Q-Learning)
在学习Q-Learning算法前你最好能了解以下知识点:
- 时序差分方法
- ε \varepsilon ε-贪心搜索策略
- Q-Table
二、迷宫寻路问题简介
迷宫寻路问题是人工智能中的有趣问题,给定一个M行N列的迷宫图,其中 "0"表示可通路,"1"表示障碍物,无法通行,"2"表示起点,"3"表示终点。在迷宫中只允许在水平或上下四个方向的通路上行走,走过的位置不能重复走,需要搜索出从起点到终点尽量短的路径。

地图可视化如下图所示:绿色代表道路,黑色代表墙壁,粉色代表起点,蓝色代表终点

三、Java代码
3.1 环境说明
我的环境是的Java的Maven项目,其中使用到了Lombok依赖
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
迷宫寻路的可视化用到了JavaFx,我使用的是jdk1.8版本,其内部自带JavaFx,但是新版java将JavaFx移除了,需要从外部引入,用新版java的伙伴可以上网查查怎么引入JavaFx
3.2 参数配置
在迷宫环境类中进行奖励设置
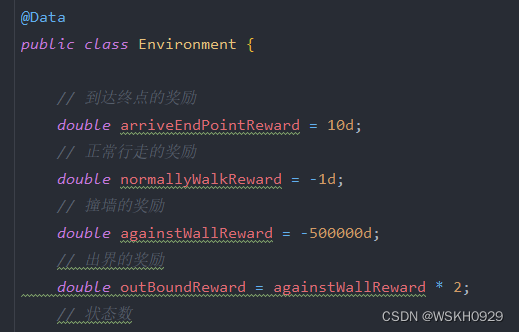
在运行类中进行算法参数配置

3.3 迷宫环境类
作用:用来模拟迷宫环境,让智能体可以在里面行走,并返回适当的奖励
import lombok.Data; import java.util.HashMap; @Data public class Environment { // 到达终点的奖励 double arriveEndPointReward = 10d; // 正常行走的奖励 double normallyWalkReward = -1d; // 撞墙的奖励 double againstWallReward = -500000d; // 出界的奖励 double outBoundReward = againstWallReward * 2; // 状态数 int stateCnt; // 起点、终点 private int startIndex, endIndex; // 当前状态 int curState; // 0是路 1是墙 2是起点 3是终点 int[][] map = new int[][]{ {1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0}, {0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0}, {0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0}, {0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0}, {0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1}, {0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1}, {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 3, 0, 0, 0, 0, 0, 0, 0}, }; public Environment() { stateCnt = map[0].length * map.length; getStartAndEndIndexByMap(); curState = startIndex; // System.out.println(startIndex + " . . " + endIndex); } // 按照指定动作行走 public HashMap<String, Object> step(int action) { switch (action) { case 0: // 上 if (curState - map.length < 0) { return outBound(); } else if (isWall(curState - map.length)) { return againstWall(); } else { return normallyWalk(curState - map.length); } case 1: // 下 if (curState + map.length >= stateCnt) { return outBound(); } else if (isWall(curState + map.length)) { return againstWall(); } else { return normallyWalk(curState + map.length); } case 2: // 左 if (curState % map.length == 0) { return outBound(); } else if (isWall(curState - 1)) { return againstWall(); } else { return normallyWalk(curState - 1); } case 3: // 右 if (curState % map.length == map.length - 1) { return outBound(); } else if (isWall(curState + 1)) { return againstWall(); } else { return normallyWalk(curState + 1); } default: throw new RuntimeException("识别不到的动作: " + action); } } // 正常行走 public HashMap<String, Object> normallyWalk(int nextState) { HashMap<String, Object> resMap = new HashMap<>(); curState = nextState; resMap.put("nextState", nextState); resMap.put("reward", curState == endIndex ? arriveEndPointReward : normallyWalkReward); resMap.put("done", curState == endIndex); return resMap; } // 出界处理 public HashMap<String, Object> outBound() { HashMap<String, Object> resMap = new HashMap<>(); resMap.put("nextState", curState); resMap.put("reward", outBoundReward); resMap.put("done", true); return resMap; } // 撞墙处理 public HashMap<String, Object> againstWall() { HashMap<String, Object> resMap = new HashMap<>(); resMap.put("nextState", curState); resMap.put("reward", againstWallReward); resMap.put("done", true); return resMap; } // 重置环境,并获取初始状态 public int reset() { curState = startIndex; return startIndex; } // 判断该状态是不是墙 public boolean isWall(int state) { return map[state / map.length][state % map.length] == 1; } // 根据地图获取起点和终点的序号 public void getStartAndEndIndexByMap() { for (int i = 0; i < map.length; i++) { for (int j = 0; j < map[i].length; j++) { if (map[i][j] == 2) { startIndex = i * map[0].length + j; } else if (map[i][j] == 3) { endIndex = i * map[0].length + j; } } } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
3.4 Q-Learning算法类
import lombok.Data; import java.util.HashMap; import java.util.Random; @Data public class QLearning { // 采样次数 int sampleCnt = 0; // 状态数 int stateCnt; // 动作数 上下左右 int actionCnt = 4; // 学习率 double lr; // 未来奖励衰减因子 double gamma; // 当前epsilon值 double epsilon; // 初始epsilon值 double startEpsilon; // 最后epsilon值 double endEpsilon; // epsilon衰变参数 double epsilonDecay; // Q表格 HashMap<Integer, double[]> QTable = new HashMap<>(); // 随机数对象 Random random; // 构造函数 public QLearning(double lr, double gamma, double startEpsilon, double endEpsilon, double epsilonDecay, int stateCnt,int seed) { this.lr = lr; this.gamma = gamma; this.startEpsilon = startEpsilon; this.endEpsilon = endEpsilon; this.epsilonDecay = epsilonDecay; this.stateCnt = stateCnt; this.random = new Random(seed); // 初始化Q表:对应四种运动可能 上下左右 全部设置为0 for (int i = 0; i < stateCnt; i++) { QTable.put(i, new double[actionCnt]); } } // 训练过程: 用e-greedy policy获取行动 public int sampleAction(int state) { sampleCnt += 1; epsilon = endEpsilon + (startEpsilon - endEpsilon) * Math.exp(-1.0 * sampleCnt / epsilonDecay); if (random.nextDouble() <= (1 - epsilon)) { return predictAction(state); } else { return random.nextInt(actionCnt); } } // 测试过程: 用最大Q值获取行动 public int predictAction(int state) { int maxAction = 0; double maxQValue = QTable.get(state)[maxAction]; for (int i = 1; i < actionCnt; i++) { if (maxQValue < QTable.get(state)[i]) { maxQValue = QTable.get(state)[i]; maxAction = i; } } return maxAction; } // 更新Q表格 public void update(int state, int action, double reward, int nextState, boolean done) { // 计算Q估计 double QPredict = QTable.get(state)[action]; // 计算Q现实 double QTarget = 0.0; if(done){ QTarget = reward; }else{ QTarget = reward + gamma * getMaxQValueByState(nextState); } // 根据Q估计和Q现实,差分更新Q表格 QTable.get(state)[action] += (lr * (QTarget - QPredict)); } // 获取某个状态下的最大Q值 public double getMaxQValueByState(int state){ int maxAction = 0; double maxQValue = QTable.get(state)[maxAction]; for (int i = 1; i < actionCnt; i++) { if (maxQValue < QTable.get(state)[i]) { maxQValue = QTable.get(state)[i]; maxAction = i; } } return maxQValue; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
3.5 运行类
import Algorithm.图论.网格型最短路.Environment; import javafx.geometry.VPos; import javafx.scene.Scene; import javafx.scene.canvas.Canvas; import javafx.scene.canvas.GraphicsContext; import javafx.scene.layout.AnchorPane; import javafx.scene.paint.Color; import javafx.scene.text.Font; import javafx.scene.text.TextAlignment; import javafx.stage.Stage; import java.util.*; public class Run extends javafx.application.Application { // 算法参数 // 学习率 double lr = 0.01; // 未来奖励衰减因子 double gamma = 0.9; // 初始epsilong值 double startEpsilon = 0.95; // 最后epsilong值 double endEpsilon = 0.01; double epsilonDecay = 300; // 训练迭代数 int epochs = 20000; // 随机数种子 int seed = 520; @Override public void start(Stage primaryStage) throws Exception { // 初始化JavaFx视图 AnchorPane pane = new AnchorPane(); // 初始化环境 Environment env = new Environment(); // 初始化地图 Canvas canvas = initCanvas(env.getMap()); pane.getChildren().add(canvas); // 实例化QLearning对象 QLearning agent = new QLearning(lr, gamma, startEpsilon, endEpsilon, epsilonDecay, env.getStateCnt(), seed); // 开始训练 long start = System.currentTimeMillis(); train(env, agent); System.out.println("训练用时:" + (System.currentTimeMillis() - start) / 1000.0 + " s"); // 测试 test(canvas, env, agent); primaryStage.setTitle("QLearning算法求解迷宫寻路问题"); primaryStage.setScene(new Scene(pane, 600, 600, Color.YELLOW)); primaryStage.show(); } // 训练智能体 private void train(Environment env, QLearning agent) { // 记录每个epoch的奖励和步数 double[] rewards = new double[epochs]; double[] steps = new double[epochs]; // 开始循环迭代 for (int epoch = 0; epoch < epochs; epoch++) { // 每个epoch的奖励总数 double epReward = 0d; // 每个回合的步数 int epStep = 0; // 重置环境,获取初始状态(起点) int state = env.reset(); // 开始寻路 while (true) { int action = agent.sampleAction(state); HashMap<String, Object> resMap = env.step(action); agent.update(state, action, (double) resMap.get("reward"), (int) resMap.get("nextState"), (boolean) resMap.get("done")); state = (int) resMap.get("nextState"); epReward += (double) resMap.get("reward"); epStep += 1; if ((boolean) resMap.get("done")) { break; } } // 记录 rewards[epoch] = epReward; steps[epoch] = epStep; // 输出 if ((epoch + 1) % 1000 == 0) { System.out.println("Epoch: " + (epoch + 1) + "/" + epochs + " , Reward: " + epReward + " , Epsilon: " + agent.getEpsilon()); } } } // 测试智能体 private void test(Canvas canvas, Environment env, QLearning agent) { List<Integer> bestPathList = new ArrayList<>(); // 重置环境,获取初始状态(起点) int state = env.reset(); bestPathList.add(state); // 按照最大Q值寻路 while (true) { int action = agent.predictAction(state); HashMap<String, Object> resMap = env.step(action); state = (int) resMap.get("nextState"); bestPathList.add(state); if ((boolean) resMap.get("done")) { break; } if(bestPathList.size() >= agent.stateCnt){ throw new RuntimeException("智能体还没收敛,请增加迭代次数后重试"); } } plotBestPath(canvas, bestPathList, env); } // 绘制最佳路线 public void plotBestPath(Canvas canvas, List<Integer> bestPathList, Environment env) { int[][] map = env.getMap(); for (int i = 0; i < bestPathList.size(); i++) { int pos = bestPathList.get(i); int colLen = map[0].length; int y = pos % colLen; int x = (pos - y) / colLen; GraphicsContext gc = canvas.getGraphicsContext2D(); gc.setFill(Color.GRAY); gc.fillRect(y * 20, x * 20, 20, 20); // 绘制文字 gc.setFill(Color.BLACK); gc.setFont(new Font("微软雅黑", 15)); gc.setTextAlign(TextAlignment.CENTER); gc.setTextBaseline(VPos.TOP); gc.fillText("" + (i), y * 20 + 10, x * 20); } System.out.println("测试: 行走步数为:" + (bestPathList.size() - 1)); } // 绘制初始地图 public Canvas initCanvas(int[][] map) { Canvas canvas = new Canvas(400, 400); canvas.relocate(100, 100); for (int i = 0; i < map.length; i++) { for (int j = 0; j < map[i].length; j++) { int m = map[i][j]; GraphicsContext gc = canvas.getGraphicsContext2D(); if (m == 0) { gc.setFill(Color.GREEN); } else if (m == 1) { gc.setFill(Color.BLACK); } else if (m == 2) { gc.setFill(Color.PINK); } else if (m == 3) { gc.setFill(Color.AQUA); } gc.fillRect(j * 20, i * 20, 20, 20); } } return canvas; } public static void main(String[] args) { launch(args); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
四、运行结果展示
4.1 案例1
地图
int[][] map = new int[][]{ {1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0}, {0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0}, {0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0}, {0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0}, {0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1}, {0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1}, {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 3, 0, 0, 0, 0, 0, 0, 0}, };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
输出
Epoch: 1000/20000 , Reward: -500341.0 , Epsilon: 0.01 Epoch: 2000/20000 , Reward: -305.0 , Epsilon: 0.01 Epoch: 3000/20000 , Reward: -107.0 , Epsilon: 0.01 Epoch: 4000/20000 , Reward: -500053.0 , Epsilon: 0.01 Epoch: 5000/20000 , Reward: -500174.0 , Epsilon: 0.01 Epoch: 6000/20000 , Reward: -29.0 , Epsilon: 0.01 Epoch: 7000/20000 , Reward: -33.0 , Epsilon: 0.01 Epoch: 8000/20000 , Reward: -39.0 , Epsilon: 0.01 Epoch: 9000/20000 , Reward: -19.0 , Epsilon: 0.01 Epoch: 10000/20000 , Reward: -19.0 , Epsilon: 0.01 Epoch: 11000/20000 , Reward: -19.0 , Epsilon: 0.01 Epoch: 12000/20000 , Reward: -19.0 , Epsilon: 0.01 Epoch: 13000/20000 , Reward: -19.0 , Epsilon: 0.01 Epoch: 14000/20000 , Reward: -19.0 , Epsilon: 0.01 Epoch: 15000/20000 , Reward: -21.0 , Epsilon: 0.01 Epoch: 16000/20000 , Reward: -500022.0 , Epsilon: 0.01 Epoch: 17000/20000 , Reward: -19.0 , Epsilon: 0.01 Epoch: 18000/20000 , Reward: -19.0 , Epsilon: 0.01 Epoch: 19000/20000 , Reward: -21.0 , Epsilon: 0.01 Epoch: 20000/20000 , Reward: -19.0 , Epsilon: 0.01 训练用时:1.06 s 测试: 行走步数为:30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
路径长度:30

4.2 案例2
地图
int[][] map = new int[][]{ {1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0}, {0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0}, {0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0}, {0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0}, {0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0}, {0, 0, 1, 0, 1, 3, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1}, {0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1}, {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0}, };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
输出:
Epoch: 1000/20000 , Reward: -285.0 , Epsilon: 0.01 Epoch: 2000/20000 , Reward: -500352.0 , Epsilon: 0.01 Epoch: 3000/20000 , Reward: -183.0 , Epsilon: 0.01 Epoch: 4000/20000 , Reward: -500116.0 , Epsilon: 0.01 Epoch: 5000/20000 , Reward: -69.0 , Epsilon: 0.01 Epoch: 6000/20000 , Reward: -41.0 , Epsilon: 0.01 Epoch: 7000/20000 , Reward: -37.0 , Epsilon: 0.01 Epoch: 8000/20000 , Reward: -25.0 , Epsilon: 0.01 Epoch: 9000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 10000/20000 , Reward: -500027.0 , Epsilon: 0.01 Epoch: 11000/20000 , Reward: -21.0 , Epsilon: 0.01 Epoch: 12000/20000 , Reward: -21.0 , Epsilon: 0.01 Epoch: 13000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 14000/20000 , Reward: -500005.0 , Epsilon: 0.01 Epoch: 15000/20000 , Reward: -21.0 , Epsilon: 0.01 Epoch: 16000/20000 , Reward: -21.0 , Epsilon: 0.01 Epoch: 17000/20000 , Reward: -21.0 , Epsilon: 0.01 Epoch: 18000/20000 , Reward: -500019.0 , Epsilon: 0.01 Epoch: 19000/20000 , Reward: -21.0 , Epsilon: 0.01 Epoch: 20000/20000 , Reward: -500014.0 , Epsilon: 0.01 训练用时:1.107 s 测试: 行走步数为:32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
路径长度:32

4.3 案例3
地图
int[][] map = new int[][]{ {1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0}, {3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0}, {0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0}, {0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0}, {0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, {0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 2, 0, 1}, {0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1}, {0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1}, {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0}, };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
输出
Epoch: 1000/20000 , Reward: -500088.0 , Epsilon: 0.01 Epoch: 2000/20000 , Reward: -500138.0 , Epsilon: 0.01 Epoch: 3000/20000 , Reward: -1000062.0 , Epsilon: 0.01 Epoch: 4000/20000 , Reward: -89.0 , Epsilon: 0.01 Epoch: 5000/20000 , Reward: -61.0 , Epsilon: 0.01 Epoch: 6000/20000 , Reward: -25.0 , Epsilon: 0.01 Epoch: 7000/20000 , Reward: -25.0 , Epsilon: 0.01 Epoch: 8000/20000 , Reward: -500024.0 , Epsilon: 0.01 Epoch: 9000/20000 , Reward: -25.0 , Epsilon: 0.01 Epoch: 10000/20000 , Reward: -27.0 , Epsilon: 0.01 Epoch: 11000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 12000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 13000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 14000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 15000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 16000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 17000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 18000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 19000/20000 , Reward: -23.0 , Epsilon: 0.01 Epoch: 20000/20000 , Reward: -23.0 , Epsilon: 0.01 训练用时:0.706 s 测试: 行走步数为:34
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
路径长度:34

以上就是完整代码啦!如果觉得感兴趣,欢迎点赞+关注,以后会继续更新相关方面的文章!

